
- 1VMWare克隆虚拟机之后,IP地址修改_虚拟机克隆后怎么修改ip地址
- 2Git branch && Git checkout常见用法
- 3开源模型应用落地-qwen1.5-7b-chat-LoRA微调(二)
- 4Linux项目自动化构建工具-make/ makefile及其应用:多文件编写第一个linux程序:进度条(懒人学习必备博文!!!)
- 5Javascript基础 86个面试题汇总 (附答案)_javascript面试
- 6《铸梦之路》Untiy高性能自动化UI管理框架ZMUIFramework
- 7spyder安装pyqt5_spyder怎么安装pyqt5
- 81694件AI事件大盘点!2020年12月,哪些让你记忆深刻_最优子集选择问题的多项式算法 王学钦讲座
- 9Matlab怎么计算信号的能量,Matlab小波包分解后如何求各频带信号的能量值? [转]...
- 10朴素贝叶斯(Naive Bayes)_贝叶斯公式小球
浅谈线性多分类分类器(全连接层、SVM、Softmax classifier等)_svm 全连接层
赞
踩
本文在CIFAR-10数据集上举例。CIFAR-10的训练集有50000张32*32*3的图片,包括10个类别。因此形成一个32*32*3 = 3072维的样本空间,此空间中其中包括50000个样本点。
一个机器学习(包括深度学习)多分类器的生命周期包括3大模块:
1.Score Function:
将3072维的input xi转化成一个10维的classfication score vector。这个模块可以plug in包括线性分类器、Neural Network, CNN, RNN等等。score function就是一个mapping,把高维input vector map到想要的低维输出空间上去。linear classifier用matrix multiplication完成了这个mapping,而NN、CNN、RNN则是用多个连接主义的matrix mul、filtering等操作来实现这个mapping。
(1)线性分类器:f(x) = W * x + b:
这里W是10 * 3072 维的matrix,x是3072 * 1维的一个input image flattened vector,b是10 * 1 维的scalar bias values。对于此线性分类器的训练,就是在学习W和b。当W和b训练完成固定之后,分类的test过程就是很简单的矩阵乘法(和加法)。
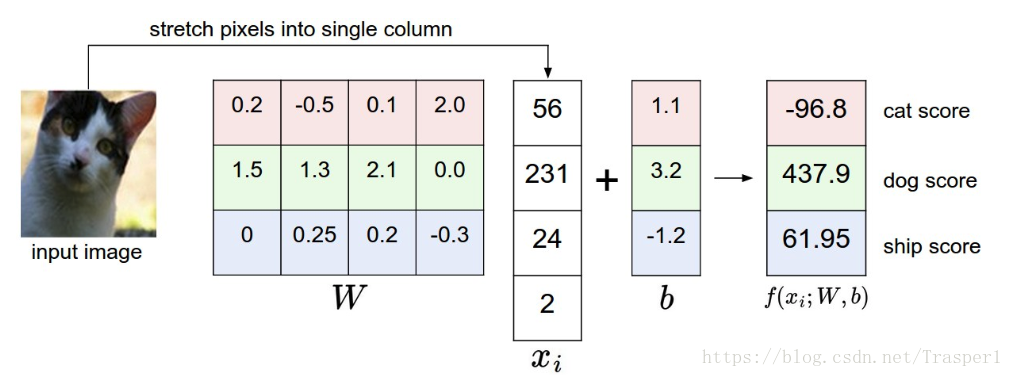
那么如何理解线性分类器呢?换言之,如何理解由W完成一次matrix multiplication就可以实现分类呢?W又有什么物理意义呢?
i. W的ensemble理解:
10*3072的W可以理解为10个1*3072维的row vector,每个row vector是CIFAR-10 10中类别中一类的打分器。每个row vector对应最终10*1维输出中的一维,即某个1*3072 vector of W 乘以 xi输出一个scalar value,这个实数就是该样本xi属于这个row vector对应类别的classification score。换言之,W * xi的矩阵乘法而不是向量乘法,是一中并行计算的模式,一次性完成10个类别的打分。
那么,W的每个row vector中的3072个数字又各自有什么意义呢?当将row vector与xi(3072 * 1)这个flattened image vector进行dot-product时,是对位相乘再相加:

