
- 1MS Access 教程之如何将 MDB 文件转换为 SQLite 数据库_mdb转sqlite
- 2《花雕学AI》ChatGPT Shortcut Chrome 扩展:让生产力和创造力加倍的 ChatGPT 快捷指令库
- 3用通俗易懂的方式讲解:决策树模型及案例(Python 代码)
- 4ubuntu下使用ollama来运行gemma_ubuntu ollama
- 5Bert几个数据集的概念Cola、MRPC、XNLI、MNLI等_mrpc数据集
- 6小程序实现卡片式设计(又叫原子化设计)_小程序css卡片效果
- 7【Pytorch(七)】基于 PyTorch 实现残差神经网络 ResNet_resnet18.pt
- 8【氮化镓】同质GaN垂直PiN二极管的SEB
- 9oracle镜像装载不到软盘中,Oracle ASM无法识别扩展分区的磁盘设备
- 10Bert基础(一)--自注意力机制_bert中transformer编码器
可解释AI如何帮助图片分类模型调试调优-可解释AI系列博文(二)_smooth gradient 可解释
赞
踩
转载地址:https://bbs.huaweicloud.com/forum/thread-101335-1-1.html
作者:Huygens12
本文是MindSpore1.1版本可解释AI系列的第二篇文章, 第一篇文章“MindSpore首次开源可解释AI能力”主要对可解释AI和MindSpore1.1开源的可解释AI能力做总体介绍, 本文将深入探讨MindSpore可解释AI如何帮助图片分类模型的调试调优。
下面结合MindSpore1.1版本中已支持的显著图可视方法的其中3种解释方法:Gradient 、GradCAM和RISE,介绍如何使用可解释AI能力来更好理解图片分类模型的预测结果,获取作为分类预测依据的关键特征区域,从而判断得到分类结果的合理性和正确性,加速模型调优。
