
- 1【数据结构】线性表部分习题2(顺序表与链表)
- 2Android科大讯飞TTS语音合成实例详细步骤_科大讯飞 tts文档
- 3Failed to start docker.service: Unit docker.service is masked.
- 4Mac OS X下如何使用OpenGL
- 5pytorch 遇到 ImportError cannot import name ‘Iterator‘ from ‘torchtext.data‘_oserror: /home/lx207/.local/lib/python3.8/site-pac
- 6VPN原理、IPsecVPN、SSL VPN
- 7离散数学_所有极大项的析取为永真式
- 8什么是残差矢量量化?_rvq原理
- 9致远OA任意文件上传_致远oa文件上传
- 10transformer中的positional encoding(位置编码)_transformer 位置编码和 embed 维度关系
TCN(Temporal Convolutional Network,时间卷积网络)
赞
踩
1 前言
实验表明,RNN 在几乎所有的序列问题上都有良好表现,包括语音/文本识别、机器翻译、手写体识别、序列数据分析(预测)等。
在实际应用中,RNN 在内部设计上存在一个严重的问题:由于网络一次只能处理一个时间步长,后一步必须等前一步处理完才能进行运算。这意味着 RNN 不能像 CNN 那样进行大规模并行处理,特别是在 RNN/LSTM 对文本进行双向处理时。这也意味着 RNN 极度地计算密集,因为在整个任务运行完成之前,必须保存所有的中间结果。
CNN 在处理图像时,将图像看作一个二维的“块”(m*n 的矩阵)。迁移到时间序列上,就可以将序列看作一个一维对象(1*n 的向量)。通过多层网络结构,可以获得足够大的感受野。这种做法会让 CNN 非常深,但是得益于大规模并行处理的优势,无论网络多深,都可以进行并行处理,节省大量时间。这就是 TCN 的基本思想。
1.1 RNN的问题
LightRNN:高效利用内存和计算的循环神经网络_曼陀罗彼岸花的博客-CSDN博客
将RNN内存占用缩小90%:多伦多大学提出可逆循环神经网络:将RNN内存占用缩小90%:多伦多大学提出可逆循环神经网络 - 知乎

循环神经网络(RNN)在处理序列数据方面取得了当前最佳的性能表现,但训练时需要大量内存,需要存储隐藏状态。
最近,循环神经网络(RNN)已被用于处理多种自然语言处理(NLP)任务,例如语言建模、机器翻译、情绪分析和问答。有一种流行的 RNN 架构是长短期记忆网络(LSTM),其可以通过记忆单元(memory cell)和门函数(gating function)建模长期依赖性和解决梯度消失问题。因为这些元素,LSTM 循环神经网络在当前许多自然语言处理任务中都实现了最佳的表现,尽管它的方式几乎是从头开始学习。
虽然 RNN 越来越受欢迎,但它也存在一个局限性:当应用于大词汇的文本语料库时,模型的体量将变得非常大。比如说,当使用 RNN 进行语言建模时,词首先需要通过输入嵌入矩阵(input-embedding matrix)从 one-hot 向量(其维度与词汇尺寸相同)映射到嵌入向量。然后为了预测下一词的概率,通过输出嵌入矩阵(output-embedding matrix)将顶部隐藏层投射成词汇表中所有词的概率分布。当该词汇库包含数千万个不同的词时(这在 Web 语料库中很常见),这两个嵌入矩阵就会包含数百亿个不同的元素,这会使得 RNN 模型变得过大,从而无法装进 GPU 设备的内存。以 ClueWeb 数据集为例,其词汇集包含超过 1000 万词。如果嵌入向量具有 1024 个维度并且每个维度由 32 位浮点表示,则输入嵌入矩阵的大小将为大约 40GB。进一步考虑输出嵌入矩阵和隐藏层之间的权重,RNN 模型将大于 80GB,这一数字远远超出了市面上最好的 GPU 的能力。
