
- 1【转】C# 温故而知新:Stream篇(—)_c#stream的子类
- 2垃圾邮件检测:LSTM与Transformer模型在SpamAssassin数据集上的应用_lstm垃圾邮件分类
- 3网络安全相关证书资料——OSCP、CISP-PTE
- 4阿里云实现短信发送_阿里云发送段兴
- 5500个计算机毕业设计项目推荐(源码+论文+PPT)_计算机毕设项目
- 6Attention注意力机制及其在计算机视觉中的应用_attention+视觉
- 7解决每次打开pycharm都特别慢的几个方法_pycharm启动慢
- 8SpringBoot + Mockito单元测试_spring boot mockito
- 9谁说前端已死?低代码没干掉我,chatGPT 又如何!_前端死路一条
- 10【数据结构与算法】图(Graph)【详解】_graph 图
YOLOv5 7.0 网络结构解读
赞
踩
前言
YOLOV5是一系列在COCO数据集上预训练的目标检测架构和模型,结合了在数千个小时的研究和开发中获得的经验教训和最佳实践。本文主要以yolov5s为例介绍YOLOV5-v7.0版本的网络架构及初始化超参数。
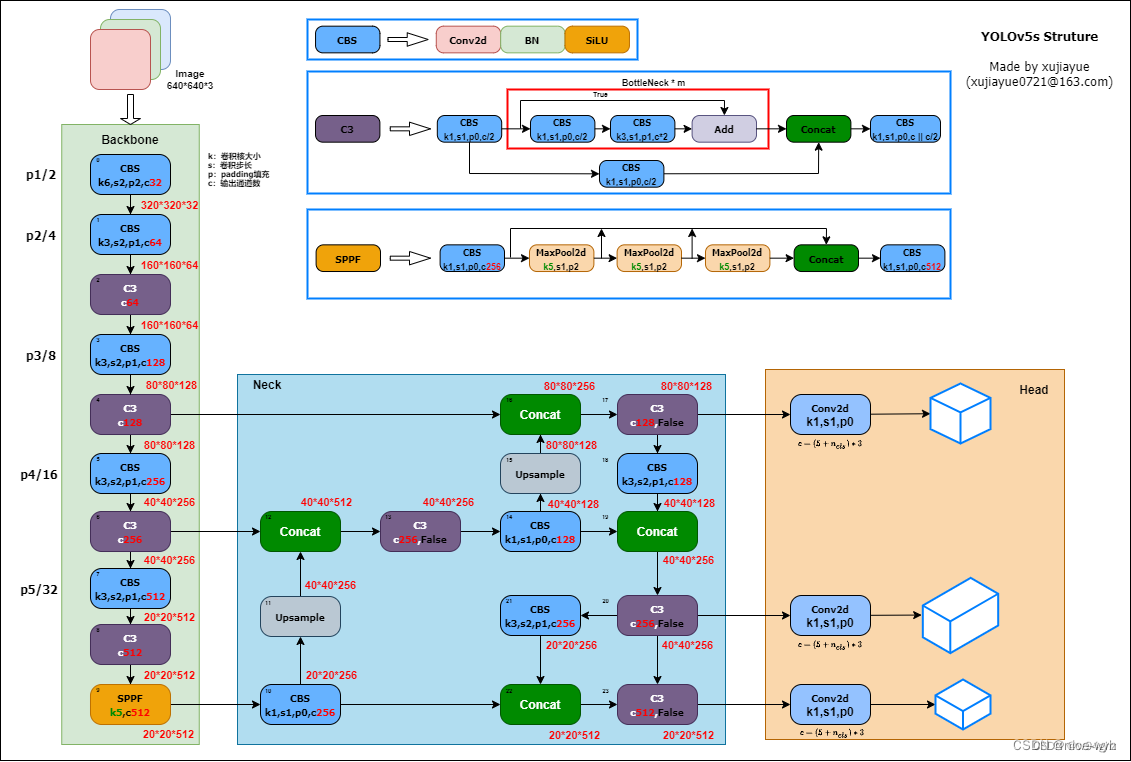
一.YOLOV5s网络结构图
网络结构主要包含以下部分:
1.输入端:自适应锚框计算、自适应图片缩放、Mosaic数据增强
2.Backbone:CBS模块、C3模块、SPPF模块
3.Neck:FPN+PAN结构
4.Head:CIOU Loss
二.输入端
(1)自适应锚框计算
在YOLOV5中,每次训练前,都会根据数据集来自适应计算anchor锚框大小
若觉得计算的锚框效果不好,可以在train.py的参数设置部分将--noautoanchor的default设置为False
1.1计算过程
- 读取训练集的所有图片的w、h以及检测框的w、h
- 将读取的坐标修正为绝对坐标
- 使用Kmeans算法将训练集的所有检测框进行聚类,得到k个anchor
- 通过遗传算法对得到的anchor进行变异,如果变异后的效果好,则将其保留,否则跳过
- 将最终得到的最优anchor按照面积返回
1.2默认锚框
在models下的配置文件yaml下预设了一些针对COCO数据集在640*640图像下的锚定框的尺寸:

anchor的参数一共有三行,每行6个数值;每一行代表不同的特征图;
- 第一行是在最大特征图上的锚框,80*80代表浅层的特征图(P3),包含较多的低层次信息,适合于小目标检测,所以这一行特征图所用的anchor尺度较小
- 第二行是在中间的特征图上的锚框,40*40特征图上就用介于这两个尺寸之间的anchor用来检测中等大小的目标
- 第三行是在最小特征图上的锚框,20*20代表浅层的特征图,包含更多的高层次信息,如轮廓、结构等信息,适合于大目标检测,所以这一行的anchor尺度较大
1.3自定义锚框
锚框核查函数/utils/autoanchor.py文件中:
- def check_anchors(dataset, model, thr=4.0, imgsz=640):
- # Check anchor fit to data, recompute if necessary
- m = model.module.model[-1] if hasattr(model, 'module') else model.model[-1] # Detect()
- shapes = imgsz * dataset.shapes / dataset.shapes.max(1, keepdims=True)
- scale = np.random.uniform(0.9, 1.1, size=(shapes.shape[0], 1)) # augment scale
- wh = torch.tensor(np.concatenate([l[:, 3:5] * s for s, l in zip(shapes * scale, dataset.labels)])).float() # wh
-
- def metric(k): # compute metric
- r = wh[:, None] / k[None]
- x = torch.min(r, 1 / r).min(2)[0] # ratio metric
- best = x.max(1)[0] # best_x
- aat = (x > 1 / thr).float().sum(1).mean() # anchors above threshold
- bpr = (best > 1 / thr).float().mean() # best possible recall
- return bpr, aat
-
- stride = m.stride.to(m.anchors.device).view(-1, 1, 1) # model strides
- anchors = m.anchors.clone() * stride # current anchors
- bpr, aat = metric(anchors.cpu().view(-1, 2))
- s = f'\n{PREFIX}{aat:.2f} anchors/target, {bpr:.3f} Best Possible Recall (BPR). '
- if bpr > 0.98: # threshold to recompute
- LOGGER.info(f'{s}Current anchors are a good fit to dataset ✅')
- else:
- LOGGER.info(f'{s}Anchors are a poor fit to dataset ⚠️, attempting to improve...')
