
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~
本文来自专栏语言、知识与人工智能,作者腾讯知文实验室
1. 什么是任务型机器人
任务型机器人指特定条件下提供信息或服务的机器人。通常情况下是为了满足带有明确目的的用户,例如查流量,查话费,订餐,订票,咨询等任务型场景。由于用户的需求较为复杂,通常情况下需分多轮互动,用户也可能在对话过程中不断修改与完善自己的需求,任务型机器人需要通过询问、澄清和确认来帮助用户明确目的。
2. 任务型机器人的组成
任务型机器人核心模块主要包括三部分:
自然语言理解模块 —— Language Understanding
对话管理模块 —— Dialog Management
自然语言生成模块 —— Natural Language Generation
整体框架如下:
下面根据各个模块进行详细介绍:
2.1 自然语言理解模块
2.1.1 简介
当用户语言经过自然语言理解模块时,即需要经过领域识别,用户意图识别以及槽位提取三个子模块。领域识别,即识别该语句是不是属于这个任务场景,一般有多个机器人集成时,如闲聊机器人,问答机器人等,领域识别应当在进入任务型机器人之前做判断与分发;意图识别,即识别用户意图,细分该任务型场景下的子场景;实体识别与槽位填充,用于对话管理模块的输入。
2.1.2 举例
对这个模块举个简单的例子:假设Text=“人民币对美元的汇率是多少”;经过自然语言理解模块会解析为 act ( slot1 = value1, slot2 = value2 ......) 的形式,即意图,槽位,槽位信息三元组形式,即 Text会解析为“查询(槽位1=人民币,槽位2=美元)"这样的形式。
2.1.3 自然语言理解模块的相关研究工作
意图理解与槽位提取作为任务型机器人的核心模块之一,引起研究者的广泛兴趣。有以下方法:
1. 基于规则理解方法
例如商业对话系统VoiceXML和Phoenix Parser (Ward et al., 1994; Seneff et al., 1992; Dowding et al., 1993)。Phoenix Parser 将输入的一句文本(词序列)映射到由多个语义槽(Slot)组成的语义框架里,一个语义槽的匹配规则由多个槽值类型与连接词构成的,可以表示一段完整的信息,如图2所示。优点:不需要大量训练数据。缺点:1. 规则开发易出错 。2. 调整规则需要多轮的迭代。 3. 规则冲突,较难维护。
Phoenix基于TownInfo语料的测试结果见表1:
2. 规则与统计结合的方法
例如组合范畴语法 (CCG),可以基于标注数据,对大量的复杂语言现象进行统计建模和规则自动提取。 由于语法规则的宽松性以及与统计信息的结合,该方法在口语语义理解中 的应用可以学习解析无规则的文本 (Zettlemoyer et al., 2007)。基于ATIS语料的测试结果见表2:
3. 统计方法(对齐)
