
- 1android NDK——搭建Android Studio的NDK环境_both android.ndkpath and ndk.dir in local.properti
- 2Rabbitmq在java中的使用_java使用rabbitmq
- 3SpringBoot连接Redis报错:org.springframework.data.redis.RedisSystemException: Error in execution
- 42023年6月GESP能力等级认证C++四级真题_gesp4级真题
- 5Python自动化机器学习(AutoML)快速实现,只需要PyCaret 2.0、AutoGluon两个包_london_merged
- 6第十三届蓝桥杯B组C++(试题B:顺子日期)_蓝桥杯顺子日期
- 7element el-table实现可进行横向拖拽滚动_eltable横向拖拽滚动
- 8从模型到部署,教你如何用Python构建机器学习API服务
- 9计算机网络——网络层_源和目的端之间所有可能的传输路径是什么
- 10七大OSINT操作系统(开源网络情报)
sklearn中特征提取方法基础知识_sklearn图像特征提取
赞
踩
特征提取方法基础知识,将不同类型的数据转换成特征向量方便机器学习算法研究
目录
-
分类变量特征提取:分类数据的独热编码方法,并用scikit-learn的DictVectorizer类实现
-
机器学习问题中常见的文档特征向量:
- 词库模型将文档转换成词块的频率构成的特征向量,用CountVectorizer类计算基本单词频次的二进制特征向量。
- 通过停用词过滤(stop_word),词根还原,词形还原(wordNetLemmatizer)进一步优化特征向量,
- 加入TF-IDF(TfidfVectorizer)权重调整文集常见词,消除文档长度对特征向量的影响。
-
图像特征提取的方法(skimage)
介绍了一个关于的手写数字识别的OCR问题,通过图像的像素矩阵扁平化来学习手写数字特征。这种方法非常耗费资源,于是引入兴趣点提取方法,通过SIFT和SURF进行优化。
-
数据标准化的方法,确保解释变量的数据都是同一量级,均值为0的标准化数据。scikit-learn的scale函数可以实现。
1、分类变量特征提取
分类数据的独热编码方法,分类变量特征提取(One-of-K or One-Hot Encoding):通过二进制数来表示每个解释变量的特征
例子:假设city变量有三个值:New York, San Francisco, Chapel Hill。独热编码方式就是用三位二进制数,每一位表示一个城市。
from sklearn.feature_extraction import DictVectorizer
onehot_encoder = DictVectorizer()
instances = [{'city':'New York'},{'city':'San Francisco'},{'city': 'Chapel Hill'}]
print (onehot_encoder.fit_transform(instances).toarray())
out:
[[ 0. 1. 0.]
[ 0. 0. 1.]
[ 1. 0. 0.]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2、Machine Learning中常见的文档特征向量
1)文字特征提取-词库模型(Bag-of-words model)
文字模型化最常用方法,可以看成是独热编码的一种扩展,它为每个单词设值一个特征值。依据是用类似单词的文章意思也差不多。可以通过有限的编码信息实现有效的文档分类和检索。
CountVectorizer 类会将文档全部转换成小写,然后将文档词块化(tokenize).文档词块化是把句子分割成词块(token)或有意义的字母序列的过程。词块大多是单词,但是他们也可能是一些短语,如标点符号和词缀。CountVectorizer类通过正则表达式用空格分割句子,然后抽取长度大于等于2的字母序列。
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'UNC played Duke in basketball',
'Duke lost the basketball game',
'I ate a sandwich'
]
vectorizer = CountVectorizer()
print (vectorizer.fit_transform(corpus).todense())
print (vectorizer.vocabulary_)
out:
[[0 1 1 0 1 0 1 0 0 1]
[0 1 1 1 0 1 0 0 1 0]
[1 0 0 0 0 0 0 1 0 0]]
{'game': 3, 'ate': 0, 'sandwich': 7, 'lost': 5, 'duke': 2, 'unc': 9, 'played': 6, 'in': 4, 'the': 8, 'basketball': 1}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
词汇表里面有10个单词,但a不在词汇表里面,是因为a的长度不符合CountVectorizer类的要求。
对比文档的特征向量,会发现前两个文档相比第三个文档更相似。如果用欧氏距离(Euclidean distance)计算它们的特征向量会比其与第三个文档距离更接近。
两向量的欧氏距离就是两个向量欧氏范数(Euclidean norm)或L2范数差的绝对值:d=||x0-x1||
