
- 1C++第十周任务-吃饭、睡觉、打豆豆_吃饭睡觉打豆豆c需要画图源代码
- 2【网安AIGC专题10.19】论文4:大模型(CODEX 、CodeGen 、INCODER )+自动生成代码评估:改进自动化测试方法、创建测试输入生成器、探索新的评估数据集扩充方法_大模型自动生成评论
- 3https 页面包含非安全传输内容解决方法
- 4Android针对视频部分截屏是黑色的解决办法_andorid 截屏视频控件是黑的
- 5CNN在图像分割中的简史:从 R-CNN 到Mask R-CNN_mask r-cnn历史
- 6Python3 如何设置文件的缓冲
- 7Disruptor本地线程队列_WorkProcessor异常_FatalExceptionHandler---线程间通信工作笔记004_disruptor本地线程队列_fatalexception这个错误怎么解决?fatalexcept
- 8(实测可用)STM32CubeMX教程-STM32L431RCT6开发板研究串口通信(RS485)_用stm32cubemx、keil接收rs485信号
- 9脚本外挂-图色识别-大漠课程-鼠标键盘命令(二)_大漠组合键命令
- 10HCIP-DATACOM-带解析-51-100题(821)_路由器根据转发表直接指导数据的转发
【开发工具】JAVA性能分析:5、超详细的JProfilerCPU分析(官方中文版)_jprofiler cpu热点
赞
踩
CPU Profiling——CPU分析
当JProfiler测量方法调用的执行时间及其调用堆栈时,我们称之为“CPU分析”。该数据以各种方式呈现。根据您尝试解决的问题,一个或另一个演示文稿将是最有帮助的。默认情况下不记录CPU数据,您必须打开CPU记录才能捕获有趣的用例。
一、采样与仪表——Sampling versus instrumentation
测量方法调用可以使用称为“采样”和“检测”的两种不同技术来完成,每种技术都有优点和缺点:通过采样,JVM定期停止并检查当前的调用堆栈。使用检测,可以修改所选类的字节码以跟踪方法的进入和退出。
