
- 1Unity2D教程:单例模式、SceneManager.LoadSceneAsync场景切换、Loading界面进度条
- 2mysql undo表空间_MySQL UNDO表空间独立和截断
- 3Chatgpt这么智能,以后会不会取代掉人类?_chatgpt是否会代替人类的大脑
- 4计算机设计大赛 深度学习人体语义分割在弹幕防遮挡上的实现 - python
- 5windows7装python哪个版本好,win7安装哪个版本的python_pycharm win7适配版本
- 6UE4蓝图基础入门(一)变量与蓝图_ue setmenbersin
- 7ChatGPT-4和ChatGPT-3.5知识库截止日期竟然一样?_gpt4数据库截止日期
- 8Unity——InputSystem入门及部分问题讲解_unity inputsystem
- 9python库turtle的双画笔并发绘制兔兔 表白神器_pythonturtle画小白兔
- 10Rabbitmq学习之路3-cluster_rabbitmqctl join_cluster --ram
操作系统:内存管理篇—— 虚拟内存、段式内存管理、页式内存管理_纯页式存储管理是虚拟存储吗
赞
踩
前言
本文参考自《小林coding》、《深入理解计算机系统》。
为了更加有效地管理内存并且少出错,现代系统提供了一种对主存的抽象概念,叫做虚拟内存(VM)。
虚拟内存是硬件异常、硬件地址翻译、主存、磁盘文件和内核软件的完美交互,它为每个进程提供了一个大的、一致的和私有的地址空间。
通过一个很清晰的机制,虚拟内存提供了三个重要的能力:
- 它将主存看成是一个存储在磁盘上的地址空间的高速缓存,在主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据,通过这种方式,它高效地使用了主存。
- 它为每个进程提供了一致的地址空间,从而简化了内存管理。
- 它保护了每个进程的地址空间不被其他进程破坏。
一、物理和虚拟地址
计算机系统的主存被组织成一个有M个连续的字节大小的单元组成的数组。每字节都有一个唯一的物理地址( Physical Address,PA)。
第一个字节的地址为0,接下来的字节地址为1,再下一个为2,依此类推。给定这种简单的结构,CPU 访问内存的最自然的方式就是使用物理地址。我们把这种方式称为物理寻址( physicaladdressing)。示例:
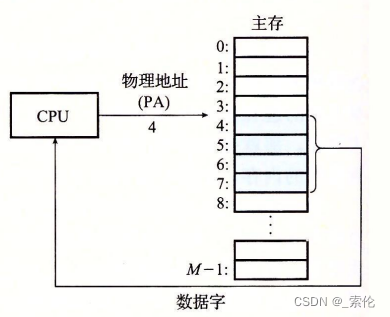
在这种情况下,要想在内存中同时运行两个程序是不可能的。如果第一个程序在1的位置写入一个新的值,将会擦掉第二个程序存放在相同位置上的所有内容,所以同时运行两个程序是根本行不通的,这两个程序会立刻崩溃。
操作系统如何解决该问题?
我们可以把进程所使用的地址 “隔离” 开来,即让操作系统为每个进程分配独立的一套 「虚拟地址」 ,人人都有,大家自己玩自己的地址就行,互不干涉。但是有个前提每个进程都不能访问物理地址,至于虚拟地址最终怎么落到物理内存里,对进程来说是透明的,操作系统已经把这些都安排的明明白白了。
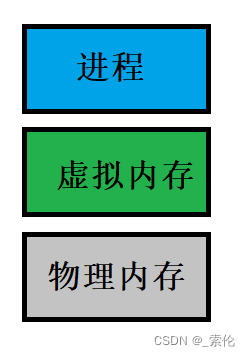
操作系统会提供一种机制,将不同进程的虚拟地址和不同内存的物理地址映射起来。
如果程序要访问虚拟地址的时候,由操作系统转换成不同的物理地址,这样不同的进程运行的时候,写入的是不同的物理地址,这样就不会冲突了。
于是,这里就引出了两种地址的概念:
- 我们程序所使用的内存地址叫做虚拟内存地址(Virtual Memory Address)
- 实际存在硬件里面的空间地址叫物理内存地址( Physical Memory Address) 。
来看看书中是怎么说的:
使用虚拟寻址,CPU通过生成一个虚拟地址(Virtual Address,VA)来访问主存,这个虚拟地址在被送到内存之前先转换成适当的物理地址。将一个虚拟地址转换为物理地址的任务叫做地址翻译(address translation)。
就像异常处理一样,地址翻译需要CPU硬件和操作系统之间的紧密合作。CPU芯片上叫做 内存管理单元(Memory Management Unit,MMU) 的专用硬件,利用存放在主存中的查询表来动态翻译虚拟地址,该表的内容由操作系统管理。
图示:
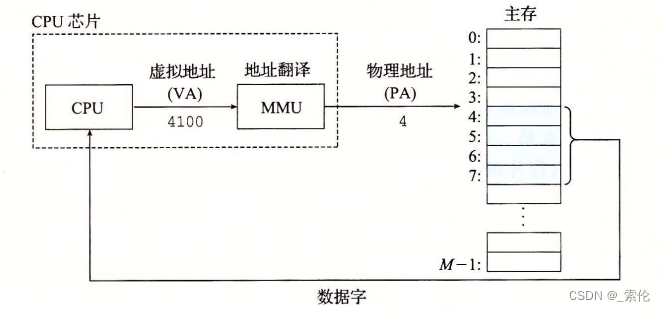
二、如何管理虚拟地址和物理地址?