- na = m.anchors.numel() // 2 # number of anchors
- anchors = kmean_anchors(dataset, n=na, img_size=imgsz, thr=thr, gen=1000, verbose=False)
- new_bpr = metric(anchors)[0]
- if new_bpr > bpr: # replace anchors
- anchors = torch.tensor(anchors, device=m.anchors.device).type_as(m.anchors)
- m.anchors[:] = anchors.clone().view_as(m.anchors)
- check_anchor_order(m) # must be in pixel-space (not grid-space)
- m.anchors /= stride
- s = f'{PREFIX}Done ✅ (optional: update model *.yaml to use these anchors in the future)'
- else:
- s = f'{PREFIX}Done ⚠️ (original anchors better than new anchors, proceeding with original anchors)'
- LOGGER.info(s)

YOLOV5在开始训练前会计算数据集标注信息针对默认锚定框的最佳召回率,如果最佳召回率大于或等于0.98,则不需要重新计算锚定框,使用默认锚定框;否则会重新计算符合此数据集的锚定框。
- def metric(k, wh): # compute metrics
- r = wh[:, None] / k[None]
- x = torch.min(r, 1 / r).min(2)[0] # ratio metric
- # x = wh_iou(wh, torch.tensor(k)) # iou metric
- return x, x.max(1)[0] # x, best_x
其中,bpr参数就是判断是否需要重新计算锚定框的依据(是否小于0.98)
重新计算符合此数据集标注的锚定框,是利用k均值聚类算法和遗传算法实现的
(2)Mosaic数据增强
最早出现在YOLOV4,V5也沿用了此技术。
Mosaic数据增强的主要思想是将多张图片按一定比例组合成一张图片,实则是参考了CutMix的数据增强方式,CUtMix是将两张图片进行拼接,Mosaic则是对四张图片进行拼接,拼接后得到一张新的图片,同时也获得了对应的检测框。然后把他传入网络中学习,相当于一下子传入四张图片学习。

Mosaic数据增强的主要步骤:
- 随机选择四张不同的图像作为输入
- 分别对四张图片进行翻转(对原始图片进行左右的翻转)、缩放(对原始图片进行大小的缩放)、色域变化 (对原始图片的明亮度、饱和度、色调进行改变)等操作。
- 操作完成之后然后再将原始图片按照第一张图片摆放在左上,第二张图片摆放在左下,第三张图片摆放在右下,第四张图片摆放在右上四个方向位置摆好。
- 根据每张图片的尺寸变换方式,将映射关系对应到图片标签上。
- 依据指定的横纵坐标,对大图进行拼接。处理超过边界的检测框坐标。
Mosaic数据增强的优点:
- 增加数据多样性,随机选取四张图像进行组合,组合得到图像个数比原图个数要多。
- 增强模型鲁棒性,混合四张具有不同语义信息的图片,可以让模型检测超出常规语境的目标。
- 加强批归一化层(Batch Normalization)的效果。当模型设置BN操作后,训练时会尽可能增大批样本总量(BatchSize) ,因为
BN原理为计算每一个特征层的均值和方差, 如果批样本总量越大,那么BN计算的均值和方差就越接近于整个数据集的均值和方
