
热门标签
热门文章
- 1NLP之NLTK、spacy、jieba(中文)的使用_python nltk和jieba
- 2同事之间,你就要diao一点!工作,就要会演
- 3国产linux视频播放软件下载,JMPlayer:开发中的国产Linux音乐播放器
- 4HarmonyOS鸿蒙基于Java开发:平行视界
- 5【正点原子Linux连载】 第十一章 Linux并发与竞争 摘自【正点原子】ATK-DLRK3568嵌入式Linux驱动开发指南
- 6【Python】Linux、Windows更换镜像源(pip、conda、pycharm)_linux 修改python镜像源
- 7vue打包错误_vue打包命令失败.js from terser
- 8python 基础 详细,python 基础入门_python入门
- 9华为WLAN产品介绍与组网(包括capwap隧道,ap上线,STA上线,组网方式,转发方式)_华为云 ap 是什么
- 10Ant Design Pro项目部署后在IE上打不开问题解决_ant design pro在ie打不开
当前位置: article > 正文
pytorch 笔记 :实现Dropout_pytorch dropout
作者:2023面试高手 | 2024-04-01 15:08:02
赞
踩
pytorch dropout
1 理论部分
首先说明一点,dropout是用来解决overfitting的,如果在训练集上实验效果就不理想,那么加了dropout也救不了。
第二点是,Dropout常作用在多层感知机的隐藏层输出上,(CNN之类用得不多)

