
热门标签
热门文章
- 1leecode-1379-找出克隆二叉树中的相同节点_code1379
- 2web课程设计——仿小米商城(10个页面)HTML+CSS+JavaScript web前端课程设计 web前端课程设计代码 web课程设计 HTML网页制作代码
- 3java比较两个实体类及属性差异工具类(简版)_java实体类属性差集
- 4SpringbootV2.6整合Knife4j 3.0.3 问题记录_springboot2.6对应的knife版本
- 5Python自然语言处理学习笔记(2):Preface 前言
- 6MATLAB中的曲线拟合_matlab的linefit
- 7《.Net 基础系列》- IO操作
- 8分析Java8中的stream.map()函数_java 8 stream map
- 9多目标跟踪:视觉联合检测和跟踪
- 10概率论与数理统计B 重点/笔记梳理 第二章_概率论与数理统计考点归纳两点分布
当前位置: article > 正文
Python爬取携程和同程的景点评论并实现词云_同程评论爬取
作者:2023面试高手 | 2024-04-06 13:39:56
赞
踩
同程评论爬取
某人为了期末作业(非计算机系的文科生)想获取数据做分析,奈何不会八爪鱼,于是乎她成了我的甲方。甲方妈妈的需求是这样的:爬取携程网和同程网的对于三亚蜈支洲岛的评论。
一、爬取携程网的评论
1.1 分析
爬取的地址:https://you.ctrip.com/sight/sanya61/3244.html#comment
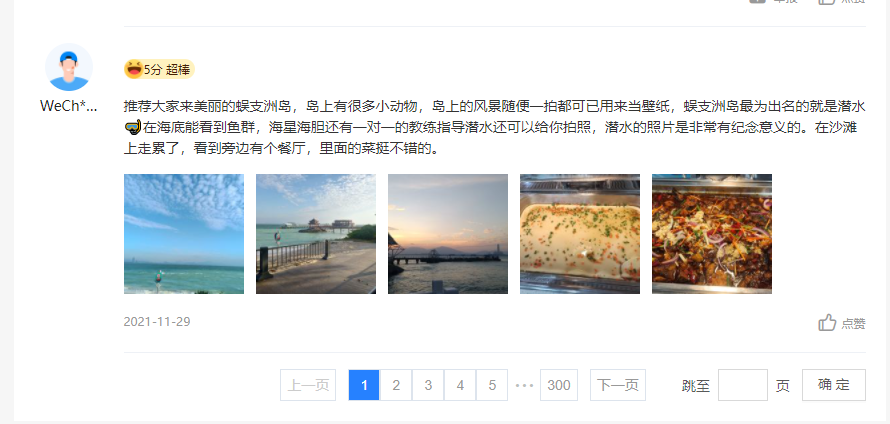
- 评论在这里,并且有分页
- 但是发现点击下一页的时候地址栏并没有变化

- 所以这种情况打开F12控制台看看吧
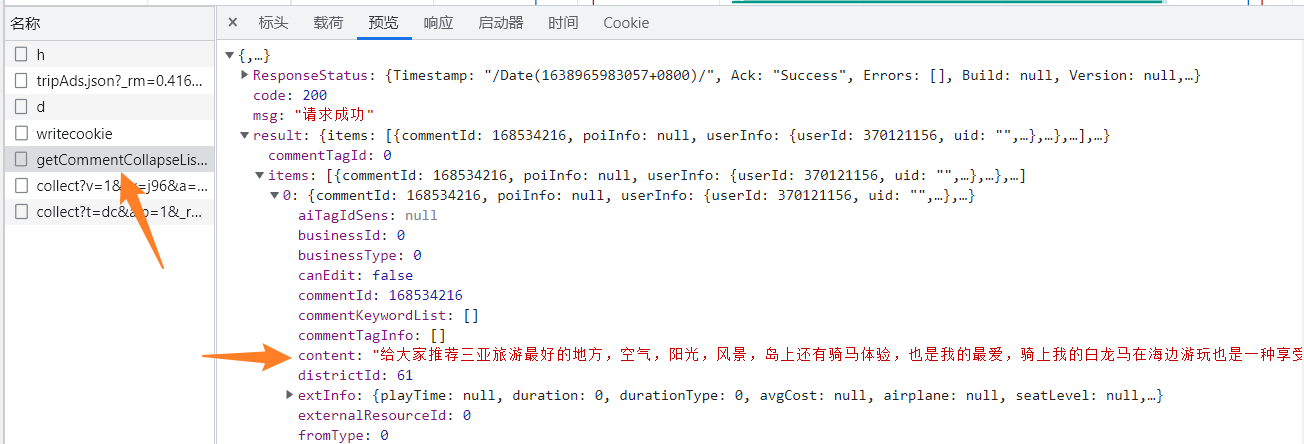
- 发现分页和这个响应有关,并且返回的是一个json数据的格式
