
- 1Spring Security实现RBAC权限模型练习_rbac权限管理5张表
- 2Maven打包报错: NB: JAVA_HOME should point to a JDK not a JRE
- 3概率论知识复习_概率论复习
- 4超详细MySQL下载及安装、基本使用
- 5京东电商知识图谱与AIGC落地
- 6关于如何将Win幻兽帕鲁服务端存档转化为单人本地存档的一种方法(无损转移)_palworld-host-save-fix
- 7华为云云耀云服务器L实例评测|宝塔一站式安装数据库MySQL+Redis教程_华为云宝塔账号
- 8一个程序员的诗集【古诗篇】_程序员诗
- 9【057】百场网球比赛高清下载地址
- 10Windows Server2003系统安全设置_windows_serve...2003服务器安全设置技术
VMware vSphere 性能优化设计经验+优化方法 | 周末送资料_resxtop
赞
踩
VMware vSphere 性能优化设计经验+优化方法 | 周末送资料

本文包括两部分:第一部分“VMware vSphere 性能优化设计经验分享”介绍如何对VMware vSphere架构的CPU、内存、存储、网络及虚拟机进行性能调优,主要集中在物理层面的优化。第二部分“VMware vSphere 性能优化方法”包括vSphere 性能优化逻辑、针对 VM 的性能优化、针对 CPU 的性能优化、针对 RAM 的性能优化、针对 DISK 的性能优化、针对 Networking 的性能优化。
VMware vSphere 性能优化设计经验分享
【作者】张志强
前言
本文主要介绍如何对VMware vSphere架构的CPU、内存、存储、网络及虚拟机进行性能调优。将贯穿观念中那些有性能限制的领域,打消虚拟化和性能相悖的旧观念,最重要的是通过一个个小的案例展现如何在虚拟化环境中实现性能调优,让虚拟化技术发挥其最大优势,助力业务提升效率,按需扩展,灵活多变。
CPU性能优化
CPU资源的分配对于保证虚拟化环境的最佳性能很重要。现在的处理器一般为每个进程都配比了多核处理器,还提供了多种技术帮助提高虚拟化环境的性能,比如Intel-VT和AMD-V等硬件虚拟化及加速技术。CPU虚拟化技术使得虚拟机可以直接在物理处理器上执行大多数的指令,可以使多个虚拟机一起运行来直接访问一个物理处理器。
物理CPU与虚拟CPU之间的关系
在做CPU性能优化前,理解什么是物理CPU?什么是虚拟CPU?是个很重要的前提。目前几乎所有的处理器,无论X86架构还是Power架构,对每一个封装都有多个物理处理器内核。一般规格为4、6、8、12核,有的甚至更多。在VMware ESXi中,每一个物理处理内核被检测为一个物理CPU,如果Intel处理器上有超线程,那么每个物理处理器内核都会有两个硬件线程,ESXi就能检测到每个线程作为一个物理CPU。虚拟CPU是针对虚拟机上的CPU而言,每个虚拟机至少配置一个虚拟CPU。VMM调度每个虚拟CPU在任何可用的物理CPU上运行,可以定义任何虚拟机在给定时间内可以同时访问的物理CPU的数量。
ESXi CPU如何工作
VMware vSphere ESXi中的CPU通过复杂的调度算法接收和执行用户及外界的指令,按照设定好的策略依次执行,下面将介绍一下ESXi中CPU的几个主要的动作。
CPU的比例分配算法:
当发生在多个虚拟机之间竞争资源的时,ESXi则使用比例分配算法来决定哪一个虚拟机应该使用更多的CPU和内存资源。比例分配算法可以让VMware ESXi调度程序通过将每个执行语境在可用物理处理器资源的一个共享相关联,从而进行重要的调度计算。根据资源配置标准,如分享、保留、限制,所计算出的分享权益会被分配到每个执行语境上。
CPU联合调度:
我们常见的联合调度分为严格联合调度和宽松联合调度。这种严格联合调度主要出现在VMware ESXi的早期版本中,当执行联合调度时,CPU调度程序在多处理器虚拟机的每个微CPU上会有一个累积的偏移。当一个单进程应用在多处理器的虚拟机上运行时,只有一个微CPU在物理处理上运行,而其他的微CPU都处于闲置状态,因此,只需要要求一个物理CPU可用就可以了。
宽松联合调度主要出现在VMware ESXi5版本以后,使得每个虚拟机上的每个微CPU进程都可以被单独追踪,偏移值是通过测量最慢的微CPU和其他每个微CPU之间的差异得到的。
ESXi的CPU性能调优
众所周知,VMware是虚拟化领域的领头羊,其为ESXi虚拟化层提供的默认设置在性能方面可以满足大多数企业的应用场景和需求。对于更严苛的业务需求,采用默认设置可能会影响虚拟化发挥其最大的优势。如何调优,就成了管理员必备的要求。
CPU性能如何诊断?哪些指标是性能调优最在意的?可以帮管理员尽快定位问?VMware在众多管理指令中提供了一个名为ESXtop的命令。通过输出结果可以清晰的看到CPU等相关的性能问题。管理员通过root身份登陆ESXi服务器,并输入C切换到CPU的分析界面。除了CPU可以监控CPU之外,也可以对内存、网络等性能进行观察。具体的使用方法,不在此文的讨论范围内。
表1:VMware esxtop CPU性能指标表
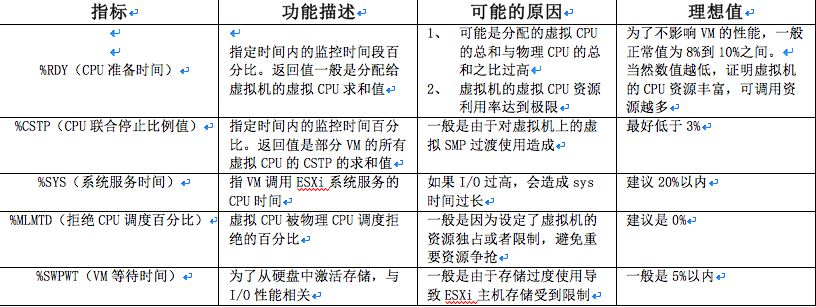
内存性能优化
内存的运算速度要比硬盘快很多,所以通常情况下,内存越大,服务器的应用速度较快。所有ESXi作为VM的载体,必然需要大内存的支持。那么在进行内存性能讲解之前,先介绍一些ESXi中内存的分层。
-
虚拟主机的物理内存
这个是指实际物理主机的物理内存,比如一台物理内存微256G的服务器,那么其实际物理内存就是256G;
-
虚拟机的物理内存
这个是指管理员实际分配给虚拟机使用的内存,可以被虚拟机直接调用的内存,仅仅对分配的虚拟机可见;
-
虚拟机的虚拟内存
这个是指虚拟机操作系统分配给应用程序的可用内存,这是虚拟机操作系统映射到虚拟机物理内存的地址空间;
ESXi内存如何工作
那么ESXi虚拟化软件是如何管理硬件的物理内存的呢?使其可以同时运行多个虚拟机,并且内存之间相互隔离,保证数据的稳定性和可靠性。
首先ESXi会将所有的物理内存虚拟化,为其上运行的不同的虚拟机创建一个个连续的虚拟内存地址空间。这些内存地址空间映射到虚拟机的物理内存,形成不同的内存空间。内存空间之间相互隔离,确保虚拟机内容的独立性和安全性。所有物理内存的分配调用,都需要ESXi来进行管理。特别需要注意的是,在向虚拟机分配物理内存前,ESXi管理程序会将主机物理内存置零,避免主机上不同虚拟机之间的信息泄漏,引起页面错误。
内存回收
虚拟化中的内存回收是个很专业的话题,技术难度也很高,目前仅有VMware实现了内存过量功能的管理。为了实现内存的回收,VMware主要通过以下几种方式进行,不同的环境采用不提供的方式,避免性能出现瓶颈,影响虚拟机的正常运行。
-
透明页共享
透明页共享(TPS)是主机物理内存回收的一种简单而有效的方式。原理是将相同镜像或者应用的内存冗余页做成单一的共享页面,只保留一个内存页的副本。因此,虚拟机主机内存占用总量减小,可以提供更多的内存给不同页面的虚拟机,从而也实现了内存过量。
-
内存膨胀
为了实现内存膨胀,需要每个虚拟机安装VMware Tools,以为Tools内置了内存膨胀驱动来实现这一功能。当ESXi物理内存处于高压状态,就会触发内存膨胀机制来收回内存。管理程序会通知虚拟机上的内存膨胀驱动,给超过阈值的虚拟机分配“空闲的”虚拟机物理内存页去扩大内存。当然默认是没有启用的,启用此功能会在一定程度上影响虚拟机的性能。
-
内存压缩
ESXi通过内存压缩技术可以将一部分本该分页到磁盘的虚拟机内存也进行压缩。压缩的内存页存储在虚拟机主内存的压缩高速缓存中。当检测到内存页压缩比率低于50%时,该内存页不会被压缩,而是通过管理程序内存交换交换到磁盘,ESXi只会使用管理程序交换未压缩的内存页,不会把已压缩的内存页交换到磁盘。
-
管理程序内存交换
在VM的配置文件中,有个后缀名为.vswp的文件,这个就是内存交换文件。通过此方法,ESXi可以将供给虚拟机使用的物理内存与物理磁盘设备进行交换,以达到释放内存的目的。此文件在虚拟机启动的时候即被创建,文件大小与虚拟机的内存 一样。
ESXi的内存性能调优
控制内存的占用比例即使用率,是保证VM及主机稳定、性能优越的前提条件。ESXi内置了内存性能调优工具-ESXtop。虽然VMware支持内存过量技术,但是建议不要随便使用,毕竟过量会引发内存膨胀及内存交换,影响虚拟机的整体性能。
表2:VMware esxtop内存性能指标表