主要有两种方式,内存分段和内存分页。
1. 内存分段
程序是由若干个逻辑分段组成的,如可由代码分段、数据分段、栈段、堆段组成。不同的段是有不同的属性的,所以就用分段(Segmentation) 的形式把这些段分离出来。
1.1 分段机制下虚拟地址和物理地址如何映射?
分段机制下的虚拟地址由两部分组成,段选择因子和段内偏移量。
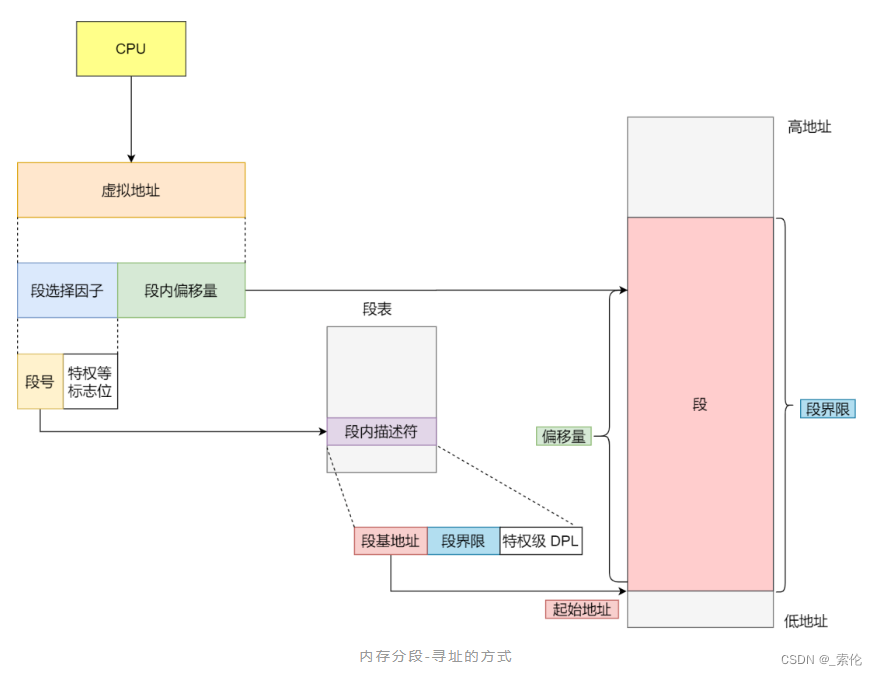
- 段选择因子就保存在段寄存器里面。段选择子里面最重要的是段号,用作段表的索引。
- 段表里面保存的是这个段的基地址、段的界限和特权等级等。
- 虚拟地址中的段内偏移量应该位于0和段界限之间,如果段内偏移量是合法的,就将段基地址加上段内偏移量得到物理内存地址。
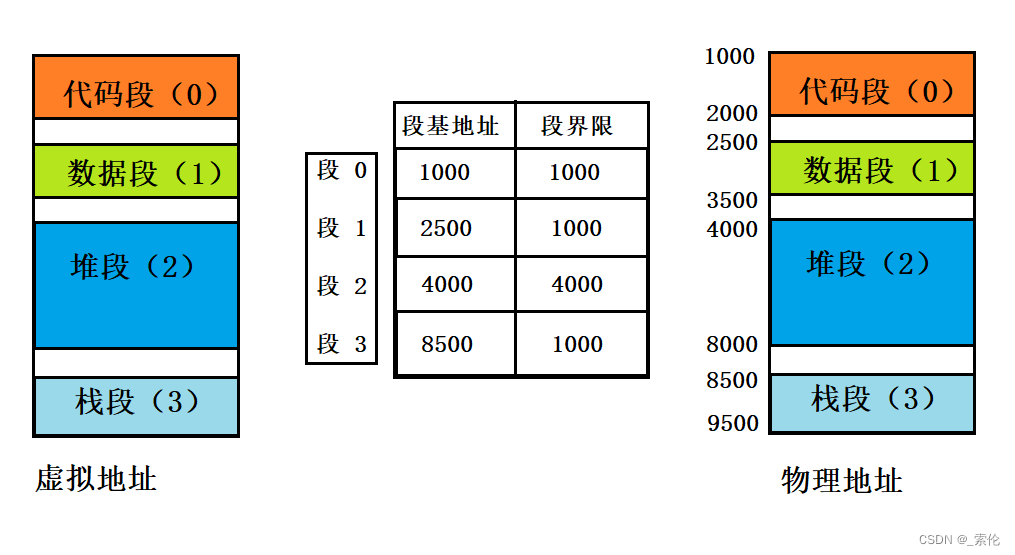
如果要访问段1中偏移量500的虚拟地址,可以计算出它的物理地址为段1基地址2500 + 500 = 3000.
分段方法的不足之处:
- 内存碎片
- 内存交换效率低。
1.2分段产生内存碎片问题
示例:假设有1G的物理内存,用户执行了多个程序,其中:
- 游戏占用了512MB;
- 音乐占用了128MB;
- 浏览器占用了256MB;
这时候如果终止了音乐这个进程,那么空闲内存还有256MB,但它们是不连续的,这时候就无法再创建一个占用200MB的进程。
图示:
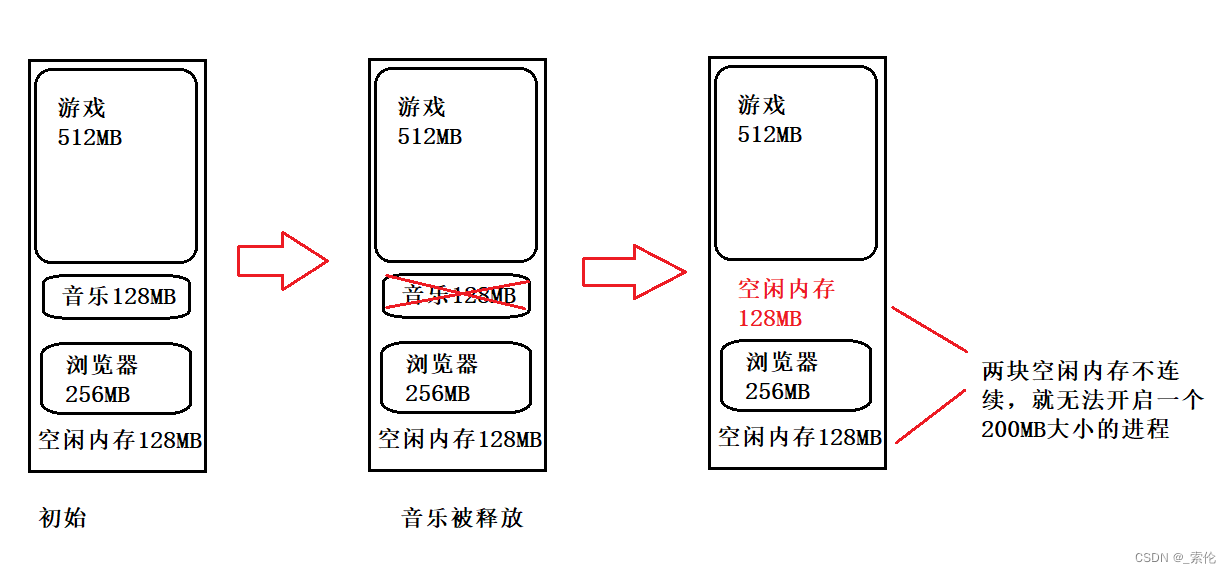