基于词对齐数据的口语理解通常被看做一个序列标注问题。基于生成模型有随机有限状态机 (FST),统计机器翻译(SMT)、动态贝叶斯网络 (DBN)等,判别模型主要CRF,SVM,MEMM等(Hahn et al., 2011)。基于Media evaluation预料测试结果见表3。
4. 统计方法(非对齐)
如生成式的动态贝叶斯网络 (DBN) (Schwartz et al., 1996) ,缺点:马尔科夫假设使得该模型不能准确地对词的长程相关性进行建模;分层隐状态的方法能解决上述长程相关性的问题,但所需要的计算复杂度很高 (He et al., 2006);支持向量机分类器的基础上提出了语义元组分类器 (Mairesse et al., 2009) 的方法。基于TownInfo,ATIS语料测试结果见表4。
5. 深度学习方法
单向RNN应用于语义槽填充任务,在ATIS评测集合上取得了显著性超越CRF模型的效果 (Yao et al., 2013; Mesnil et al., 2013); LSTM等一些扩展(BiLSTM+CRF);CNN用于序列标注 (Xu et al. 2013; Vu 2016) ;基于序列到序列(sequence-to-sequence)的编码-解码(encoder-decoder)模型,attention等拓展 (Zhu et al., 2016; Liu et al., 2016); 加入外部记忆单元(External Memory)的循环神经网络可以提升网络的记忆能力 (Peng et al., 2015);RecNN (Guo et al., 2014)等。上述方法测试结果见表5。
6. 基于上述方法的例子
基于规则的解析:如将"我想查询一下美元现在的汇率"输入基于规则的解析器,可以解析出如下意图与槽位的信息。
基于LSTM的模型:句子的标注格式如下,采用BIO标注,以及对整个句子所属的意图标注,采用极大化槽位与意图的似然来求解模型参数。
基于统计方法的模型(SVM):对句子进行n-gram特征提取,通过训练领域的SVM与槽位的SVM进行分类。
2.2 对话管理模块
2.2.1 简介
自然语言理解模块的三元组输出将作为对话管理系统的输入。对话管理系统包括两部分,状态追踪以及对话策略。状态追踪模块包括持续对话的各种信息,根据旧状态,用户状态(即上述的三元组)与系统状态(即通过与数据库的查询情况)来更新当前的对话状态如图3所示。 对话策略与所在任务场景息息相关,通常作为对话管理模块的输出,如对该场景下缺失槽位的反问策略等。
2.2.2 举例
还是继续上面的text=“人民币对美元的汇率是多少”。“查询(槽位1=人民币,槽位2=美元)"这样的形式将作为对话管理模块的输入,这时候状态追踪模块就要根据前几轮的信息,结合该输入判断该轮的查询状态,确定查询的槽位,以及与数据库的交互。如得到想要查询的确实是人民币对美元的汇率信息。这时候,根据现有的对话策略判断当前的槽位状态,最后给出对话管理模块的输出,如查询结果(源货币=人民币,目标货币=美元,汇率=1:0.16)
