
- 1nandflash移植程序_韦东山鸿蒙移植01-移植RTOS需要做的事
- 2ADC学习系列(一):ADC基础概念_adc基础知识
- 3对比Vector、ArrayList、LinkedList有何区别?_vector,arraylist,linkedlist区别
- 4chatgpt 逐字输出 使用fetch/eventSource/fetchEventSouce进行sse流式处理_fetcheventsource
- 5初探ViewBinding_viewbinding 初始化
- 6瑞士名表排名介绍及手表品牌识别
- 7每日一道Python编程题目练习,不定期更新_python每日一题
- 8如何使用不同的方法和命令来检查 Ubuntu 中的 CPU 数量?_ubuntu查看cpu核数
- 9RK1808 MIPI屏幕上电初始化_compatible = "sitronix,st7703", "simple-panel-dsi"
- 10人工智能、机器学习、深度学习、强化学习、深度强化学习_人工智能 机器学习 深度学习 强化学习
深度学习--循环神经网络(Recurrent Neural Network)_循环神经网络优缺点
赞
踩
RNN(Recurrent Neural Network)是怎么来的?
一些应用场景,比如说写论文,写诗,翻译等等。
既然已经学习过神经网络,深度神经网络,卷积神经网络,为什么还要学习RNN?
首先我们必须要知道DNN,CNN的输入是相互独立的,比如说我们有一张照片,最终输入是猫还是狗,我输入的每张照片之间是不是没什么关系,也就是说相互独立。但是现实生活当中,有好多都是相互连接的,比如说股票随着时间的变化,再比如说:我是中国人,因此我的母语是______.我们知道这个空格要填的是汉语对吧,我们是怎么知道到,是不是通过上文进行简单的推断,知道这个地方要填汉语的呀,假如说:我们现在还是三岁小孩,读一个字忘一个字,那么我读到空格这个地方时候知道是汉语吗?不知道吧。所以RNN的本质是啥啊,是不是就是让它,“像人一样具有记忆啊”。
网络结构是什么样子的呢?