这里的内存碎片的问题共有两处地方:
- 外部内存碎片,也就是产生了多个不连续的小物理内存,导致新的程序无法被装载;
- 内部内存碎片,程序所有的内存都被装载到了物理内存,但是这个程序有部分的内存可能并不是很常使用,这也会导致内存的浪费;
针对上面两种内存碎片的问题,解决的方式会有所不同。
解决外部内存碎片的问题就是内存交换。
可以将浏览器程序占用的256MB写到硬盘上,再从硬盘上读回到内存上,这时候的这256MB回紧跟随着游戏程序所占用的512MB后面,空出来的剩余空间就是连续的。
1.3 分段为什么会导致内存交换效率低
对于多进程的系统来说,用分段的方式,内存碎片是很容易产生的,产生了内存碎片,那不得不重新Swap内存区域,这个过程会产生性能瓶颈。
因为硬盘的访问速度要比内存慢太多了,每一次内存交换,我们都需要把一大段连续的内存数据写到硬盘上。
所以,如果内存交换的时候,交换的是一个占内存空间很大的程序,这样整个机器都会显得卡顿。
为了解决内存分段的内存碎片和内存交换效率低的问题,就出现了内存分页。
2.内存分页
分段的好处就是能产生连续的内存空间,但是会出现内存碎片和内存交换的空间太大的问题。
要解决这些问题,那么就要想出能少出现一些内存碎片的办法。另外,当需要进行内存交换的时候,让需要交换写入或者从磁盘装载的数据更少一点,这样就可以解决问题了。这个办法,也就是内存分页( Paging) 。
