
热门标签
热门文章
- 1华为交换机查mac地址命令_关于IP-MAC地址绑定的交换机设置思科篇
- 2ByteMD - 掘金社区 MarkDown 编辑器的免费开源的版本,可以在 Vue / React / Svelte 中使用
- 3国内常用公共DNS服务器、各省运营商DNS服务器汇总_huggingface dns
- 4Pytorch的x = x.view(x.size(0), -1) 的理解_self.avg_pool(x).view(x.size(0),-1
- 5微信公众平台的开发过程及其要点
- 6数据分析 | 特征重要性分析 | 树模型、SHAP值法
- 7数据库|什么?通过 Prometheus 编写巡检脚本?
- 8【浙政钉埋点】稳定性监控对接+H5流量分析对接【2024年3月19日】
- 9探索主题建模:使用LDA分析文本主题_lda查看某一个主题
- 10自定义Mybatis-plus插件(限制最大查询数量)_mybatisplus限制条数
当前位置: article > 正文
使用Python读取数据集的图片路径,划分训练集与验证集并保存到txt文件中_python怎么读取图像数据集
作者:2023面试高手 | 2024-03-18 17:14:00
赞
踩
python怎么读取图像数据集
本文将分享自己写的5个函数,分别用来实现保存数据集图片的路径到txt文件,读取txt文件,划分训练集、验证集与测试集并保存到txt文件,以及能获取txt文件中存储的图片路径与标签。
1. 读取数据集
- def write_dataset2txt(dataset_path, save_path):
- '''
- :param save_path: txt文件保存的目标路径
- :return:
- '''
- # 分类文件夹名称
- classes_name = os.listdir(dataset_path) # 列表形式存储
- print(f'classes_name: {classes_name}')
-
- # 执行写入文件操作,如果文件已存在,则不执行写入操作,需手动删除文件后再执行
- if os.path.exists(save_path):
- print(f'{save_path} already exists! Please delete it first.')
- else:
- for classes in classes_name:
- cls_path = f'{dataset_path}/{classes}'
- for i in os.listdir(cls_path):
- img_path = f'{cls_path}/{i}'
- with open(os.path.join(save_path), "a+", encoding="utf-8", errors="ignore") as f:
- f.write(img_path + '\n')
- print('Writing dataset to file is finish!')

2. 逐行读取dataset.txt中的内容
- def get_image_path(read_path):
- '''
- 读取数据集所有图片路径
- :param read_path: dataset.txt文件所在路径
- :return: 返回所有图像存储路径的列表
- '''
- with open(os.path.join(read_path), "r+", encoding="utf-8", errors="ignore") as f:
- img_list = f.read().split('\n')
- img_list.remove('') # 因为写入程序最后一个循环会有换行,所以最后一个元素是空元素,故删去
- # print(f'Read total of images: {len(img_list)}')
- random.seed(0)
-
- return img_list
3. 获得保存在txt文件中的图像路径和图像标签
- def get_dataset_list(read_path):
- '''
- 读取训练集和验证集txt文件,获得图片存储路径和图片对应标签
- :param read_path: txt文件读取的目标路径
- :return: 返回所有图像存储路径和对应标签的列表的列表
- '''
- with open(os.path.join(read_path), "r+", encoding="utf-8", errors="ignore") as f:
- # 图片路径
- data_list = f.read().split('\n')
- # print(data_list)
- # print(f'Read total of images: {len(data_list)}')
- # 对应图片标签
- img_path = []
- labels = []
- for i in range(len(data_list)):
- image = data_list[i]
- img_path.append(image)
- label = data_list[i].split('/')[1]
- labels.append(str(label))
-
- # print(img_path)
- return img_path, labels
4. 随机静态划分训练集、验证集与测试集,并保存到txt文件中
- def write_train_val_test_list(img_list, train_rate, val_rate,
- train_save_path, val_save_path, test_save_path):
- '''
- 随机划分训练集与验证集,并将训练集和验证集的图片路径和对应的标签存入txt文件中
- 本方法因使用random.seed(0)语句,所以本方法是静态划分数据集,若想实现动态划分,可注释掉random.seed(0)语句
- :param img_list: 保存图像路径的列表
- :param train_rate: 训练集数量的比率
- :param train_save_path: 训练图像保存路径
- :param val_save_path: 验证集图像保存路径
- :return:
- '''
- train_index = len(img_list) * train_rate # 以train_index为界限,img_list[0, train_index)为训练集
- val_index = len(img_list) * (train_rate + val_rate) # 索引在[train_index, val_index)之间的为验证集,其余的为测试集
-
- # 列表随机打乱顺序,放入种子数,保证随机固定,使结果可复现
- random.seed(0)
- random.shuffle(img_list)
-
- # 划分训练集和验证集,并写入txt文件
- # 判断txt文件是否已经存在,若存在则不执行写入操作,需手动删除
- if os.path.exists(train_save_path):
- print(f'{train_save_path} already exists! Please delete it first.')