1.1 training时的dropout
使用了Dropout之后,训练的时候,每个神经元都有p的概率不向后传递自己的信息。
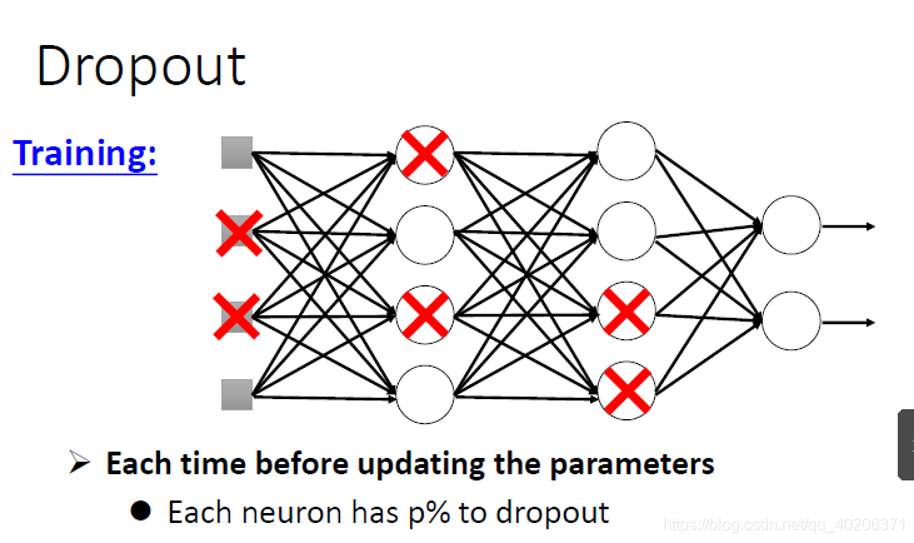
把上图画×的申请元擦掉(因为这些神经元不传递自己的信息,在本轮training中是没有作用的【也就是这些神经元这一轮不会更新】),可以得到一个更“细”的神经网路
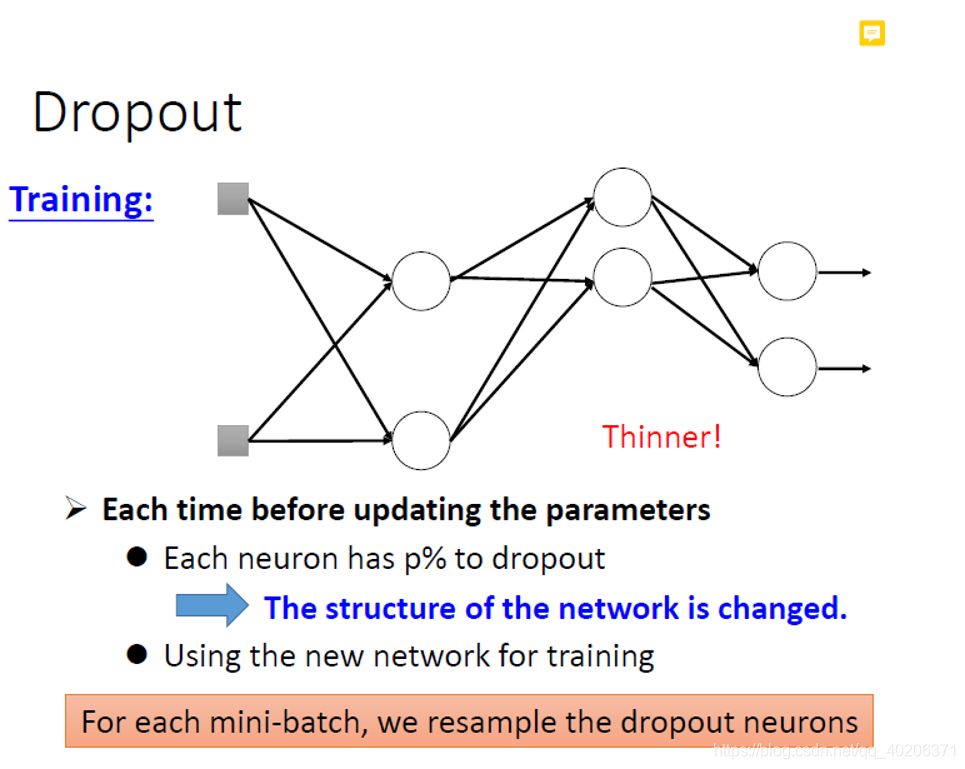
但这并不代表其他的神经元没有作用了。对每个mini-batch,我们重新计算那些神经元参与传递哪些没有。所以最后所有的参数都会被更新的。
1.2 testing时的dropout
测试模型的时候,神经元就都是相连的了,只不过权重值得乘以(1-p%)
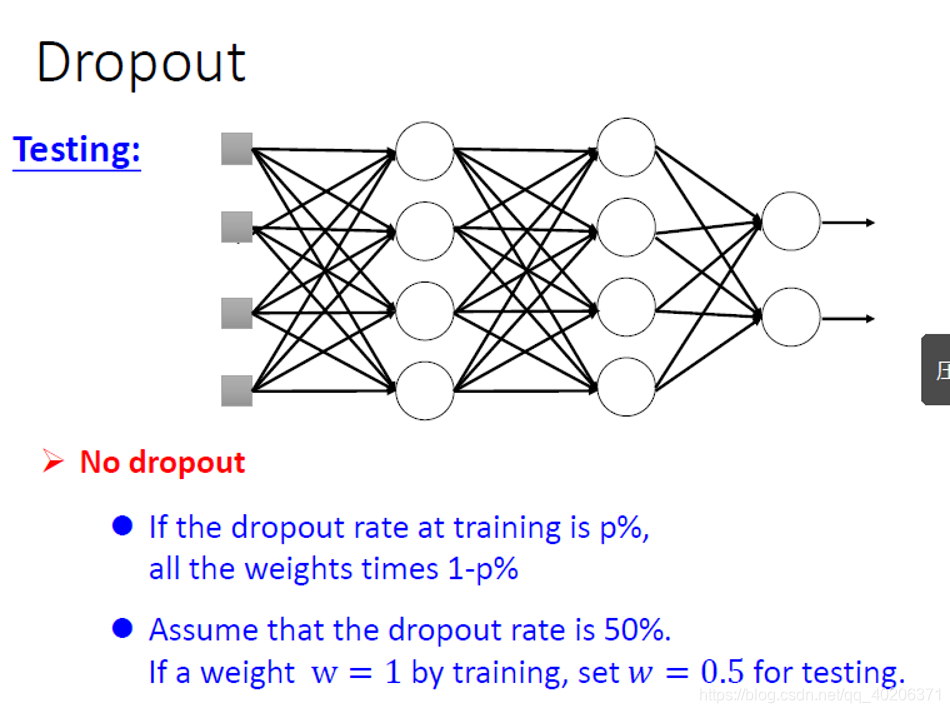
从另一个视角看dropput,它相当于把一堆共享参数的model整合起来

2 pytorch实现Dropout
Dropout训练的时候,需要声明model.train()(不声明也行,因为默认是train状态)
Dropout测试的时候,则是需要声明model.eval()(如果不希望开启dropout进行训练,所有的神经元都参与前向传播和反向传播的话,在训练阶段开启前声明model.eval()即可)
- #导入库
- import torch
-
-
- #神经网络结构声明
- net=torch.nn.Sequential(
- torch.nn.Linear(1,16),
- torch.nn.Dropout(p=0.5),
- torch.nn.ReLU(),
- torch.nn.Linear(16,2)
- )
-
- net.train()
- net.eval()
- net
- '''
- Sequential(
- (0): Linear(in_features=1, out_features=16, bias=True)
- (1): Dropout(p=0.5, inplace=False)
- (2): ReLU()
- (3): Linear(in_features=16, out_features=2, bias=True)
- )
- '''

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/349378
推荐阅读
相关标签