分页是把整个虚拟和物理内存空间切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。在Linux下,每一页的大小为4KB。
虚拟地址与物理地址之间通过页表来映射,如下图:
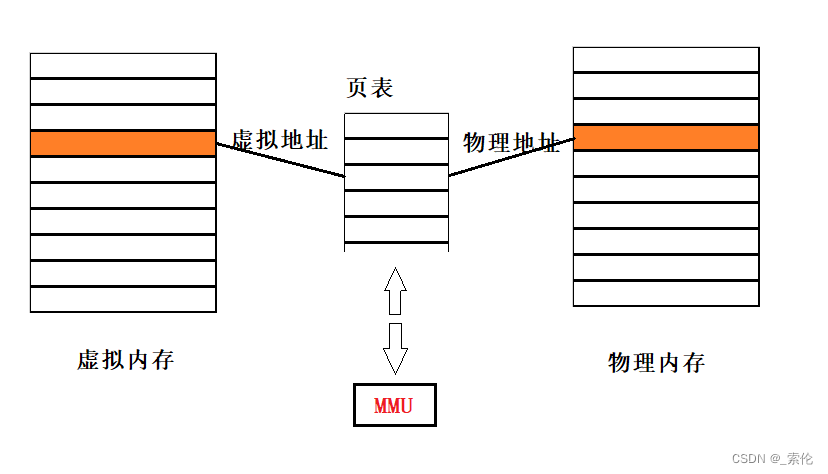
页表就是一个页表条目(Page Table Entry, PTE)的数组。虚拟地址空间中的每个页在页表中一个固定偏移量处都有一个PTE。
2.1分页怎么解决分段的内存碎片、内存交换效率低的问题
由于内存空间都是预先划分好的,也就不会像分段会产生间隙非常小的内存,这正是分段会产生内存碎片的原因。而采用了分页,那么释放的内存都是以页为单位释放的,也就不会产生无法给进程使用的小内存。
如果内存空间不够,操作系统会把其他正在运行的进程中的【最近没被使用】的内存页面给释放掉,也就是暂时写在硬盘上,称为换出(Swap Out)。一旦需要的时候,再加载进来,称为换入(Swap In)。所以,一次性写入磁盘的也只有少数的一个页或者几个页,不会花太多时间,内存交换的效率就相对比较高。
图示:
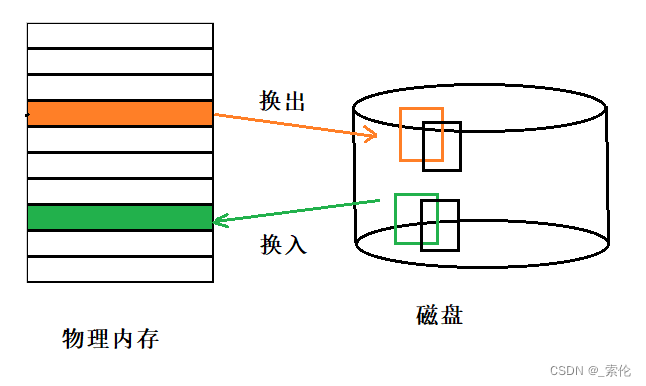
分页的方式使得我们在加载程序的时候,不再需要一次性都把程序加载到物理内存中。
我们完全可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,而是只有在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。