处理采样数据时,比较后续采样。它们的公共调用堆栈显示了在两个样本之间的整个时间内可能执行的方法。随着大量样本,出现统计上正确的图像。采样的优点是开销非常低。不需要修改字节码,采样周期远大于方法调用的典型持续时间。缺点是你错过了短期运行的方法调用,你无法确定方法调用计数。如果您正在寻找性能瓶颈,这无关紧要,但如果您试图了解代码的详细运行时特性,则可能会很不方便。

另一方面,如果检测了许多短期运行方法,则仪表会引入很大的开销。由于时间测量的固有开销,这种仪器会扭曲性能热点的相对重要性,但也因为热点编译器以其他方式内联的许多方法现在必须保持单独的方法调用。对于花费较长时间的方法调用,开销是微不足道的。如果您能找到一组主要执行高级操作的良好类,那么检测将增加非常低的开销,并且可以优于采样。此外,调用计数通常是重要的信息,可以更容易地查看正在发生的事情。

二、跟踪树——Call tree
跟踪所有方法调用及其调用堆栈将消耗大量内存,并且只能保持很短的时间直到所有内存都耗尽。此外,直观地掌握繁忙JVM中的方法调用次数并不容易。通常,这个数字是如此之大,以至于无法定位和跟踪痕迹。
另一个方面是,如果收集的数据被聚合,许多性能问题才会变得清晰。通过这种方式,您可以了解方法调用对特定时间段内整个活动的重要性。对于单个跟踪,您不了解您正在查看的数据的相对重要性。
这就是为什么JProfiler构建所有观察到的调用堆栈的累积树,用观察到的时序和调用计数进行注释。按时间顺序排除,只保留总数。树中的每个节点代表一个至少观察过一次的调用堆栈。节点有子节点,表示在该调用堆栈中看到的所有传出呼叫。

调用树是“CPU视图”部分中的第一个视图,它是启动CPU分析时的一个很好的起点,因为从起点到最细粒度的终点的方法调用之后的自上而下的视图最容易了解。JProfiler按照总时间对子项进行排序,因此您可以首先打开树深度,以分析对性能影响最大的树部分。
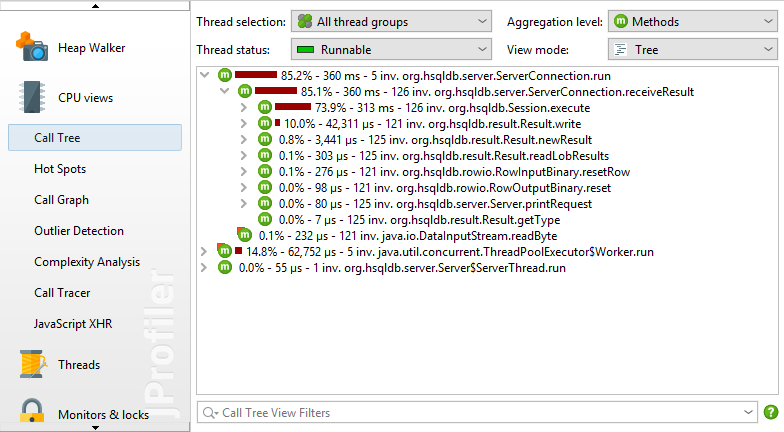
调用树过滤器
如果调用树中显示了所有类的方法,则树通常太深而无法管理。如果您的应用程序是由框架调用的,则调用树的顶部将包含您不关心的框架类,并且您自己的类将被深埋。调用库将显示其内部结构,可能有数百个级别的方法调用,您不熟悉且无法影响。
此问题的解决方案是将过滤器应用于调用树,以便仅记录某些类。作为一个积极的副作用,必须收集更少的数据,并且必须对更少的类进行检测,因此减少了开销。
默认情况下,分析会话配置有常用框架和库中的排除包列表。
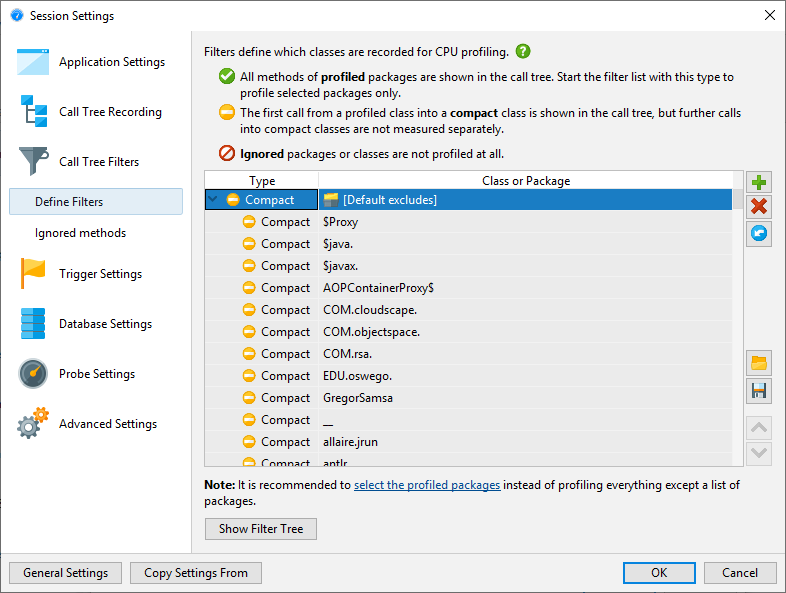
当然这个列表是不完整的,所以你删除它并自己定义感兴趣的软件包要好得多。事实上,仪器和默认过滤器的组合是如此不可取,JProfiler建议在会话启动对话框中更改它。
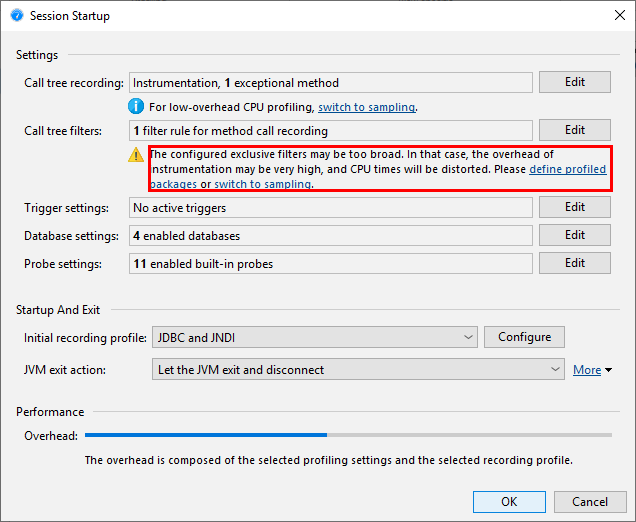
过滤器表达式与完全限定的类名进行比较,因此com.mycorp. 匹配所有嵌套包中的类,例如com.mycorp.myapp.Application。有三种类型的过滤器,称为“profiled”,“compact”和“ignored”。测量“分析”类中的所有方法。这就是您自己的代码所需要的。
在“紧凑”过滤器所包含的类中,仅测量对该类的第一次调用,但不显示其他内部调用。“Compact”是你想要的库,包括JRE。例如,在调用hashMap.put(a, b)时可能希望HashMap.put()在调用树中看到但不多于它 - 除非您是地图实现的开发人员,否则应将其内部工作视为不透明。
最后,根本没有对“忽略”方法进行分析。由于开销考虑,它们可能不适合仪器,或者它们可能只是在调用树中分散注意力,例如在动态调用之间插入的内部Groovy方法。
手动输入包容易出错,因此您可以使用包浏览器。在启动会话之前,程序包浏览器只能显示已配置的类路径中的程序包,这些程序包通常不会涵盖实际加载的所有类。在运行时,包浏览器将显示所有已加载的类。
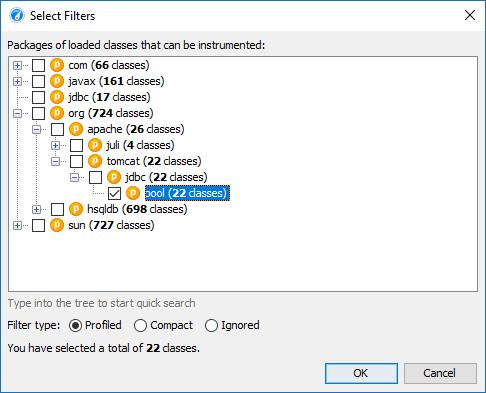
为每个类从上到下评估已配置的过滤器列表。在每个阶段,如果存在匹配,则当前过滤器类型可能会更改。什么样的过滤器从过滤器列表开始是很重要的。如果以“profiled”过滤器开头,则类的初始过滤器类型为“compact”,这意味着仅分析显式匹配。
a.*a.b.*a.b.c.*a.Aa.b.Ba.b.c.CDefault:123Result:d.Dprofiledcompactmatch
如果使用“紧凑”过滤器启动它,则类的初始过滤器类型为“已分析”。在这种情况下,除了显式排除的类之外,所有类都被分析。
a.*a.b.*a.b.c.*a.Aa.b.Ba.b.c.CDefault:123Result:d.Dprofiledcompactmatch
四、调用树时间——Call tree times
要正确解释调用树,了解调用树节点上显示的数字非常重要。对于任何节点,总时间和自我时间有两次是有趣的。自身时间是节点的总时间减去嵌套节点中的总时间。
通常,除了紧凑过滤类之外,自我时间很短。大多数情况下,压缩过滤类是叶节点,总时间等于自身时间,因为没有子节点。有时,紧凑过滤的类将调用一个分析类,例如通过回调或因为它是调用树的入口点,就像run当前线程的方法一样。在这种情况下,一些未经编译的方法消耗了时间,但未在调用树中显示。那个时间到达调用树中第一个可用的祖先节点并且有助于紧凑过滤类的自我时间。
A: self time 1 msC: self time 3 msB: self time 2 msprofiledcompactB: self time 6 msX: self time 3 msY: self time 1 msactual call sequencefiltered call sequence
调用树中的百分比条显示总时间,但自我时间部分显示为不同的颜色。除非在同一级别上的两个方法被重载,否则显示的方法没有其签名。有多种方法可以在视图设置对话框中自定义调用树节点的显示。例如,您可能希望将自我时间或平均时间显示为文本,始终显示方法签名或更改使用的时间刻度。此外,百分比计算可以基于父时间而不是整个调用树的时间。
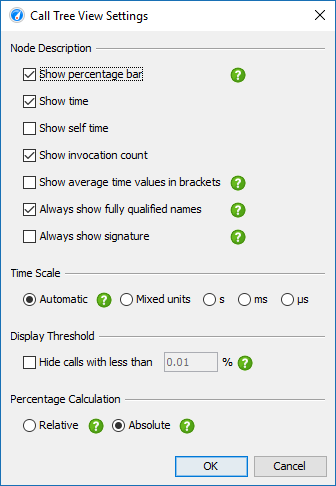
五、线程状态——Thread status