即使 GPU 的内存可以扩容,用于训练这样体量模型的计算复杂度也将高到难以承受。在 RNN 语言模型中,最耗时的运算是计算词汇表中所有词的概率分布,这需要叠乘序列每个位置处的输出嵌入矩阵和隐藏状态。简单计算一下就可以知道,需要使用目前最好的单 GPU 设备计算数十年才能完成 ClueWeb 数据集语言模型的训练。此外,除了训练阶段的难题,即使我们最终训练出了这样的模型,我们也几乎不可能将其装进移动设备让它进入应用。
1.2 TCN背景
到目前为止,深度学习背景下的序列建模主题主要与递归神经网络架构(如LSTM和GRU)有关。S. Bai等人(*)认为,这种思维方式已经过时,在对序列数据进行建模时,应该将卷积网络作为主要候选者之一加以考虑。他们能够表明,在许多任务中,卷积网络可以取得比RNNs更好的性能,同时避免了递归模型的常见缺陷,如梯度爆炸/消失问题或缺乏内存保留。此外,使用卷积网络而不是递归网络可以提高性能,因为它允许并行计算输出。他们提出的架构称为时间卷积网络(TCN),将在下面的部分中进行解释。
TCN是指时间卷积网络,一种新型的可以用来解决时间序列预测的算法。
该算法于2016年由Lea等人首先提出,当时他们在做视频动作分割的研究,一般而言此常规过程包括两个步骤:首先,使用(通常)对时空信息进行编码的CNN来计算低级特征,其次,将这些低级特征输入到使用(通常是)捕获高级时域信息的分类器中)RNN。这种方法的主要缺点是需要两个单独的模型。
TCN提供了一种统一的方法来分层捕获所有两个级别的信息。
自从TCN提出后引起了巨大反响,有人认为:时间卷积网络(TCN)将取代RNN成为NLP或者时序预测领域的王者。
DataScienceCentral 的编辑主任William Vorhies给出的原因如下:
RNN耗时太长,由于网络一次只读取、解析输入文本中的一个单词(或字符),深度神经网络必须等前一个单词处理完,才能进行下一个单词的处理。这意味着 RNN 不能像 CNN 那样进行大规模并行处理;并且TCN的实际结果也要优于RNN算法。