存储性能优化
我们在设计虚拟化架构的时候,除了考虑CPU、内存、网络等因素外,更要对存储进行精心设计。不同的业务需求,对存储的类型也是有不同的要求。因为存储平台不同,意味着使用的协议和存储的特点也就不同。速度并非是选择合适存储的唯一条件,如协议、连通性、现有的基础设施和费用都要总和考虑。目前存储主要分为以下三种类型:
-
存储区域网络
简称SAN,是一种提供块级存储设备的专用网络。主机与存储之间通过光纤进行连接,多采用光纤交换机进行接口对接。SAN提供了一个存储中心,与其配合使用,淡化了本地存储的功能。主要协议有互联网小型计算机系统接口(ISCSI)、以太网光纤通道(FCoE)及光纤通信(FC)。
-
网络文件系统
除了块存储,ESXi也支持与网络文件系统(NFS)的连接共享以存储虚拟机和相关模板。主要通过网络传输,不需要购买额外的HBA卡。
-
虚拟SAN
又称VSAN,此概念是VMware在vSphere5.5以后推出的一个新特性。去除了使用NFS和SAN的限制,同时又保证了数据的高可靠性。通过将ESXi本地磁盘聚合在一起并将共享数据存储呈现给ESXi主机。支持横向及纵向灵活扩展,也是VMware近期主推的存储架构。
如何设计物理存储
合理的设计和选型物理存储是虚拟化解决方案成功的重要环节。存储设计的好坏,直接影响整体虚拟化环境的性能好坏。存储的类型、RAID的配置、网络和很多其他方面都会对虚拟化环境的性能产生很大影响,以下是对共享存储的设计建议:
-
业务需求
技术永远是为业务服务的,任何优秀的架构设计都需要对业务需求理解透彻,否则做出来的架构将不具备任何价值。所以业务需求的确定是着手设计的第一步。
-
RAID级别
又称磁盘冗余阵列,不同的RAID级别,可以满足不同等级的业务需求。简单的说,RAID是一种将多个物理硬盘驱动器整合并作为一个或多个逻辑驱动器呈现的技术。主流的RAID级别有,0、1、5、、10等。数字越高,其安全等级越高,防止数据丢失能力越强。
-
固态盘的使用
随着技术和硬件的不断发展,硬盘的类型也得到了扩展。从之前的机械硬盘,到现在的固态硬盘和纯闪存盘。速度越来越快,I/O吞吐越来越大。并不是说在整体的存储架构中,哪种盘一定好,为了获得最大的性能,一定要结合业务需求,合理搭配使用。对于永久数据的保存,建议使用机械硬盘。但是对于缓存区域和热数据区,建议采用SSD或者Flash disk。
-
IP存储网络
IP网络存储技术完全依赖于以太网的传输。在某些情况下,我们也要考虑结合IP存储网络来进行架构的非关键组件的弥补。从成本考虑,光存储网络和SSD等硬件虽然速度快,但是成本较高。例如ISO等镜像问题,由于不是经常调用,可以存放于IP网络存储中,采用NFS或者ISCSI进行呈现。
如何设计虚拟存储
VMware的VSAN不同于其他我们熟知的存储,既不是NFS也不是VMF,它是vSphere 5.5版本以上才有的一种虚拟SAN存储。它通过整合所有ESXi计算节点的本地硬盘资源,创建一个可以被集群中所有ESXi共同访问的逻辑数据存储。虚拟机文件等其他数据可以在主机之间复制,使得单个主机损坏,不会发生单点故障,影响业务正常。当然VSAN也有一些注意事项,避免性能瓶颈:
-
固态盘
VSAN中的每个存储组必须有一块SSD盘来创建数据存储,而且要求有一个能够直通的硬盘驱动控制器,可以将每个单独的磁盘驱动数据提交给vSphere。其中SSD主要作为缓存层,一般SSD与机械盘的比例是1:10。
-
存储策略
VMware将VSAN定义为软件定义存储,通过定义存储策略对存储资源进行管理。通过策略管理员可以定义一组特点的可用性、性能和大小的要求并允许vSphere在部署新的虚拟机的时候管理VMDK的位置和选择正确的数据存储。
-
网络
由于是通过以太网进行连接,所以VSAN依靠同步复制在各个ESXi主机中复制数据,从而对网络的要求较高。因为其对延迟的容忍度很低,网络延迟的增加,可能会导致严重的性能下降。强烈建议采用至少10G网络负载ESXi之间的复制压力。
ESXi的存储性能调优
网络性能优化
网络性能的好坏直接影响用户最终的体验。虚拟化的所有数据传输,几乎都是通过网络进行的。用户对数据提取,主机与主机之间的数据复制等。越是复杂的网络,越要精细化设计,做好合理的规划,否则一旦投入生产使用,就会带来很多不必要的麻烦。
ESXi的网络设计
ESXi的网络设计主要分为两种,物理网络设计和虚拟化网络设计。不同的层次网络设计,需要配置的和支持的团队也不同,一般物理网络的设计主要是由公司的网络部门负责,而虚拟化网络一般是云计算团队负责。
物理网络设计:
-
在网络设计的过程中,应该确保每一条网络路径都应该是冗余的,避免单点故障。
-
确保主机与主机之间的复制通道具备足够的带宽,避免大流量造成数据延迟。
-
确保具备足够的物理网络上行链路,以提供网络隔离和环境要求的冗余。
-
确保数据网络、Kernel和管理网络的隔离。
虚拟化网络设计:
主要分为标准交换机和虚拟交换机,行业中一般较小的环境建议采用标准交换机,较大的环境建议采用分布式交换机。因为分布式交换机在可扩展性、功能性以及向后延续性都优于标准交换机。
标准交换机:
-
标准交换机是VMware最早的虚拟交换机,也是单机版交换机。每个主机的所有出入流量都要经过标准交换机,需要更多的管理开销。
-
适用于小规模的部署。
-
确保每个主机上每个vSwitch的部署和配置是一致的,避免虚拟机飘移后,网络无法通信。
分布式交换机:
-
适合大规模的部署,因为其实现了集中配置和管理,使主机设置更加统一。也是VMware平台的网络增强版。
-
合理使用网络I/O控制
-
分布式交换机具备后期延伸的优势,提供负载均衡策略。
ESXi的分布式交换机
其实如何选择虚拟交换机完全取决于各自的业务需要。但是随着VMware的更新技术的发展,越来越青睐分布式交换机的应用,尤其是大环境的部署与应用。那么我们在部署分布式交换机的时候可以得到哪些提高性能的好处呢?
-
具备较好的向后扩能力,否则VMware技术的发展路线
-
支持NIOC功能,实现不同虚拟机使用不同网络资源的管理。尤其是在SDN中应用较广,实现多个功能共享较少的网卡。
-
提供负载均衡功能,能够有效的均衡跨物理网卡的流量负载。
-
提供Netflow和LLDP的管理功能,当虚拟化关键业务的时候,这个功能就显得尤为重要。
ESXi的网络性能调优
在以往的虚拟化环境管理工作中可以发现,绝大多数的性能问题主要来自于CPU、内存和存储,网络引发的性能瓶颈几乎没有。但是随着SDN、NSX等技术的出现,对网络的要求是越来越高,网络的优化也就越来越重要。
ESXi主机层面性能优化
通过多年的工作经验积累得出,好的网络性能应该从ESXi主机层次开始。
-
首先选择合适数量网卡的主机以保证冗余和性能。
-
虚拟交换机的负载均衡策略可以有效的对网卡之间的流量进行负载,避免单块网卡的流量瓶颈。所以建议无论在大与小的环境,尽量采用分布式交换机。
-
如果网络吞吐量增加,那么建议对ESXi的主机CPU也要进行增加。因为吞吐越大,需要的CPU处理量也就越大。
-
合理使用网络I/O控制功能,采用共享而不是阈值来控制网络流量。因为阈值是设置可以使用的最大限。而共享是依靠策略,通过优先级方式,对关键虚拟机进行流量优化。
-
vMotion的流量建议采用单独的网卡进行隔离,避免与其它的流量冲突。迁移的流量和FT的流量都会使用kernel的网卡。
虚拟机层面的性能优化
-
在所有的虚拟机中安装VMware tools,选择使用VMXNET3增强型虚拟网卡,因为其提供了更高级的功能,比如巨型帧、接收端收放等等技术。
-
将有关联的虚拟机尽量放在同一个ESXi主机上,因为相同主机的网络是通过内核传输,速度实现最大化。但是并不是说,VM就不用做备份或者异地部署了,还是要依据业务的实际应用来分。
-
对于那些要求网络延迟较小的应用,需要调整VMware高级设置中的网络延迟敏感度,满足业务需求。当然,默认的设置已经可以满足大多数的用户的应用场景。
结束语
以上主要阐述了VMware在CPU、内存、存储和网络方面的性能优化。当然一个成熟的虚拟化架构方案,不仅要考虑以上几种场景,还要对虚拟机本身的CPU、内存、存储、网络进行微调。本文主要集中在物理层面的优化。有兴趣的朋友,可以从VMware vSphere的官方找到相关的优化细节。
VMware vSphere 性能优化方法
本部分由社区会员分享,相关著作权归原作者所有
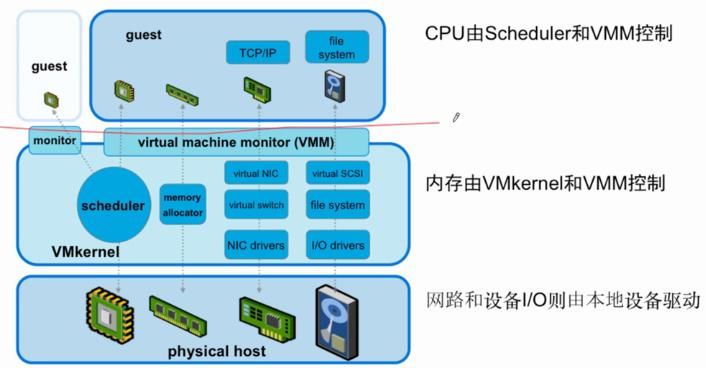
一、vSphere 性能优化逻辑
1 、虚拟化逻辑分层示意图
2 、X86 结构下虚拟化的问题
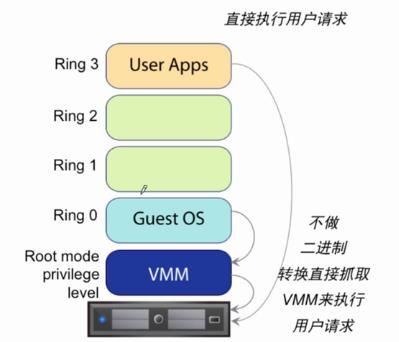
• X86 的 os 通常直接运行在物理硬件层面,因此它的执行权限必须为 ring 0.
• X86 虚拟化架构则要求 os 运行在虚拟化层级上面