向量的欧氏范数是其元素平方和的平方根。
scikit-learn里面的euclidean_distances函数可以计算若干向量的距离,表示两个语义最相似的文档其向量在空间中也是最接近的。
from sklearn.feature_extraction.text import CountVectorizer from sklearn.metrics.pairwise import euclidean_distances vectorizer = CountVectorizer() counts = vectorizer.fit_transform(corpus).todense() for x,y in [[0,1],[0,2],[1,2]]: dist = euclidean_distances(counts[x],counts[y]) print('文档{}与文档{}的距离{}'.format(x,y,dist)) out: 文档0与文档1的距离[[ 2.44948974]] 文档0与文档2的距离[[ 2.64575131]] 文档1与文档2的距离[[ 2.64575131]] 文档0:[[0 1 1 0 1 0 1 0 0 1]] 文档1:[[0 1 1 1 0 1 0 0 1 0]] 文档2:[[1 0 0 0 0 0 0 1 0 0]]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
两个常见问题:
第一个问题就是高维向量需要占用更大内存。有许多零元素的高维特征向量成为稀疏向量(sparse vectors)。NumPy提供了一些数据类型只显示稀疏向量的非零元素,可以有效处理这个问题。
第二个问题就是著名的维度灾难(curse of dimensionality,Hughes effect),维度越多就要求更大的训练集数据保证模型能够充分学习。如果训练样本不够,那么算法就可以拟合过度导致归纳失败。
2)特征向量降维的基本方法
-
单词全部转换成小写
-
去掉文集常用词,即停用词(stop-word)像a,an,the,助动词do,be,will,介词on,around,beneath等。停用词通常是构建文档意思的功能词汇,其字面意义并不体现。
CountVectorizer类可以通过设置stop_words参数过滤停用词,默认是英语常用的停用词。 -
词根还原与词形还原
#去掉停用词 from sklearn.feature_extraction.text import CountVectorizer corpus = [ 'UNC played Duke in basketball', 'Duke lost the basketball game', 'I ate a sandwich' ] vectorizer = CountVectorizer(stop_words='english') print(vectorizer.fit_transform(corpus).todense()) print(vectorizer.vocabulary_) out: [[0 1 1 0 0 1 0 1] [0 1 1 1 1 0 0 0] [1 0 0 0 0 0 1 0]] {'game': 3, 'ate': 0, 'sandwich': 6, 'lost': 4, 'duke': 2, 'unc': 7, 'played': 5, 'basketball': 1} #词根还原(stemming)与词形还原(lemmatization),可以用nltk的wordNetLemmatizer实现 #nltk.stemmer.porter.PorterStemmer 类是一个用于从英文单词中获得符合语法的(前缀)词干的极其便利的工具. #用法例子 from nltk.stem.wordnet import WordNetLemmatizer lemmatizer = WordNetLemmatizer() print(lemmatizer.lemmatize('gathering','v')) print(lemmatizer.lemmatize('gathering','n')) out: gather gathering #词根还原 from nltk import word_tokenize from nltk.stem import PorterStemmer from nltk.stem.wordnet import WordNetLemmatizer from nltk import pos_tag wordnet_tags = ['n','v'] corpus = [ 'UNC played Duke in basketball', 'Duke lost the basketball game', 'I ate a sandwich' ] stemmer = PorterStemmer() print ('Stemmed:',[[stemmer.stem(token) for token in word_tokenize(document)] for document in corpus]) # 解析单词 #词形还原 def lemmatize(token, tag): if tag[0].lower() in ['n','v']: return lemmatizer.lemmatize(token, tag[0].lower()) return token lemmatizer = WordNetLemmatizer() tagged_corpus = [pos_tag(word_tokenize(document)) for document