
热门标签
热门文章
- 1基于Python爬虫宁夏银川天气预报数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状_python的arima天气预测的研究背景
- 2linux open firmware,Firmware/Open
- 3微信小程序--小程序框架_微信小程序框架
- 4HTML常用标签总结_html标签大全
- 5flex布局详解
- 605、Kafka ------ 各个功能的作用解释(主题和分区 详解,用命令行和图形界面创建主题和查看主题)_cmak查看主题内容消息
- 7Android-桌面小组件RemoteViews播放动画_android桌面小组件动画
- 8宝塔安装mayfly-go
- 9王小川的大模型打造秘籍首次曝光:五步走,两个月炼成
- 10JAVA单机五子棋小游戏(双人对战版)
当前位置: article > 正文
浅谈对transforms.ToTensor()和transforms.Normalize()函数的理解_totensor函数
作者:2023面试高手 | 2024-04-02 05:51:51
赞
踩
totensor函数
前言
在进行tensor图片数据进行视觉时,一般会进行预处理操作,这个时候就需要用到ToTensor()和Normalize()这两个函数.
提示:以下是本篇文章正文内容,下面案例可供参考
一.ToTensor函数
1.ToTensor函数的作用
1.将shape为(H,W,C)的数据维度转变为(C,H,W),其中C表示通道数,H表示高度,W表示宽度。
2. 将输入数据归一化到(0,1)的范围内,其归一化方法为除以255进行缩放
2.代码实现
import torch import torchvision from torchvision.transforms import transforms import numpy as np '''tranforms.Compose将多个函数进行组合''' tranforms_1 = transforms.Compose([transforms.ToTensor()]) tensor1 = np.array([[[1,2,3],[4,5,6],[7,8,9],[5,6,7]], [[1,2,3],[4,5,6],[7,8,9],[5,6,7]], [[1,2,3],[4,5,6],[7,8,9],[5,6,7]], [[1,2,3],[4,5,6],[7,8,9],[5,6,7]]],dtype = np.float32) print(f'未转换数据前数据的维度为{tensor1.shape}') #(4,4,3) trans_tensor1 = tranforms_1(tensor1) print(f'转换后数据的维度为{trans_tensor1.shape}') #(3,4,4)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3.数据没有归一化问题
可以看到,在经过ToTensor()函数的处理之后,维度确实发生了变化,达到预期的效果,接下来再输出转换前的数据和转换后的数据。
print(tensor1[0])
#[[1. 2. 3.]
#[4. 5. 6.]
#[7. 8. 9.]
#[5. 6. 7.]]
print(trans_tensor1[0])
#tensor([[1., 4., 7., 5.],
#[1., 4., 7., 5.],
#[1., 4., 7., 5.],
# [1., 4., 7., 5.]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
可以发现,转换后的trans_tensor1虽然维度确实发现了变化,可是数据应该缩放到[0,1]的范围,但是数据本身却没有发生变化,进入到ToTensor()的实现函数查看原因
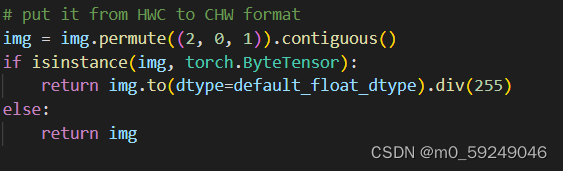
可以看到,传入的数据需要是字节类型的数据,否则会返回传入的数据本身。那么传入的数据类型究竟应该是什么呢?接下来使用cv函数读取图片并转换数据查看结果
import cv2 images = cv2.imread('../data/cat1.jpg') images_result = tranforms_1(images) #(288, 352, 3) torch.Size([3, 288, 352]) print(images.shape,images_result.shape) print(images_result[0]) # tensor([[0.9765, 0.9961, 1.0000, ..., 0.9647, 0.9647, 0.9647], # [0.9686, 0.9922, 1.0000, ..., 0.9608, 0.9686, 0.9608], # [0.9255, 0.9647, 0.9922, ..., 0.9765, 0.9843, 0.9765], # ..., # [0.0392, 0.3098, 0.4157, ..., 0.2118, 0.2157, 0.2157], # [0.0588, 0.2627, 0.3098, ..., 0.1608, 0.1608, 0.1608], # [0.0196, 0.0706, 0.0392, ..., 0.0549, 0.0549, 0.0510]]) print(images.dtype) #unit8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
在传入图片调用ToTensor()函数后,发现数据的维度发生了变化,数据也归一化,输出image的数据类型发现,为unit8,接着我们将前面的numpy数组的数据类型转变为unit8后发现,输出结果正常,因此传入的数据需要为unit8
tensor1 = np.array([[[1,2,3],[4,5,6],[7,8,9],[5,6,7]], [[1,2,3],[4,5,6],[7,8,9],[5,6,7]], [[1,2,3],[4,5,6],[7,8,9],[5,6,7]], [[1,2,3],[4,5,6],[7,8,9],[5,6,7]]],dtype = np.uint8) #[[1 2 3] #[4 5 6] #[7 8 9] #[5 6 7]] print(tensor1[0]) #tensor([[0.0039, 0.0157, 0.0275, 0.0196], # [0.0039, 0.0157, 0.0275, 0.0196], # [0.0039, 0.0157, 0.0275, 0.0196], # [0.0039, 0.0157, 0.0275, 0.0196]]) print(trans_tensor1[0])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
二.Normalize()函数
1.Normalize函数的作用
Normalize()函数的作用是将数据转换为标准高斯分布,每个通道都进行标准化,即每个通道的均值都变为0,标准差都变为1,这样可以加快模型的收敛。
2.代码实现
`'''均值mean=[0.485, 0.456, 0.406],
标准差std=[0.229, 0.224, 0.225]
这一组数据是由Imagenet训练集中抽样训练出来的'''
tranforms_2 = transforms.Compose([transforms.ToTensor(),transforms.Normalize
(mean = [0.485, 0.456, 0.406],
std = [0.229, 0.224, 0.225])])
tensor1 = np.array([[[1,2,3],[4,5,6],[7,8,9],[5,6,7]],
[[1,2,3],[4,5,6],[7,8,9],[5,6,7]],
[[1,2,3],[4,5,6],[7,8,9],[5,6,7]],
[[1,2,3],[4,5,6],[7,8,9],[5,6,7]]],dtype = np.uint8)
trans_tensor2 = tranforms_2(tensor1)
trans_tensor2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/351037
推荐阅读
相关标签

