
热门标签
热门文章
- 1如何使用Springboot开发实现一个物业管理系统_物业系统怎么做
- 2Scrcpy_安卓手机投屏电脑 | 流畅高帧率 | 电脑控制手机 | 无线投屏 | 免安装 | 可录屏
- 3点云地面滤波实验之渐进形态学(实验二)
- 4【每周一文】A Few Usefull Things to know about Machine Learning_a few useful things to know about machine learning
- 5Google IO 2023推出Android Studio官方AI工具Studio Bot
- 6Android 五大数据存储 数据库加密 数据库升级 跨进程共享数据(含greendao招商银行转账示例实务操作)_sharedprefereces 跨进程
- 7Android方案需求,Android 三种适配方案
- 8docker 服务的启动命令_docker启动命令
- 9中国特色新型智 谋定研究·中国智库-周湘智:发展趋势与走向
- 10机器学习系列文章(chapter two)——数据特征分析处理_数据特征趋势分析机器学习
当前位置: article > 正文
【总结】RuntimeError: CUDA out of memory 问题解决_为什么将stride值设置为1后的运行代码时显示cuda out of memory
作者:2023面试高手 | 2024-03-18 14:00:16
赞
踩
为什么将stride值设置为1后的运行代码时显示cuda out of memory
第一种情况
报错后面跟了想要占用多少显存但是不够这样的字眼

解决办法:
- 修改数据加载函数(根据代码有所不同)中的num_workers 参数后解决。num_workers参数是加载数据的线程数目,有可能电脑的线程数不满足所配置的参数。
train_loader = DataLoader(train, batch_size=batch_size, shuffle=True, num_workers=8, pin_memory=True) # 比如,电脑是8线程,参数调为8就不合适,可相应降低。 # 但num_worker越小,训练越慢,可权衡后调整。 # 因此,可以将num_workers改为1或者小于8的数值- 1
- 2
- 3
- 4
- 改小batchsize,batchsize砍半可以差不多省掉一半的显存
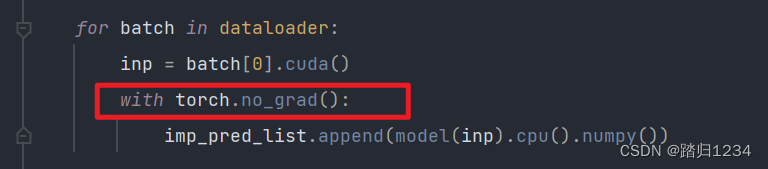
- 推理阶段加上with torch.no_grad(),这个可以将修饰的代码段不要梯度,可以省掉很多显存
- 更改显卡,这里大多指在服务器上运行,没有制定显卡,都默认使用第一张,或者多人使用,产生的不足。
-
状态描述
在操作系统输入如下,查一下memory现在的状态。nvidia-smi- 1
发现GPU-0有一个进程正在执行导致1GB剩余都不够。因此可以选择使用GPU-1执行。
-
解决办法
import os os.environ["CUDA_VISIBLE_DEVICES"] = '1' #使用第二张显卡- 1
- 2
-
- 改小input的shape,例如(224,224)->(112,112)这样可以省掉一半的显存
- 换小的网络结构
- 用多卡训练,torch可以用model = nn.DataParallel(model)启用多卡训练,终端用CUDA_VISIBLE_DEVICES=0,1 python3 train.py启动即可,这样会将batchsize等份的分给n张卡,这里的示例是2张卡,这样相当于减小了单卡的batchsize,就不会OOM了。
开启FP16,就是浮点数截断,可以省一大部分显存
第二种情况
直接报错OOM没有说申请多少显存而不够的字眼。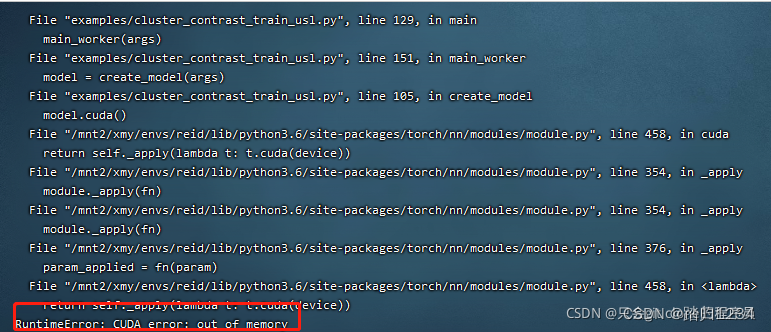
这个情况比较特殊,有多种原因:
原因一:linux下某个用户存在了显存泄露,如果是自己的账号有显存泄露,执行fuser -v /dev/nvidia*然后将提示的进程kill掉即可,如果是其他用户显存泄露,需要管理员权限,执行以下命令,执行前最好跟所有用户通知下,不然再跑的任务会被杀了。但是出现这样显存泄露的情况,所有的用户都会用不了显卡,所以应该不会有任务在跑(猜测):
sudo fuser -v /dev/nvidia* |awk '{for(i=1;i<=NF;i++)print "kill -9 " $i;}' | sudo sh
- 1
原因二:网上看到的,据说模型加载的参数和自己pytorch的版本不匹配就会报错这个,例如你的pretrain使用torch1.1.0训的,你用torch1.2.0的代码加载这个参数就有可能报错。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/263542
推荐阅读
相关标签