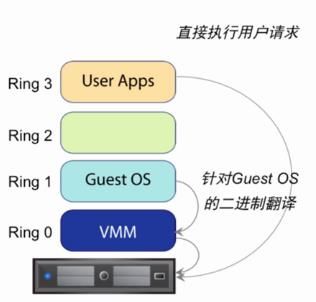
3 、CPU 软件虚拟化
• 二进制转换是最原始的 32bit x86 虚拟化的指令结构
• 利用二进制转换,就可以实现:
o 让 VMM 单独运行在 ring 0,保证相对独立与性能
o 让 Guest OS 运行在 ring 1.
o 让 Applications 运行在 ring 3.
4 、CPU 硬件虚拟化
• CPU 硬件虚拟化使得 VMM 运行虚拟机变得更加简单
• CPU 硬件虚拟化允许 VMM 不依赖二进制转换依然能够完全控制虚拟机
• 包括以下两种
o Intel VT-x
o AMD-v
5 、Intel VT-x 和 和 AMD-v
• 两者都是 CPU 的一种指令执行模式,它们的主要功能如下:
o 允许 VMM 运行在 ring 0 之下的 root mode
o 自动的通过 hypervisor 来获取权限和灵敏度级别
o 存放 Guest OS 在虚拟 CPU 控制架构中的状态
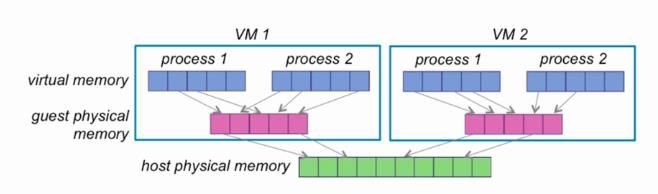
6、内存工作示意图
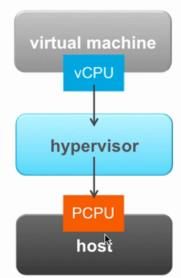
7 、虚拟环境性能分析
• 第一维度:
o 单台物理服务器上的单台虚拟机
• Hypervisor 位于物理设备与虚拟机之间
o 影响性能的重要因素
• VMM overhead
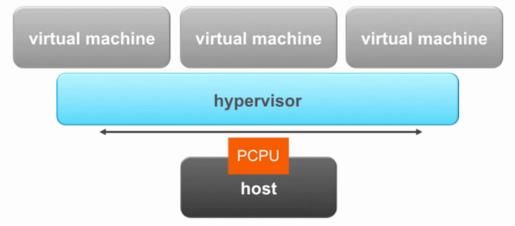
• 第二维度:
o 单台物理机上运行多台虚拟机
• Hypersior 位于物理设备与虚拟机之间
o 影响性能重要因素
• 调度开锁以及网路、存储、计算资源不足等问题
• 第三维度:
o VMware vSphere Distributed Resource Scheduler:
• 降低第二维度中可能存在的部分性能问题
o 影响性能的因素
• 高频次的 vMotion 动作
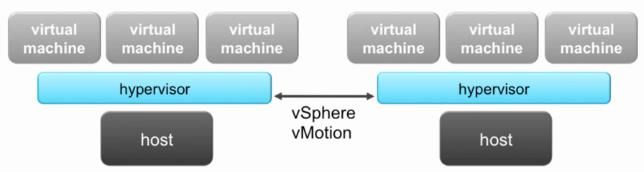
8 、vSphere 环境中影响性能的因素
• 硬件层面:
o CPU
o Memory
o Storage
o Network
• 软件层面:
o VMM
o Virtual Machine 设定
o Applications
9 、关于性能的最佳实践
10 、常见的性能问题
• 通常,性能问题都应该是在进行综合性能定义、管理的过程中出现的
• 综合所有产品的性能问题而言,性能问题通常体现在如下方面
o 应用程序无法满足 Service-Level Agreement
o 应用程序无法满足预先规划的性能浮动范围
o 用户反馈性能故障或吞吐不足
11 、性能问题排错方法论
• 排查性能问题和排查故障问题很多时候都是相似的,或者说:性能问题与故障问题的界限其实是很模糊的,因此都需要遵循类似的方法论,才能比较有效的进行排查
• 根据前辈们和厂家总结的经验,通常都建议参考如下 逻辑来定义故障
o 故障的体现形式是什么?
o 从哪里着手开始查找问题?
o 如何确定怎样检查问题?
o 是否确认找到问题就是真正意义上的问题所在?
o 想要针对性解决这个问题,需要做些什么
o 如果处理之后问题依然存在,接下来该怎么办?
12 、针对 ESXi Host 的 的 Checklist

13 、vSphere

二、针对 VM 的性能优化
1 、VM 性能相关概览
• 经过精细化配置、调校后的 VM 将会为 Applications 提供一个最好的运行环境
• 通常考虑 VM 的性能相关的参数包含下列几个选项
o Guest OS
o VMware Tools
o CPU
o Memory
oStorage
o Network
2 、首先选定合适的 OS 类型
• 在创建 VM 时,一定要正确选择 Guest OS 的类型
• Guest OS 类型会决定缺省的最优化硬件以及配套的设定
3 、保证好 Guest OS 的时间
• VM 里的时间计算逻辑会导致 Guest OS 的时间要想保持准确性是很重要的
• 规避这种可能性的方式
o 尽量选择需要较小时间中断的 Guest OS
• 大多数 Windows、Linux 2.4:100 Hz(每秒 100 个中断计数)
• 大多数 Linux 2.6: 1000 Hz
• 最新的 Linux:250 Hz
o NTP Server 是最好的方法
• 无论如何,别用 2 种以上的时间同少方式
4 、VMware Tools
• 被用于提升 VM 的性能和可管理性
• 保持 VMware Tools 为最新版本
• 确保 VMware Tools 是处于正常被 激活状态的,如果没有被激活,则请激活它