TCN可以采用一系列任意长度并将其输出为相同长度。在使用一维完全卷积网络体系结构的情况下,使用因果卷积。一个关键特征是,时间t的输出仅与t之前发生的元素卷积。
2 TCN特点
TCN 模型以 CNN 模型为基础,并做了如下改进:
- 适用序列模型:因果卷积(Causal Convolution)
- 记忆历史:空洞卷积/膨胀卷积(Dilated Convolution),残差模块(Residual block)
下面将分别介绍 CNN 的扩展技术。
TCN的特点:
- 因果卷积网络
- 膨胀卷积方式(扩张卷积、空洞卷积)Dilated Causal Convolution
- 残差块
- 激活函数
- 规范化
- 正则化
- Dropout
2.1 因果卷积(Causal Convolution)

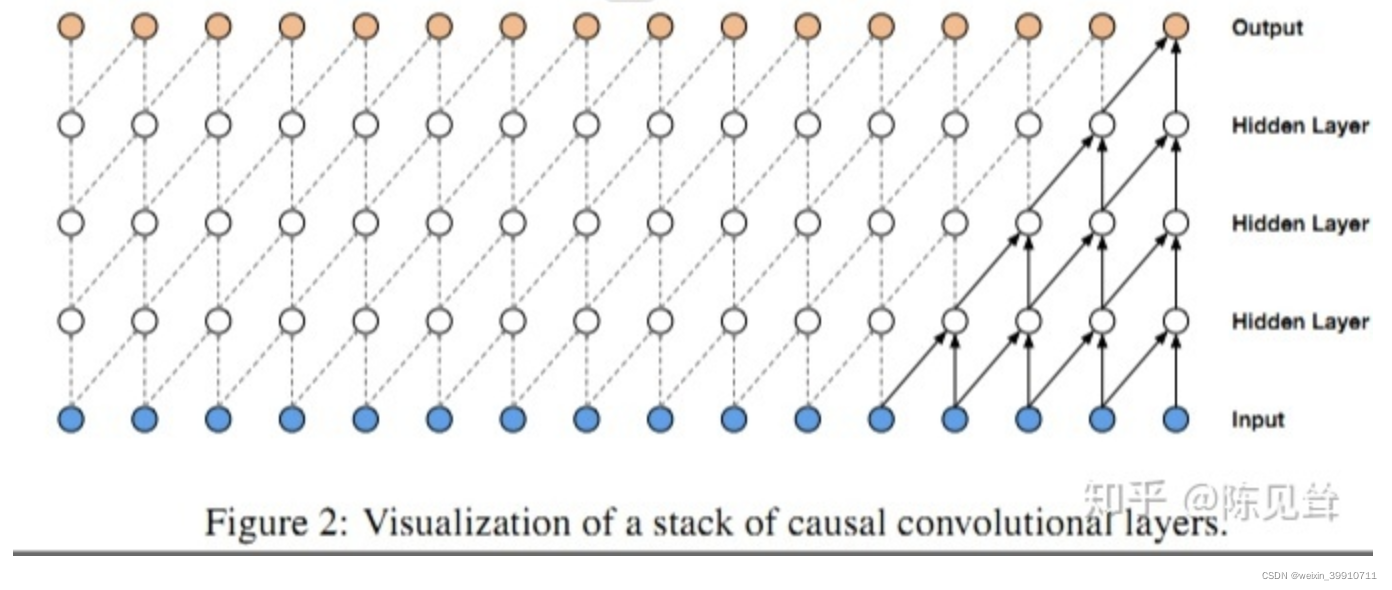
因果卷积可以用上图直观表示。 即对于上一层t时刻的值,只依赖于下一层t时刻及其之前的值。和传统的卷积神经网络的不同之处在于,因果卷积不能看到未来的数据,它是单向的结构,不是双向的。也就是说只有有了前面的因才有后面的果,是一种严格的时间约束模型,因此被成为因果卷积。
因果卷积有两个特点:
- 不考虑未来的信息。给定输入序列
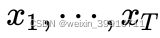 ,预测
,预测  。但是在预测
。但是在预测 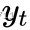 时,只能使用已经观测到的序列 ,而不能使用
时,只能使用已经观测到的序列 ,而不能使用 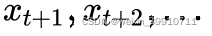 。
。 - 追溯历史信息越久远,隐藏层越多。上图中,假设我们以第二层隐藏层作为输出,它的最后一个节点关联了输入的三个节点,即
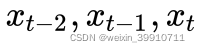 ;假设以输出层作为输出,它的最后一个节点关联了输入的五个节点。
