
ACL 2022 | NLP领域最新热门研究,你一定不能错过!
赞
踩
编者按:作为自然语言处理领域的国际顶级学术会议,ACL 每年都吸引了大量学者投稿和参会,今年的 ACL 大会已于5月22日至5月27日举办。值得注意的是,这也是 ACL 大会采用 ACL Rolling Review 机制后的首次尝试。在此次会议中,微软亚洲研究院有多篇论文入选,本文精选了其中的6篇进行简要介绍,论文主题涵盖了:编码器解码器框架、自然语言生成、知识神经元、抽取式文本摘要、预训练语言模型、零样本神经机器翻译等。欢迎感兴趣的读者阅读论文原文。
SpeechT5:语音和文本联合预训练的编码器解码器框架

-
论文链接:https://arxiv.org/abs/2110.07205
编码器-解码器框架广泛应用于自然语言处理和语音处理领域,比如端到端的神经机器翻译模型和语音识别模型。受 T5(Text-To-Text Transfer Transformer)在自然语言处理预训练模型上应用成功的启发,本文提出了一个统一语音模态和文本模态的联合框架 SpeechT5,该框架探索了基于自监督语音和文本表示学习的编码器-解码器预训练方法。
SpeechT5 包含一个共享的编码器-解码网络和对应模态的前处理/后处理网络,试图通过编码器-解码器框架将不同的语音处理任务转换成语音/文本到语音/文本的问题。利用大规模的未标注语音和文本数据,SpeechT5 统一了预训练学习两种模态的表示,以提高对语音和文本的建模能力。为了将文本和语音信息对齐到统一的语义空间中,本文提出了一种跨模态的矢量量化方法,该方法将语音和文本向量和潜在量化向量随机混合,作为编码器和解码器之间的语义接口。研究员们在多种不同的语音处理任务上评估了所提出的 SpeechT5 模型,包括自动语音识别、语音合成、语音翻译、语音转换、语音增强和说话人识别,均显示出该模型的有效性和优越性。
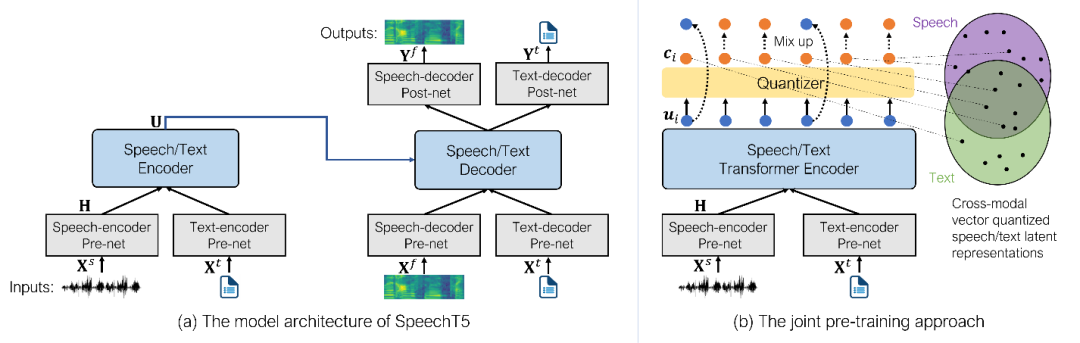
图1:(a)是 SpeechT5 模型结构,该模型架构包含一个编码器-解码器模块和六个模态特定的前处理/后处理网络。(b)是联合预训练方法,通过在不同模态之间共享潜在量化向量,联合预训练方法搭建起了语音和文本之间的桥梁。
利用对比前缀的可控自然语言生成

-
论文链接:https://arxiv.org/abs/2202.13257
为了指导大型预训练语言模型的生成,之前的工作主要集中在直接微调语言模型或利用属性分类模型来引导生成。Prefix-tuning (Li and Liang, 2021) 提出通过训练前缀(一个小规模的连续向量)来替代在下游生成任务上进行的微调。受此启发,研究员们在本文中提出了一种用于控制 GPT2 生成的新型轻量级框架。该框架利用一组前缀来引导自然语言文本的生成,每个前缀都与一个被控制的属性相对应。
与使用属性分类模型或生成判别器相比,使用前缀实现可控性具有以下优点:首先,它引入了更少的附加参数(在实验中约为 GPT2 参数的 0.2%-2%)。其次,使用前缀可以使推理速度与原始 GPT2 模型相媲美。与 Prefix-tuning 独立训练每个前缀的方式不同,微软亚洲研究院的研究员们认为属性之间有相互关系(比如正面情感和负面情感是相互对立的关系),并且在训练过程中学习这种关系将有助于提高前缀的控制效果。因此,在该框架中,研究员们考虑了前缀之间的关系并同时训练了多个前缀。本文提出了一种新的有监督训练方法和一种新的无监督训练方法来实现单属性控制,而这两种方法的结合则可以实现多属性控制。单属性控制任务(情绪控制、去毒化、主题控制)的实验结果表明,研究员们提出的方法可以在保持较高语言质量的同时引导生成文本具备目标属性。而多属性控制任务(情感和主题控制)的实验结果表明,用该方法训练的前缀可以同时成功地控制这两个方面的属性。