5 、Virtual Hardware 兼容性
• Virtual Hardware 兼容能力丐 ESXi Host 的版本有关系,高版本,低版本的 Virtual Hardware 的功能、性能兼容级别都不同
o 它会影响着 VM 的性能
o 正常状态下只能升级,不能降级
o Virtual Hardware 版本可以向下兼容
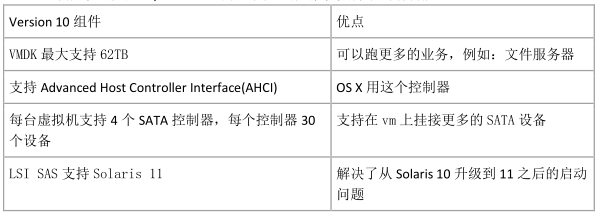
6 、Virtual Hardware v10
• 这个版本出现在 vSphere 5.5 当中,其上的虚拟机支持下列新功能
7 、针对 CPU
• 除非运行在 OS 里的 Applicantion 有这个需求,否则尽量避免使用 vSMP
o 激活了 SMP,则进程可能会被 跨 vCPUs 进行迁移,会导致额外的开销
• 如果有选择,最好是使用 OS 缺省的建议配置
8、关于 vNUMA 的使用
• vNUMA 允许 NUMA-aware 的 Guest OS 和 Application 通过硬件层的 NUMA 架构来提升资源利用效率
• vNUMA
o 要求 virtual hardware v8+(ESXi 5.0+)
o 当 vCPUs 数量超过 8 个时自动激活
o 可以在 vSphere Web Client 里激活或禁止
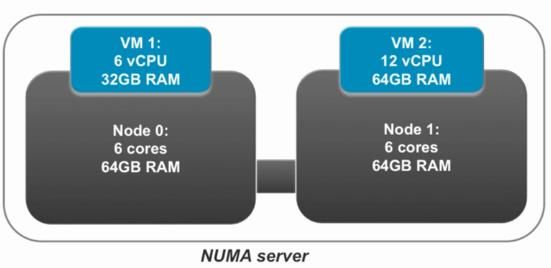
9 、针对 Memory 这部分的考量
• 大内存页面状态下:
o ESXi 可以支持 2MB 的内存页面给 Guest
o 大内存页面内存的使用会降低内存管理开销且能够变相提升 hypervisor 性能
• Transparent page sharing 组件是唯一的 overcommitted
o 如果 Guest OS 或 Applications 能够 handle 的话,建议使用大内存页面
• 为 VM 的交换文件单独找个地方存放
o 在 SSD 上配置 Host Cache 用作存放 swap-to-host cache
o 如果主机没用 swap-to-host cache 功能则建议存放在本地磁盘或远程 SSD 空间
o 尽量不要将交换文件存放在 Thin 模式下的 LUN 上面
10 、针对 Storage 这部分的考量
• 选择好合适 Guest OS 的硬件类型
o BusLogic 或 LSI Logic
o VMware Paravirtual SCSI(PVSCSI)适配器
• 针对 I/O 敏感类型业务选用
• PVSCSI 是一个和 BusLogic 和 LSI Logic 相似的部件,但是它是一个低 CPU 开销、高吞吐、低延迟和更好扩展能力的控制器类型
o Guest OS 队列深度适中
o 对齐 OS 的分
11 、针对 Network 部分的考量
• 如果有的选择,尽量使用 vmxnet3 这款虚拟网路卡:
o 如果不支持 vmxnet3,则可以退而求其次选择 Enhanced vmxnet
o 如果 Enhanced vmxnet 也不支持,可以选择 flexible 类型
• 尽量选择支持主机物理卡高性能功能组件的虚拟网路卡,例如 TCP checksum offlad,TSO 和 Jumbo Frames 等
• 确保物理网路卡运行在全双工模式和最高速状态
12 、开启 VM 的建议
• 在虚拟机开启和成功启动前,会消耗大量的资源
o CPU 和 Memory reservations 必须要得到满足
o 需要足够的磁盘空间用于存放下面 2 个 vswp 文件
• *.vswp
• vmx-*.vswp
o 如果为 vm 配置了 vSphere Flash Read Cache(vFRC),则还需要足够的 SSD 磁盘
13 、开启 VM 的 CPU 和内存预留
• 为了顺利开启 vm,ESXi Host 必须要有大量的 CPU、内存资源用于满足虚拟机的启动。当然,还需要包含启动这台虚拟机所需要的额外 Memory 开销
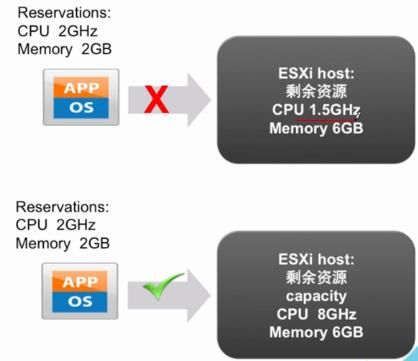
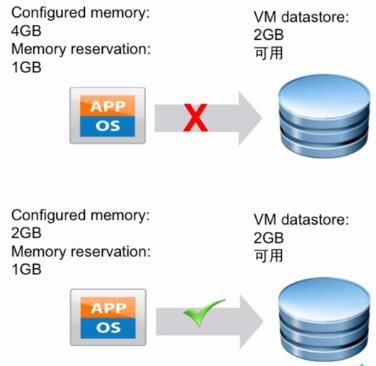
14 、针对 VM 的 的 Swap 文件存放建议
• 想要成功开启 VM 还需要有足够的存储空间存放 swap 文件
o *.vswp 交换文件的大小取决于虚拟机已配置的内存及预留值
o vmx-*.vswp 交换文件的大小取决于虚拟机的 Overhead Memory 和 Vmkernel 的 Reservation
15 、开启 VM 的 的 vSCSI 类型建议
• 要想成功启动 VM,Guest OS 必须要支持 SCSI Controller
• SCSI Controller 的选择可以在创建时和创建后去修改
• 创建虚拟机的向导中,会根据 Guest OS 类型不同而设定不同的默认建议选择
16 、VM 性能最佳实践
• 在创建 vm 时,选择合适的 Guest OS 类型
• 把不必要的设备,例如:USB, CD-ROM, 软驱等删除
• 仅仅在 Applications 支持 Multi-Threaded 时才配置 SMP
• 为 Guest OS 配置好时间同步
• 务必为 vm 安装 VMware Tools 并且保持为最新版本
• 建议使用最新的 Virtual Hardware 版本
• 针对大 I/O 类型的业务,需要考虑清楚,因为它会导致 Guest OS 的 I/O 性能受到影响
• 做好对 Guest OS 的分区对齐
• 尽可能使用 vmxnet3
三、针对 CPU 的性能优化
1 、World 概念概述
• 基本上,可以将 World 理解为 CPU 上调度的执行任务
o World 就好像是传统 OS 里的进程一样
• 所以,VM 就相当于一级 worlds 的集合
o 一个用于每个 vCPU
o 一个用于虚拟鼠标、键盘、屏幕(MKS)
o 一个用于 VMM
• CPU Scheduler 会选择将 World 调度到对应物理 CPU 或 core 上
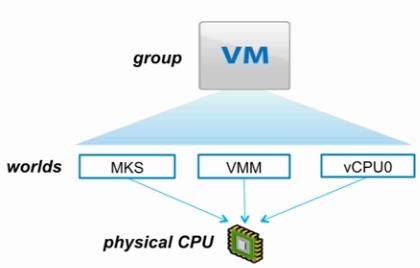
2 、CPU Scheduler 组件
• CPU 资源的分配对于用户而言是动态和透明的
o 将 vCPUs 调度到物理 CPUs 上
o 每 2 ~ 40ms 会检查一次物理 CPU 的使用情况,然后按需去迁移 vCPUs
• 针对 CPU 的使用情况,强制采用 proportional-share 算法
o 每当 CPU 资源 overcommitted,则主机会在所有的 VMs 上执行物理 CPU time-slice
o 每个 vCPU 在调度时,会按照资源设定的优先级别去调用
3 、CPU Scheduler 组件:VM SMP 相关
• VMware ESXi 使用 co-scheduling 表来优化虚拟机 SMP 的效率
• Co-scheduling 的工作原理将同一时间的 CPU 调度请求分散到不同的物理 CPU 上
o 每一颗 vCPU 都会随时可能 Scheduled、Descheduled、Preempted、Blocked 等
• 在 SMP 虚拟机里发生 vCPUs 调度时,CPU Scheduler 可能会导致调度不均衡的问题
o 两颗以上的 vCPUs 的 SMP 虚拟机在调度到不同的 CPU 上时可能存在不同的执行速率,所以会不均衡
o 当除了某个 vCPU 外,整体的 vCPUs 的调度并没有完整执行,vCPU 的不均衡程度会加剧
o 当 vCPU 不均衡比例超过一定比例之后,也会被判定为不均衡
4 、CPU Scheduler 组件:Relaxed Co-Scheduler
• 该组件技术表示检测到不均衡之后同时调度大量虚拟机 vCPUs 的技术
o 减少虚拟机 Co-start 对物理 CPUs 数量的要求
o 增加 CPU 的利用率
• 针对 idle 的 vCPU 不存在 co-scheduling 的开销部分
5 、CPU Scheduler 组件:Processor topology
• CPU Scheduler 使用 Processor topology 信息来优化 vCPUs 在不同 Sockets 的位置存放选择
• CPU Scheduler 会尽可能在所有的 Sockets 上去分布负载,以便充分利用可用的 Cache
o 单 Socket 里的 Cores 通常会使用共享的 Last-Level Cache
o 使用共享的 Last-Level Cache,可以在内存敏感业务上提升 vCPU 的性能
• 当 SMP 虚拟机在 vCPUs 之间表现出明显的数据共享时,则依托缓存分布的方式将会是退而求其次的负载分布方式
o 可以通过在 vmx 文件里增加 sched.cpu.vsmpConsolidate= "TRUE"这行参数来覆盖掉缺省的调度逻辑
6 、CPU Scheduler 组件:NUMA-aware
• 在 Non-Uniform Memory Access(NUMA)主机上都会有直边到 1 个或多个本地内存控制器的 CPU 来提供本地内存:
o 同一台物理服务器上,通过本地内存访问 CPU 的进程效率会高于远程内存
o 当虚拟机的内存分布中大部分不在本地内存是,就意味着此时的 NUMA 性能是较差的
• NUMA scheduler 限制 vCPUs 到单一的 Socket 上,以便充分利用缓存