;假设以输出层作为输出,它的最后一个节点关联了输入的五个节点。
2.2 空洞卷积/膨胀卷积(Dilated Convolution)
单纯的因果卷积还是存在传统卷积神经网络的问题,即对时间的建模长度受限于卷积核大小的,如果要想抓去更长的依赖关系,就需要线性的堆叠很多的层。标准的 CNN 可以通过增加 pooling 层来获得更大的感受野,而经过 pooling 层后肯定存在信息损失的问题。
空洞卷积是在标准的卷积里注入空洞,以此来增加感受野。空洞卷积多了一个超参数 dilation rate,指的是 kernel 的间隔数量(标准的 CNN 中 dilatation rate 等于 1)。空洞的好处是不做 pooling 损失信息的情况下,增加了感受野,让每个卷积输出都包含较大范围的信息。下图展示了标准 CNN (左)和 Dilated Convolution (右),右图中的 dilatation rate 等于 2 。
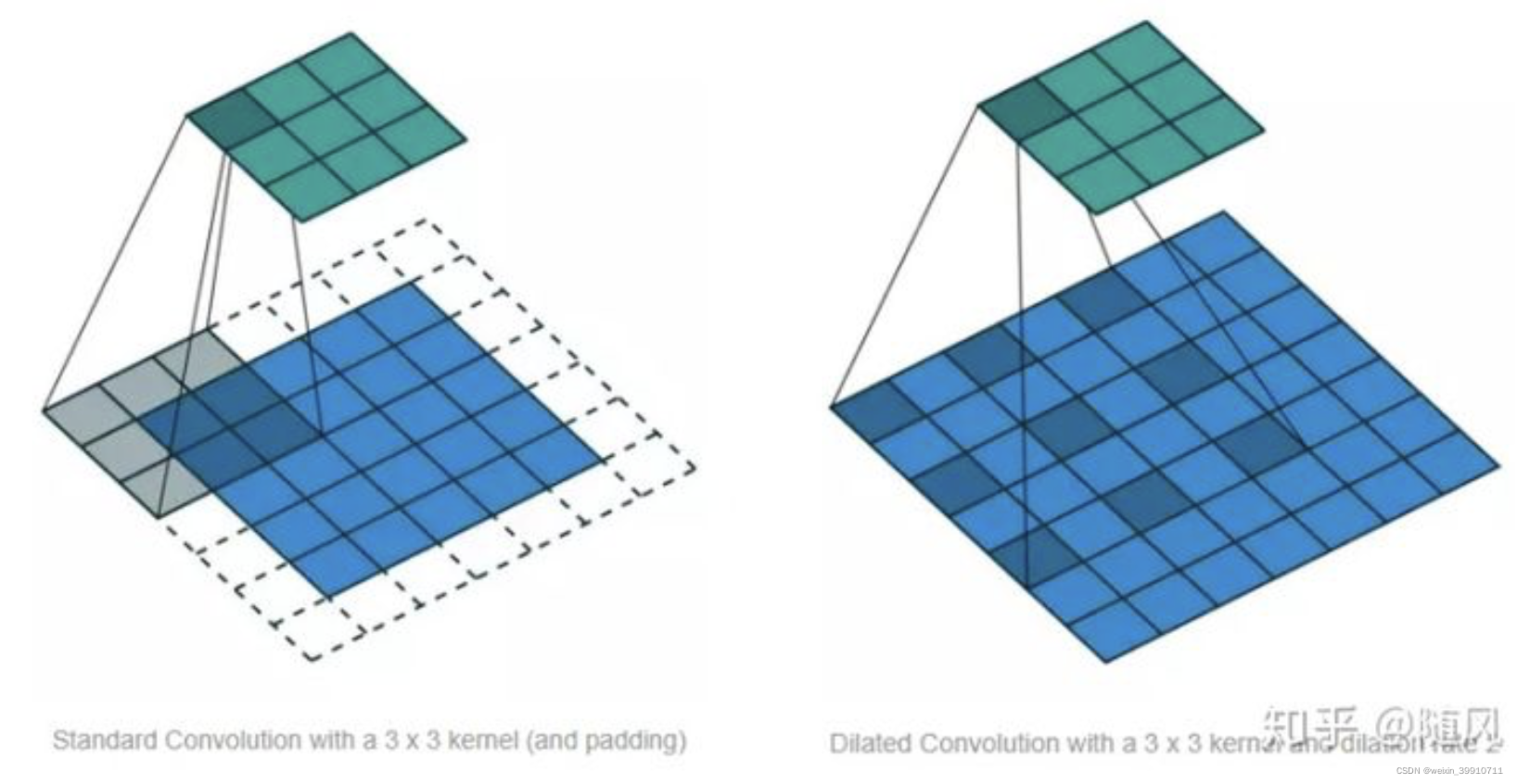
和传统卷积不同的是,膨胀卷积允许卷积时的输入存在间隔采样,采样率受图中的d控制。 最下面一层的d=1,表示输入时每个点都采样,中间层d=2,表示输入时每2个点采样一个作为输入。一般来讲,越高的层级使用的d的大小越大。所以,膨胀卷积使得有效窗口的大小随着层数呈指数型增长。这样卷积网络用比较少的层,就可以获得很大的感受野。
空洞卷积的参数:
- d:层数
- k:内核大小,filter size
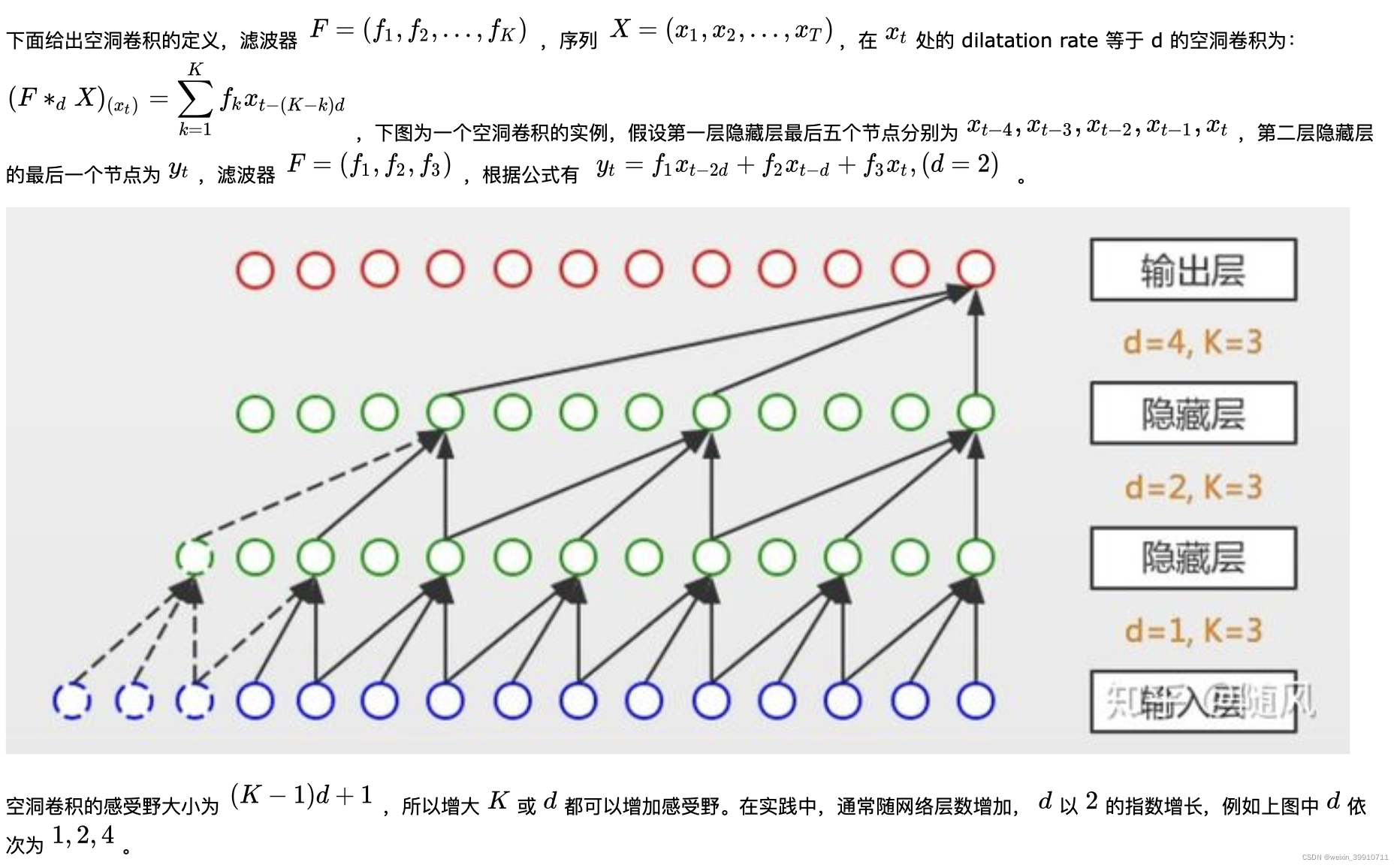
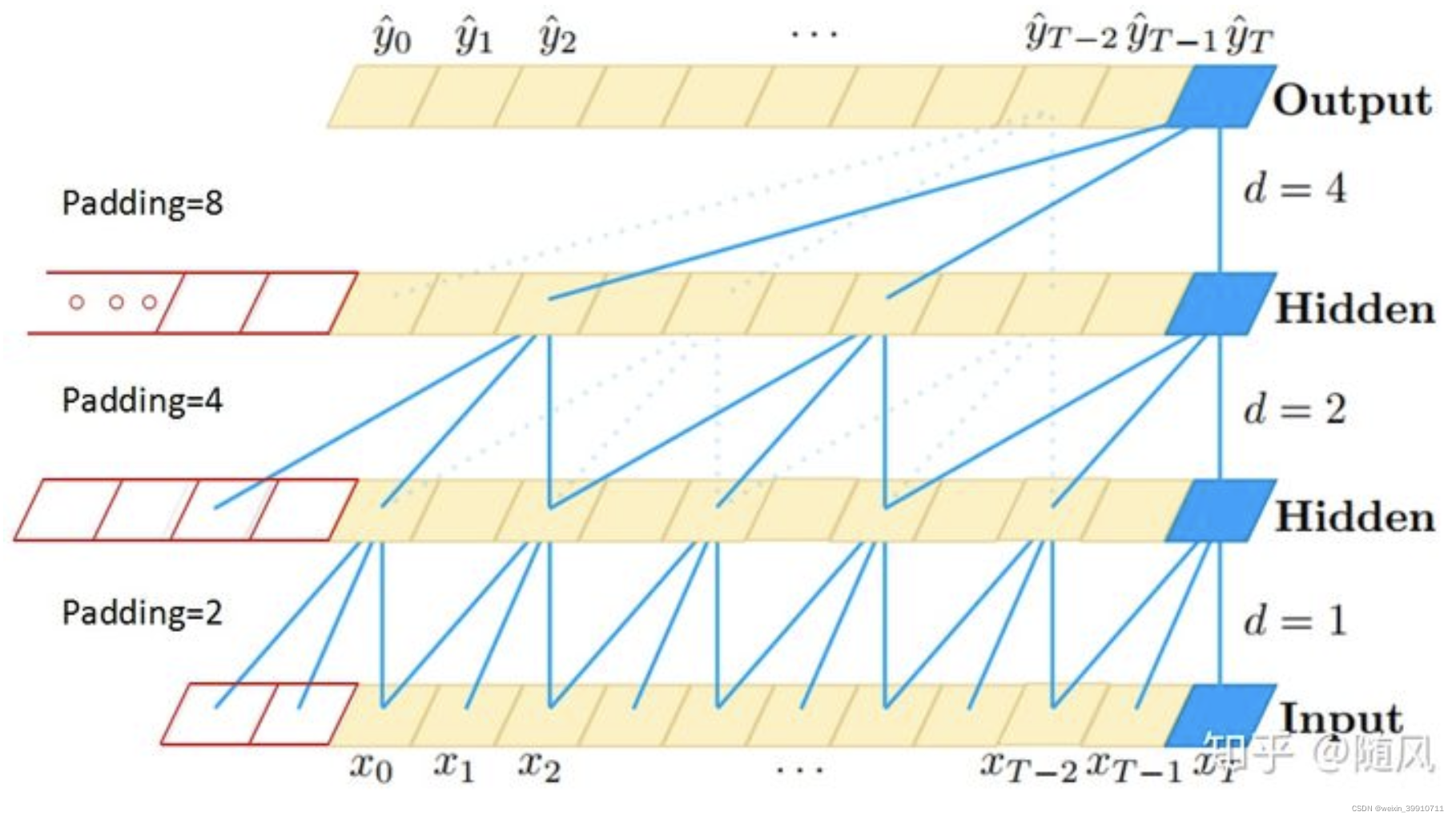
因为研究对象是时间序列,TCN 采用一维的卷积网络。上图是 TCN 架构中的因果卷积与空洞卷积,可以看到每一层 ![]() 时刻的值只依赖于上一层