图2: Prefix-tuning(上)和本文方法(下)在情感控制任务上的比较。实线箭头表示训练过程,虚线箭头表示生成过程。在本文提出的框架中,训练可以是有监督的、半监督的、或者无监督的。
预训练 Transformers 中的知识神经元

-
论文链接:https://arxiv.org/abs/2104.08696
近年来,大规模预训练语言模型被证明拥有较好的回忆预训练语料中所暴露的知识的能力。但现有的知识探针工作,如 LAMA,仅仅关注评估知识预测的整体准确率。本文试图对预训练语言模型进行更深入的研究,通过引入知识神经元的概念,来探究事实型知识是如何在模型中进行存储的。
首先,如图3所示,研究员们把 Transformer 中的 FFN 模块类比为键-值记忆模块。具体来说,FFN 中的第一个线性层可以被看做一系列键,而第二个线性层可以被看做一系列对应的值。一个隐向量先跟第一个线性层中的键通过内积来计算出一系列中间神经元的激活值,然后用这个激活值作为权重,来对第二个线性层中的值进行加权求和。研究员们假设知识神经元就存在于这些中间神经元之中。

图3:研究员们把 FFN 模块类比为键-值记忆模块,而知识神经元存在于其中
在以上类比和假设的基础之上,研究员们提出了一套检测知识神经元的方法。基于知识填空的任务,研究员们先通过知识归因算法来找到对最终知识表达最重要的神经元,然后再通过一个知识神经元精炼的步骤,进一步提取出跟知识表达最为相关的神经元。
研究员们通过实验验证了知识神经元跟知识表达之间的关系:正向的,研究员们验证了知识神经元的激活值可以直接影响事实型知识的表达;反向的,研究员们验证了知识神经元更容易被表达知识的文本所激活。此外,基于知识神经元,本文还提出了两个初步的知识编辑方法,通过修改知识神经元对应的 FFN 中的参数,可以一定程度上对预训练模型中的一条知识进行更新,也可以从模型中删除一整类知识。
基于神经标签搜索的零样本多语言抽取式摘要

-
论文链接:https://arxiv.org/abs/2204.13512
抽取式文本摘要目前在英文上已经取得了很好的性能,这主要得益于大规模预训练语言模型和丰富的标注语料。但是对于其他小语种语言,目前很难获得大规模的标注数据。因此,本文的研究内容是基于 Zero-Shot 的多语言抽取式文本摘要,具体方法是使用在英文上预训练好的抽取式文本摘要模型来在其他低资源语言上直接进行摘要抽取。针对多语言 Zero-Shot 中的单语言标签偏差问题,本文提出了多语言标签(Multilingual Label)标注算法和神经标签搜索模型 NLSSum。
多语言标签是通过机器翻译和双语词典替换等无监督的方式所构造的标签,如图4所示,其中包含a、b、c、d四组标签集合,它们分别通过不同语言间的翻译和词替换来构造。通过这种方式构造的标签能够在标签中融入更多跨语言信息。
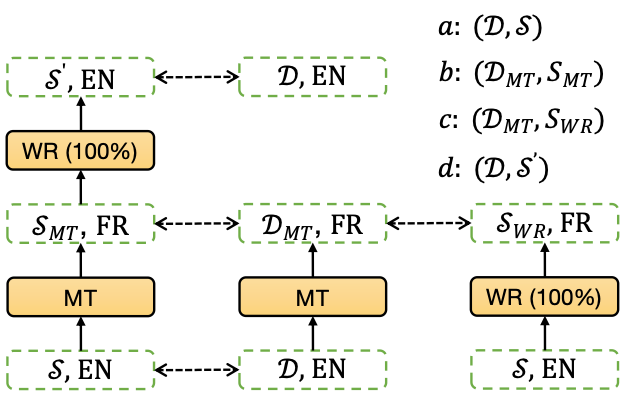
图4:多语言抽取式摘要标签构建。a为在英文上获得的标签集合,b、c、d为对英文训练集进行机器翻译(MT)和双语词典替换(WR)而获得的标签集合。
NLSSum 通过神经搜索的方式来对多语言标签中不同标签集合赋予不同的权重,并最终得到每个句子加权平均的标签。本文就是使用这种最终的标签在英文数据集上训练抽取式摘要模型(见图5)。其中,每个句子的标签得分综合考虑了句子级别权重预测器 T_α 以及标签集合级别权重预测器 T_β 的结果。和单语言标签相比,多语言标签中存在更多的跨语言语义和语法信息,因此 NLSSum 模型在数据集 MLSUM 的所有语言数据集上均大幅度超越了基线模型的分数,甚至超越了未使用预训练模型的有监督方法(Pointer-Generator)。
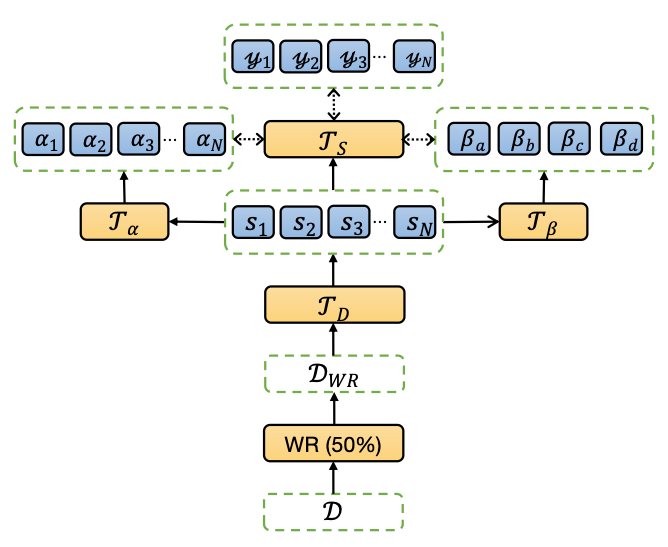
图5:多语言神经标签搜索摘要模型
本文中,研究员们还通过可视化分析进一步研究了不同语言间重要信息的分布位置,可以发现英文语言中重要信息的分布较为靠前,其他语言中重要信息的分布相对比较分散,而这也是本文多语言标签能够提升模型性能的重要原因。
NoisyTune: 加一点噪声就能帮你更好地微调预训练语言模型

-
论文链接:https://arxiv.org/abs/2202.12024
预训练语言模型是近年来自然语言处理领域备受关注的热门技术之一。在下游任务中如何有效地微调预训练语言模型是其成功与否的关键。目前已有的许多方法直接利用下游任务中的数据来微调预训练语言模型,如图6(a)所示。但是,研究员们认为语言模型也存在过拟合预训练任务和数据的风险。由于预训练任务与下游任务通常存在鸿沟,已有的微调方法较难快速地从预训练空间迁移到下游任务空间,特别是当下游任务的训练数据较为稀少时。针对这一问题,微软亚洲研究院的研究员们提出了一种简单而有效的解决方案,即在微调之前添加少量噪声来扰动预训练语言模型,名为 NoisyTune。其范式如图6(b)所示。
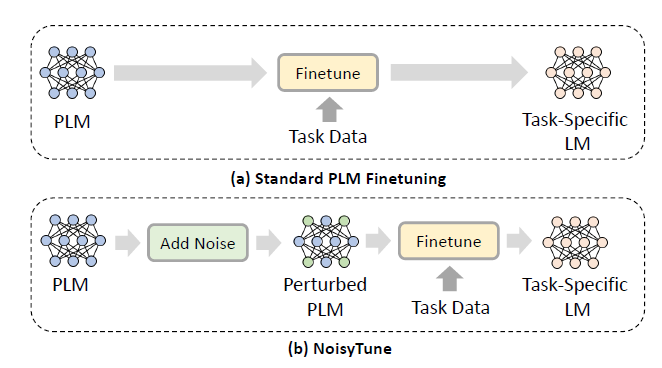
图6:标准语言模型微调的方式与本文所提出方式的对比
研究员们认为,对 PLM 添加少量噪声可以帮助模型“探索”更多潜在的特征空间,从而减轻对预训练任务和数据的过拟合问题。为了更好地保留语言模型的知识,研究员们提出了一种根据参数矩阵的方差添加均匀噪声的方法,这种方法能够根据不同类型参数的特点添加合适强度的噪声,其公式如下。其中超参数λ控制了添加噪声的强度。
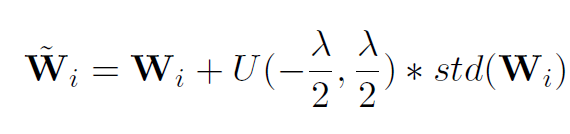
研究员们在英文的 GLUE 数据集与多语言的 XTREME 数据集上开展了实验。结果显示,NoisyTune 可以有效为不同类型的语言模型带来提升,特别是对规模相对较小的数据集提升幅度更大。
此外,研究员们还进一步探究了添加不同噪声对于 NoisyTune 的影响,结果发现加入全局统一分布的噪声往往对模型性能有一定损害,而根据参数矩阵的偏离程度添加效果更佳。另外,可能由于高斯噪声缺乏硬性范围约束,添加均匀分布噪声的模型效果比高斯噪声更好。
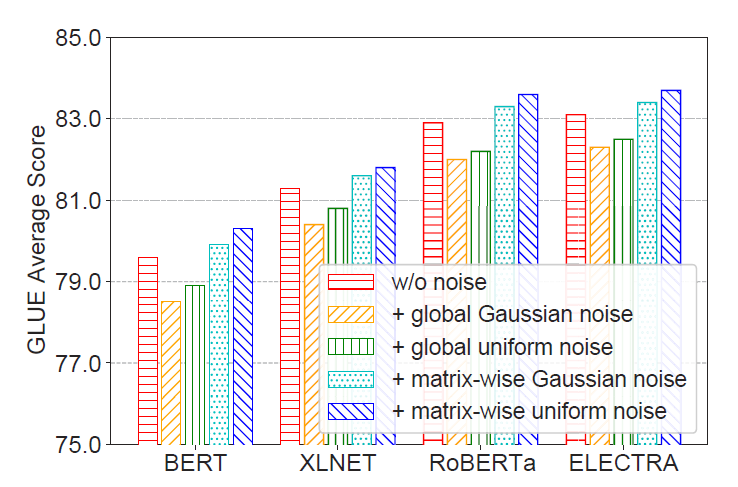
图7:不同噪声类型对 NoisyTune 的影响
零样本神经机器翻译的跨语言迁移