7 、Wide-VM NUMA Support
• Wide-VM 表示虚拟机拥有超过 NUMA 节点所有 Cores 的 vCPUs 数量
o 例如:1 台 4 vCPUs SMP 虚拟机可能分布在 2 Scokets, 2 Cores 的环境
o 只有当 Cores 的数量满足才不算 Wide-VM(HT 不算)
• 1 台 8 vCPUs 虚拟机可能 分布在 2 Scokets, 4 Cores 系统上,跃然激活了 HT,不过由于每个 NUMA 节点的 CPU 只有 4 Cores,所以,算作 Wide-VM
• Wide-VM NUMA 支持将 Wide-VM 分割到更小的 NUMA Client 环境里
o Wide-VM 为每个 Client 分配一个 Home Node
• 例如:1 台 4 vCPUs SMP 虚拟机运行在 2 Socket, 2 Cores 的系统时,会有 2 个 2 vCPU NUMA Clients;1 台 8 vCPUs SMP 虚拟机运行在 2 Sockets, 4 Cores 的系统时,会有 2 个 4 vCPU NUMA Clients.
o Wide-VM 由于包含多个 Clients,所以存在多个 Home Nodes,每个 Client 都有自己的 Home Node
8 、Wide-VM NUMA Support 的性能影响
• 以 1 台运行在 2 Sockets, 4 Cores 主机上的 8 vCPUs SMP 虚拟机为例(在这案例中,Wide-VM NUMA 支持与否都不影响性能) :
o 假设是 Uniform Memory Access, 大约 50%的内存在 Local,因为如果不用 Wide-VM NUMA Support, 则会有 2 个 Home Nodes
• 以 1 台 4 Sockets, 2 Cores 系统为例,只有 25%左右的内存在 Local(这样一来,性能就会比直接访问好 1/2 左右) :
o Wide-VM NUMA support 则相当于变相提升 50%的本地内存访问比例
9 、影响 CPU Performance 相关因素
• Idling virtual machines:
o 主要是 Gues 需要的 Time Interrupts 开销
• CPU affinity
o CPU affinity 则会限制 Scheduler 并且会导致负载不均衡
• SMP virtual machines
o 会产生 Co-Scheduling 的开销
• CPU 资源不足时的资源调度逻辑
o 如果存在 CPU 争用,则 Scheduler 会强行按照优先级顺序去依次满足高优先级>低优先级的虚拟机 CPU 请求
10 、CPU Read Time
• vCPUs 的工作模式是从 CPU Scheduler 根据 Proportinonal-share 算法去获取物理 CPU 的 Cycles
o 如果 vCPU 想要尝试去在没有可用 CPU Cycles 的物理 CPU 上执行指令时,请求会被列入等待队列
o 物理 CPU 没有 Cycles 通常都和物理 CPU 不够用或高优先级的 vCPUs 多吃多占有关
• vCPUs 等待物理 CPU 的可用 Cycles 时间集合就是 CPU Ready Times
o 从概念上来看,就该知道,这样一来必然会影响到 Guest OS 的 Performance
注:关于 RDY ,详情请查阅 :http://bbs.vmanager.cn/thread- - 6311- -1 1- - 1.html
11 、vSphere Client 查看 CPU 指标
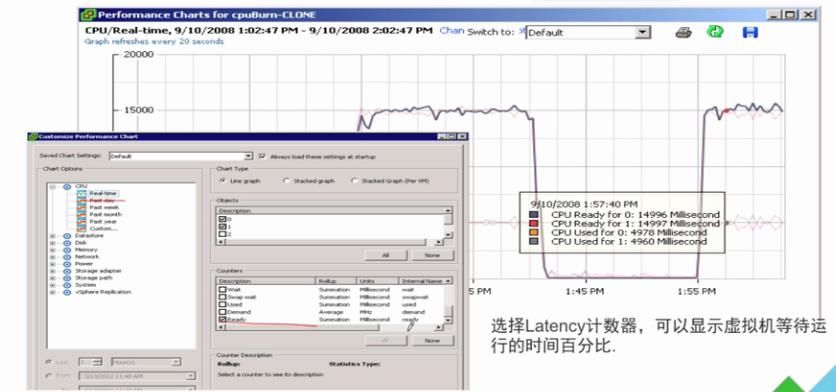
12 、esxtop 下的 CPU 性能分析参数
• PCPU USED(%): 物理 CPU 的使用率
• 每一组的统计数据信息:
o %USED:使用率(包含%SYS)
o %SYS:VMKernel 系统的活动时间
o %RDY:Ready Time
o %WAIT:Wait 和 idling 时间
o %CSTP:提交到 co-schedule 的百分比
o %MLMTD:由于 CPU Limit 导致的无法调用运行参数
o NWLD:指定 Group 分配到的 Worlds 数量
• 输入"V"可以查看虚拟机的相关输出信息
• 输入"e"可以显示为虚拟机分配的所有可用 worlds
• 用于监控性能的重要指标
o High-usage 值
• 这个值通常都意味着高资源使用率
• 这个参数适用于几乎所有的对象
o Ready time
• 这是衡量 CPU 是否存在性能问题的重要指标
• CPU Ready Time 发生在虚拟机的 CPU 请求数量超过物理 CPUs 可用数量的情况下
• 计算方式:x * 100% / 20000 = 0.0001 y%
注:x x = 时间,单位 ms , 20000 单位为 ms ,缺省系统刷新周期为 20s , y = RDY 的百分比(超过 10% 时则会存在性能问题,超过 5% 时可能就会存在,但当时可能并不存在严重性的性能问题)
四、针对 RAM 的性能优化
1 、Mem.FreeMinPct
• Mem.MinFreePct 是 VMkernel 需要保持为 free 状态内存数量的控制参数
o VMkernel 通过弹性比例基于为 ESXi Host 配置的内存来决定 Mem.MinFreePct 这个参数值
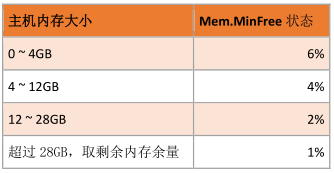
2 、VMkernel 执行内存回收逻辑
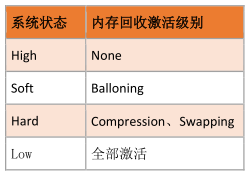
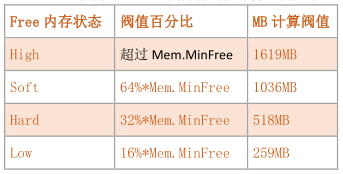
3 、vSphere 5.x 内存回收阀值计算
• 假设 Mem.MinFree 值为 1619MB,则内存阀值计算比例如下 :
4 、Guest OS 里面的内存相关参数
• 通常情况下 Guest Memory 和 Host Memory 的使用率是不同的,为什么呢?
o Guest physical memory
• Guest 里面可在评估活动内存状况时更加直观
• ESXi 活动内存评估技术需要时间去完成
o Host physical memory
• Host memory 使用情况并不会如实显示 Guest 的内存相关情况
• Host memory 使用情况会基于虚拟机在物理主机和 Guest 内存使用相关优先级而定
5 、Consumed Host Memory 和 Active Guest Memory
• Consumed host memory > active guest memory
o 如果没发生 Memory overcommitted,这种状态是 ok 的
o Consumed host memory 代表着 Guest 的最高内存使用量
• Consumed host memory <= active guest memory
o Active guest memory 不完全等于 Host Physical Memory
o 这种情况下,则性能可能存在问题
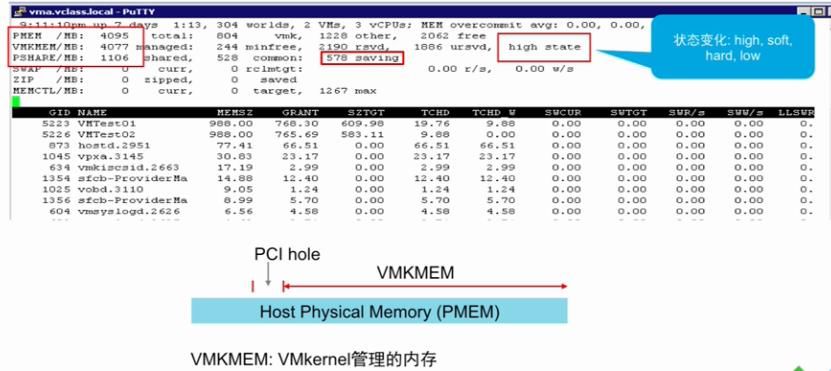
6 、利用 resxtop 监控内存状况
7 、vSphere Client 监控 Host Swapping

8 、在 resxtop 下的 Host Swapping -01
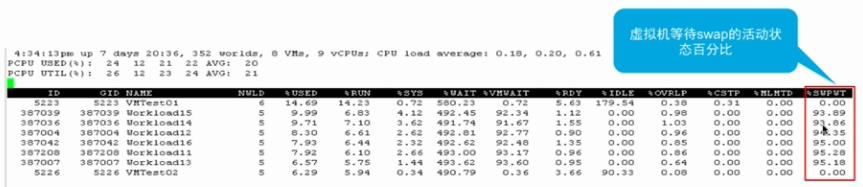
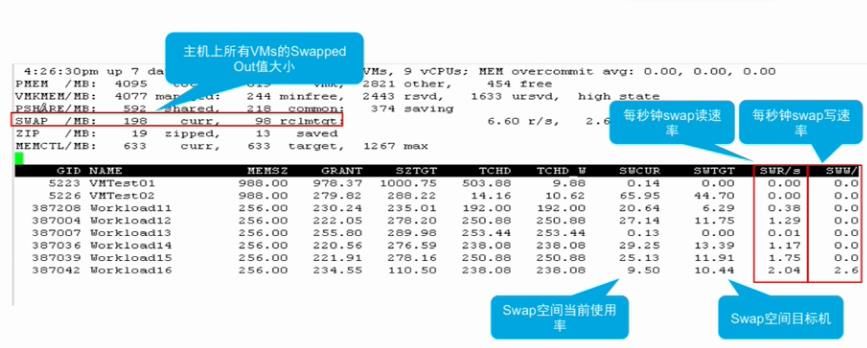
9 、在 resxtop 下的 Host Swapping-02
10 、vSphere Client 监控之 Balloon Driver