在调用树的顶部有几个视图参数,用于更改显示的分析数据的类型和范围。默认情况下,累计所有线程。JProfiler基于每个线程维护CPU数据,您可以显示单线程或线程组。
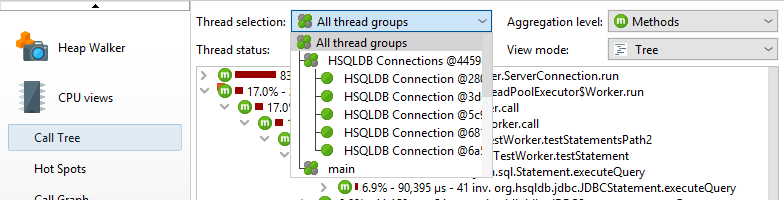
在任何时候,每个线程都有一个关联的线程状态。如果线程已准备好处理字节码指令或当前正在CPU内核上执行它们,则线程状态称为“Runnable”。在寻找性能瓶颈时,该线程状态很有用,因此默认选择它。
或者,线程可以通过在监视器上等待,例如通过调用Object.wait()或 Thread.sleep()在这种情况下线程状态被称为“等待”。尝试获取监视器时阻塞的线程(例如在synchronized代码块的边界处)处于“阻塞”状态。
最后,JProfiler添加了一个合成的“Net I / O”状态,用于跟踪线程等待网络数据的时间。这对于分析服务器和数据库驱动程序很重要,因为该时间可能与性能分析相关,例如用于调查慢速SQL查询。
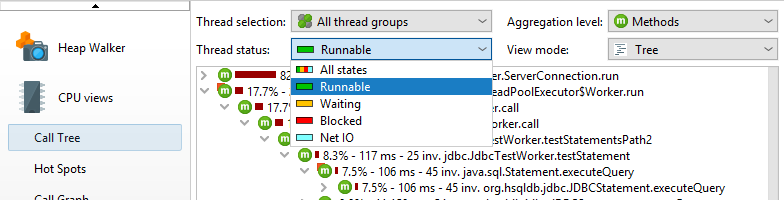
如果您对挂钟时间感兴趣,则必须选择线程状态“所有状态”并选择单个线程。只有这样,您才能将时间与通过System.currentTimeMillis()代码中的调用计算的持续时间进行比较。
如果要将所选方法转换为其他线程状态,可以使用方法触发器和“覆盖线程状态”触发器操作,或者使用嵌入式或 注入式探针API中的ThreadStatus类来执行此操作。
六、在调用树中查找节点——Finding nodes in the call tree
有两种方法可以在调用树中搜索文本。首先,通过从菜单调用View-> Find或直接开始键入调用树来激活quicksearch选项。按下后将突出显示匹配项并提供搜索选项 PageDown。使用ArrowUp和ArrowDown键可以循环显示不同的匹配项。
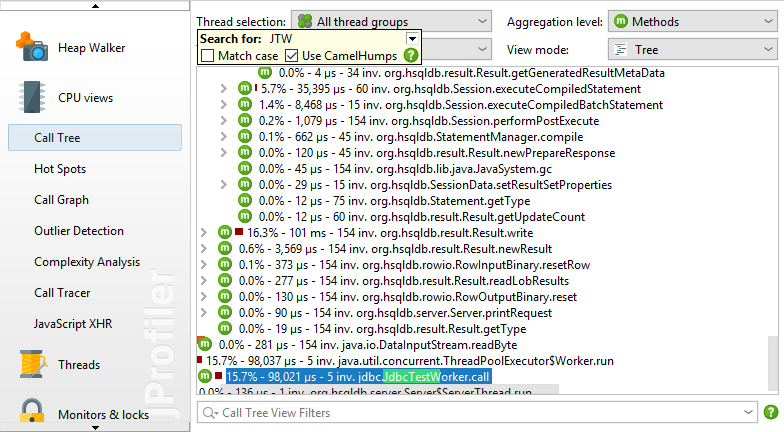