一、常见显著图可视解释方法介绍
1.1 Gradient解释方法
Gradient,是最简单直接的基于梯度的解释方法,通过计算输出对输入的梯度,得到输入对最终输出的“贡献”值,用于解释预测结果的关键特征依据。
对深度神经网络,这个梯度计算可通过后向传播算法获得,如下图所示:
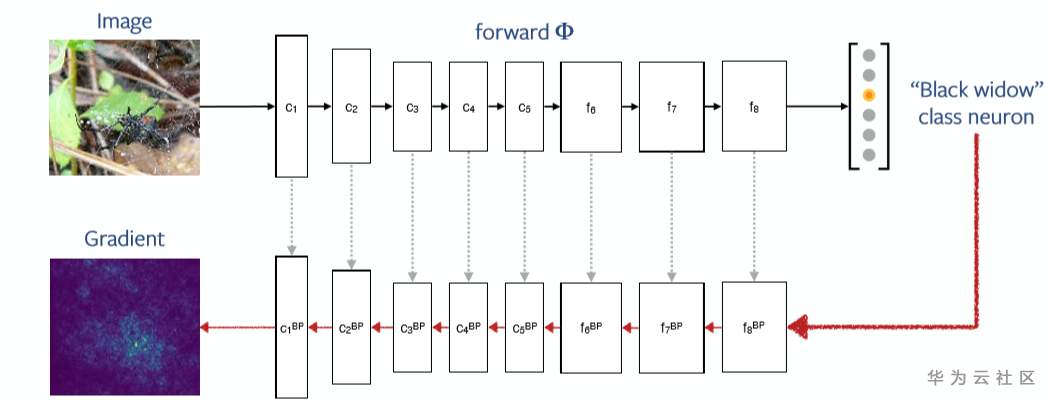
Source:Understanding models via visualizations and attribution
注:Gradient解释方法会遇到梯度饱和问题,即某个特征的贡献一旦达到饱和后,由于该特征不再对结果的变化产生影响,会导致该特征的梯度为0而出错。
Gradient解释效果如下图所示:
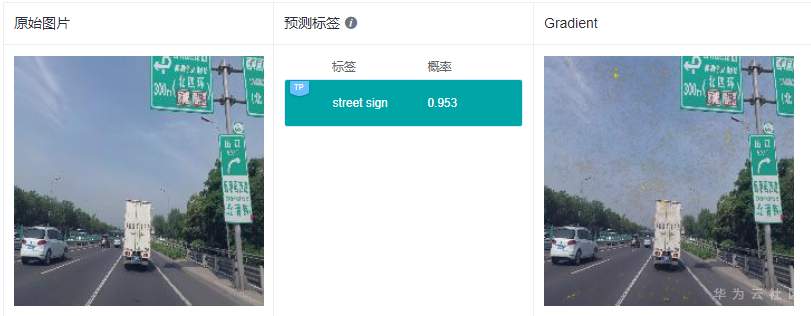
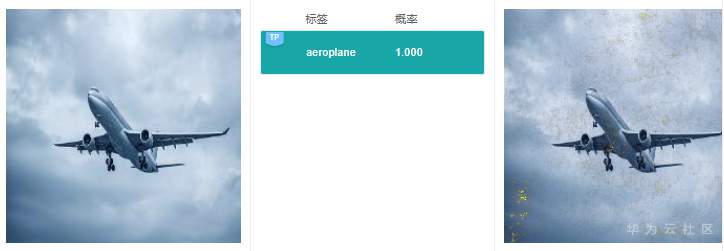
注:所有解释效果图片均来源于MindInsight截图
从上面2张图中可以看出,Gradient的解释结果可理解性较差,显著图高亮区域成散点状,没有清晰明确的特征区域定位,很难从中获取到预测结果的具体特征依据。
1.2 GradCAM解释方法
GradCAM,是Gradient-weighted Class Activation Mapping的简写,一般翻译为:加权梯度的类激活映射,是一种基于梯度的解释方法;该解释方法通过对某一层网络各通道激活图进行加权(权重由梯度计算得到),得到影响预测分类结果的关键特征区域。
GradCAM解释结果过程的概览,如下图:
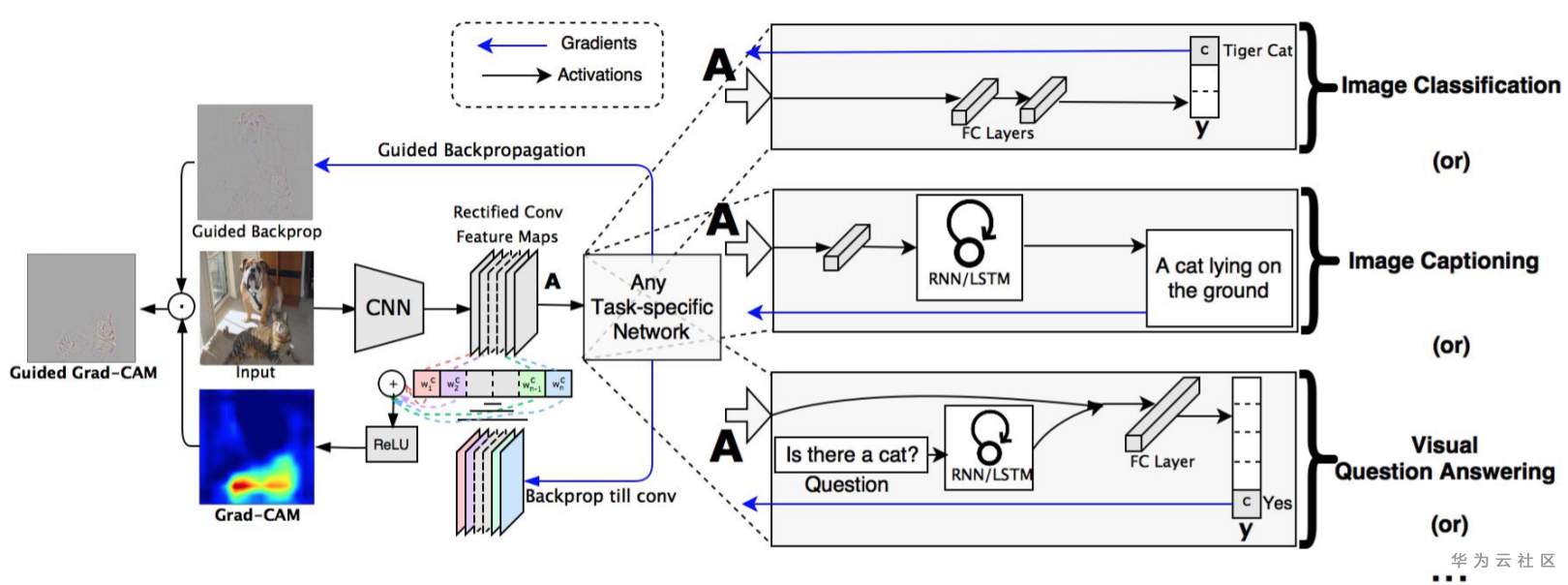
Source:Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
这里给出2个实际的例子,来看看GradCAM具体的解释效果:
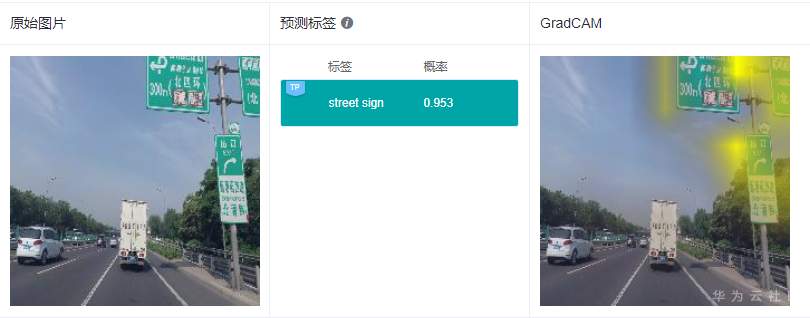
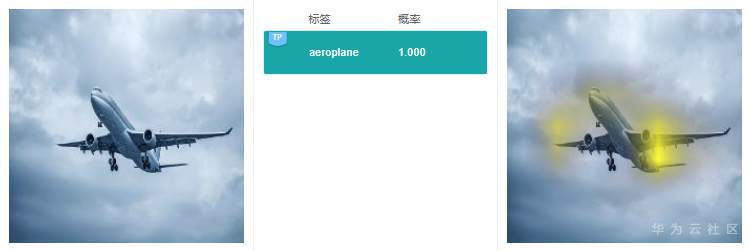
可以看到GradCAM的解释结果定位性和可理解性比较好,高亮区域集中在具体的特征上,用户可以通过高亮区域判断出和预测结果相关的特征。对于标签“路牌”,图像中的路牌被高亮,对于标签“飞机”,图像中的飞机被高亮,即GradCAM认为路牌区域和飞机区域是2个分类结果的主要依据。
1.3 RISE解释方法
RISE,是Randomized Input Sampling for Explanation的简写,即基于随机输入采样的解释,是一种基于扰动的解释,与模型无关;主要原理:使用蒙特卡洛采样产生多个掩码,然后对随机掩码进行加权(权重为遮掩后的模型的输出)平均得到最终显著图。
RISE方法解释过程的概览图,如下:
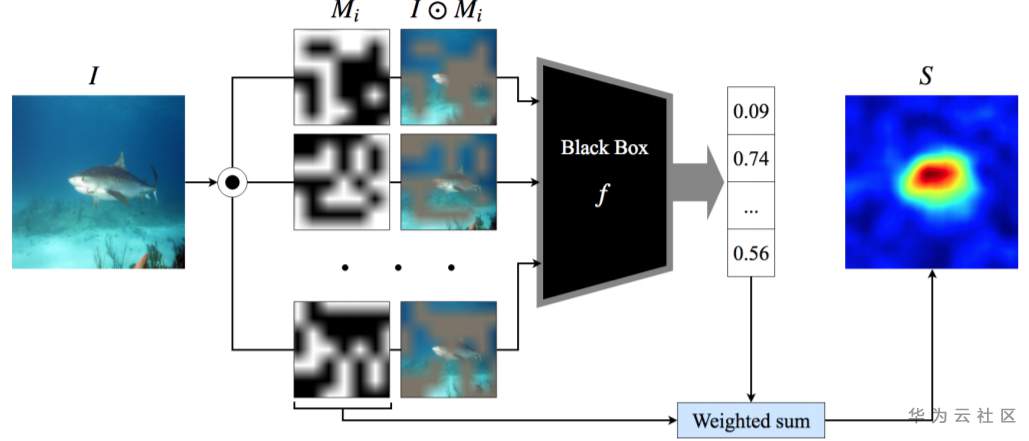
Source:RISE: Randomized Input Sampling for Explanation of Black-box Models
同样给出2个示例,展示下解释效果:
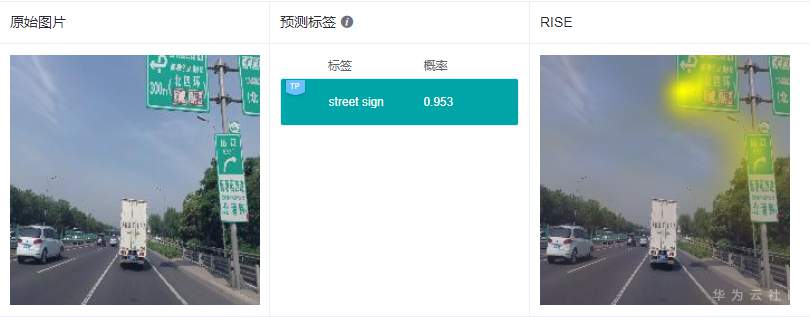
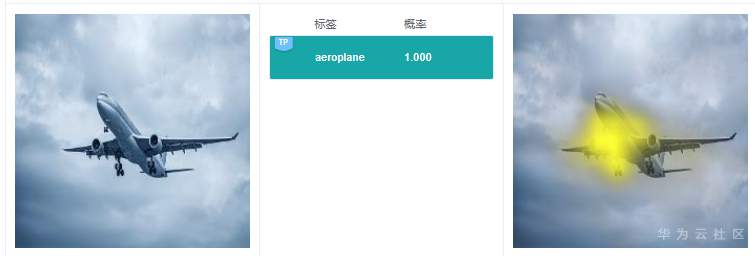
RISE采用遮掩的方法得到与分类结果相关的特征区域,解释结果的可理解性和定位性不错,和GradCAM类似,RISE准确地高亮了路牌区域和飞机区域。
二、MindSpore解释方法如何解释图片分类模型?
在实际应用中,上面介绍的3种解释方法的解释效果如何呢?根据预测结果和解释的有效性,我们将解释结果分为3类,并分别找几个典型的例子来看看实际的效果。
说明:下面所有示例图中的解释结果,都是MindSpore的MindInsight部件中的模型解释特性展现出来的。
2.1 预测结果正确,依据的关键特征合理的例子
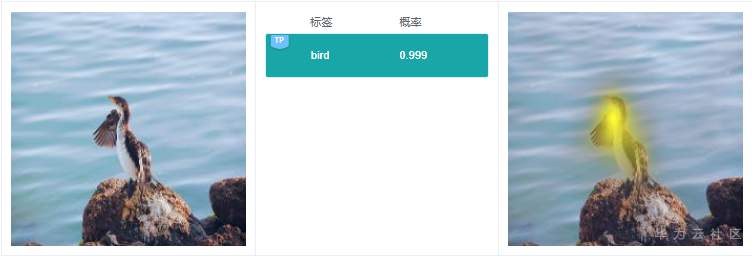
例2.1.1:上图预测标签是“bird”,右边给出依据的关键特征在鸟身上,说明这个分类判断依据是合理的。
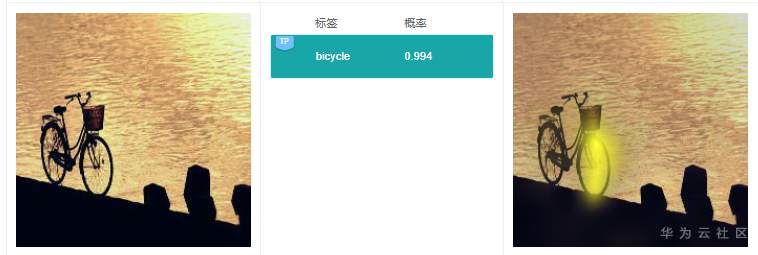
例2.1.2:上图预测标签是“bicycle”,右边解释的时候,将自行车车轮高亮,这个关键特征同样较为合理。
2.2 预测结果正确,但给出的关键特征依据可能是错误的例子
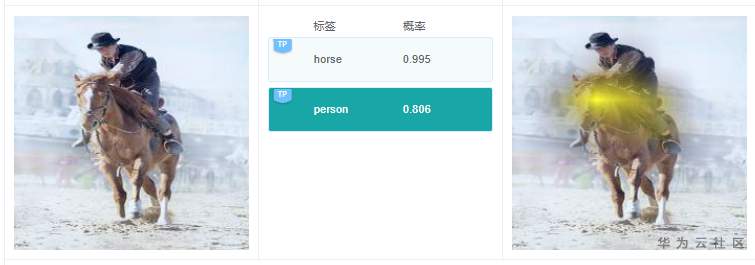
例2.2.1:原图中,有人,在预测标签中有1个标签是“person”,这个结果是对的;但是选择“person”标签,在查看右边解释的时候,可以看到高亮区域在马头上,那么这个关键特征依据很可能是错误的。
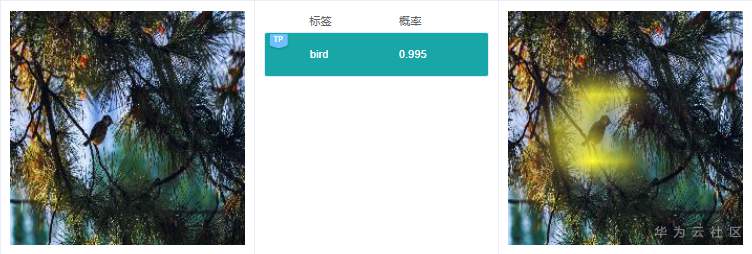
例2.2.2:原图中,有一只鸟,预测结果“bird”是对的,但是右边解释的时候,高亮区域在树枝和树叶上,而不是鸟的身上,这个依据也很可能是错的。
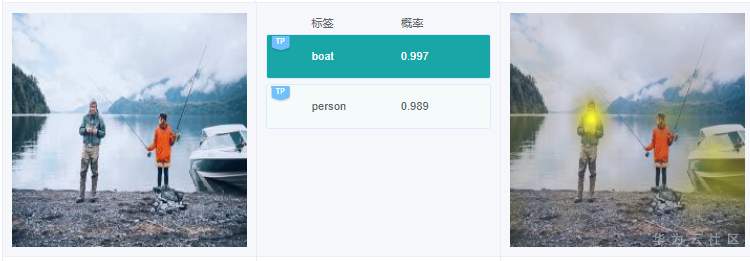
例2.2.3:上图中,有1艘小艇,有个标签是“boat”,这个没错。不过在右边针对标签“boat”的解释,高亮区域却在人身上,这个偏差有点大。
仔细分析上面的3个例子,这种高亮标识出来作为分类依据的关键特征,出现错误的情况,一般出现在图像中存在多目标的场景中。根据调优经验,往往是因为在训练过程中,这些特征经常与目标对象共同出现,导致模型在学习过程中,错误将这些特征识别为关键特征。
2.3 预测结果错误,结合依据的关键特征分析错因的例子
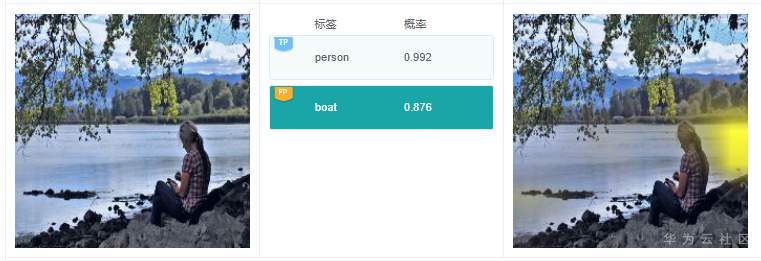
例2.3.1:在上图中,有个预测标签为“boat”,但是原始图像中并没有船只存在,通过图中右侧关于标签“boat”的解释结果可以看到模型将水面作为分类的关键依据,得到预测结果“boat”,这个依据是错误的。通过对训练数据集中标签为“boat”的数据子集进行分析,发现绝大部分标签为“boat”的图片中,都有水面,这很可能导致模型训练的时候,误将水面作为“boat”类型的关键依据。基于此,按比例补充有船没有水面的图片集,从而大幅消减模型学习的时候误判关键特征的概率。
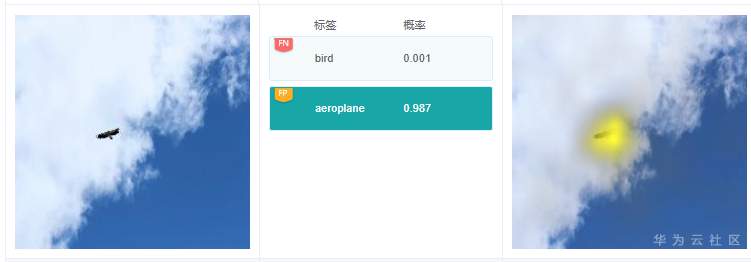
例2.3.2:图中有一个分类预测结果是“aeroplane”,但图中并没有飞机。从标签“aeroplane”的解释结果看,高亮区域在鹰的身上。打开飞机相关的训练数据子集,发现很多情况下训练图片中飞机都是远处目标,与老鹰展翅滑翔很像,猜测可能是这种原因导致模型推理的时候,误将老鹰当做飞机了。模型优化的时候,可以考虑增加老鹰滑翔的图片比例,提升模型的区分和辨别能力,提高分类准确率。
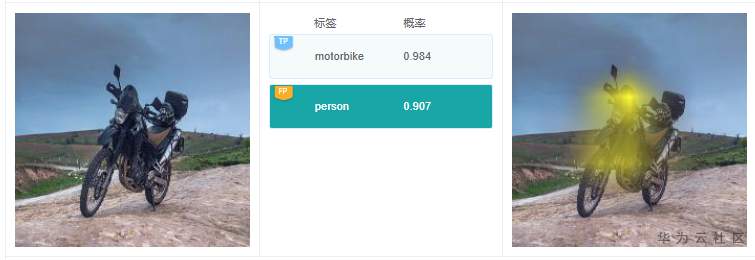
例2.3.3:这个例子中,有个预测标签是“person”,仔细看图中没有人。根据标签“person”的解释结果,高亮区域在摩托车的前部;在原图中,乍一看,还真像一个人趴着;猜测是分类模型推理的时候,误将这部分当做人了。
三、如何部署和使用MindSpore解释方法?