11 、resxtop 下的 Host Balloon

12 、Active Host-Level Swapping - 01

13 、Active Host-Level Swapping - 02
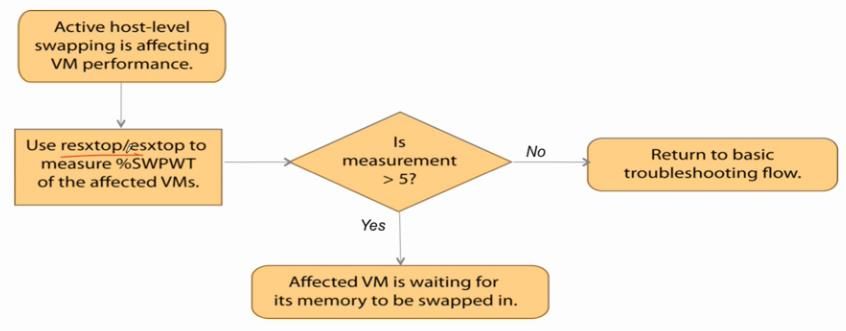
14 、解决内存不瞳的问题
• 解决 Host Swapping 的问题
o 为虚拟机安装 VMware Tools 借此激活 Balloon Driver 功能
o 减少为虚拟机设定的 Reservation 值
o 为 ESXi Host 添加物理内存
o 减少 ESXi Host 主机上 VMs 的数量
o 为虚拟机启用 Host Plug Memory 的功能,方便增加
15 、Balloon Driver vs Swapping
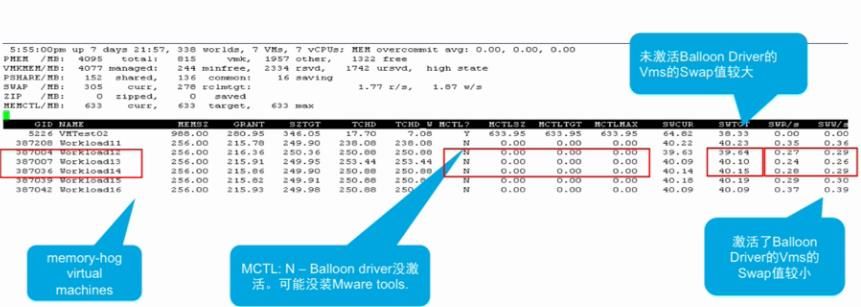
16 、什么时候出现 Swapping 发生在 Balloon 前?
• 同时开启大量虚拟机时就会出现这个情况
o 此时,虚拟机会消耗大量的内存
o 由于需要 VMware Tools 支持,所以 Balloon Driver 没有启动,因此就会导致 Swapping
• Host-Level Swapping 会导致启动缓慢,不过,完成启动之后,不一定会影响性能
• 虚拟机的内存被 Swap Out 到磁盘时,也不一定会影响性能,如果这部分内存不被访问的话
17 、Memory Best Practice
• Memory 最佳实践
o 为必要的 VMs 分配足够的内存,避免 Swapping
o 不要禁止掉 Balloon Driver
o 保证 TPS 功能开启
o 避免过大的 Memory Overcommitted
o 为必要的 VMs 启用 Memory Hot-Plug 功能
o 配置 Host Level Cache, 用 SSD 做 cache disk
o 不要为 ESXi Host 运行太多 VMs
五、针对 DISK 的性能优化
1 、针对 Datastore 的 的 Performance 相关监控
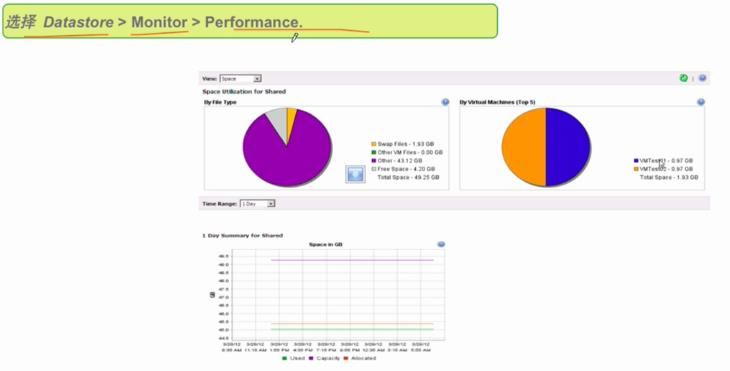
2 、磁盘相关参数
• 检查是否存在磁盘故障
o 确认是否有足够的带宽,看看是否能满足预期应用的开销需求
• 针对这样的问题,怎么办?
o 检查相关的关键参数,包含类似下面几个参数:
• 磁盘吞吐
• Device、kernel 的 Latency
• 磁盘命令的被迫终止数目
• 磁盘命令的 Active 数目
• 队列的 Active 命令数目
3 、vSphere Web Client 监控磁盘吞吐
• 关键参数:读、写速率和使用情况
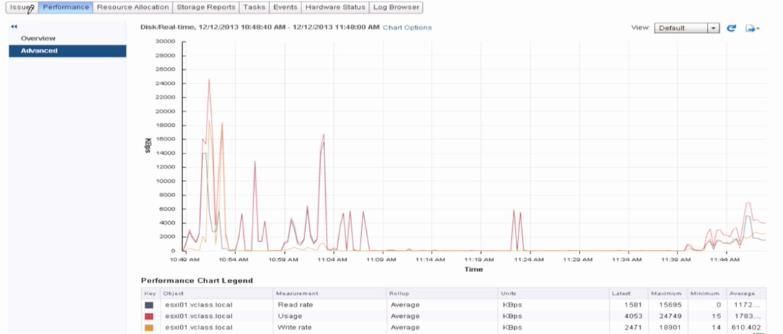
4 、利用 resxtop 监控磁盘吞吐

• 下面几个参数被用于评估磁盘的吞吐情况:
o READs/s and WRITEs/s
o READs/s + WRITEs/s = IOPS
• 也可以选用 MB 的方式来计算
o MBREAD/s and MBWRTN/s
5 、磁盘吞吐状况范例
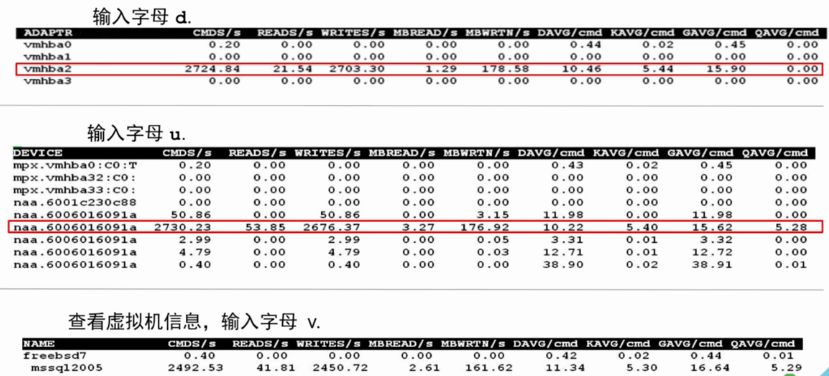
•注:输入字母 d 可以看 hba 卡相关的信息
o输入字母 u 可以查看 lun 的相关信息
o输入字母 v 可以查看虚拟机相关的信息
6 、vSphere Web Client 监控磁盘 Latency
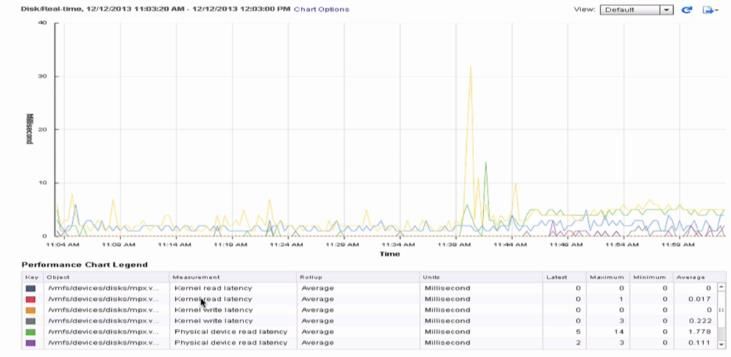
7 、利用 resxtop 监控磁盘 Latency
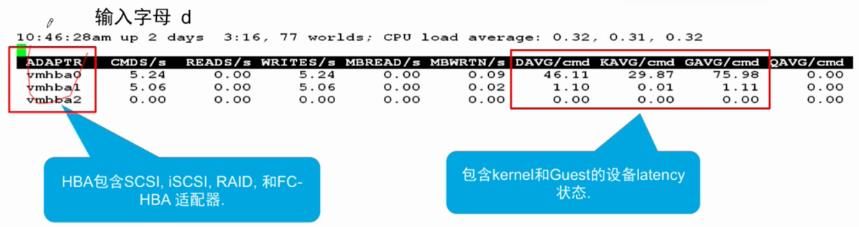
• DAVG/cmd:LUN 的平均延迟,以 ms 为单位
• KAVG/cmd:vmkernel 的平均延迟,以 ms 为单位。通常超过 3ms 就会有性能问题
• GAVG/cmd:Guest 的平均延迟,以 ms 为单位,GAVG = DAVG + KAVG
• QAVG/cmd:队列的平均延迟,以 ms 为单位
8 、监控命令和队列命令