2.2 分页机制下虚拟地址和物理地址如何映射
在分页机制下,虚拟地址分为两部分,页号和页内偏移。页号作为页表的索引,页表包含物理页每页所在物理内存的基地址,这个基地址与页内偏移的组合就形成了物理内存地址:
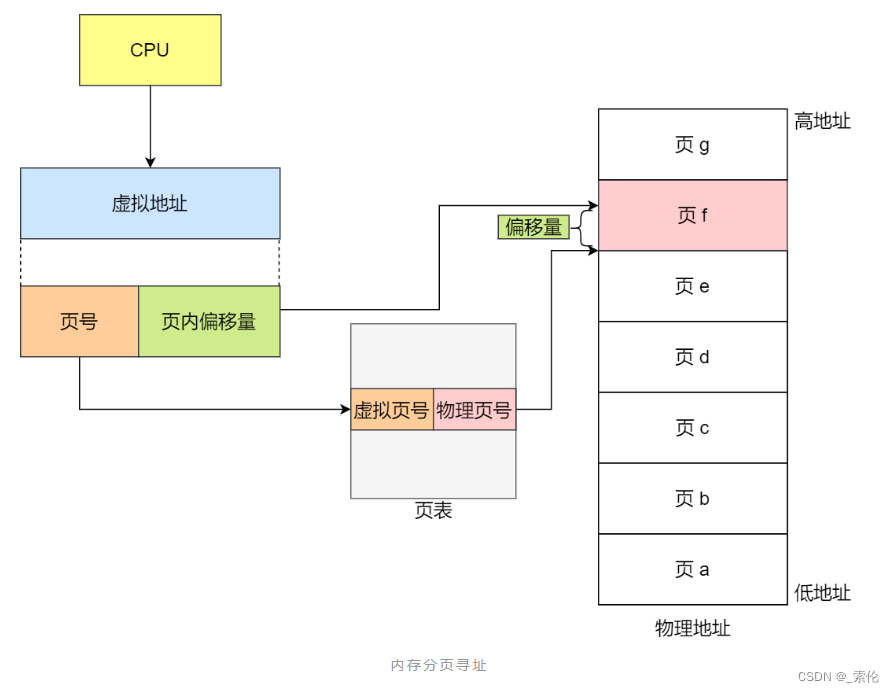
总结,对于一个内存地址转换,其实就是这样三个步骤:
-
把虚拟内存地址,切分成页号和偏移量;
-
根据页号,从页表里面,查询对应的物理页号;
-
直接拿物理页号,加上前面的偏移量,就得到了物理内存地址。
2.3 空间上的缺陷
因为操作系统是可以同时运行非常多的进程的,那这就意味着页表会非常的庞大。
在 32 位的环境下,虚拟地址空间共有 4GB,假设一个页的大小是 4KB(2^12),那么就需要大约 100 万 (2^20) 个页,每个「页表项」需要 4 个字节大小来存储,那么整个 4GB 空间的映射就需要有 4MB 的内存来存储页表。
这 4MB 大小的页表,看起来也不是很大。但是要知道每个进程都是有自己的虚拟地址空间的,也就说都有自己的页表。
那么,100 个进程的话,就需要 400MB 的内存来存储页表,这是非常大的内存了,更别说 64 位的环境了。
2.4 多级页表
要解决上面的问题,就需要采用的是一种叫作多级页表(Multi-Level Page Table)的解决方案。