在MindSpore官网的模型解释教程中,详细介绍了如何部署和使用MindSpore提供的解释方法,链接请见:
https://www.mindspore.cn/tutorial/training/zh-CN/r1.1/advanced_use/model_explaination.html
下面,对部署和使用方法,做简要介绍:
先使用脚本调用MindSpore 提供的python API进行解释结果的生成和收集,然后启动MindInsight对这些结果进行展示,整体流程如下图:
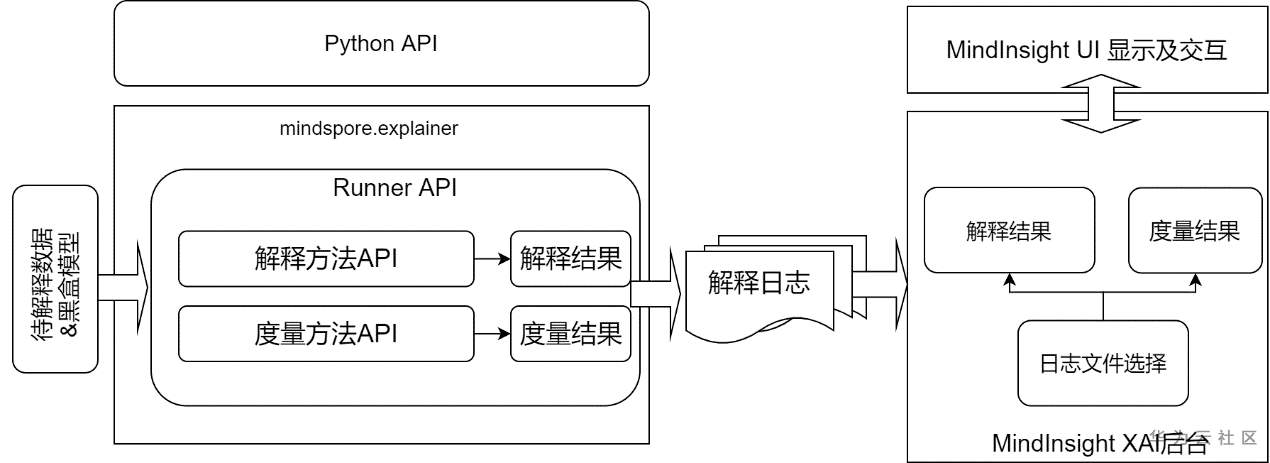
具体步骤如下:
3.1 准备脚本
通过调用解释方法Python API对模型预测结果进行解释,已提供的解释方法可以在mindspore.explainer.explanation包中获取。用户准备好待解释的黑盒模型和数据,在脚本中根据需要实例化解释方法,调用API用于收集解释结果。
MindSpore还提供mindspore.explainer.ImageClassificationRunner接口,支持自动化运行所有解释方法。用户事先将实例化的解释方法进行注册,即可在该接口调用后自动运行解释方法,生成及保存包含解释结果的解释日志。
下面以ResNet50为例,介绍如何初始化explanation中解释方法,调用ImageClassificationRunner进行解释。其样例代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
|
3.2 使用MindInsight进行结果展示
3.2.1 启动MindInsight
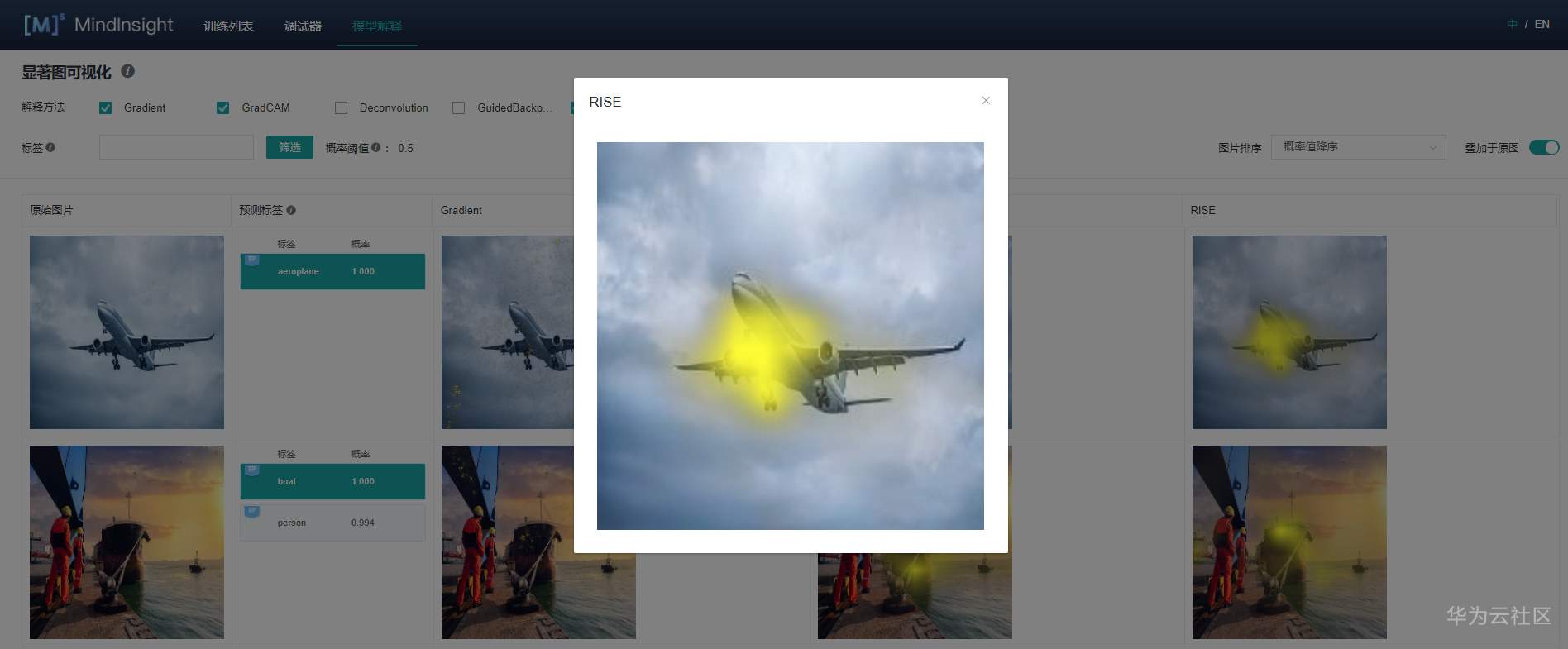
启动MindInsight系统,在顶部选择进入“模型解释”模块。可以看到所有的解释日志路径,当日志满足条件时,操作列会有“显著图可视化”的功能入口。
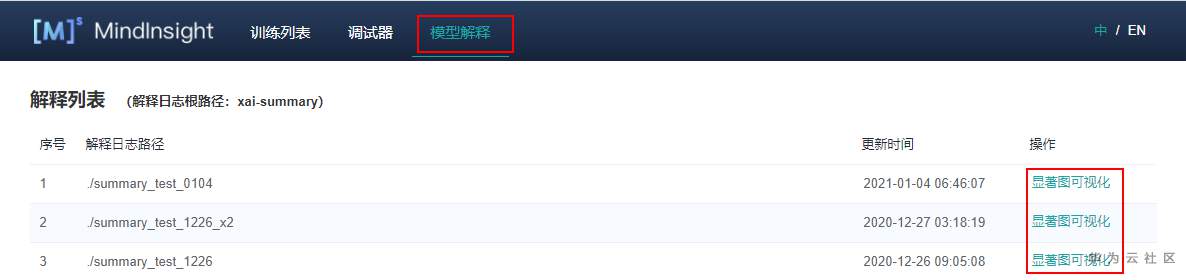
3.2.2 各项功能介绍
显著图可视化用于展示对模型预测结果影响最为显著的图片区域,通常高亮部分可视为图片被标记为目标分类的关键特征。
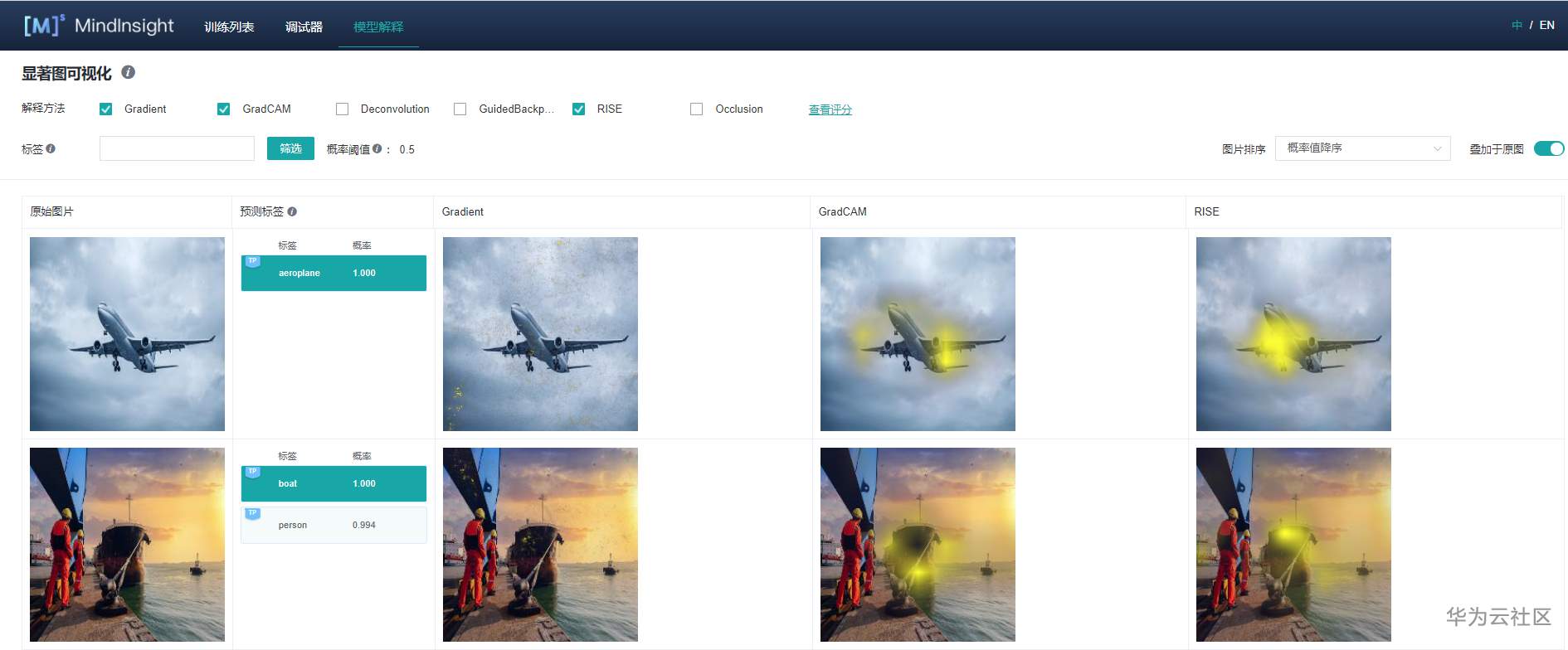
进入显著图可视化界面,如上图,会展现:
-
用户通过Dataset的Python API接口设置的目标数据集。
-
真实标签、预测标签,以及模型对对应标签的预测概率。根据具体情况,系统会在对应标签的左上角增加TP, FP,FN(含义见界面提示信息)的旗标。
-
选中的解释方法给出的显著图。
界面操作介绍:
1. 通过界面上方的解释方法勾选需要的解释方法;
2. 通过切换界面右上方的“叠加于原图”按钮,可以选择让显著图叠加于原图上显示;
3. 点击不同标签,显示对不同标签的显著图分析结果,对于不同的分类结果,通常依据的关键特征区域也是不同的;
4. 通过界面上方的标签筛选功能,筛选出指定标签图片;
5. 通过界面右上角的图片排序改变图片显示的顺序;
6. 点击图片可查看放大图。
四、结束语
至此,MindSpore1.1版本的可解释AI就介绍完毕了。后续版本中,我们将逐步开源更多的可解释AI能力,敬请期待!
MindSpore团队