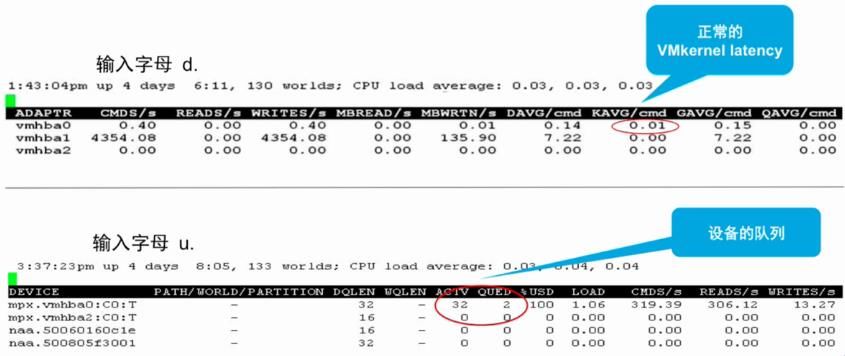
9 、磁盘 Latency 和队列范例
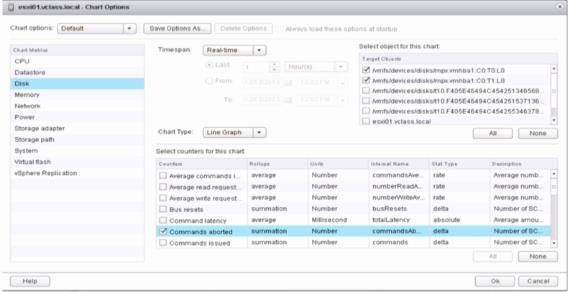
10 、监控是否存在严重存储过载
• vSphere Web Client 视图:Disk Command Aborts
• resxtop 命令参数:ABRTS/s
11 、针对 Datastore 配置 Alarm
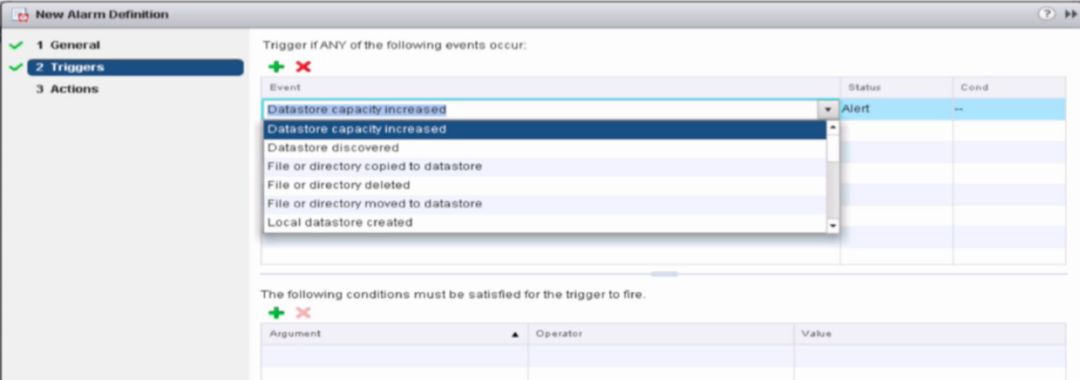
•为 Datastore 配置 alarms 的方式如下:
o右击 datastore --> Alarms --> New Alarm Definition --> 输入想要在发生状态的监控条件
12 、分析 Datastore Alarms
•点击 Monitor --> Issuses --> Triggered Alarms