时刻的值只依赖于上一层 ![]() 时刻的值,体现了因果卷积的特性;而每一层对上一层信息的提取,都是跳跃式的,且逐层 dilated rate 以 2 的指数增长,体现了空洞卷积的特性。由于采用了空洞卷积,因此每一层都要做 padding(通常情况下补 0),padding 的大小为
时刻的值,体现了因果卷积的特性;而每一层对上一层信息的提取,都是跳跃式的,且逐层 dilated rate 以 2 的指数增长,体现了空洞卷积的特性。由于采用了空洞卷积,因此每一层都要做 padding(通常情况下补 0),padding 的大小为 ![]() 。
。
2.3 残差模块(Residual block)
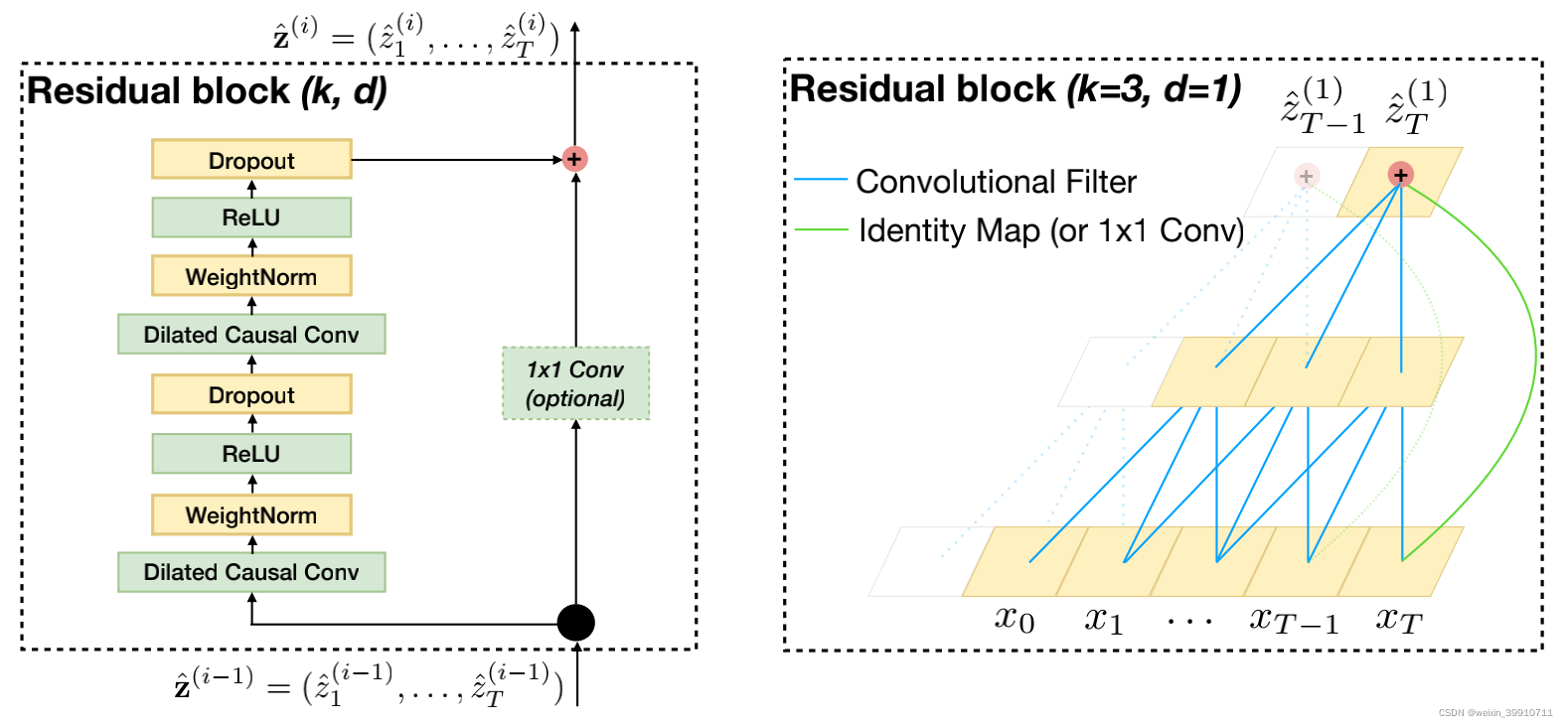
残差链接被证明是训练深层网络的有效方法,它使得网络可以以跨层的方式传递信息。本文构建了一个残差块来代替一层的卷积。如上图所示,一个残差块包含两层的卷积和非线性映射,在每层中还加入了WeightNorm和Dropout来正则化网络。
3 TCN时间卷积网络的预测
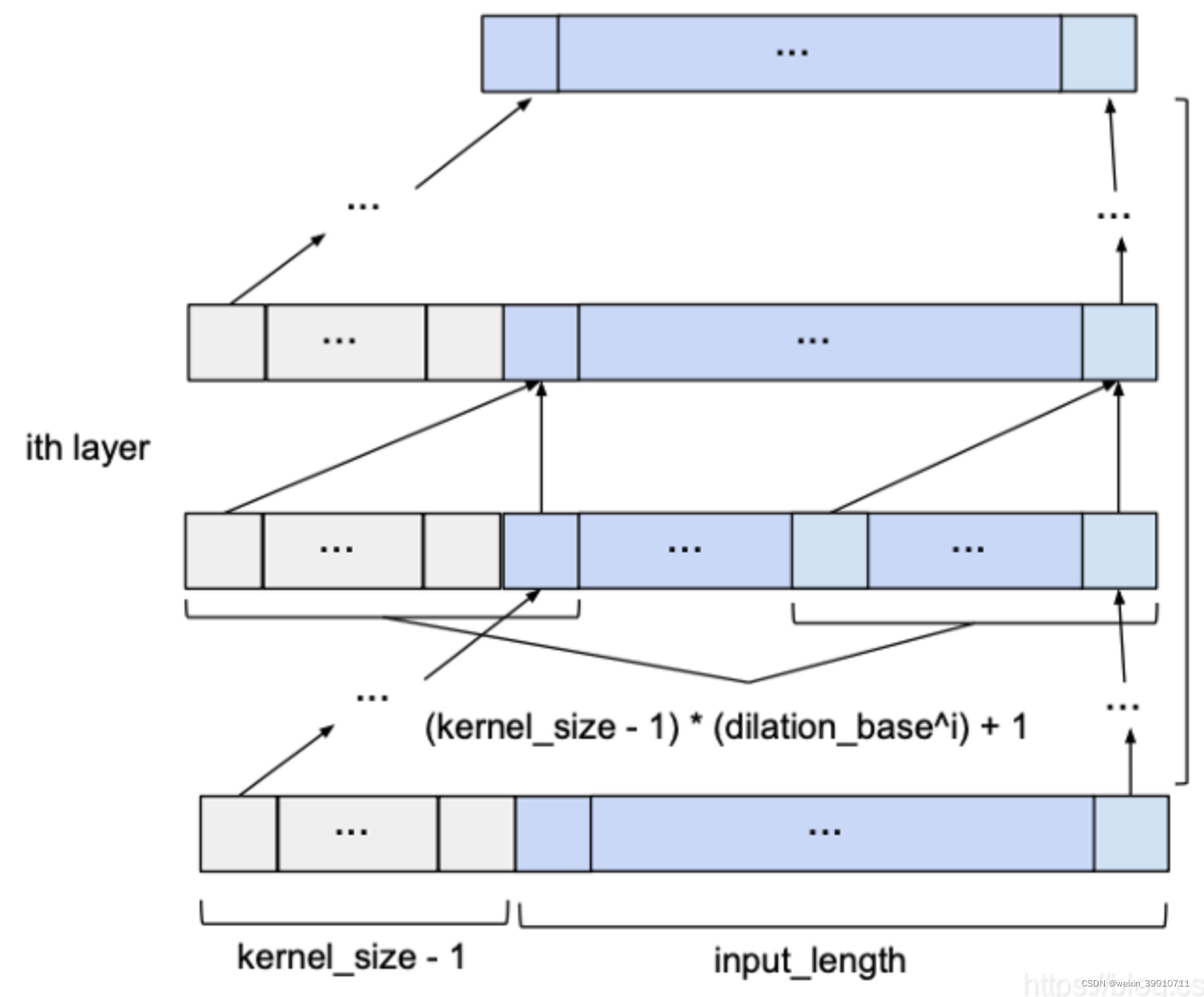
给定input_length, kernel_size, dilation_base和覆盖整个历史所需的最小层数,基本的TCN网络看起来像这样:
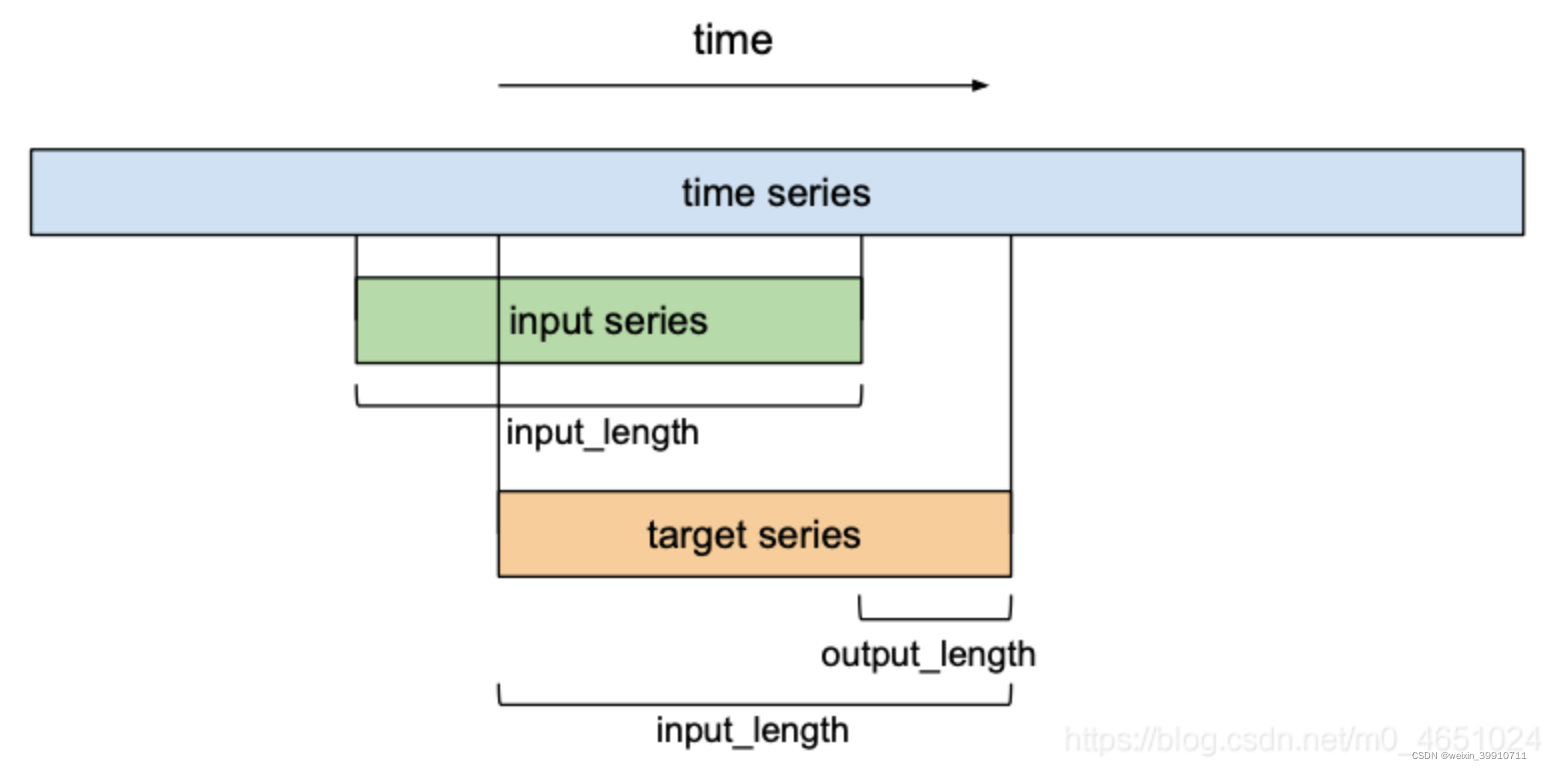
到目前为止,我们只讨论了‘输入序列’和‘输出序列’,而没有深入了解它们之间是如何相互关联的。在预测方面,我们希望预测未来时间序列的下一个条目。为了训练我们的TCN网络进行预测,训练集将由给定时间序列的等大小子序列对(输入序列、目标序列)组成。
即 input series = target series
目标序列将是相对于其各自的输入序列向右移动一定数量output_length的序列。这意味着长度input_length的目标序列包含其各自输入序列的最后(input_length - output_length)元素作为第一个元素,位于输入序列最后一个条目之后的output_length元素作为它的最后一个元素。在预测方面,这意味着该模型所能预测的最大预测视界等于output_length。使用滑动窗口的方法,许多重叠的输入和目标序列可以创建出一个时间序列。