- if os.path.exists(val_save_path):
- print(f'{val_save_path} already exists! Please delete it first.')
- if os.path.exists(test_save_path):
- print(f'{test_save_path} already exists! Please delete it first.')
-
- if not os.path.exists(train_save_path) and not os.path.exists(val_save_path) and not os.path.exists(test_save_path):
- print('Splitting datasets...')
- for i in range(len(img_list)):
- # 写入训练集
- if i < train_index:
- with open(os.path.join(train_save_path), "a+", encoding="utf-8", errors="ignore") as f:
- if i < train_index - 1:
- f.write(img_list[i] + '\n')
- else:
- f.write(img_list[i])
- # 写入验证集
- elif i >= train_index and i < val_index:
- with open(os.path.join(val_save_path), 'a+', encoding='utf-8', errors='ignore') as f:
- if i < val_index - 1:
- f.write(img_list[i] + '\n')
- else:
- f.write(img_list[i])
- # 写入测试集
- else:
- with open(os.path.join(test_save_path), 'a+', encoding='utf-8', errors='ignore') as f:
- if i < len(img_list) - 1:
- f.write(img_list[i] + '\n')
- else:
- f.write(img_list[i])
-
- print(f'Train datasets was saved: {train_save_path}')
- print(f'Val datasets was saved: {val_save_path}')
- print(f'Test datasets was saved: {test_save_path}')
- print('Splitting datasets Finished!')
5. 读取train.txt和val.txt文件中的图片路径和对应标签,并绘制柱状图
- def get_train_and_val(train_txt_path, val_txt_path):
- # 读取train.txt和val.txt文件中的图片路径和对应标签
- train_img_path, train_label = get_dataset_list(train_txt_path)
- val_img_path, val_label = get_dataset_list(val_txt_path)
-
- # 类别的集合