差,效果越好。
- Mosaic 数据增强算法有利于提升目标检测性能。Mosaic 数据增强图像由四张原始图像拼接而成,这样每张图像会有更大概率包含小目标。
三.Backbone
Backbone主干网络的主要作用是提取特征,并不断缩小特征图。他的主要结构有Conv模块、C3模块、SPPF模块
(1)CBS模块
有一个COnv2d、一个BatchNorm2d和SiLU激活函数构成

- conv2d的padding是自动计算的,通过修改stride来决定特征图缩小的倍数,在commom.py下
- def autopad(k, p=None, d=1): # kernel, padding, dilation
- # Pad to 'same' shape outputs
- if d > 1:
- k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
- if p is None:
- p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
- return p
- 在Backbone中CBS模块的stride均为2, kernel均为3。 因此CBS模块每次会将特征图的宽高减半,下采样特征图,同时提取到目标特征。
- BatchNorm2d为批归一化层,对每批的数据做归一化,其详细作用不在这里赘述。
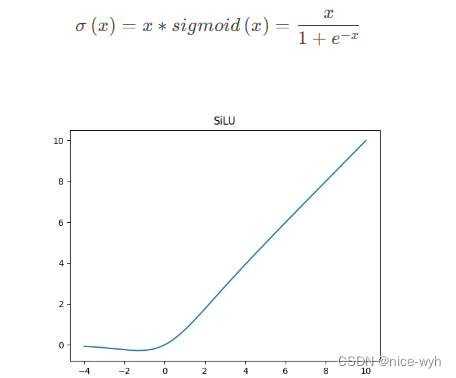
- SiLU激活函数,SiLU是Sigmoid和ReLU的改进版。 SiLU具备无上界有下界、平滑、非单调的特性。SiLU在深层模型 上的效果优于ReLU。具有平滑性和非线性特性,有助于网络在训练过程中更快地收敛。
(2)C3模块
C3模块有三个CBS模块和一个BottleNeck模块组成,因此得名。在Backbone中,C3是更为重要的特征提取模块。其结构如图:
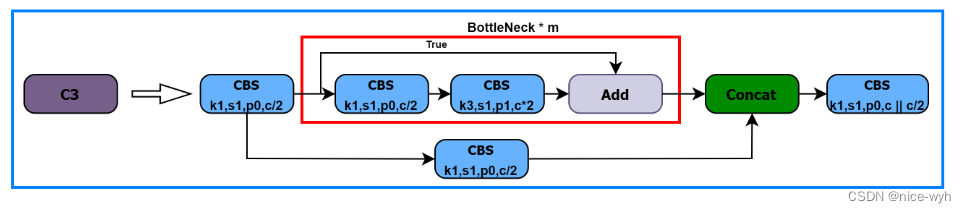
- 进入C3后,将会分为两路,左路经过CBS和一个Bottleneck, 右路只经过一个CBS,最后将两路Concat,再经过一 个CBS。 C3中的3个CBS模块均为1 * 1卷积,起到降维或升维的作用,对于提取特征意义不大。
●Bottleneck在Backbone中使用的是残差连接,Bottleneck中有两个CBS, 第一个CBS为1 * 1卷积,将通道缩减为原来的一半,第二个为3 * 3卷积,将通道数翻倍。先隆维有利王卷积核更好的理解特征信息L升维将有利于提取到更多更详细的特征。
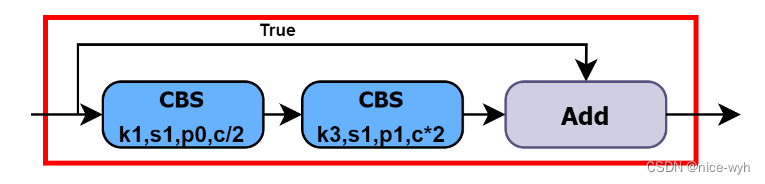
- 在残差结构中,主分支和残差分支的特征图尺寸和维度是相同的。add 操作是将主分支和残差分支的特征图进行直接相加,不会改变特征图的尺寸和维度,只是将对应位置的特征值进行相加。 下述C3中带有False参数则表示不使用残差结构。通过残差结构,可以实现在深层网络中传递梯度和信息的快速传递,并有助于解决深层网络训练中的梯度消失问题。

(3)SPPF
SPP是空间金字塔池化,采用1 x 1, 5x 5, 9x 9, 13 x 13的最大池化的方式,进行多尺度融合。YOLOv5 6.0版本开始使用了在SPP基础上改进的SPPF。
 SPP是将三个并行的MaxPool2d和输入Concat到-起,第一个MaxPool2d的kernel为5*5, 第二个为9*9,第三个为13* 13。用三个不同大小的kernel,代表三个尺度。5 * 5的kernel可以理解为比较大的尺度,而13 * 13就是比较小的尺度。这样就在图片的不同尺度下取到了最大的代表特征值,并Concat融合。