搜索方法,类或包的另一种方法是使用调用树底部的视图过滤器。在这里,您可以输入以逗号分隔的过滤器表达式列表。以“ - ”开头的过滤表达式就像紧凑过滤器一样,否则就像分析过滤器一样。与过滤器设置一样,初始过滤器类型确定默认情况下是否包含或排除类。
单击视图设置文本字段左侧的图标可显示视图过滤器选项。默认情况下,匹配模式为“Contains”,但搜索特定包时“Starts with”可能更合适。
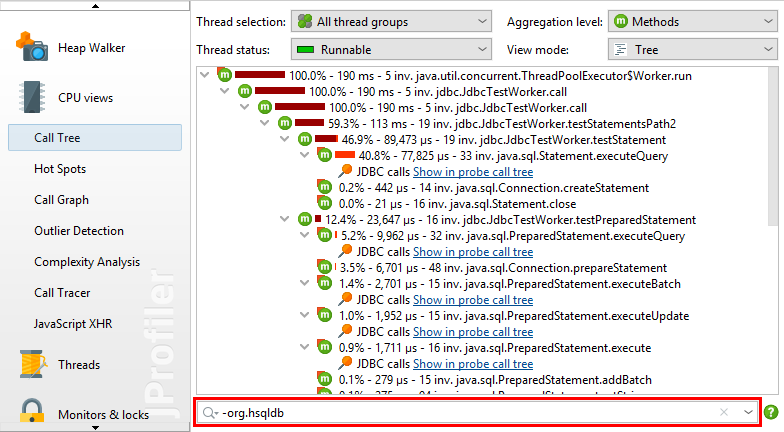
七、调用树上的不同视图——Different views on the call tree
虽然所有测量都是针对方法执行的,但JProfiler允许您通过在类或包级别聚合调用树来获取更广泛的视角。聚合级别选择器还包含“Java EE组件”模式。如果您的应用程序使用Java EE,则调用树将显示在调用堆栈跨越Java EE组件边界时拆分调用树的其他节点。“Java EE组件”聚合级别将删除所有方法节点,并仅在树中保留组件节点。
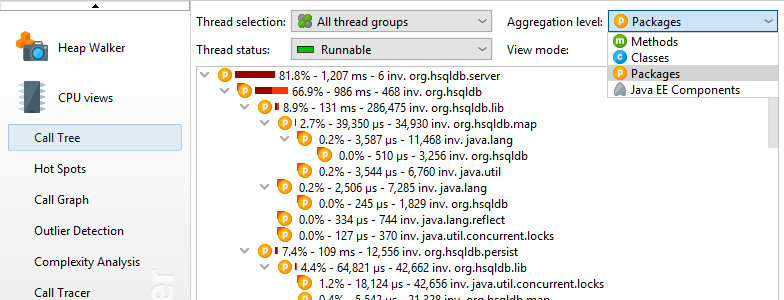
查看调用树的另一种方法是树映射。树图中的每个矩形表示树中的特定节点。矩形区域与树视图中大小条的长度成比例。与树形成对比,树形图为您提供树中所有叶子的展平透视图。如果您最感兴趣的是树的主要叶子,您可以使用树形图来快速找到它们而无需深入挖掘树的分支。此外,树形图可以让您全面了解叶节点的相对重要性。
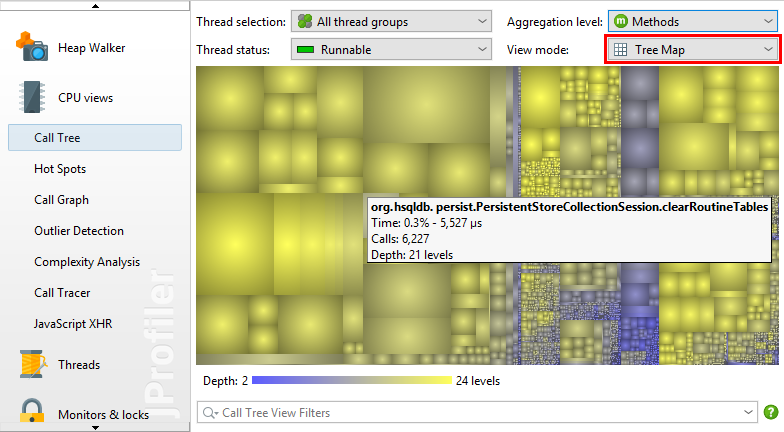
通过设计,树映射仅显示叶节点的值。分支节点仅以叶节点嵌套的方式表示。对于具有重要自我值的非叶节点,JProfiler构造合成子节点。在下图中,您可以看到节点A的自身值为20%,因此其子节点的总和为80%。为了在树图中显示A的20%自身值,创建了总值为20%的合成子节点A'。它是叶节点和B1和B2的兄弟节点。A'将在树图中显示为彩色矩形,而A仅用于确定其子节点B1,B2和A'的几何排列。

树图节点的实际信息显示在工具提示中,当您将鼠标悬停在树形图上时会立即显示这些提示。这些数字对应于树视图模式中显示的信息。树形图显示的最大嵌套深度为25个级别,其比例始终相对于当前显示的节点。