- classes = list(set(train_label + val_label)) # 去重
- classes.sort() # 排序,固定顺序
- # 统计各类别数量
- every_class_num = []
- for cls in classes:
- # print(f'{cls} total:{train_label.count(cls) + val_label.count(cls)}')
- every_class_num.append(train_label.count(cls) + val_label.count(cls)) # 追加各类别元素的数量
- # print(every_class_num)
-
- # 将标签字符串转为数值
- classes_dict = {}
- for i in range(len(classes)):
- key = classes[i]
- value = i
- classes_dict[key] = value
-
- train_labels = []
- val_labels = []
-
- for label in train_label:
- train_labels.append(classes_dict[label])
-
- for label in val_label:
- val_labels.append(classes_dict[label])
-
- # 改变字典组织格式
- classes_dict = dict((v, k) for k, v in classes_dict.items())
- # 将类别写入json文件
- classes_json = json.dumps(classes_dict, indent=4)
- json_path = r'classes.json'
- with open(json_path, 'w') as f:
- f.write(classes_json)
-
- # 是否绘制每种类别个数柱状图
- plot_image = True
- if plot_image:
- # 绘制每种类别个数柱状图
- plt.bar(range(len(classes)), every_class_num, align='center')
- # 将横坐标0,1,2,3,4替换为相应的类别名称
- plt.xticks(range(len(classes)), classes)
- # 在柱状图上添加数值标签
- for i, v in enumerate(every_class_num):
- plt.text(x=i, y=v + 5, s=str(v), ha='center')
- # 设置x坐标
- plt.xlabel('image class')
- # 设置y坐标
- plt.ylabel('number of images')
- # 设置柱状图的标题
- plt.title('Classes distribution')
- plt.show()
6. 测试部分
该程序在相对三级目录下进行测试,将存相对路径式为:数据集名称/类别名称/图片 项目目录结构如图所示:
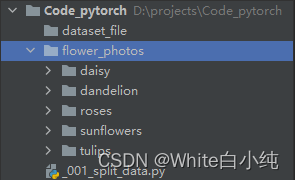
测试代码:
- if __name__ == '__main__':
- # 创建dataset.txt数据集,将flower_photos修改为自己的数据集名称