SPP是将三个并行的MaxPool2d和输入Concat到-起,第一个MaxPool2d的kernel为5*5, 第二个为9*9,第三个为13* 13。用三个不同大小的kernel,代表三个尺度。5 * 5的kernel可以理解为比较大的尺度,而13 * 13就是比较小的尺度。这样就在图片的不同尺度下取到了最大的代表特征值,并Concat融合。- SPPF是将三个kernelI为5 * 5的MaxPool2d做串行计算。第-个MaxPool2d表示较大的尺度,第二个MaxPoo在第一个MaxPool2d的基础上进一步做池化,那么产生的尺度将会进一步缩小,第三个同理。
注意:图像的尺度并非指图像的大小,而是指图像的模糊程度(σ) ,例如,人近距离看一个物体和远距离看一 个物体模糊程度是不一样的,从近距离到远距离图像越来越模糊的过程,也是图像的尺度越来越大的过程。
(4)Foucs结果(6.0版本开始启用)

Focus模块是对图片进行切片操作,具体操作是在-张图片中每隔一 个像拿到一个值,这样获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,此时宽高信息就集中到了通道信息,输入通道扩充了四倍。拼接起来的特征层相对于原先的三通道变成了十二个通道,后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
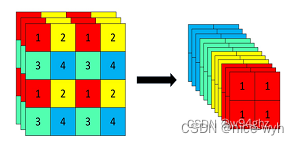
YOLOv5 6 0开始将Focus模块替换成了一个6 * 6的卷积层。两者的计算量是等价的,但使用6 * 6的卷积会更加高效。
四、Neck
Neck的作用就是从Backbone中获取相对于较浅的特征,再与深层的语义特征Concat到-起。
特征金字塔FPN+ PAN
FPN结构通过自顶向下进行上采样,使得底层特征图包含更强的图像强语义信息
- 传入FPN结构中,通过Upsample上采样的方式,向特征图中插值,使特征图的尺寸大,以便于融合来自Backbone的特征图,做特征的向.上融合,特征图不断变大;
- PAN结构自底向上进行下采样,使顶层特征包含图像位置信息,两个特征最后进行融合,使不同尺寸的特征图都包含图像语义信息和图像特征信息,保证了对不同尺寸的图片的准确预测。
总结: FPN层自顶向下可以捕获强语义特征,而PAN则通过自底向上传达强定位特征。
五、Head
Head层为Detect模块,Detect模 块的网络结构很简单,仅由三个1 * 1卷积构成,对应三个检测特征层。
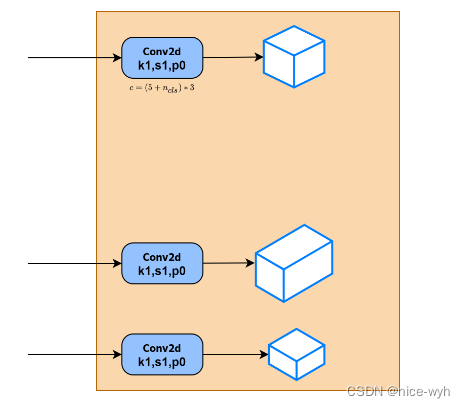
- 上述经过FPN特征金字塔,我们可以获得20* 20*512、40* 40 * 256、80* 80 * 128三个加强特征,然后我们利用这三个shape的特征层传入Yolo Head获得预测结果。
- 对于每一个特征层,我们可以获得利用一个1 * 1卷积调整通道数,最终的通道数和需要区分的种类个数相关,每-个特征层上每一个特征点存在3个先验框。
- 如果使用的是COCO训练集,类则为80种,最后的维度应该为255= 3 * 85,三个特征层的shape为20* 20 * 255、40* 40 *255、80* 80 * 255
最后的255可以拆分成3个85,对应3个先验框的85个参数, 85可以拆分成4 + 1 + 80。
这里的3是指每个位置先验框(锚框)的数量;
前4个参数用于判断每一个特征点的回归参数, 回归参数调整后可以获得预测框;
第5个参数用于判断每一个特征点是否包含物体;
最后80个参数用于判断每一个特征点所包含的物体种类。
六超参数详解
(1)hyp超参数
文件位于data/hyps文件夹下
- # YOLOv5 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/320095推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