13 、设备驱动队列深度
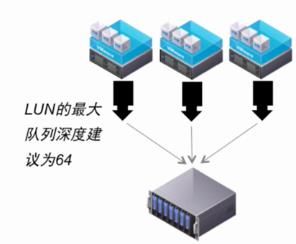
• 设备驱动队列深度决定 LUN 在同一时间支持的活动命令数目
• 设置设备驱动队列值可以用于降低磁盘延迟:
o Qlogic 适配器默认队列深度为 64
o 其它的通常缺省队列深度为 32.
o 最大队列深度建议为 64.
• 将 Disk.SchedNumReqOutstanding 的值设定为与队列深度一样的最合适
14 、存储队列
![]()
• ESXi Host 主机端的队列:
o 设备驱动队列深度控制着 LUN 上面任意时间的活动命令数目
• 缺省深度 32.
o VMkernel 队列是设备驱动队列的溢出部分
• 存储陈列队列:
o 当针对存储阵列的活动命令数据过高时,就会产生这个部分的队列
• 在主机端或存储阵列端如果有大量的队列,就会增加命令延迟
15 、SCSI Reservation 用途讲解
• SCSI reservation 用来干什么:
o LUN 在一个较短周期内被单一主机占用的时间
o 当 VMFS Metadata 被更新时,被用于支持 VMFS 实例锁定文件系统
• Metadata 更新的通常会受到下列因素影响:
o 创建、删除 VMDK
o 增加 VMFS Size
o 增加 VMDK 文件 Size
o 更改磁盘的模式
• 最小化对虚拟机性能影响:
o 别在高峰时期去做前面那些事情
• 如果存储阵列支持 vSphere Storage APIS - Array Integration(VAAI)和硬件辅助锁定功能,则 SCSI reservation 是不必要的。
16 、存储多路径技术简介
• 可以帮助解决存储的存储性能故障
• 支持下面几种 Path Selection Policy:
o Most Recently Used(MRU)
o Fixed(Fixed)
o Round Robin(RR)
o Maybe Third-Party(PSP)
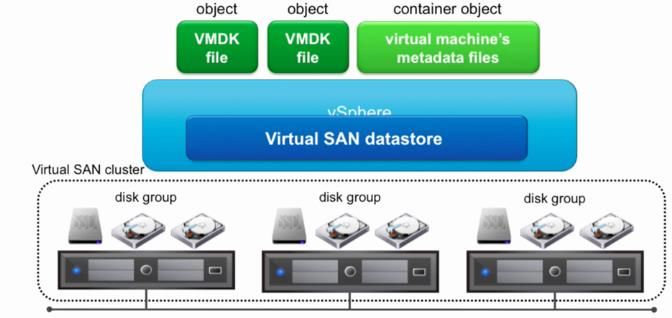
17 、VMware Virtual SAN 对于 DISK 性能相关
18 、vFRC 概述
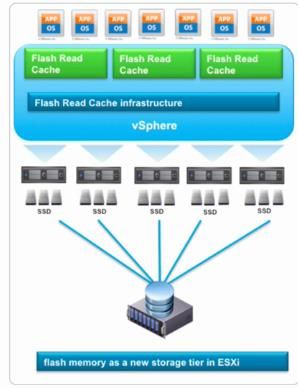
• 关键组件:
o 内置于 Hypervisor、软件定义、SSD 配合 HDD 的分层存储
o 基于 Flash 设备提供针对 VMs 的高性能读取访问支持(Virtuall Flash Host Swap Cache)
o 将本地设备配置为 Flash Cache.
o 可以与下列组件结合:
• 要求 vSphere 5.5 Enterprise Plus
• VMware vCenter Server
• vSphere HA
• vSphere DRS
• VMware vSphere vMotion
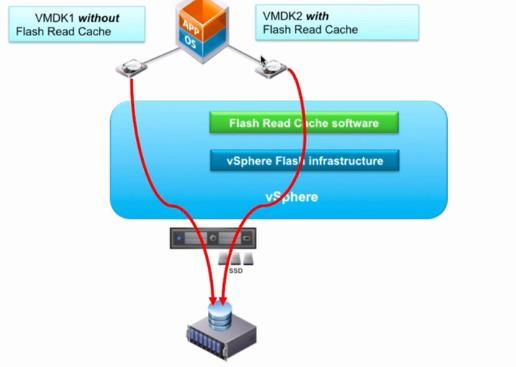
19 、vFRC 与 与 DISK 性能优化
20 、vFRC Volume 限制
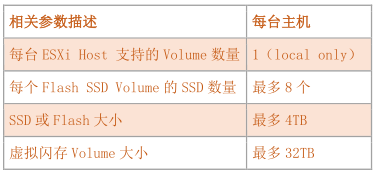
六、针对 Networking 的性能优化
1 、网路相关的参数
• 衡量网路性能相关的参数有哪些?
• 通常,和网路相关的关键参数主要是和网路统计信息相关的部分,包括:
o Network usage
o Network packets received
o Network packets transmitted
o Received packets dropped
o Transmitteed packets dropped
2 、vSphere Web Client 监控网路相关信息
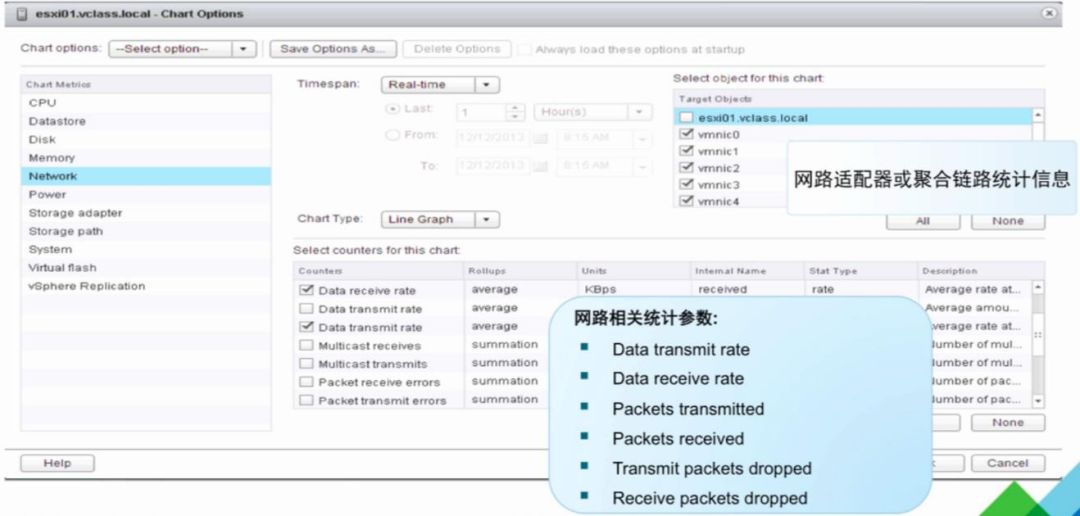
4 、利用 resxtop 监控网络统计信息
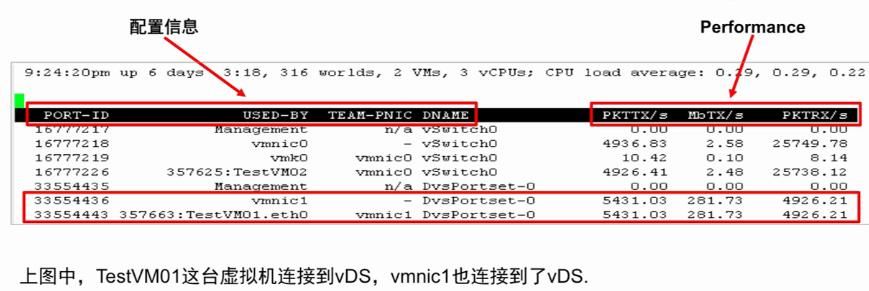
• 输入字母 n 可以查看网路相关的统计示意图
• 相关重要参数包括:
o MbTX/s: Data transmit rate
o MbRX/s: Data receive rate
o PKTTX/s: Packets transmitted
o PKTRX/s: Packets received
o %DRPTX: 传输的丢包率百分比
o %DRPRX:接收包的丢包率百分比
5 、vSphere Web Client 下查看网路性能
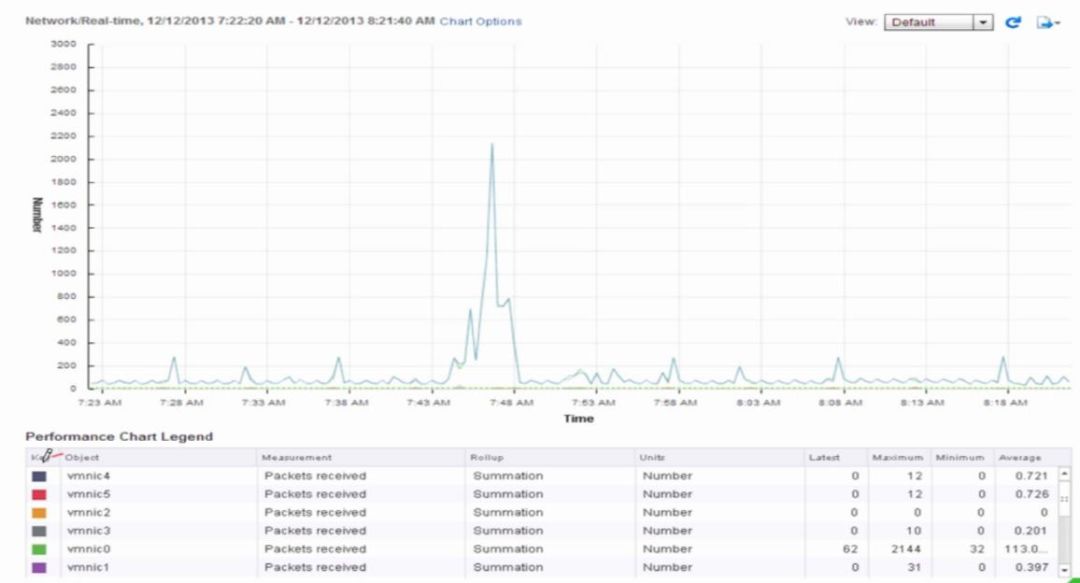
6 、利用 resxtop 查看网路性能
7 、Network I/O Virtualization Overhead
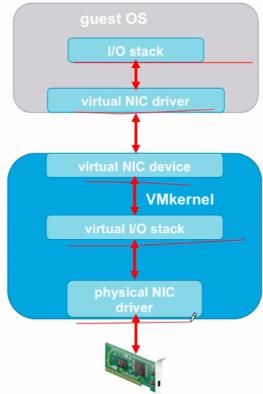
• Network I/O Virtualization overhead 可能来自于不同的层面,例如:
o Emulation 开销
o 包处理过程中
o 调度
o 虚拟中断组合
o 物理 CPU 带来的 Halt 和 Wake Up
o 虚拟 CPU 带来的 Halt 和 Wake Up
• Network I/O latency 也会由于网路虚拟化的开销导致增加
8 、vmxnet 虚拟网路卡
• vmxnet 是 VMware 的准虚拟化设备,有如下优势:
o 在虚拟机和 VMkernel 之间共享 Ring 的 Buffer
o 支持传输包聚合处理
o 支持中断聚合处理,以便减轻来自网路的中断开销
o 支持 Offloads TCP checksum 到硬件的计算
9 、影响网路性能的相关组件
• vSphere 通过结合物理网路卡的新特性,来实现针对网路性能的提升和保障,包括:
o TCP checksum offload-简单说就是利用网路卡进行 TCP 校验
• TCP checksum offload 是物理网路卡的功能之一,它的好处在于:
▪ 允许利用网路卡针对网路包执行 checksum 操作
▪ 降低来自物理 CPU 开销压力
▪ 能够根据包的大小来不同程度上提供更好的性能支持
o TCP segmentation offload-简称 TSO,简单说就是利用网路卡对 TCP 包切片
• TSO 可以通过减少大量来自 TCP 流量发送所需的 CPU 负载的情况下提升网络性能:
▪ 较大 TCP 包会被 Offload 到网路卡来进一步细分处理
▪ 网路卡会将其切割到 MTU 大小的帧
• 如果网络卡支持,则 TSO 会默认在 VMkernel 接口上激活
• 虚拟机级别的 TSO 需要手动激活
o Jumbo frames
• 在进行包传输前,IP 层会将包切片到 MTU 帧大小:
▪ 缺省的 MTU 是 1500 字节
▪ 接收端自行重组相关数据
• Jumbo Frames 的特征如下:
▪ 支持更大的以太网包,最大为 9000 字节
▪ 可以减少帧的传输数量
▪ 可以降低发送和接收端的 CPU 使用率
• 虚拟机端虚拟网路卡最好是配为 vmxnet3
• 网路的端到端都需要支持 Jumbo Frames
o 利用 DMA 直接访问内存
• 为了加快包处理效率,网路卡可以被允许直接 DMA(Direct Memory Access)到 Memory
• DMA 的好处
▪ 绕过 CPU,让 NIC 直接访问内存
▪ 避免内存空间需要通过 VMkernel 处理一次的情况
▪ 利用 Scatter-Gathe 的方式来实现将内存写入到不相邻的内存区块
▪ 允许灵活的使用可用内存,进而提供更好的性能
o 10 Gigabit Ethernet 与 40 Gigabit Ethernet
o NetQueue
• NetQueue 的性能提升主要体现在下面几个方面:
▪ 在 10GbE 和 40GbE 网路卡环境下大幅提升虚拟环境的网路性能
▪ 使用 Multiple Transmit、Multiple Receive Queues 的方式来实现将 I/O 在不同 CPU 上处理
▪ 不过仅限于支持 MSI-X(Extended Message Signaled Interrupts)系统类型
o VMware vSphere DirectPath I/O
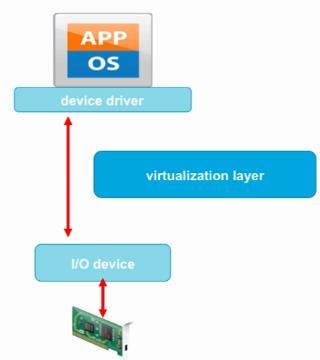
o vSphere DirectPath I/O 允许虚拟机直接访问使用物理网路卡
o vSphere DirectPath I/O:
• 要求底层激活 IOMMU
• Intel CPU 要求支持 VT-d, AMD CPU 要求支持 AMD-Vi
• SpliRx Mode
o SplitRx 通过利用多物理 CPU 来处理单一网路队列中收到的网路包的方式,帮助提升网路性能
o 当同一台 ESXi Host 上多台 VMs 接收来自相同数据源的多播通讯时激活 SplitRx 模式
o 只有 vmxnet3 支持 SplitRx 模式
o SplitRx 模式会在 ESXi Host 检测到物理网路卡上单一网路队列符合下列条件时会被 激活:
• 网路卡的使用率负载过重
• 网路卡每秒超过 10000 个广播或多播包时
10 、Single Root I/O Virtualization
• Single Root I/O Virtualization(SR-IOV)允许单块物理 PCI Express(PCIe)卡同时被多台虚拟机使用
• SR-IOV 的工作场景如下:
o 针对网路延迟延迟活 CPU 敏感型业务的虚拟机
o 针对需要 Offload I/O 到物理网路卡处理和需要降低网路延迟的业务
• SR-IOV 配置要求:
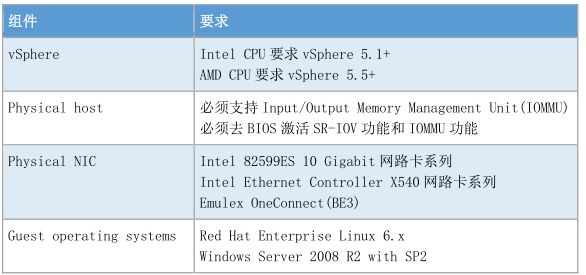
• SR-IOV 兼容的功能,当 SR-IOV 功能启用后,以下功能将无法使用
o VMware vSphere vMotion
o VMware vSphere Storage vMotion
o VMware vSphere High Availability
o VMware vSphere Fault Tolerance
o VMware vSphere Distributed Resource Scheduler
o VMware vSphere Distributed Power Management
o Virtaul Machine 挂起与恢复
o Virtual Machine Snapshots
o 虚拟机设备热添加
o Cluster
11 、Network 性能最佳实践
• 尽可能使用 vmxnet3 这块虚拟网路卡
• 尽可能充分利用物理网络卡的高性能组件
• NIC Teaming 帮助 Load Balancing
• 合理的规划虚拟交换机构成,条件许可的情况下分开不同业务到不同的 vSwitch
• 条件许可的情况下,尽量启用 Traffic Flow、Network I/O Control 等功能
• 在网路负载较重的情况下,尽可能保证足够的物理 CPU 性能
觉得本文有用,请转发、点赞或点击“在看”,让更多同行看到
资料/文章推荐:
点击阅读原文关注社区"虚拟化"技术主题 ,将会不断更新优质资料、文章,您也可以前往提出疑难问题,与同行切磋交流。地址:http://www.talkwithtrend.com/Topic/23
下载 twt 社区客户端 APP

长按识别二维码即可下载
或到应用商店搜索“twt”
长按二维码关注公众号

*本公众号所发布内容仅代表作者观点,不代表社区立场