更高的聚合级别以及树形图都是从方法级别的细节退一步并采用鸟瞰图的方式。但是,当您找到特别感兴趣的点时,您通常会希望返回到方法级别。如果选择了某个节点并且您更改了方法聚合级别,则JProfiler会尽可能地保留调用堆栈。使用树映射,上下文菜单中的 Show in tree操作提供了一种返回调用树的方法。
八、热点——Hot spots
如果您的应用程序运行速度太慢,您希望找到大部分时间都占用的方法。使用调用树,有时可以直接找到这些方法,但通常不起作用,因为调用树可以包含大量叶节点。
在这种情况下,您需要调用树的反转:所有方法的列表按其总自身时间排序,累计来自所有不同的调用堆栈,后面跟踪显示方法的调用方式。在热点树中,叶子是入口点,如main应用程序的run方法或线程的方法。从热点树中最深的节点,调用向上传播到顶级节点。
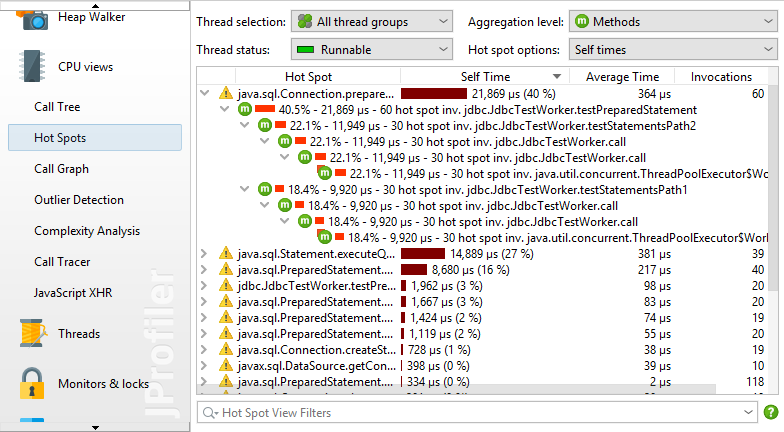
回溯中的调用计数和执行时间不是指方法节点,而是指沿着此路径调用顶级热点节点的次数。理解这一点非常重要:粗略地看一下,您可以期望节点上的信息量化对该节点的调用。但是,在热点树中,该信息显示节点对顶级节点的贡献。所以你必须读取这样的数字:沿着这个倒置的调用堆栈,顶级热点被称为 n时间,总持续时间为t秒。

默认情况下,热点是从自身时间计算的。您也可以从总时间计算它们。这对于分析性能瓶颈并不是很有用,但如果您想查看所有方法的列表,则会很有趣。热点视图仅显示减少开销的最大方法数,因此您可能无法显示所查找的方法。在这种情况下,使用底部的视图过滤器来过滤包或类。与调用树相反,热点视图过滤器仅过滤顶级节点。热点视图中的截止值不是全局应用的,而是针对显示的类应用,因此在应用过滤器后可能会出现新节点。
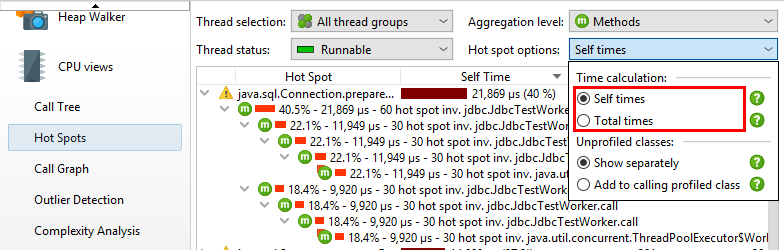
九、热点和过滤器——Hot spots and filters
热点的概念不是绝对的,而是取决于调用树过滤器。如果你根本没有调用树过滤器,那么最大的热点很可能总是JRE核心类中的方法,比如字符串操作,I / O例程或集合操作。这样的热点不是很有用,因为你经常不直接控制这些方法的调用,也无法加快它们的速度。