4 TCN 进行序列建模的几个优点和缺点
优点:
- 并行性(Parallelism)。与在 RNN 中对后续时间步的预测必须等待其前任完成的情况不同,卷积可以并行完成,因为每一层都使用相同的滤波器。因此,在训练和评估中,长输入序列可以在 TCN 中作为一个整体进行处理,而不是像在 RNN 中那样按顺序处理。
- 灵活的感受野大小(Flexible receptive field size)。TCN 可以通过多种方式改变其感受野大小。例如,堆叠更多扩张(因果)卷积层、使用更大的膨胀因子或增加滤波器大小都是可行的选择(可能有不同的解释)。因此,TCN 可以更好地控制模型的内存大小,并且易于适应不同的领域。
- 稳定的梯度(Stable gradients)。与循环架构不同,TCN 的反向传播路径与序列的时间方向不同。因此,TCN 避免了梯度爆炸/消失的问题,这是 RNN 的一个主要问题,并导致了 LSTM、GRU、HF-RNN(Martens & Sutskever,2011)等的发展。
- 训练时内存要求低。特别是在输入序列较长的情况下,LSTM 和 GRU 很容易占用大量内存来存储它们的多个单元门的部分结果。而在 TCN 中,滤波器跨层共享,反向传播路径仅取决于网络深度。因此,在实践中,我们发现门控 RNN 可能比 TCN 使用更多的内存。
- 可变长度输入。就像 RNN 以循环方式对可变长度的输入进行建模一样,TCN 也可以通过滑动 1D 卷积核来接收任意长度的输入。这意味着 TCN 可以作为 RNN 的替代品,用于任意长度的序列数据。
使用 TCN 也有两个明显的缺点:
- 评估期间的数据存储。在评估/测试中,RNN 只需保持隐藏状态并获取当前输入 xt 即可生成预测。换句话说,整个历史的“摘要”由一组固定长度的向量 ht 提供,而实际观察到的序列可以被丢弃。相比之下,TCN 需要接收到有效历史长度的原始序列,因此在评估期间可能需要更多内存。
- 域迁移的潜在参数变化(Potential parameter change for a transfer of domain)。不同领域对模型预测所需的历史数量可能有不同的要求。因此,当将模型从只需要很少内存的域(即小 k 和 d)转移到需要更长内存的域(即大得多的 k 和 d)时,TCN 可能会因为没有足够大的感受野。
论文《An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling》:https://arxiv.org/pdf/1803.01271.pdf
TCN 时间卷积网络:TCN 时间卷积网络 - 知乎
时域卷积网络TCN详解:使用卷积进行序列建模和预测:时域卷积网络TCN详解:使用卷积进行序列建模和预测_deephub的博客-CSDN博客_tcn时间卷积网络
时空卷积网络TCN:时空卷积网络TCN - USTC丶ZCC - 博客园
Darts实现TCN(时域卷积网络): https://blog.csdn.net/liuhaikang/article/details/119704701?spm=1001.2014.3001.5501
TCN-时间卷积网络:https://blog.csdn.net/qq_27586341/article/details/90751794?utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromMachineLearnPai2~default-4.base&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromMachineLearnPai2~default-4.base
多变量时间序列、预训练模型和协变量:

