
- 1【数据结构】二叉树OJ题目
- 2ConstraintLayout布局的使用总结_layout_constrainttop_totopof
- 3python回文数判断_#s1-7 判断回文数 n = eval(input()) #输入数据 # 请在下面添加代码 ###
- 4Android Studio学习笔记(三)_android studio自动补全设置
- 5Android Intent 启动方法和启动Action大全_android.intent.action.view
- 6Pytorch之Bert中文文本分类(二)_bertadam用什么声明
- 7【Android 逆向】Android 中常用的 so 动态库 ( /system/lib/libc.so 动态库 | libc++.so 动态库 | libstdc++.so 动态库 )
- 8Cocos2d-x 3D渲染技术 (一)_cocos2d-objc 动画引擎的多实例视图渲染的技术实现
- 9计算机网络实验 | Wireshark 实验_安装wireshark. 2、与对象机器连通 在命令行中ping对象机器,使之连通。 主机地址1
- 10安卓开发环境Android SDK下载安装及配置教程
Diffusion 模型_diffusion模型
赞
踩

Diffusion是一种深度生成模型(无监督生成模型),其属于机器学习-无监督学习-概率模型-生成模型。
概率模型是为了求得数据的后验概率P(Y|X)或者联合概率P(X,Y)
对于监督学习而言,判别模型主要是求后验概率,即根据输入的特征X去确定标签信息Y。
生成模型主要是为了求得联合概率,对于X,求出X与不同标记之间的联合概率分布,取其中大的。
举个例子
假如我们需要解决一个分类问题,红色小三角使我们需要分类的对象。
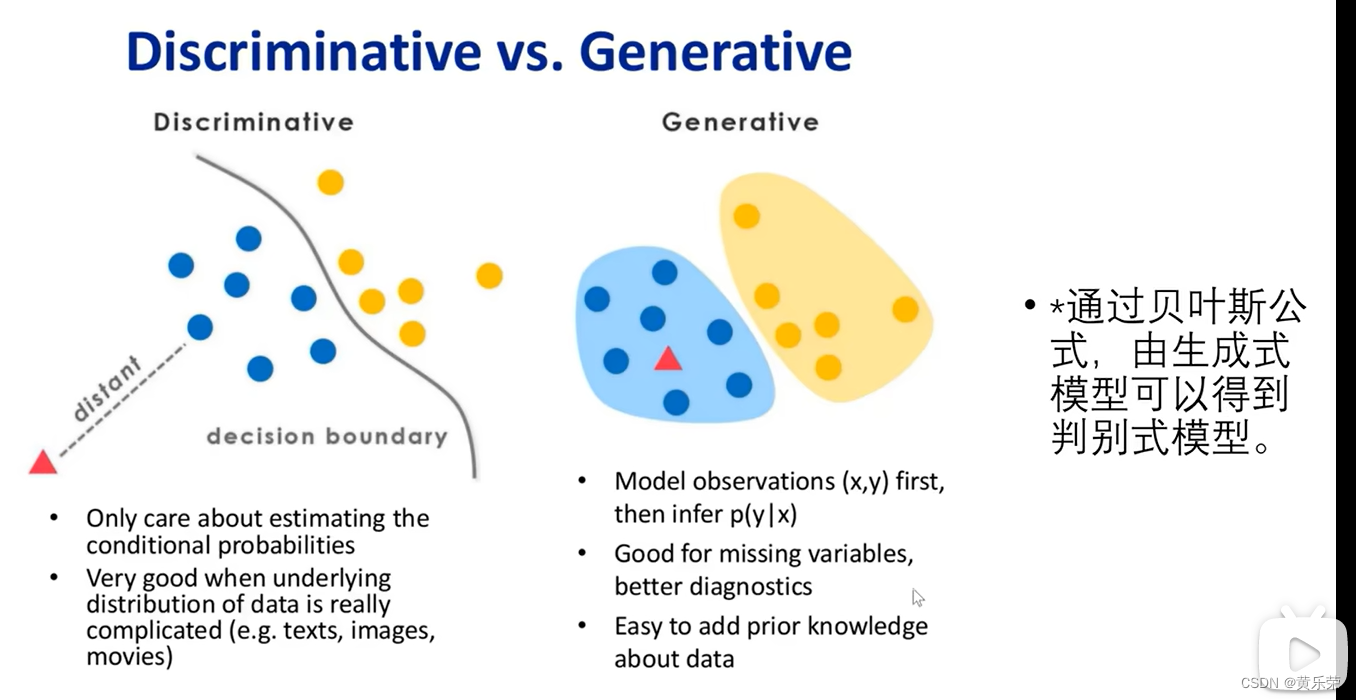
对于判别模型来说,判别模型训练出来的是这条决策边界,根据这红色小三角离决策边界的距离判定红色小三角属于哪一个类别。
对于生成模型来说,学习到的是概率分布,图中我们有两个类,我们分别求红色小三角与这两个类的联合概率分布,红色小三角属于联合概率分布大的那个类别。
生成模型意味着对输入特征和标签信息的联合分布进行建模,无监督学习意味着不存在标签信息。
在无监督生成模型中,是对输入特征的概率密度函数建模,训练得到的概率模型应该接近于输入特征的概率密度函数。
我们可以从概率模型中采样来生成样本。
对于无监督生成模型来说,如何进行概率密度估计,训练出概率模型、如何采样生成样本,是需要解决的两个难点。
由此,我们引入隐空间和隐变量的概念
例如,在数学中,我们需要用a估计b,用a估计b很困难,但是用c估计b很简单,用a估计c很容易,所以我们可以通过a来估计c,再用c估计b,以此达到用a估计b的目的。
此处的c,类似我们深度学习中经常提到的隐变量。
假如我们的无监督生成模型需要对一张图像进行建模,对原始数据直接进行建模是非常困难的。所以我们可以把原始数据转换成另外一组好进行建模的数据,即把原始数据转为隐变量。
隐空间,顾名思义是隐变量所在的空间。