in corpus] print ('Lemmatized:',[[lemmatize(token, tag) for token, tag in document] for document in tagged_corpus]) out: Stemmed: [['UNC', 'play', 'Duke', 'in', 'basketbal'], ['Duke', 'lost', 'the', 'basketbal', 'game'], ['I', 'ate', 'a', 'sandwich']] Lemmatized: [['UNC', 'play', 'Duke', 'in', 'basketball'], ['Duke', 'lose', 'the', 'basketball', 'game'], ['I', 'eat', 'a', 'sandwich']]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
转载者注:NLTK是Python下NLP主流的工具包(当然还有它的竞争对手Spacy),关于更多有关NLTK的详解,请参考NLTK的官方文档
3)TF-IDF权重的扩展词库
- 单词频率对文档意思有重要作用,但是在对比不同文档时,还需考虑文档的长度,可通过scikit-learn的
TfdfTransformer类对词频(term frequency)特征向量归一化实现不同文档向量的可比性(L2范数)。 - 对数词频调整方法(logarithmically scaled term frequencies),把词频调整到一个更小的范围
- 词频放大法(augmented term frequencies),适用于消除较长文档的差异,scikit-learn没有现成可用的词频放大公式,不过通过
CountVectorizer可以实现。
归一化,对数调整词频和词频放大三支方法都可以消除文档不同大小对词频的影响,另一个问题仍然存在,那就是特征向量里高频词的权重更大,即使这些词在文集内其他文档里面也经常出现。这些词可以被看成是该文集的停用词,因为它们太普遍对区分文档的意思没任何作用。逆向文件频率(inverse document frequency,IDF)就是用来度量文集中单词频率的。
单词的TF-IDF值就是其频率与逆向文件频率的乘积,TfdfTransformer类默认返回TF-IDF值,其参数use_idf默认为True。由于TF-IDF加权特征向量经常用来表示文本,所以scikit-learn提供了TfidfVectorizer类将CountVectorizer和TfdfTransformer类封装在一起。
转载者注:
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上是:TF * IDF,TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率。
IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处. 在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到
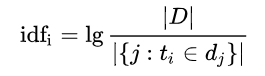
有很多不同的数学公式可以用来计算TF-IDF。这边的例子以上述的数学公式来计算。词频 (TF) 是一词语出现的次数除以该文件的总词语数。假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是3/100=0.03。一个计算文件频率 (IDF) 的方法是文件集里包含的文件总数除以测定有多少份文件出现过“母牛”一词。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是 lg(10,000,000 / 1,000)=4。最后的TF-IDF的分数为0.03 * 4=0.12
4)通过哈希技巧实现特征向量
前面是用包含文集所有词块的词典来完成文档词块与特征向量的映射的。两个缺点。首先是文集需要被调用两次。第一次是创建词典,第二次是创建文档的特征向量。另外,词典必须储存在内存里,如果文集特别大就会很耗内存。通过哈希表可以有效的解决这些问题。可以将词块用哈希函数来确定它在特征向量的索引位置,可以不创建词典,这称为哈希技巧(hashing trick)。scikit-learn提供了HashingVectorizer来实现这个技巧:哈希技巧是无固定状态的(stateless),它把任意的数据块映射到固定数目的位置,并且保证相同的输入一定产生相同的输出,不同的输入尽可能产生不同的输出。它可以用并行,线上,流式传输创建特征向量,因为它初始化是不需要文集输入。n_features是一个可选参数,默认值是1048576,这里设置成6是为了演示。另外,注意有些单词频率是负数。由于Hash碰撞可能发生,所以HashingVectorizer用有符号哈希函数(signed hash function)。
from sklearn.feature_extraction.text import HashingVectorizer
corpus = ['the', 'ate', 'bacon', 'cat']
vectorizer = HashingVectorizer(n_features=6)
print(vectorizer.transform(corpus).todense())
out:
[[-1. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 1. 0. 0.]