在前面我们知道,对于单页表的实现方式,在 32 位和页大小 4KB 的环境下,一个进程的页表需要装下 100 多万个「页表项」,并且每个页表项是占用 4 字节大小的,于是相当于每个页表需占用 4MB 大小的空间。
我们把这个 100 多万个「页表项」的单级页表再分页,将页表(一级页表)分为 1024 个页表(二级页表),每个表(二级页表)中包含 1024 个「页表项」,形成二级分页。
如图:
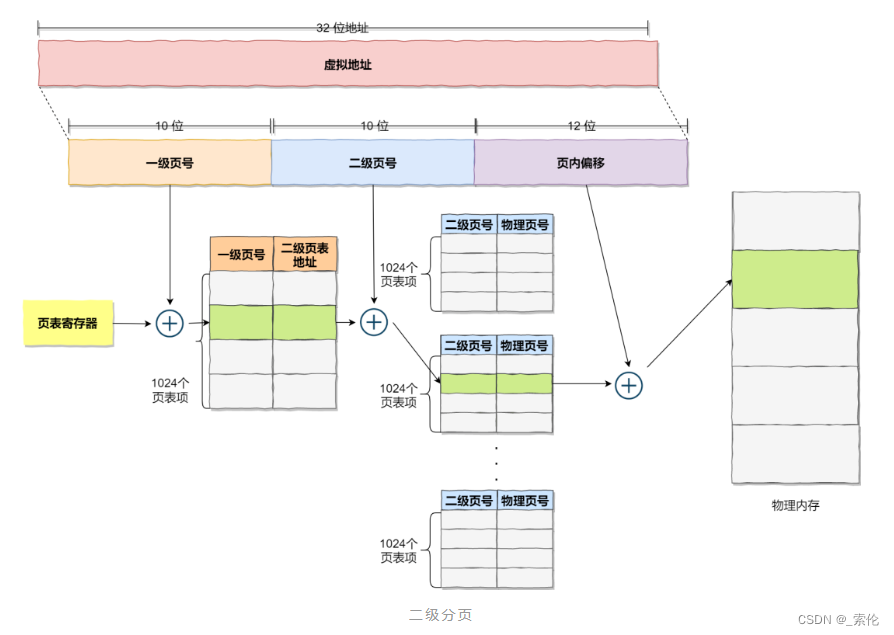
每个进程都有 4GB 的虚拟地址空间,而显然对于大多数程序来说,其使用到的空间远未达到 4GB,因为会存在部分对应的页表项都是空的,根本没有分配,对于已分配的页表项,如果存在最近一定时间未访问的页表,在物理内存紧张的情况下,操作系统会将页面换出到硬盘,也就是说不会占用物理内存。
如果使用了二级分页,一级页表就可以覆盖整个 4GB 虚拟地址空间,但如果某个一级页表的页表项没有被用到,也就不需要创建这个页表项对应的二级页表了,即可以在需要时才创建二级页表。做个简单的计算,假设只有 20% 的一级页表项被用到了,那么页表占用的内存空间就只有 4KB(一级页表) + 20% * 4MB(二级页表)= 0.804MB
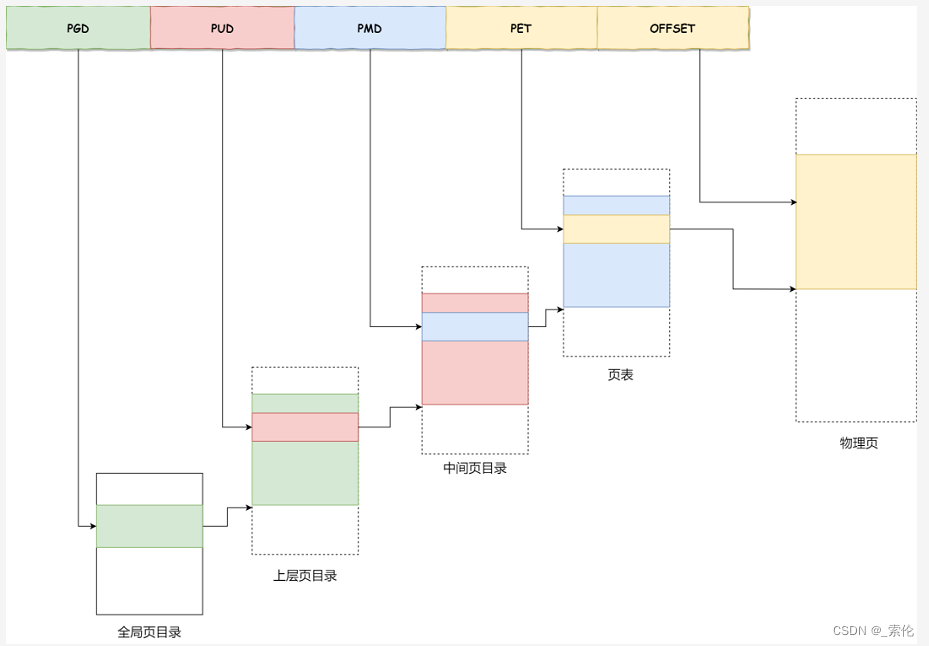
对于 64 位的系统,两级分页肯定不够了,就变成了四级目录,分别是:
-
全局页目录项 PGD(Page Global Directory);