为了对您有用,热点必须是您自己的类中的方法或您直接调用的库类中的方法。就调用树过滤器而言,您自己的类在“分析”过滤器中,库类在“紧凑”过滤器中。
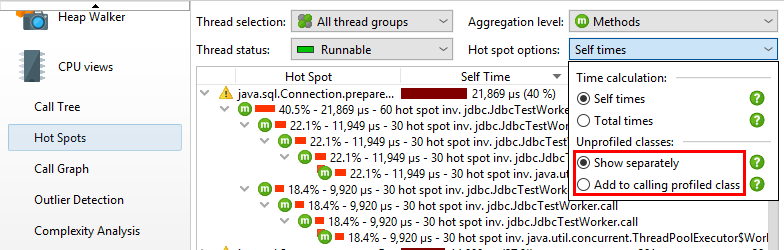
解决性能问题时,您可能希望消除库层,只查看自己的类。您可以通过在热点选项弹出窗口中选择添加到调用配置文件类单选按钮,快速切换到调用树中的该透视图 。
十、调用图——Call graph
在调用树以及热点视图中,每个节点都可以多次出现,尤其是在递归调用时。在某些情况下,您对以方法为中心的统计信息感兴趣,其中每个方法仅发生一次,并且所有传入和传出呼叫都是可见的。这样的视图最好显示为图形,在JProfiler中,它称为调用图。
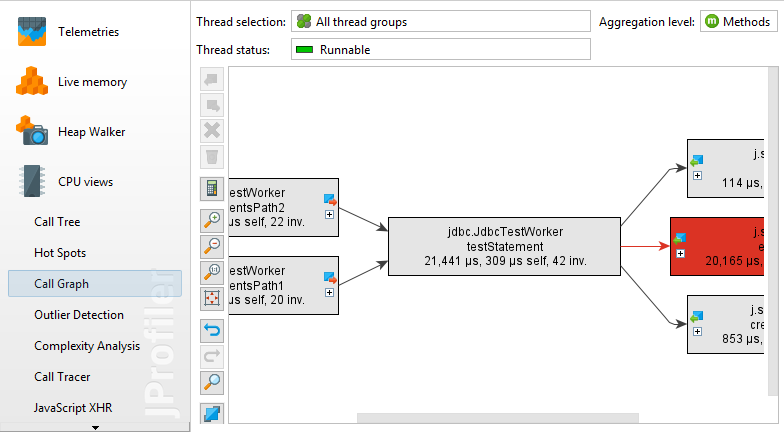
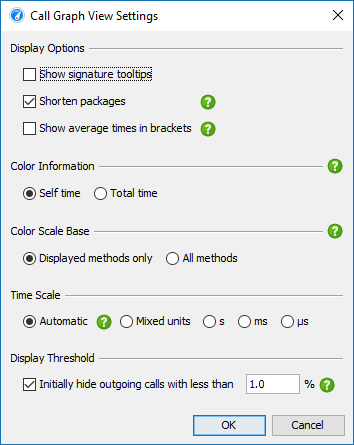
图的一个缺点是它们的视觉密度低于树的视觉密度。这就是为什么JProfiler默认缩写包名称,默认情况下隐藏传出呼叫的时间少于总时间的1%。只要节点具有传出扩展图标,您就可以再次单击它以显示所有呼叫。在视图设置中,您可以配置此阈值并关闭包缩写。
扩展调用图时,它可能会很快变得混乱,特别是如果您多次回溯。使用撤消功能可以恢复图形的先前状态。与调用树一样,调用图提供快速搜索。通过键入图表,您可以开始搜索。
图表和树视图各有优缺点,因此有时您可能希望从一种视图类型切换到另一种视图类型。在交互式会话中,调用树和热点视图显示实时数据并定期更新。但是,调用图是根据请求计算的,并且在展开节点时不会更改。调用树中的“在调用图中显示”操作计算新的调用图并显示所选方法。
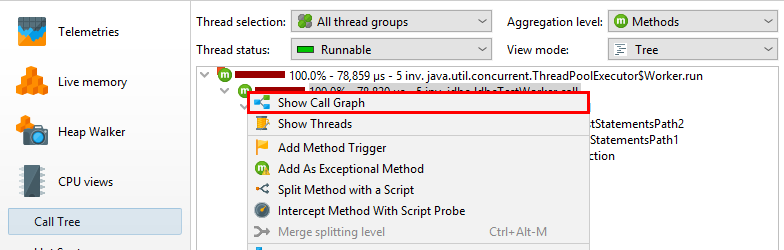
无法从图表切换到调用树,因为以后数据通常不再具有可比性。但是,调用图通过其View-> Analyze 操作提供调用树分析,该操作可以显示每个所选节点的累计传出呼叫和回溯的树。