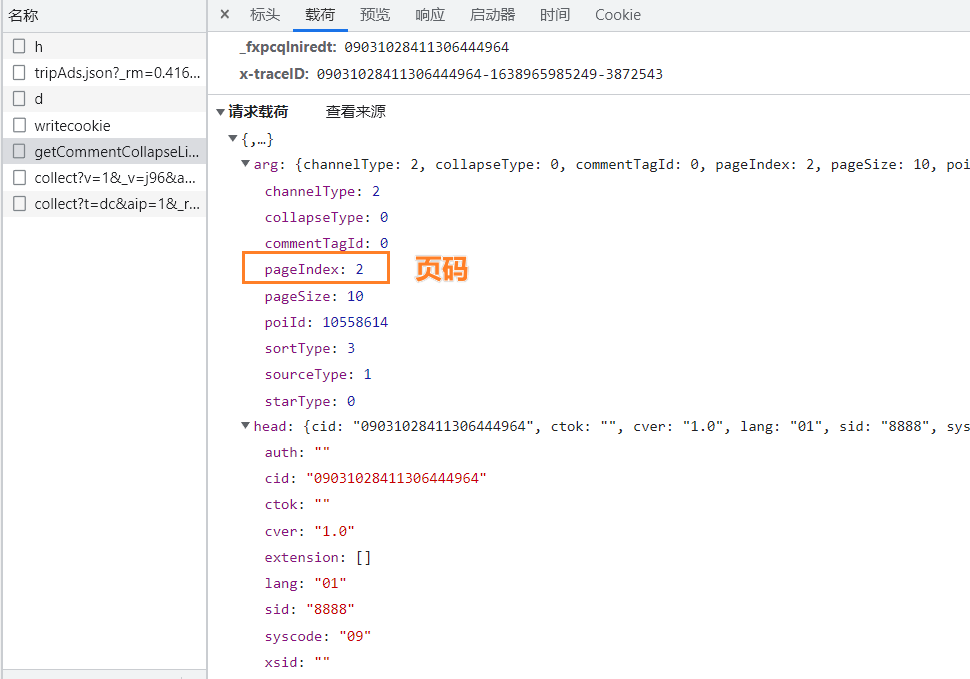
- pageIndex是页码,所以找到关键的点了
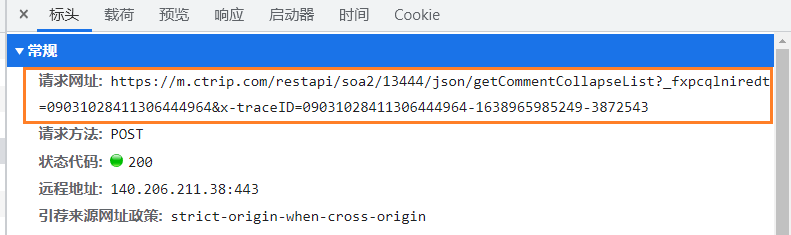
- 获取到评论的地址:https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList?_fxpcqlniredt=09031028411306444964
- 请求是POST请求
1.2 代码实现
- 这里我只爬取了前50页
import requests import json import time headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36', } posturl = "https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList?_fxpcqlniredt=09031028411306444964" def getdata(): j = 1 for i in range(1, 51): request = { 'arg': { 'channelType': '2', 'collapseType': '0', 'commentTagId': '0', 'pageIndex': str(i), 'pageSize': '10', 'poiId': '10558614', 'sortType': '3', 'sourceType': '1', 'starType': '0'}, 'head': { 'auth': "", 'cid': "09031028411306444964", 'ctok': "", 'cver': "1.0", 'extension': [], 'lang': "01", 'sid'

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/372241
推荐阅读
相关标签