-
上层页目录项 PUD(Page Upper Directory);
-
中间页目录项 PMD(Page Middle Directory);
-
页表项 PTE(Page Table Entry);
2.5 TLB
多级页表虽然解决了空间上的问题,但是虚拟地址到物理地址的转换就多了几道转换的工序,这显然就降低了这俩地址转换的速度,也就是带来了时间上的开销。
程序是有局部性的,即在一段时间内,整个程序的执行仅限于程序中的某一部分。相应地,执行所访问的存储空间也局限于某个内存区域。
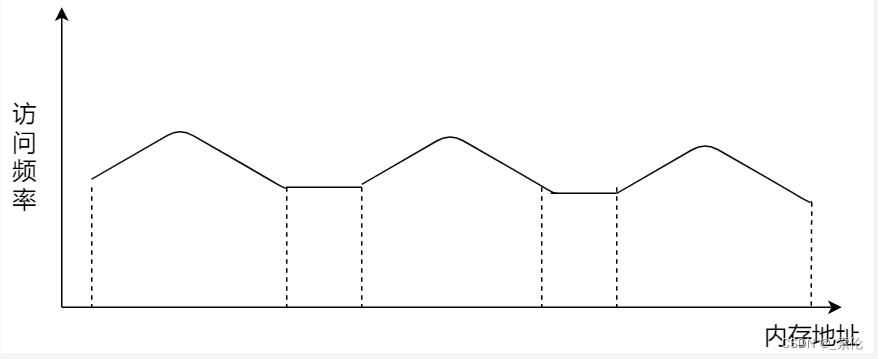
利用这一特性,把最常访问的几个页表项存储到访问速度更快的硬件,于是计算机科学家们,就在 CPU 芯片中,加入了一个专门存放程序最常访问的页表项的 Cache,这个 Cache 就是 TLB(Translation Lookaside Buffer) ,通常称为页表缓存、转址旁路缓存、快表等。
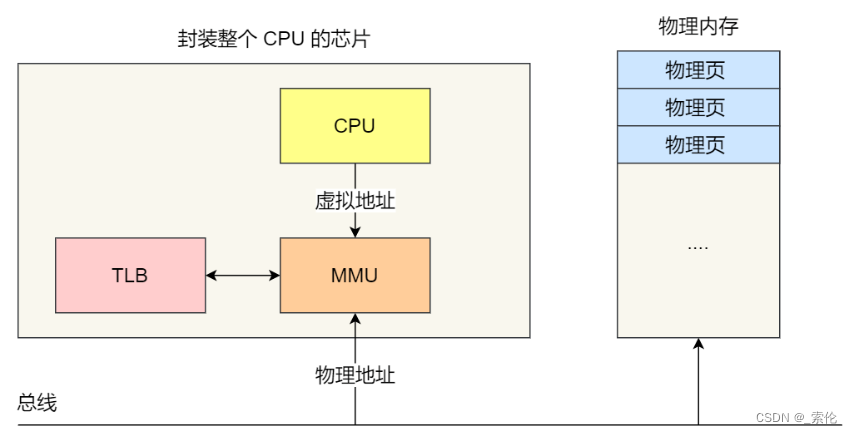
在 CPU 芯片里面,封装了内存管理单元(Memory Management Unit)芯片,它用来完成地址转换和 TLB 的访问与交互。
有了 TLB 后,那么 CPU 在寻址时,会先查 TLB,如果没找到,才会继续查常规的页表。
TLB 的命中率其实是很高的,因为程序最常访问的页就那么几个。
END
图文参考自小林coding