2.2.3 对话管理系统的相关研究工作
对话管理模块相当于任务型机器人的大脑。主要方法有基于规则与统计学习的方法。目前流行的有基于强化学习的对话管理模块。基于强化学习的对话管理系统需要很多数据去训练。Jost Schatzm-ann and Steve Young等人提出了agenda user simulator模型来模拟用户,不断与对话管理模块进行训练,一定程度上解决了标注数据稀缺的问题。但对于复杂对话还是不能很好应付。Jianfeng Gao等通过实验,证明了基于强化学习训练的对话管理系统对噪声的抗干扰能力较强,同时整体误差来看槽位误差造成的影响比意图误差造成的影响更严重。
2.3 自然语言生成模块
自然语言模块通常采用基于模版,基于语法或模型等。模版与语法主要基于规则的策略,模型可以用如LSTM等网络生成自然语言。
2.4 端到端的模型
这里以微软的End-to-End 模型 (Jianfeng Gao et al., 2018)为例,见下图。
文章的主要亮点是根据 (Jost Schatzmann and Steve Young, Fellow et al., 2009) 从语义层次上升到自然语言层次,同时用误差模型对基于DQN强化学习的对话管理系统深入探究。User Simulator 沿用Steve Young之前的基于堆栈的agenda模型,自然语言生成模块和自然语言理解模块采用LSTM模型,对话管理模块采用基于DQN (Jianfeng Gao et al., 2018)。 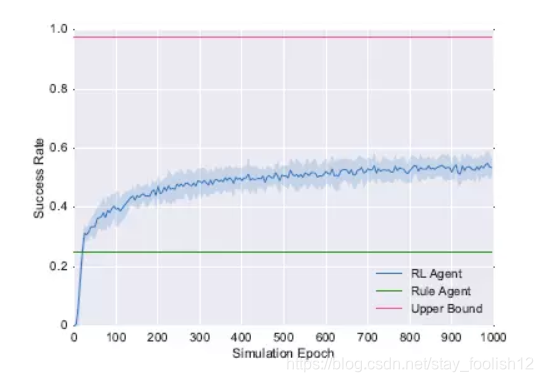 3. 应用:阿里小蜜调研
阿里小蜜机器人整体算法体系如下,采用领域识别将输入的query和context分发到不同的机器人执行任务。 4.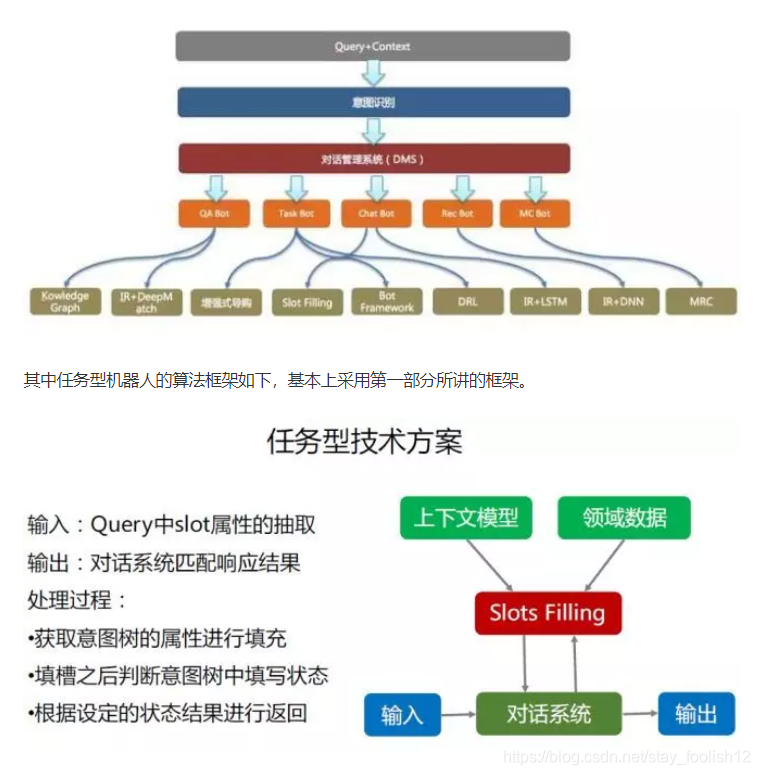 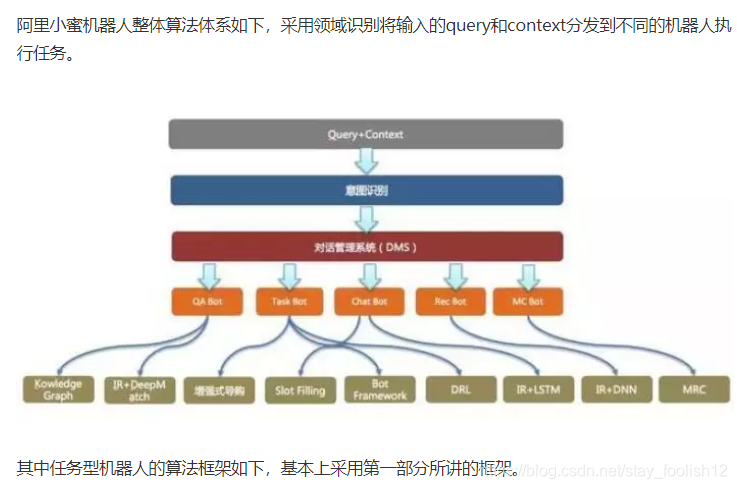 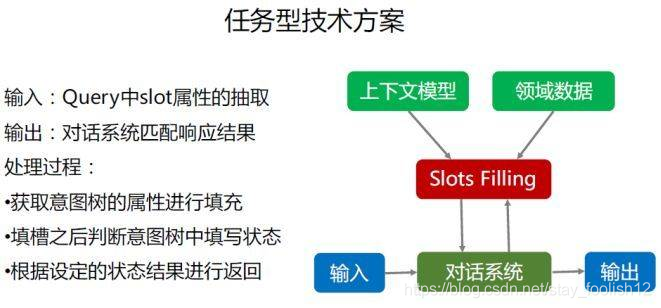 4. 总结
本文较为浅显的介绍了基于任务型对话的框架与一些方法,大家如果需要深入研究可在参考文献中寻找相应的文章阅读。当然,目前这个领域还存在较多的问题,如:
语义的表示方式。如何将句子设计成合适的语义结构形式,增添语义解析,语义推理,领域迁移的鲁棒性等,一直是十分有挑战性的问题。
任务型的数据收集和标注非常困难,如何设计一套较为通用的数据标注格式,有待研究推进,随着用户对任务型领域要求的日益增多,利用已有的资源对领域迁移的研究变得尤其重要。
此文已由作者授权腾讯云+社区发布,原文链接:cloud.tencent.com/developer/a…
欢迎大家前往腾讯云+社区或关注云加社区微信公众号(QcloudCommunity),第一时间获取更多海量技术实践干货哦~