[ 0. 0. 0. 0. -1. 0.]
[ 0. 1. 0. 0. 0. 0.]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3、图片特征的提取
1)通过像素特区特征值
数字图像通常是一张光栅图或像素图,将颜色映射到网格坐标里。一张图片可以看成是一个每个元素都是颜色值的矩阵。表示图像基本特征就是将矩阵每行连起来变成一个行向量。光学文字识别(Optical character recognition,OCR)是机器学习的经典问题。
scikit-learn的digits数字集包括至少1700种0-9的手写数字图像。每个图像都有8x8像像素构成。每个像素的值是0-16,白色是0,黑色是16。
from sklearn import datasets
import matplotlib.pyplot as plt
digits = datasets.load_digits()
print('Digit:',digits.target[0])
print (digits.images[0])
plt.figure()
plt.axis('off')
plt.imshow(digits.images[0], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

2)对感兴趣的点进行特征提取
兴趣点:有效的图片信息,边缘(edges)和角点(corners)是两种常用的兴趣点类型。
#官方文档:http://scikit-image.org/ pdf 下载 https://peerj.com/preprints/336/ import numpy as np from skimage.feature import corner_harris, corner_peaks from skimage.color import rgb2gray import matplotlib.pyplot as plt import skimage.io as io from skimage.exposure import equalize_hist def show_corners(corners, image): fig = plt.figure() plt.gray() plt.imshow(image) y_corner, x_corner = zip(*corners) plt.plot(x_corner, y_corner, 'or') plt.xlim(0, image.shape[1]) plt.ylim(image.shape[0], 0) fig.set_size_inches(np.array(fig.get_size_inches()) * 1.5) plt.show() mandrill = io.imread('ascii_dora.png') mandrill = equalize_hist(rgb2gray(mandrill)) corners = corner_peaks(corner_harris(mandrill), min_distance=2) show_corners(corners, mandrill)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
提取感兴趣点结果如下:轮廓大致被提取出来了。


3)尺度不变特征转换(Scale-Invariant Feature Transform,SIFT)
尺度不变特征转换(Scale-Invariant Feature Transform,SIFT)是一种特征提取方法,相比前面使用的方法,SIFT对图像的尺寸,旋转,亮度变化更不敏感。每个SIFT特征都是一个描述图片上某个区域边缘和角点的向量。和兴趣点不同,SIFT还可以获取每个兴趣点和它周围点的综合信息。
4)加速稳健特征(Speeded-Up Robust Features,SURF)
加速稳健特征(Speeded-Up Robust Features,SURF)是另一个抽取图像兴趣点的方法,其特征向量对图像的尺寸,旋转,亮度变化是不变的。SURF的算法可以比SIFT更快,更有效的识别出兴趣点。
5)数据标准化(scikit-learn的scale函数可以实现)
标准化数据均值为0,单位方差(UnitVariance)。均值为0的解释变量是关于原点对称的,特征向量的单位方差表示其特征值全身统一单位,统一量级的数据。
from sklearn import preprocessing
import numpy as np
X = np.array([
[0., 0., 5., 13., 9., 1.],
[0., 0., 13., 15., 10., 15.],
[0., 3., 15., 2., 0., 11.]
])
print( preprocessing.scale(X) )
out:
[[ 0. -0.70710678 -1.38873015 0.52489066 0.59299945 -1.35873244]
[ 0. -0.70710678 0.46291005 0.87481777 0.81537425 1.01904933]
[ 0. 1.41421356 0.9258201 -1.39970842 -1.4083737 0.33968311]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