每个神经单元做的事情都是一样的,因此呢我们要是把他给折叠起来呢就是左边图的样子,要是张开的话就是有点图的样子,一句话概括RNN,就是一个结构重复的使用。
然后在这里我们引入一下时间步:什么是时间步,我要说一句话:我对人工智能很感兴趣,
我是怎么说的,是不是一个字一个字说出来的,那么同理,如果是我们机器处理的话,是不是同样也是一个字一个字输入并且处理的呀,因此呢,我这输入每个字,处理每个字的时候,就叫做一个时间步。
因此呢,我们上边的结构图可不可以这样去理解:xt代表的就是t时刻的输入,ot代表的就是t时刻的输出,st-1就是t时刻的记忆。
就好像我们现在是算法一的阶段,我们的知识是由,算法一这个学到的东西(输入)加上我们深度二以及深度二以前的东西(记忆)。
因此我们的公式能写成什么呀:
St = f(U*xt + w*st-1)
那么就有同学问啦,里边的公式我理解没那么加一个f()是什么呀,这个呀就是激活函数,什么作用呢,就是过滤信息的,比如说我现在在给大家讲RNN,大家在深度的时候也学了RNN对吧,我呢,比你们之前那个老师讲的更容易理解更清楚供透彻,因此,大家是不可以吧他们讲的给忘啦,记住我讲了就行啦,对不对。RNN也是一样啊,我既然可以记忆啦,我肯定只记住有用的更重要的信息啊,那么神经网络中什么最适合过滤信息啊,激活函数吧,
做一个非线性的变换,来过滤信息。
大家已经学完了这个月的知识啦,那么是不是马上要月考了呀,那么月考的时候,大家是不是带着这个月的记忆就行啦,这个月的记忆是怎么构成的?是不是就是这个月学到的东西,加上上个月以及之前学的东西啊。
也就是告诉大家,我在计算ot的时候,是不是通过st算得的啊。
公式:ot = f(v * st)这是不是我t时刻的输出啊,也就是说我月考的成绩。
总结:
Xt:就是本月学的东西,也就是输入对吧
St:就是本月的记忆,刚才也讲啦,本月的记忆是不是由我当月学的,加上我之前学的记忆。就好像大家马上要月考啦,大家脑子里边是不是除了这个月学的东西,也有之前学的东西啊。
Ot:就是大家的月考了。是不是大家都是凭着记忆去考的试,而不是通过作弊去考的试吧,
但是很多情况下的Ot是不存在的,因为很多的NLP任务只关注最后一个输出,例如情感分析。在给大家类比一下:大家要去找工作的时候,人家是不是只看大家的技术怎么样啊,而不是看你,机器一考了100,机器二考了100,深度100,然后就要你啦对不对,我只看你学完实训之后出来掌握了多少技术,对不对。
BPTT:RNN的反向传播
实质是和BP算法一致的,只不过因为RNN是处理的序列数据,是不是随着时间步去处理的呀,我正向传播的时候是不是一个时间步一个时间步的去计算,同时时间步之间试试又是相互关联的呀,我正想传播如此,那么我反向传播的时候,是不是也应该随着时间步去反向传播啊,这就是BPTT(back propagetion through time),通过时间步反向传播。那么我们知道BP算法的核心是反向的链式求导,也就是说,寻找各个参数的梯度,然后沿着各个参数梯度的方向,不断的寻找最优的参数,直到收敛。
那么接下来我们就去看一看BPTT
首先对V求导是最简单的:
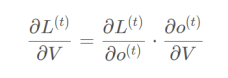
但是我们知道:RNN的代价是怎么产生的呀,是不是我在每一个时刻都会产生一个代价啊,
比如说我输出了一个样本,我这一个样本呢的序列长度是5,那么我的时间步是不是就是5,
每个时间步是不是都有一个输出啊,因此,我算代价的时候,我不能只算第五个时间步的输出和真实值的交叉熵啊,我要把每个时间步的输出都会有代价,那么我是不是要做一个所有时间步的加和是我的总代价啊,因此我对V的求偏导是不是就是这样啦:

但是对U和W进行求导的时候就比较复杂啦:
如图:

是不是我们对W和U进行求偏导的时候是不是要涉及到历史的数据啊,我们拿三个时刻举例:
对W求偏导公式:

对U求偏导:

但是好在我们是不是能发现一定的规律:

那么我们知道这里边是不是h这个隐藏单元中是不是又激活函数在里边的呀:

那么我们这么做累乘的话会出现什么问题啊,梯度消失!!!
RNN中共享参数的问题:
首先我们知道在深度神经网络里边是不是参数都特别的多啊,然后呢,像在CNN,RNN这样的网络里边呢,我们让他们去共享参数,那么是不是就大大的减少了参数量啊,这样参数量一减少,那么速度上是不是就会有很大很大的提升!!!
我想让这么多隐藏神经单元的作用是一样的!!!
举个例子:我爱我的祖国
在输入第一个‘我’的时候,得到的输出和输入第三个‘我’的时候的到的输出是一样的
因为什么呀,相同的输入,相同的参数所以我会得到相同的结果,那么输入第一个‘我’和
第二个‘爱’的时候得到的输出肯定是不一样的,为什么呀?相同的参数(U,W,V)不同的输入,所以得到的输出是不一样的。
RNN的优缺点:
优点呢就是可以解决处理序列数据,使神经网络具有记忆的功能啊。
缺点就是,如果序列太长会导致梯度消失或者梯度爆炸,梯度消失呢也就导致了RNN不能长期的记忆,如果我一个序列很长的话,后边层的梯度根本就传不到前边层,后边层的误差,不能影响到前边层的计算,因此就不能去调整前层的参数了,所以他们就是失去了关系,因此RNN的梯度消失导致了RNN不能长期记忆。

梯度消失的话可以使用LSTM中的门解决。
梯度爆炸可以设定一个最大阈值。

