
- 1深入理解深度学习——GPT(Generative Pre-Trained Transformer):GPT-2与Zero-shot Learning_gpt2 zeroshot
- 2Java冒泡排序详细讲解
- 3论文笔记--Language Models are Few-Shot Learners
- 4解决vue项目在微信公众号和小程序里的缓存问题_vue 微信公众号缓存
- 5探索TikToken:打造高效、安全的NFT交互体验
- 6Linux环境下Python使用tesseract-ocr4.0_linux pytesseract
- 7MyBatis-Plus和SpringBoot的整合_
com.baomidou - 8信息管理与信息系统毕业论文选题?
- 9RPA正在成为企业应用标配,企业应该如何进行自动化?_电商rpa site:blog.csdn.net
- 10论文报告-Linear Regression for face recognition_线性回归实现人脸识别
在pycharm中配置GPU训练环境(Anaconda)(yolov5)_yolov5模型 pytorch
赞
踩
目录
4.1: conda添加python解释器找不到对应的python.exe文件
4.2: 报错“OSError: [WinError 1455] 页面文件太小,无法完成操作。”
4.3: 报错“CUDA out of memory. Tried to allocate 14.00 MiB
1. 具体的配置过程:
2. 在指定位置(路径)创建虚拟环境:
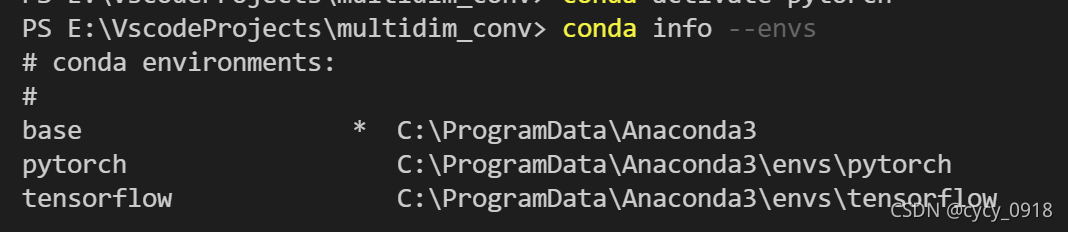
1:使用命令查看当前拥有的虚拟环境
conda info --envs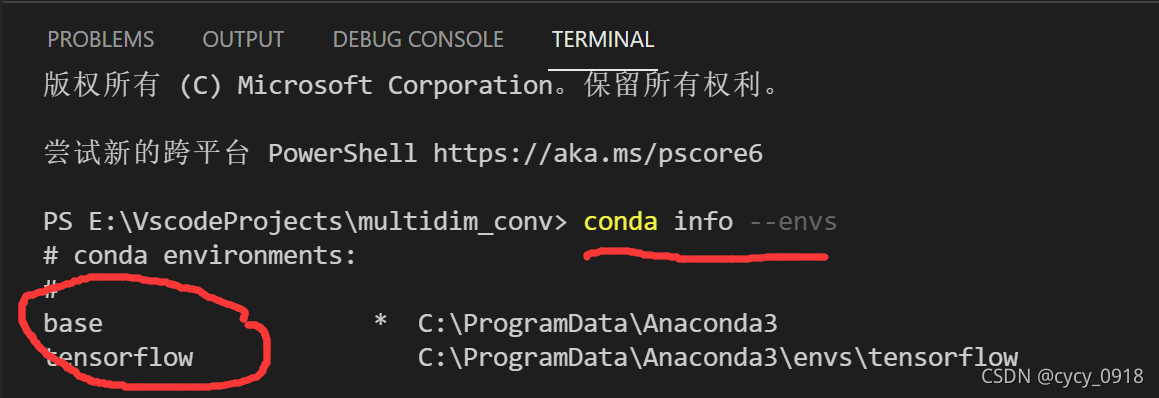
2:在指定目录下创建新的虚拟环境,输入命令:
conda create --prefix=C:/ProgramData/Anaconda3/envs/pytorch python=3.8 其中C:/ProgramData/Anaconda3/envs 是创建的目录所在位置;/pytorch是所创建的环境的名称 python=3.8是创建的python的版本。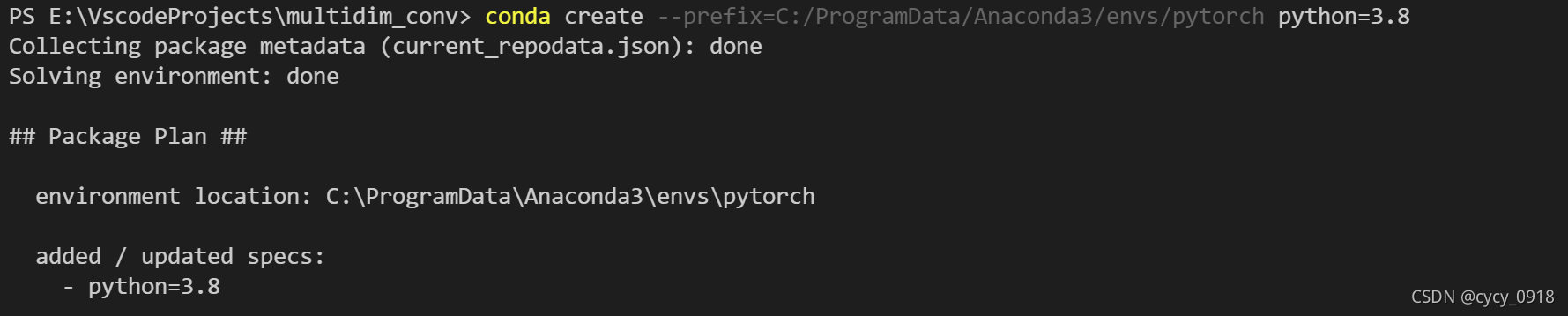
可以看到,验证确实创建在我们想要的位置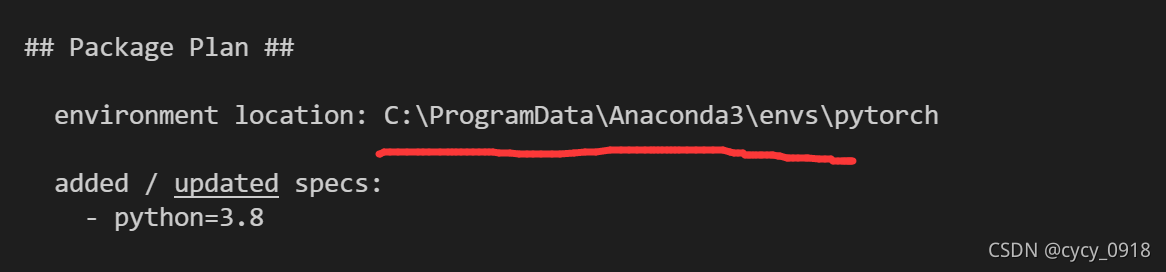
OK啦,创建成功: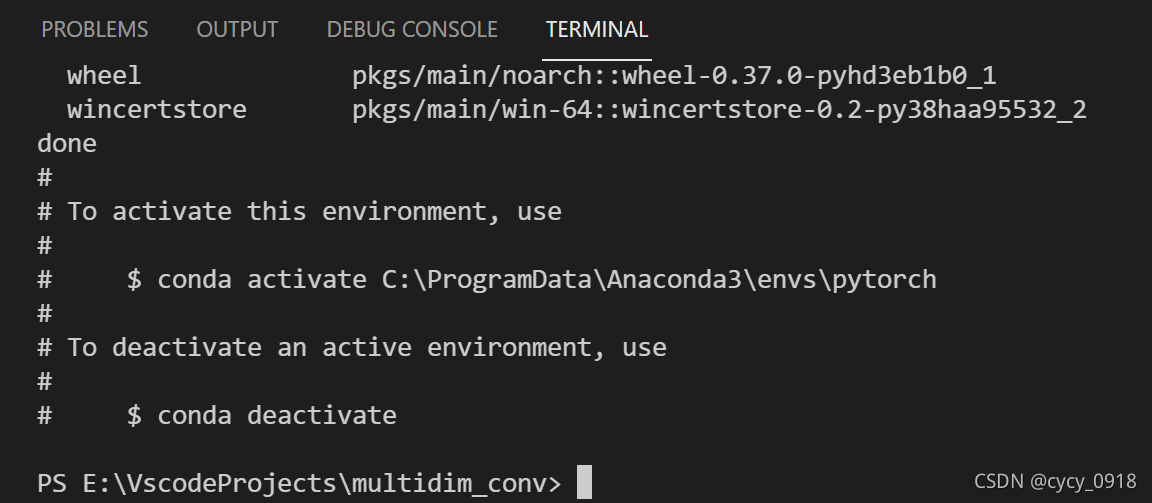
3. conda常用命令:
- 删除虚拟环境的代码如下(yolo5表示env名字)
- 两者选其一:
- conda env remove -n yolo5
-
- conda env remove -p 虚拟环境路径
- 激活虚拟环境
conda activate F:\Anaconda\envs\yolo54: 在跑模型时候遇到的一些问题:
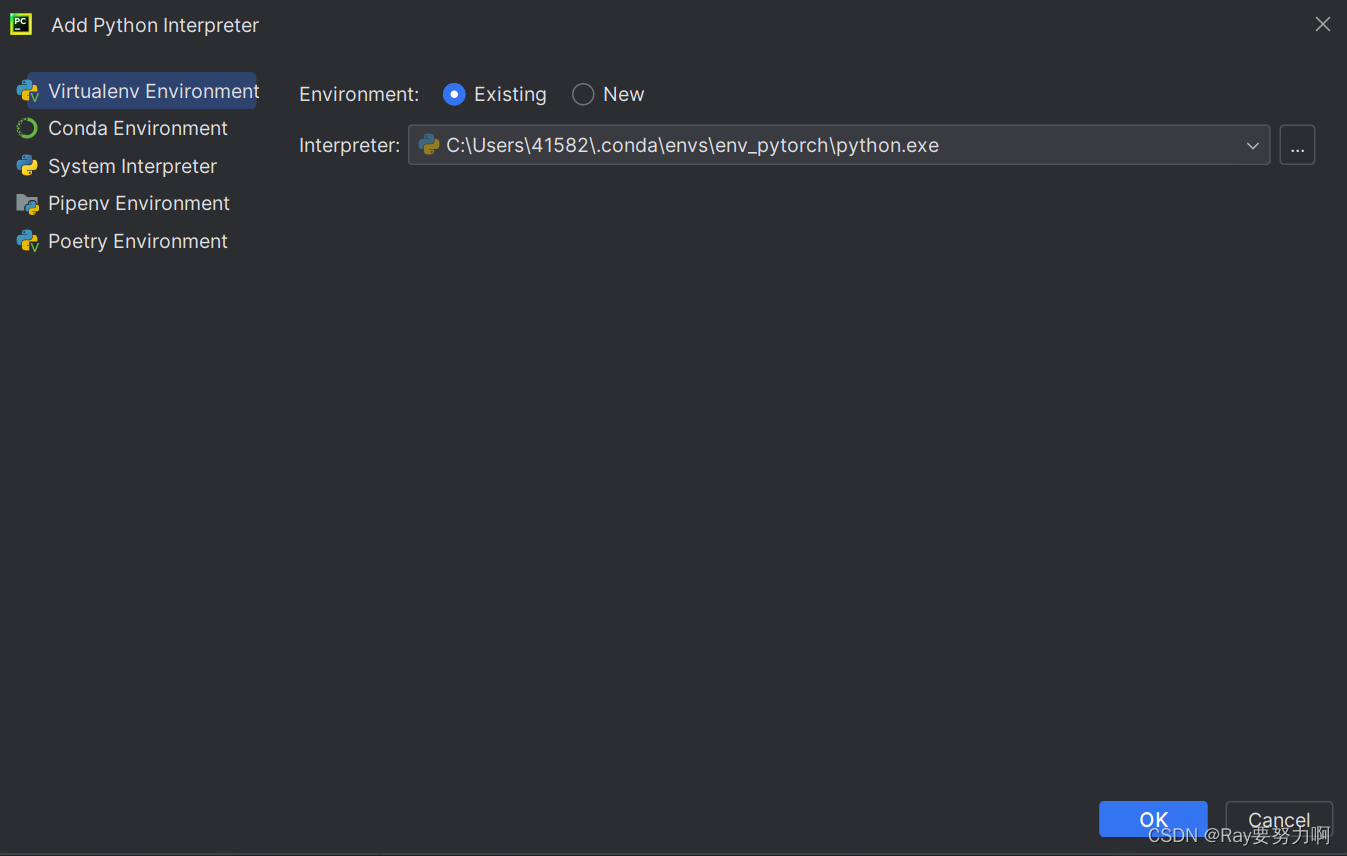
4.1: conda添加python解释器找不到对应的python.exe文件
网上有很多解决方法,我参考了这个:(也是用GPU训练的,如果解释器是anaconda虚拟环境中的python,那效果应该是一样的)
- 直接在Virtualenv Enviroment中找conda的虚拟环境里的python.exe就可以
- 直接在System Environment中找conda的虚拟环境就可以
4.2: 报错“OSError: [WinError 1455] 页面文件太小,无法完成操作。”
这个好像和给cuda虚拟环境所在盘分配的虚拟内存有关:
具体可以参考下边这个博客:
4.3: 报错“CUDA out of memory. Tried to allocate 14.00 MiB
这个应该是训练的模型所设置的batch-size太大了,GPU的显存满足不了
把batch-size调小一些,如设置常用的256 128 64 32 16等,我是把yolov5中的16改为了8,然后问题就迎刃而解了。
最后附上使用GPU训练yolov5模型成功的截图:
(之前用CPU跑同样规模的数据集跑了2个小时,用了GPU只需要16分钟,不得不说真香)

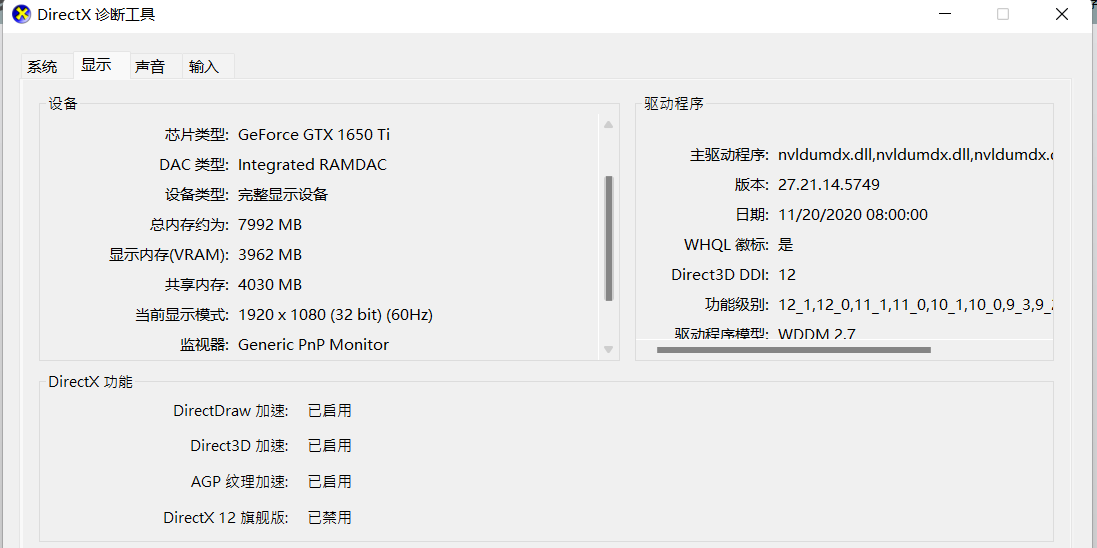
显卡配置:(有钱一定换块好的)
5: CUDA11.1版本出现NAN的问题原因及解决措施:
我在完成上述步骤后,出现了一些错误,具体表现为如下形式:
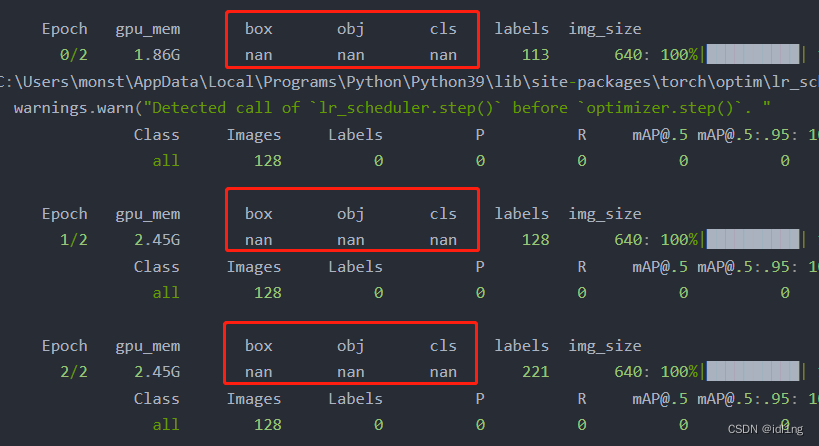
该问题出现的原因在于CUDA版本较高(11.1),最好采用10.2的CUDA版本 ,只需要在虚拟环境中安装10.2的cuda即可,不需要在系统中重新安装。
解决方法可以参考下述博客:
YOLOv5s GTX 1660 Ti训练时出现,box,obj,cla全是nan的问题P、R、mAP都是0,Pytorch和cuda、cudnn版本不对
GTX 16XX系显卡 yolov5训练结果出现NAN的问题
此外,也可能是如下问题导致的:
服务器上训练好的yolov5数据集在自己电脑上什么都检测不出来(已解决)
6: 虚拟环境中的cuda和系统中cuda的区别:
7: 对于动漫角色,训练效果不是很好 :


原本想训练一个自动识别视频中动漫角色(九柱)的模型,但是拿 恋柱——甘露寺蜜璃和水柱——富冈义勇做了小实验(每个选取了各40张图片,其中3张作为验证集),在batch_size=8的情况下epoch=200,最后只能实现识别这两个人物不会出太大问题,但是你喂给它一张猫或狗或者其他柱可能会识别错误(可能是因为数据集太小的缘故,同时动漫人物本身识别也较为困难)
大家如果有开源的鬼灭之刃数据集,可以考虑分享给bz一下,嘿嘿;有问题欢迎在评论区留言!