- dataset_path = r'flower_photos'
- dataset_txt_path = r'dataset_file/dataset.txt'
- write_dataset2txt(dataset_path, dataset_txt_path)
-
- # 划分训练集、验证集与测试集
- img_list = get_image_path(dataset_txt_path) # 读取dataset.txt中的内容获得图片路径
- train_rate = 0.6 # 训练集比重60%
- val_rate = 0.2 # 验证集比重20%,测试集比重20%
- train_path = r'dataset_file/train.txt'
- val_path = r'dataset_file/val.txt'
- test_path = r'dataset_file/test.txt'
- write_train_val_test_list(img_list, train_rate, val_rate, train_path, val_path, test_path)
-
- # 获取训练集和验证集图片路径与标签
- train_img_path, train_labels, val_img_path, val_labels, classes = get_train_and_val(train_path, val_path)
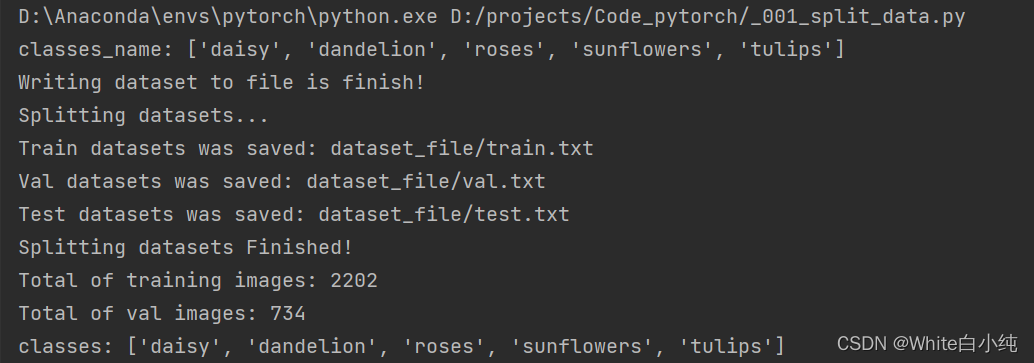
- print(f'Total of training images: {len(train_img_path)}')
- print(f'Total of val images: {len(val_img_path)}')
- print(f'classes: {classes}')
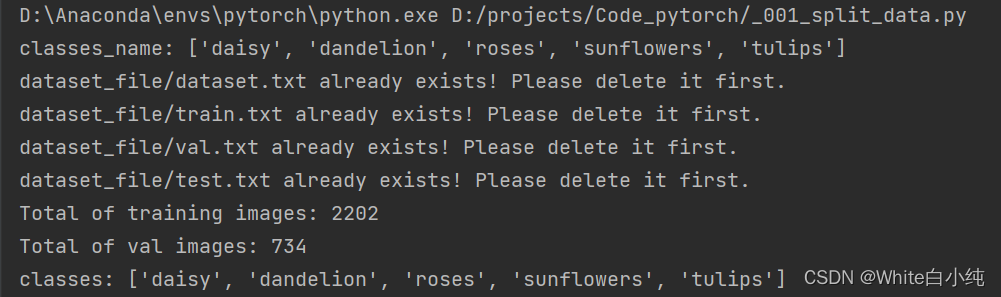
代码运行后的控制台结果:
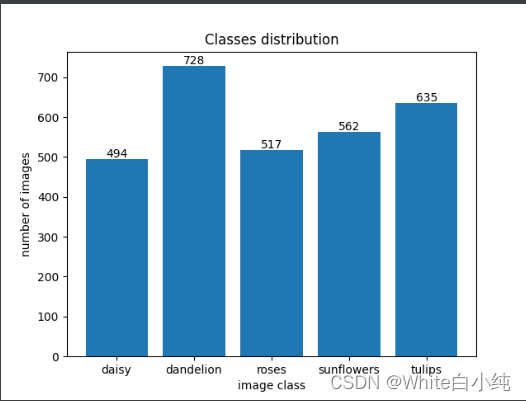
且绘制每个种类参与训练的样本数
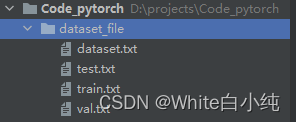
同时,项目中多了4个.txt文件,如图所示
若上述四个文件已存在,再次运行程序,不会执行写入操作,且控制台会打印提醒(如下图),需手动删除上述4个文件,才能执行
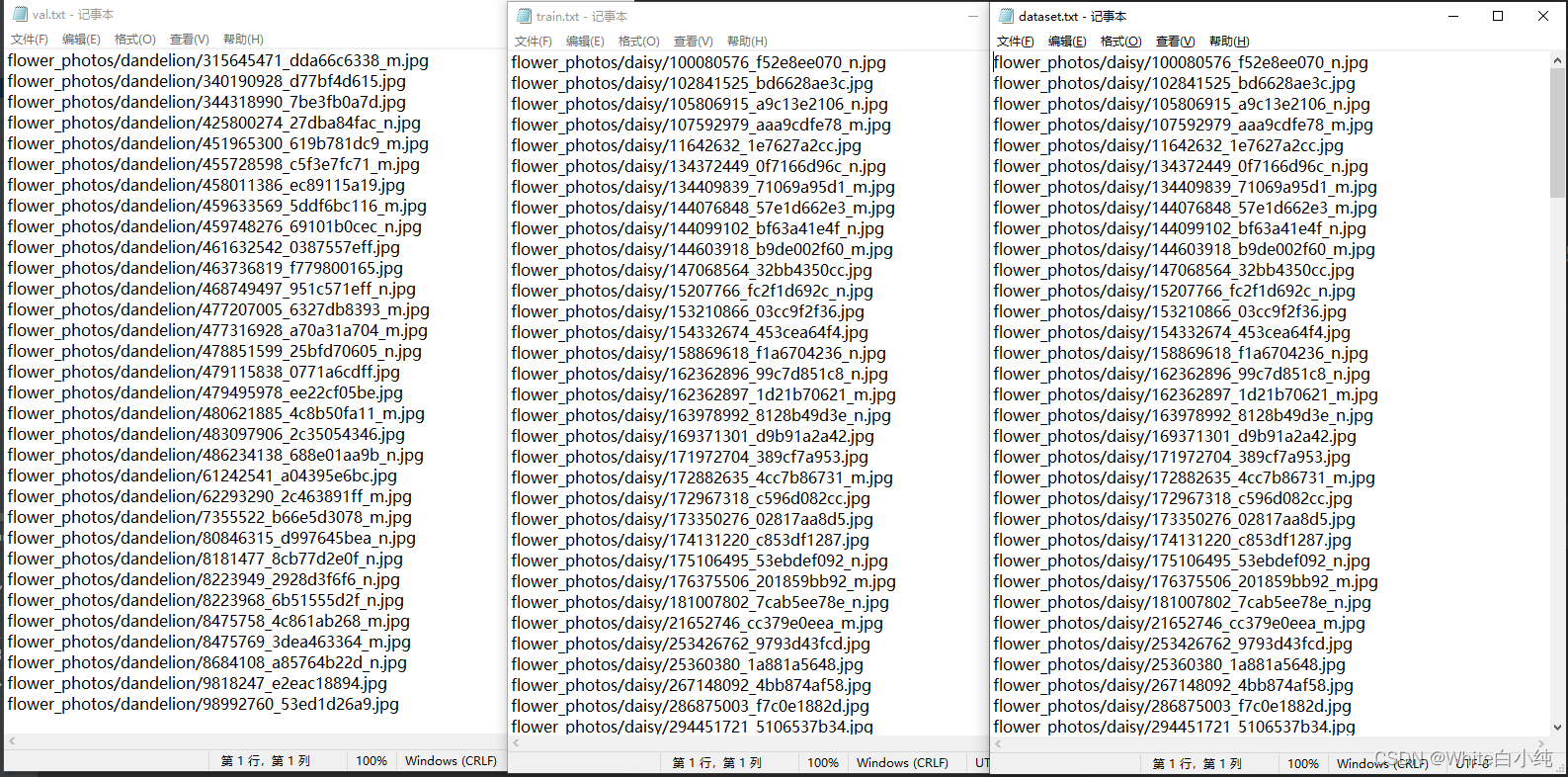
三个文件的部分内容展示如下图,可以看出该程序成果将图片的相对路径存储到txt文件中。
注意:
1. 程序中的写入文件操作,使用的是'a+'指令,会在同名文件进行追加写入操作,所以,每次执行该程序,需要删掉生成的4个txt文件,防止追加写入。(程序已更新优化,若文件已存在,则不执行写入操作,同时控制台会打印文件已存在的提醒)
2. 该测试程序中,使用的是相对目录,所以该.py程序应和数据集目录放置在同一级别,且数据集目录如图一中的目录结构相同。
3. 上述代码可依次复制到自己的程序中,并能运行成功。如果想获取源文件,我已免费上传,可直接从如下链接下载:使用Python读取数据集图片路径,划分数据集并将图片路径保存到txt文件中
4. 如有其他问题,欢迎评论区留言讨论。创作不易,如有帮助,感谢点赞支持。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/264567
推荐阅读
相关标签

