
- 1Jenkins 初始密码文件在/var/lib/jenkins/secrets没有的解决办法_cat: /var/lib/jenkins/secrets/initialadminpassword
- 2Docker+Jenkins+Gitee自动化部署maven项目_jenkins docker maven
- 3git查询当前目录下的文件列表_Gitqlite - 用SQL语法来查询Git仓库
- 4Unity按钮事件的几种绑定方式_unity 获取button事件
- 5el-table样式修改_el-table__cell gutter
- 6C#系列-EF框架的创新应用+利用EF框架技术的知名开源应用项目(42)_知名c#开源项目
- 7【Java】斐波那契数列(Fibonacci Sequence、兔子数列)的3种计算方法(递归实现、递归值缓存实现、循环实现、尾递归实现)...
- 8使用vue3+element-ui plus 快速构建后台管理模板_element ui plus
- 9一个月空余时间微信诗词小程序前后端开发上线实践指南_古诗词的前后端开源
- 10python中的tkinter包的使用--messagebox弹窗_tk.messagebox.showinfo
yolov8网络结构详解(逐行解析)
赞
踩
一. Backbone
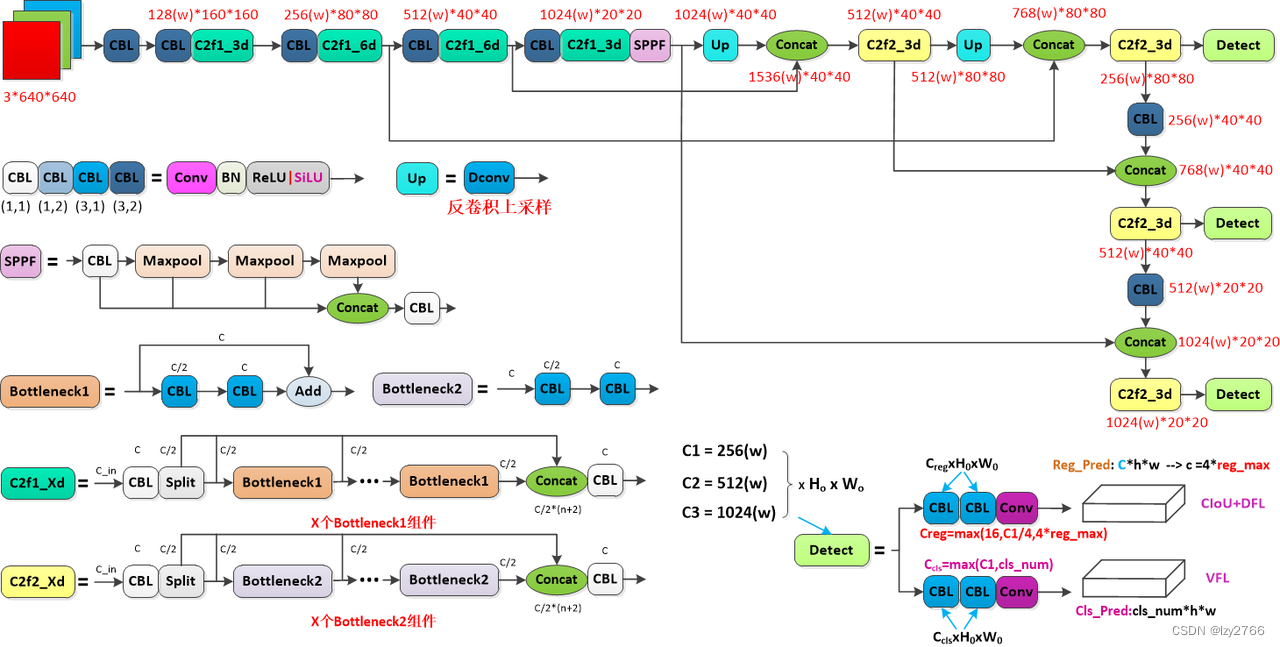
1. C2f结构
CSP结构

yolov5使用的CSP结构分为两种,在backbone中为CSP1_X,其中的X个组件中存在残差结构,如下图:

在Neck中为CSP2_X,其中的2*X个CBL模块没有残差结构;
C2f结构

yolov8使用的C2f结构同样分为两种,与yolov5类似,在backbone中为C2f1,其中的X个组件中存在残差结构,如下图:

在Neck中为C2f2,其中的X个组件中没有残差结构,如下图:

从以上两个结构可以看出,CSP主要是传统的残差连接,而C2f参考了densenet增加了更多的跳层连接,取消了分支中的卷积操作,并且增加了额外的split操作,让特征信息更丰富的同时,减少计算量,保证了两者兼顾;
2. SPPF
SPP

SPP结构中有三层并行连接的最大池化层,分别是卷积核5*5 9*9 13*13,池化后进行concat操作
SPPF
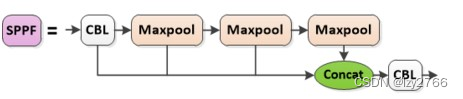
SPPF结构中是具有残差结构的连续三次最大池化, 卷积核统一为5*5,最后将池化前和每次池化后的结果concat
池化公式
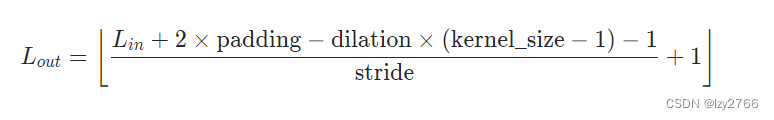
最大池化操作中因特征提取后,特征图会变小,所以在特征提取前,都会增大padding,保证每次池化后特征图大小不变;例如5*5的kernel_size,需要padding=2保证Lin与Lout的shape大小不变
yolo中本身池化的操作是为了结合更多种的池化结果,多尺度融合,保证特征提取信息更丰富,SPP利用不同的卷积核大小进行分别池化,进行多尺度融合,但计算量较大,而SPPF利用三次连续池化,降低了计算量,并且结合了每一层的输出,保证了多尺度融合的同时,降低了计算量,并且还相比较进一步增大了感受野;
二. head
1. 解耦头
耦合头
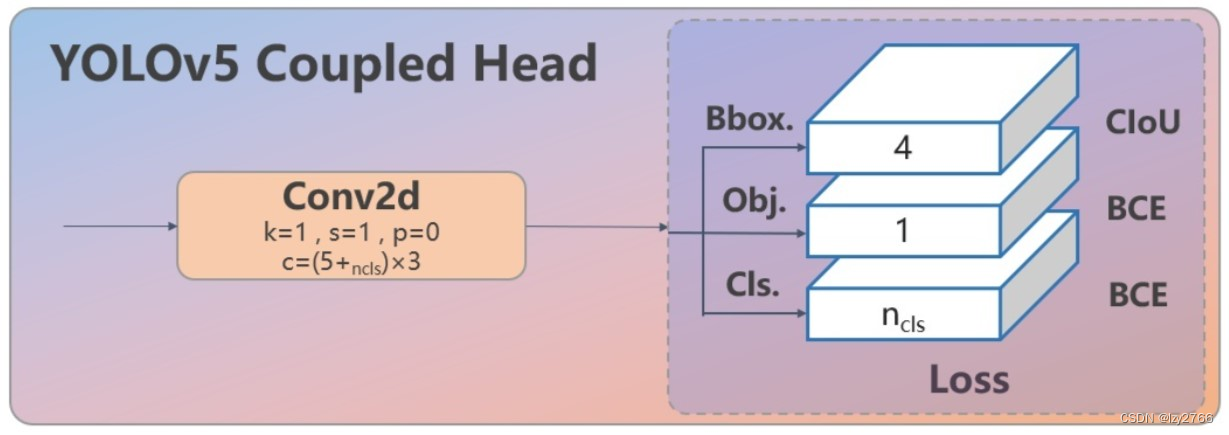
耦合头的设计是在网络的末尾,通过一系列的卷积和全连接层,同时预测不同尺度的边界框位置、尺寸和类别。具体来说,YOLOv5的头部包含了几个输出层,每个输出层负责预测一个尺度的边界框。每个输出层都具有相同数量的预测通道Ccls=Cbbox=Cobj=5+ncls,用于预测边界框的位置、尺寸和类别。这种设计使得YOLOv5可以在不同尺度上并行地进行目标检测
解耦头

解耦头的设计是每个尺度都有独立的检测器,每个检测器由一组卷积和全连接层组成,用于预测该尺度上的边界框(yolov8只有分类和回归分支,舍弃了目标对象分支)。因此,YOLOv8在网络的不同层级上应用了不同的检测器,每个检测器单独负责预测一个尺度的边界框。这样的设计允许YOLOv8捕捉不同尺度目标的信息,以提高目标检测的准确性。
对于cls类别分支,其通道数为Ccls = max(c1, cls_num)
对于box回归分支,其通道数为Creg = max(16, c1/4, 4*reg_max) reg_max表示每个锚点输出的通道数,默认为16
cls类别分支公式中包含两个值:c1和cls_num,要保证通道数至少要大于类别的数量
box回归分支公式中包含三个值:16、c1/4和4*reg_max。它们分别代表了三个参考值,通过取它们的最大值作为回归器通道数,可以保证回归器充分拥有模型的表示能力和捕捉目标位置和尺寸的能力。
16:16是一个固定值,表示回归器的最小通道数。这是为了确保回归器具有足够的表示能力,能够预测目标的位置和尺寸。
c1/4:c1表示特征图的通道数,通过除以4来得到c1/4。这个值代表了特征图的通道数的四分之一,目的是限制回归器通道数不能超过特征图通道数的四分之一。这样做是为了避免回归器通道数过多导致模型过于复杂和计算量过大。
4*reg_max:reg_max代表目标位置和尺寸的参数中的最大值,通过将reg_max乘以4,可以得到一个与目标尺寸参数相关的参考值。这是为了保证回归器具有足够的通道数来适应目标的不同尺度,防止信息损失和误差过大。
综合考虑以上三个参考值,选择其中最大的值作为回归器通道数,可以平衡模型复杂度和性能,同时确保回归器具备足够的表示能力和预测能力,以实现较好的目标检测效果。
2. 网络输出
锚点的输出计算方式为:no = nc+4*reg_max(假设类别数为2, 则no = 2+4*16 = 66)
W和H是分别通过CBL进行两次下采样得到80*80—40*40—20*20
则输出的三个特征图的大小分别为1*66*80*80, 1*66*40*40, 1*66*20*20适用于预测不同大小的目标
三. yolov8s.yaml文件解读

From: 输入,-1表示上层的输出作为本层的输入, [15, 18, 21] 为索引值,表示detect层的输入为第15层、18层、21层的输出
Repeats: 模块的重复次数
Module: 使用的模块
Args: 模块里面的参数 conv (in_channel, kernel, padding) , True代表Bottleneck模块中shortcut=True, 没有写表示False, upsample中的“nearest”表示上采样差值方式为最近邻差值, None表示不指定输出尺寸, 2表示输出尺寸为输入尺寸的2倍;
out_size = (in_size - k + 2*p) / s + 1
四. 网络逐层解读
1. Backbone
Input map channel: 3 size:640*640
第0层 CBL(conv-bn-silu) channel: 64 size:320*320
第1层 CBL(conv-bn-silu) channel: 128 size:160*160
前两层主要是简单的CBL模块,主要是扩充通道,缩小特征图,提取深层特征
第2层 C2f * 3 channel: 128 size:160*160 shortcut=True
进入核心模块C2f, 输入通道为128,经过split变为64, 经过Bottleneck模块时,通过两个k=3 p=1 e=1的卷积模块,最后经过add模块,out_channel和out_size都没有变化,输出为64*160*160, 然后经过concat, 包含n个Bottleneck模块输出+1个split+1个CBL(C/2) = C/2*(n+2)= 192*160*160,最后经过CBL层,输出为128*160*160
第3层 CBL(conv-bn-silu) channel: 256 size:80*80
第4层 C2f * 6 channel: 256 size:80*80 shortcut=True
第5层 CBL(conv-bn-silu) channel: 512 size:40*40
第6层 C2f * 6 channel: 512 size:40*40 shortcut=True
第7层 CBL(conv-bn-silu) channel: 1024 size:20*20
第8层 C2f * 3 channel: 1024 size:20*20 shortcut=True
第9层 SPPF(k=5) channel: 1024 size:20*20
第3-8层与1-2层一致,分别重复6-6-3个Bottleneck模块
第9层是一层池化层,采用SPPF结构,多尺度融合特征,在前面已经详细讲过,这里不赘述;
2. Head
第10层 upsample channel:1024 size:40*40
第10层开始进行上采样,利用最近邻差值方法,放大特征图
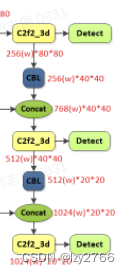
第11层 concat channel:1536 size:40*40
第6层输出+第10层输出=512*40*40+1024*40*40=1536*40*40
第12层 C2f * 3 channel: 512 size:40*40 shortcut=False
第12层与backbone中的从c2f类似,只是shortcut=False,取消了残差结构,输出尺寸从1536*40*40—512*40*40
第13层 upsample channel: 512 size:80*80
第14层 concat channel: 768 size:80*80
第14层为第4层输出+第13层输出=256*80*80+512*80*80=768*80*80
第15层 C2f * 3 channel: 256 size:80*80 shortcut=False
第13-15层与10-12层相同
第16层 CBL(conv-bn-silu) channel: 256 size:40*40
第17层 concat channel: 768 size:40*40
第17层为第12层输出+第16层输出=512*40*40+256*40*40=768*40*40
第18层 C2f * 3 channel: 512 size:40*40 shortcut=False
第19层 CBL(conv-bn-silu) channel: 512 size:20*20
第20层 concat channel: 1536 size:20*20
第20层为第9层输出+第19层输出=1024*20*20+512*20*20=1536*20*20
第21层 C2f * 3 channel: 1024 size:20*20 shortcut=False
第16-21层,除了从上采样变为下采样,其他与10-12层相同
3. Detect
第22层 Detect channel: 64+nc size:80*80 40*40 20*20
假设nc=2,那么第22层的最后输出的三个特征图分别为1*66*80*80, 1*66*40*40, 1*66*20*20

