
- 1C#发送Get/Post请求的3种方式_c# get post
- 2MacOS配置Python环境_mac配置python环境
- 3SQL进阶(五):With 函数 vs 视图函数
- 4define 字符串_extern、#define、#ifdef __cplusplus
- 5【PostgreSQL】PostgreSQL容量相关查询_查询pg库各模式大小
- 6kernel-pwn学习(1)--环境搭建_could not access kvm kernel module: no such file o
- 7【Python 字符视频】Python 实现将抖音视频转换成字符视频_if ret: # ********** begin ********** # # 将当前帧转换成灰
- 8ACM训练计划_你有一根木棍和一个神秘数字 k,木棍上有 1 n 1 道划痕将木棍分
- 9Android - 使用DSL构建专有的语法结构_android dsl
- 10AndroidStudio自带的模拟器如何联网_androidstudio模拟器联网
手把手教你如何基于Anaconda安装Tensorflow(Windows和Linux两种版本)
赞
踩
版本:Windows10
一:安装Anaconda和Tensorflow
步骤:
1:从官方网站下载Anaconda
https://www.anaconda.com/download/
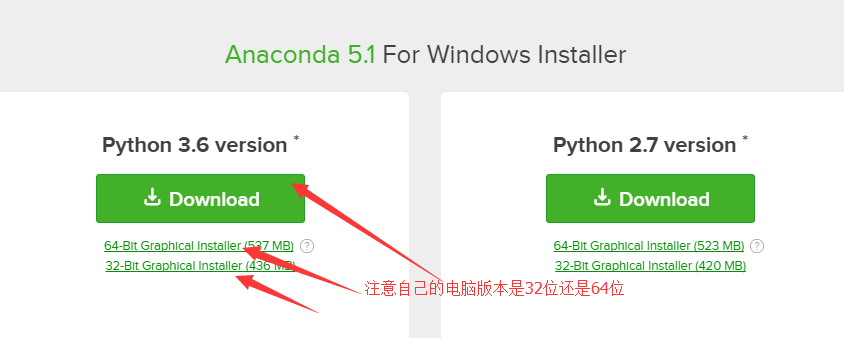
2:进行软件安装(这个和普通的没什么特别区别)
注意一点:
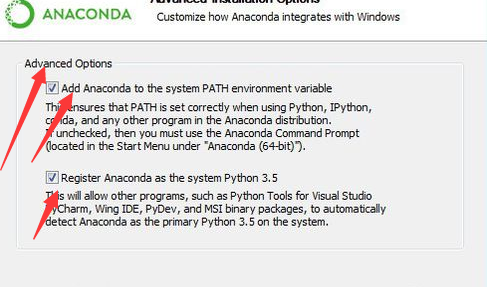
3:安装完成Anaconda之后进行环境变量的测试
进入到windows中的命令模式:
(1)检测anaconda环境是否安装成功:conda --version

(2)检测目前安装了哪些环境变量:conda info --envs

(3)对于Anaconda中安装一个内置的python版本解析器(其实就是python的版本)
查看当前有哪些可以使用的python版本:conda search --full -name python
安装python版本(我这里是安装的3.5的版本,这个根据需求来吧):conda create --name tensorflow python=3.5
(4)激活tensflow的环境:activate tensorflow(注意:这个是在后序安装成功之后才能进行的,否则会提示错误)

(5)检测tensflow的环境添加到了Anaconda里面:conda info --envs(注意:基于后序安装成功之后才进行的,否则会提示错误)

(6)检测当前环境中的python的版本:python --version
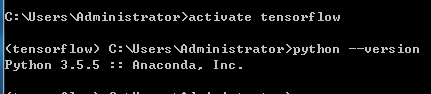
(7)退出tensorflow的环境:deactivate