-
论文链接:https://arxiv.org/abs/2110.08547
本文证明了在零样本神经网络机器翻译中,合适的多语言预训练和多语言微调方法对提高跨语言迁移的能力都是至关重要的。根据这个动机,研究员们提出了 SixT+,一个强大的多语言神经机器翻译模型,该模型只使用了六言的平行语料进行训练,却能够同时支持100种语言的翻译。
SixT+ 使用 XLM-R large 初始化 解码器嵌入和整个编码器,然后使用简单的两阶段训练策略训练 编码器和解码器。SixT+ 在不少翻译方向上都取得了很好的结果,性能明显优于 CRISS 和 m2m-100 这两个强大的多语言神经机器翻译系统,其平均增长分别为7.2和5.0 BLEU。
此外,SixT+ 也是一个很好的预训练模型,可以进一步微调以适应其他无监督任务。实验结果证明,在斯洛文尼亚语和尼泊尔语这两个语言的翻译上,SixT+ 比最先进的无监督机器翻译模型的平均 BLEU 高出1.2以上。SixT+ 同样可以应用于零样本跨语言摘要,它的平均性能显著高于 mBART-ft,平均可以提高 12.3 ROUGE-L。研究员们还对 SixT+ 进行了详细分析,以了解 SixT+ 的关键组成部分,包括多语言平行数据的必要性,位置分离编码器及其编码器的跨语言迁移能力。
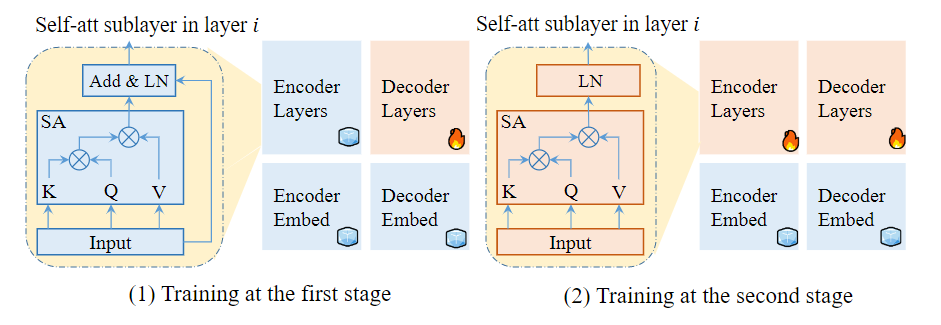
图8:研究员们提出的两阶段训练框架,利用多语言预训练模型 XLM-R 建立跨语言生成模型。图中蓝色的冰块表示用 XLM-R 初始化并冻结,而红色的火焰则代表随机初始化或从第一阶段开始初始化。
关注微软中国MSDN公众号了解更多
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