以上图中的有两把椅子和一张桌子,是什么让椅子相似呢?
椅子有靠背,桌子没靠背,椅子没抽屉,桌子有等等这样的特征
这些特征可以让我们的模型学习出来,并表示在隐空间中。
我们将数据压缩、转换到隐空间中表示的过程,是剔除数据冗余信息的过程。
在这个实例中,椅子、桌子的颜色信息就是冗余信息,会被剔除,只有比较重要的特征会被存储在隐空间的表示中。
在机器学习中,数据被压缩为学习有关的数据点的重要信息。
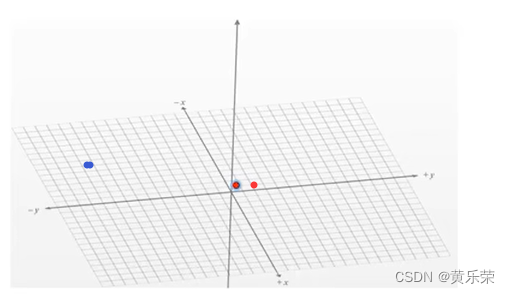
在隐空间中,相似的挨得近,不相似的挨得远。两个椅子挨得近,桌子和他们离的远。
除了判别数据的相似性,在隐空间中采样,还可以生成新的数据。我们可以通过在潜在空间上进行插值,并使用模型解码器将潜在空间表示重构为二维图像,并以与原始输入相同尺寸来生成不同的面部结构

以下为生成模型的基本结构。
未完待续
视频链接
【简单易懂diffusion模型讲解 - 从前置知识深度生成模型 隐变量 VAE开始】 https://www.bilibili.com/video/BV1re4y1m7gb/?share_source=copy_web&vd_source=9ee2521627a11b87c06e3907e194e1ab
【简单易懂Diffusion模型综述 - 基础算法详解】 https://www.bilibili.com/video/BV1TP4y1Q7qJ/?share_source=copy_web&vd_source=9ee2521627a11b87c06e3907e194e1ab
【【10分钟】了解香农熵,交叉熵和KL散度】 https://www.bilibili.com/video/BV1JY411q72n/?share_source=copy_web&vd_source=9ee2521627a11b87c06e3907e194e1ab
事件信息量和事件发生的概率是成反比的,事件发生概率越小,信息量越大。
熵表述了一个概率分布的平均信息量。
交叉熵描述了从估计概率分布的角度,对真实概率分布的平均信息量的估计值。
KL散度定量描述了两个概率分布之间的区别,并且其是概率分布模型中的一个基础概念,对推导模型的损失函数,比如交叉熵损失函数,具有重要意义。