(8)切换到tensorflow的环境:activate tensorflow
上面的这些基本就可以对于Anaconda有一个比较简单的了解,其实它就类似于JDK的一些操作,比如我们查看jdk的版本,也可以用java --version ,所以说对于Anaconda去安装tensorflow是比较简单的原因也正是这样,也就是是给我们提供了一个基础的依赖环境,这样就方便我们进行后面的安装操作;
Anaconda的官方开发文档,可以看看,还是官网的东西更加好:
https://docs.anaconda.com/anaconda/user-guide/getting-started
4:进行正式的安装Tensorflow
注意事项:根据Tensorflow的官方文档,可以得到安装tensorflow的一个命令是下面:
pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/windows/cpu/tensorflow-1.0.0-cp35-cp35m-win_x86_64.whl
但是,如果我们在cmd中,直接进行这样的话,有可能是不能够成功的,开始也不知道为什么,后面发现是跟电脑的cpu和显卡有点关系,所以,采取后面的方法进行安装;
5:通过命令:pip install --upgrade --ignore-installed tensorflow
剩下的就是慢慢的等待安装的过程啦
温馨提示:(1)如果在这个命令之后,有提示说需要你升级你的pip的版本,那么你就根据上面的提示进行命令安装就可以了
6:等待完成之后,确认是否安装成功
(1)打开之前安装的Anaconda
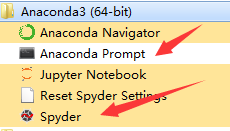
这两个都可以,我这里说一下使用Anaconda Prompt的方式;
方法一:步骤:①直接点击进入,就会显示如下的内容:
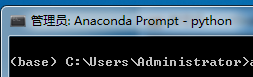
②切换到tensorflow的环境

③进入python编辑环境

④然后编写一个使用的代码:
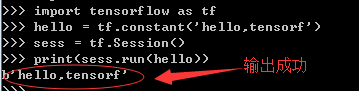
方法二:通过使用Anaconda中的spyder的编辑器
通过这个的方式的话,更加简单,直接编写上面的代码,然后进行运行就可以啦,我这里就不多介绍了。。。
7:OK,到这里的话,基本上从安装到成功就已经实现了~~~~
温馨提示:如果你发现,你的conda和tensorflow环境都是安装成功的,但是一用测试代码进行跑的时候就出问题了,那么请注意,这个原因你由于你在安装tensorflow的时候,是直接在cmd下,而不是在你用conda激活的一个环境,所以导致,tensorflow并没有直接嵌入到conda环境,所以,就导致无法导入模块的一个错误;
解决方法:(1)只需要在activate tensorflow ----------注意:这个环境是第三步中的第3点里面创建的;
(2)然后再使用第五步中的命令就可以了
二:将Tensorflow环境嵌入到编辑器中
环境:Tensorflow和Pycharm编辑器
步骤:
1:下载Pycharm软件,,这个的话下载安装都很简单,所以就不多说了
2:使用Pycharm创建一个项目

3:设置项目的相关内容
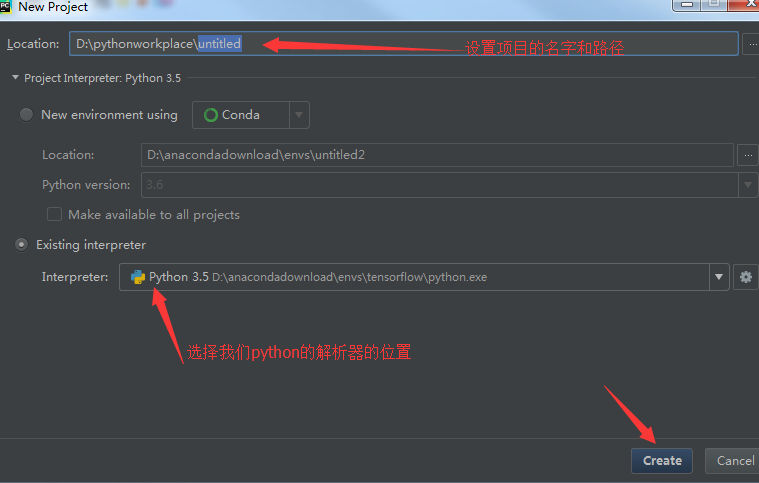
温馨提示:注意上面的Interpreter的选择,因为我们现在要测试的是tensorflow嵌入到我们的IDE,方便我们开发,所以这个python解析器就是要选择我们之前安装tensorflow目录下的解析器,否则的话,我们之后是使用不了tensorflow的模块的内容的哦。。。特别要注意。。。当然,如果这里不选择,那么在创建工程之后还是可以修改的,后面我会说;
4:创建一个py文件,用于编写测试代码
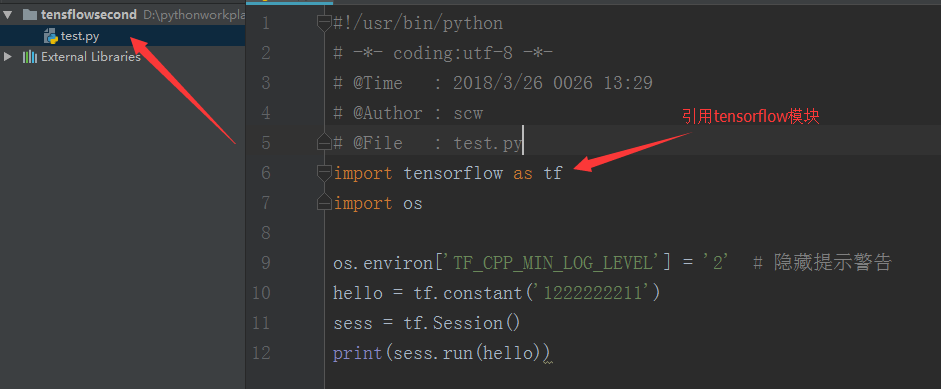
5:运行程序代码
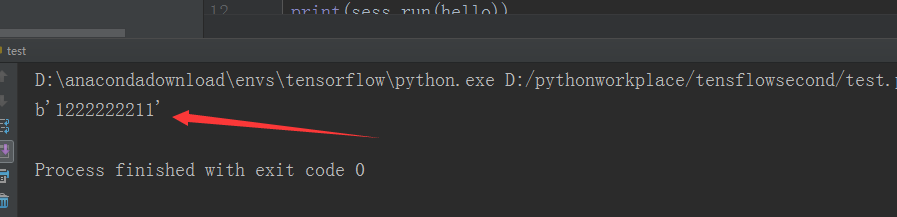
OKOK,,,这就说明我们的环境已经整合完成啦。。。。大功告成
温馨提示:有时候我们会发现,我们引入了tensorflow模块之后,那就会报错,这个原因有如下可能:
(1)tensorflow没有安装成功,这样的话,就需要重新按照我的步骤去了!
(2)IDE中的python解析器,没有使用tensorflow中安装的那个,所以导致无法识别
这个解决方案有两种:
第一种:就是创建工程的时候就选择正确的解析器,也就是我上面所使用的方法
第二种:就是在项目工程里面进行修改配置:
步骤:1:选择File----》setting
2:
3:添加新的解析器
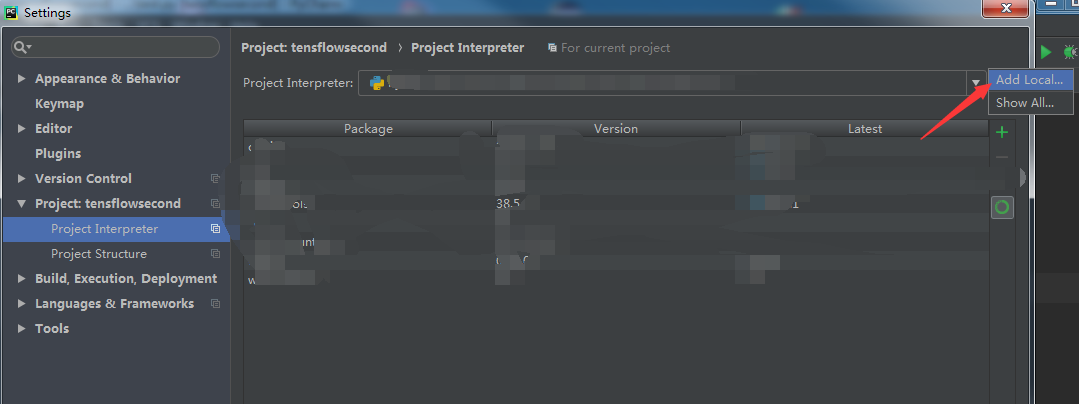
4:找到我们安装的Anadonda中的env中的tensorflow中的python.exe
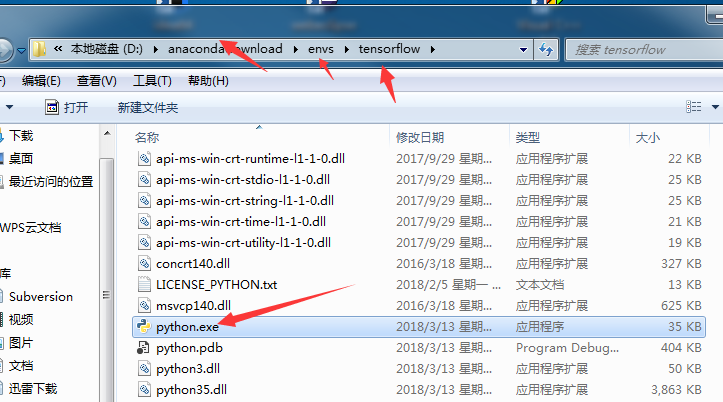
5:点击apply应用,然后重启我们的IDE,这样的话就不会报无法找到tensorflow的模块的错误了。
版本:Linux(Ubuntu14.0.1)
三:Linux环境安装Tensorflow(通过Anaconda方式)
步骤:(1)下载Anaconda的Linux版本 https://www.anaconda.com/download/#linux
从官网的路径进行下载,一般都很慢,所以,大家可以去这个地址进行下载(或者在进行留言也可以):https://download.csdn.net/download/cs_hnu_scw/10389323
(2)运行下载好的Anaconda,找到下载的目录,然后执行命令:bash XXXXXXXXX(就是Anaconda文件的名字)
(3)一直等待安装完成即可;
当出现下面这个的时候:
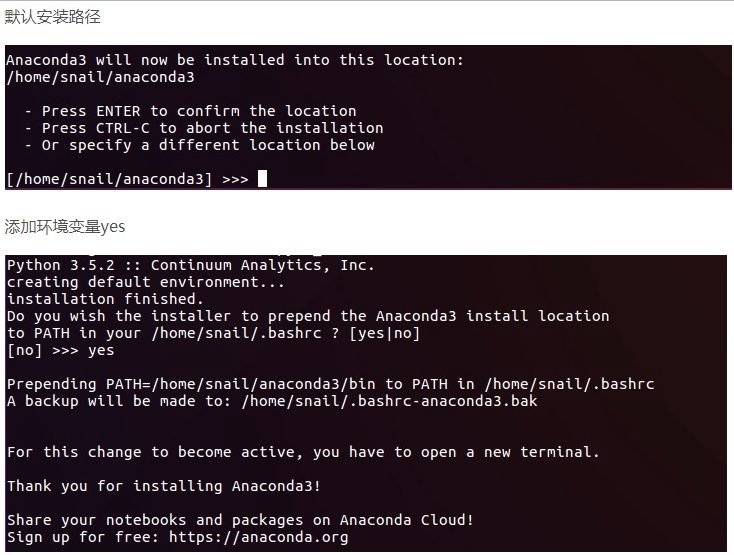
强烈注意一点:在安装的时候,会提示你是否要将这个添加到环境变量中,最好选择Yes,要不然每次都要进行额外的手动添加,非常的不方便,所以强烈建议直接添加到环境变量中;
(4)当执行完成上面的步骤之后,对Anaconda 的环境进行测试;
执行命令:conda --version (作用:查看当前Anaconda的版本)
如果,出现对应的安装版本,那么就表示安装成功,可以继续后面的安装步骤。
(5)添加tensorflow的环境。执行命令:conda create -n tensorflow python=3.5(版本的话,我个人比较喜欢3.X+版本)。当执行完成之后,就根据提示,进行输入yes就可以了,慢慢等待。
(6)激活环境,执行命令:source activate tensorflow (作用:进入到tensorflow的环境)
(7)激活tensorflow的环境,执行命令:
pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.8.0rc0-cp27-none-linux_x86_64.whl
千万要注意一个地方:如果你安装的python的版本是2.7.那么就用上面的地址,即可,如果你用了3.5版本,那么久需要对应的修改为如下链接:(其他版本类似修改)
pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.12.1-cp35-cp35m-linux_x86_64.whl
(8)执行完之后,剩下的就只有等待了,,,对于出现的提示,全部都是“yes”即可。
(9)安装完成之后,进行测试。
具体步骤:
1:在tensorflow的环境下,执行命令:python (作用:表示进入python环境)
2:然后输入代码(这个其实和windows安装的时候测试时一样):
import tensorflow as tf
hello = tf.constant('first tensorflow')
sess = tf.Session()
print sess.run(hello)- 1
- 2
- 3
如果:输出first tensorflow ,那么就表示安装成功了。
补充内容:
1:当需要退出python环境,即执行Ctrl+D或者输入quit即可
2:退出tensorflow环境,source deactivate
3:激活tensorflow环境,source activate tensorflow
四:Pycharm整合tensorflow环境
(1)下载Pycharm,这个就自己到官网下载Linux的社区版本即可,然后对其下载的文件进行相应的解压命令处理就可以了,另外的话,注意一点,在Linux中运行Pycharm不是直接点击就运行,而是需要找到对应的目录下(bin目录),然后执行命令:sh pycharm.sh 即可运行Pycharm。
(2)这个其实和windows的整合方式是一样的,只是说tensorflow的路径是不一样的而已,所以,大家可以参考上面对于Windows版本的详细配置过程即可,这里就不多说了。
---------------------------------------------------------------------------------------------------------------------------------
五:Tensorflow的案例实践
(1)案列实践:通过百度云盘下载我分享的内容即可,里面的内容都是封装好的,所以应该能看懂
项目链接:https://pan.baidu.com/s/1-TelzkLHodDNsdX6G82ZOg 密码:b05p
温馨提示:(1)在运行这个代码的时候,会出现ImportError: No module named 'matplotlib',这是因为你python中缺少了这个包,所以需要进行额外添加;或者进入tensorflow的环境,然后通过pip install matplotlib
解决办法:进入cmd,然后conda install matplotlib ,,然后等安装成功即可,这时候就会找到从而解决这个问题;
(2)手写数字的识别案例:
数据:https://pan.baidu.com/s/1UC6uBPPOBzZhYvNV93RgNw
代码:
#!/usr/bin/python # -*- coding:utf-8 -*- # @Time : 2018/3/30 0030 15:20 # @Author : scw # @File : writenumbercompute.py # 描述:进行手写数字的识别的实例分析 import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # 获取数据 mnist = input_data.read_data_sets("E:/tensorflowdata/MNIST_data/", one_hot=True) print('训练集信息:') print(mnist.train.images.shape,mnist.train.labels.shape) print('测试集信息:') print(mnist.test.images.shape,mnist.test.labels.shape) print('验证集信息:') print(mnist.validation.images.shape,mnist.validation.labels.shape) # 构建图 sess = tf.InteractiveSession() x = tf.placeholder(tf.float32, [None, 784]) W = tf.Variable(tf.zeros([784,10])) b = tf.Variable(tf.zeros([10])) y = tf.nn.softmax(tf.matmul(x,W) + b) y_ = tf.placeholder(tf.float32, [None,10]) cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y),reduction_indices=[1])) train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) # 进行训练 tf.global_variables_initializer().run() for i in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) train_step.run({x: batch_xs, y_: batch_ys}) # 模型评估 correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) print('MNIST手写图片准确率:') print(accuracy.eval({x: mnist.test.images, y_: mnist.test.labels}))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
(3)拨号键与短信息图标的识别
功能描述:主要是实现对于拨号键图标与短信息键图标的一个识别,作为一个简单的分类Demo。

百度云地址:链接:https://pan.baidu.com/s/1MC7Recml5laTsrHBQ94NcA 密码:nwxj
(4)人脸捕捉和识别
功能描述:对于某个特定的人物进行捕捉,并且能识别是否是训练中的人脸,作为一个人脸识别的Demo。
由于这个数据集太多了,百度云不让传,所以,如果有需要的同学,可以留言,我会每天都进行查看消息的。
github地址:https://github.com/qq496616246/FaceCheckPython.git
或者git@github.com:qq496616246/FaceCheckPython.git
(5)简单的网页爬虫
功能描述:非常简单,容易上手的网页爬虫小Demo。
百度云地址:链接:https://pan.baidu.com/s/1FzIzmfYON9pUpms3GyVQqQ 密码:5di1
六:安装的一些额外库的方法
(1)安装cv2:pip install opencv-python
(2)安装人脸识别的库:pip install dlib == 18.17.100
(3)安装机器学习的库:pip install sklearn
(4)安装scipy库:pip install scipy
(5)安装numpy库:pip install numpy
(6)安装Pillow图像库:pip install Pillow
(7)安装matplotlib绘图库:pip install matplotlib
(8)升级pip:python -m pip install -U pip
七:常见的一些问题汇总
(1)问题:在cmd中,输入conda 命令,提示conda不是内部命令
解决方法:在环境变量(系统的Path)中添加:你的Anaconda安装目录下面的Scripts这个目录,比如我的就是,
D:\anacondadownload\Scripts

