
- 1Excel公式与函数实战应用-陈明霞-专题视频课程
- 2自编码器AutoEncoder
- 3HarmonyOS 应用开发之数据可靠性与安全性&数据库备份与恢复
- 4PyTorch Quantization简介_pytorch quantization simulation
- 5为什么安装了pillow库,还是导入PIL?_python3里面虽然安装的是pillow,但是导入的时候还是从pil进行导入。
- 6如何在以太坊上存一张图片_怎样把图片记录到以太坊区块
- 7Attention机制【图像】_图像attention机制
- 8【面试招聘】拼多多 AI算法岗面试(附带解析)
- 9全面梳理chatGPT常用提示词,看我这一篇就够了!(同样适用于国内大语言模型)_chat gpt提示词全部汇总
- 10【数据结构与算法】图论及其相关算法_图论算法
自然语言处理(NLP)
赞
踩
自然语言处理(NLP)
主要研究人与计算机之间,使用自然语言进行有效通信的各种理论和方法。
自然语言处理的主要技术范畴
1、语义文本相似度分析
语义文本相似度分析是对两段文本的意义和本质之间的相似度进行分析的过程。
2、信息检索
信息检索是指将信息按一定的方式加以组织,并通过信息查找满足用户的信息需求的过程和技术。
3、 信息抽取
信息抽取是指从非结构化/半结构化文本(如网页、新闻、 论文文献、微博等)中提取指定类型的信息(如实体、属性、关系、事件、商品记录等),并通过信息归并、冗余消除和冲突消解等手段将非结构化文本转换为结构化信息的一项综合技术。
4、文本分类
文本分类的任务是根据给定文档的内容或主题,自动分配预先定义的类别标签。
5、文本挖掘
文本挖掘是信息挖掘的一个研究分支,用于基于文本信息的知识发现。文本挖掘的准备工作由文本收集、文本分析和特征修剪三个步骤组成。目前研究和应用最多的几种文本挖掘技术有:文档聚类、文档分类和摘要抽取。
6、文本情感分析
情感分析是一种广泛的主观分析,它使用自然语言处理技术来识别客户评论的语义情感,语句表达的情绪正负面以及通过语音分析或书面文字判断其表达的情感等。
7、问答系统
自动问答是指利用计算机自动回答用户所提出的问题以满足用户知识需求的任务。不同于现有搜索引擎,问答系统是信息服务的一种高级形式,系统返回用户的不再是基于关键词匹配排序的文档列表,而是精准的自然语言答案。
8、机器翻译
机器翻译是指利用计算机实现从一种自然语言到另外一种自然语言的自动翻译。被翻译的语言称为源语言(source language),翻译到的语言称作目标语言(target language)。
机器翻译研究的目标就是建立有效的自动翻译方法、模型和系统,打破语言壁垒,最终实现任意时间、任意地点和任意语言的自动翻译,完成人们无障碍自由交流的梦想。
9、自动摘要
自动文摘(又称自动文档摘要)是指通过自动分析给定的一篇文档或多篇文档,提炼、总结其中的要点信息,最终输出一篇长度较短、可读性良好的摘要(通常包含几句话或数百字),该摘要中的句子可直接出自原文,也可重新撰写所得。
根据输入文本的数量划分,文本摘要技术可以分为单文档摘要和多文档摘要。 在单文档摘要系统中,一般都采取基于抽取的方法。而对于多文档而言,由于在同一个主题中的不同文档中不可避免地存在信息交叠和信息差异,因此如何避免信息冗余,同时反映出来自不同文档的信息差异是多文档文摘中的首要目标,而要实现这个目标通常以为着要在句子层以下做工作,如对句子进行压缩,合并,切分等。另外,单文档的输出句子一般是按照句子在原文中出现的顺序排列,而在多文档摘要中,大多采用时间顺序排列句子,如何准确的得到每个句子的时间信息,也是多文档摘要需要解决的一个问题。
10、语音识别
语言识别指的是将不同语言的文本区分出来。其利用语言的统计和语法属性来执行此任务。语言识别也可以被认为是文本分类的特殊情况
分词(切词)
分词是自然语言处理的基础,分词准确度直接决定了后面的词性标注、句法分析、词向量以及文本分析的质量。
前向最大匹配算法
分词的目的是将一段中文分成若干个词语,前向最大匹配就是从前向后寻找在词典中存在的词。
例子:
假设Max_len = 5,即假设单词的最大长度为5。 再假设我们现在词典中存在的词有: [“我们”, “经常”,“常有”, “有意见”,“有意”, “意见”, “分歧”, “我”,“们”,“经”,“常”,“有”,“意”,“见”]
现在,用前向最大匹配算法 来划分 我们经常有意见分歧 这句话。
我们经常有意见分歧(max_len = 5)
第一轮:取子串 “我们经常有”,正向取词,如果匹配失败,每次去掉匹配字段 最后面 的一个字。
-
“我们经常有”,扫描词典中的5字单词,没有匹配,子串长度减 1 变为“我们经常”。
-
“我们经常”,扫描词典中的4字单词,没有匹配,变为“我们经”。
-
“我们经”,扫描词典中的3字单词,没有匹配, 变为“我们”。
-
“我们”,扫描词典中的2字单词,匹配成功,输出“我们”,输入变为 “经常有意见分歧” 。
第二轮:取子串“经常有意见”
-
“经常有意见”,扫描词典中的5字单词,没有匹配,子串长度减 1 变为“经常有意”。
-
“经常有意”,扫描词典中的4字单词,没有匹配,子串长度减 1 变为“经常有”。
-
“经常有”,扫描词典中的3字单词,没有匹配,子串长度减 1 变为“经常”。
-
“经常”,扫描词典中的2字单词,有匹配,输出“经常”,输入变为“有意见分歧”。
以此类推,直到输入长度为0时,扫描终止。 最终,前向最大匹配算法得出的结果为: 我们 / 经常 / 有意见 / 分歧
N-gram算法
朴素贝叶斯:
-
朴素贝叶斯法是贝叶斯定理与特征条件独立性假设的分类方法。
-
最为广泛的两种分类模型是决策树模型和朴素贝叶斯模型。
朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
整个朴素贝叶斯分类分为三个阶段:
第一阶段:准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段:分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段:应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
比如:

朴素贝叶斯模型就是要衡量这句话属于垃圾短信敏感句子的概率。

朴素贝叶斯将句子处理为一个词袋模型(Bag-of-Words, BoW),以至于不考虑每个单词的顺序。
N-gram 模型就是考虑句子中单词之间的顺序。
N-gram
N-gram模型是一种语言模型(Language Model,LM),语言模型是一个基于概率的判别模型,它的输入是一句话(单词的顺序序列),输出是这句话的概率,即这些单词的联合概率(joint probability)。
N-gram本身也指一个由N个单词组成的集合,各单词具有先后顺序,且不要求单词之间互不相同。常用的有 Bi-gram (N = 2) 和 Tri-gram (N = 3)
例如: I love deep learning

-
用途
1、词性标注
N-gram可以实现词性标注。例如“爱”这个词,它既可以作为动词使用,也可以作为名词使用。不失一般性,假设我们需要匹配一句话中“爱”的词性。
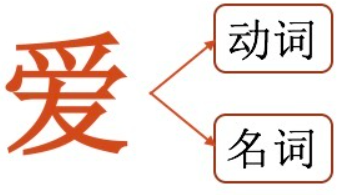

我们可以将词性标注看成一个多分类问题,按照Bi-gram计算每一个词性概率:

选取概率更大的词性(比如动词)作为这句话中“爱”字的词性。
2、垃圾短信分类
-
步骤一:给短信的每个句子断句。
-
步骤二:用N-gram判断每个句子是否垃圾短信中的敏感句子。
-
步骤三:若敏感句子个数超过一定阈值,认为整个邮件是垃圾短信。
3、分词器
用N-gram可以实现一个简单的分词器(Tokenizer)。同样地,将分词理解为多分类问题:X表示有待分词的句子,Y 表示该句子的一个分词方案。

4、机器翻译和语音识别

词向量(Word Embedding)
词向量是表示自然语言里单词的一种方法,即把每个词都表示为一个N维空间内的点,即一个高维空间内的向量。通过这种方法,实现把自然语言计算转换为向量计算。
如何把词转换为向量
-
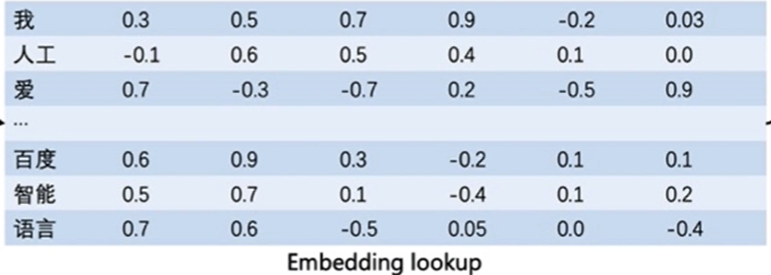
通常情况下,我们可以维护一个如图所示的查询表。
-
表中每一行都存储了一个特定词语的向量值,每一列的第一个元素都代表着这个词本身,以便于我们进行词和向量的映射。
-
(如“我”对应的向量值为 [0.3,0.5,0.7,0.9,-0.2,0.03] )
-
给定任何一个或者一组单词,我们都可以通过查询这个excel,实现把单词转换为向量的目的,这个查询和替换过程称之为Embedding Lookup。
-
在进行神经网络计算的过程中,需要大量的算力,常常要借助特定硬件(如GPU)满足训练速度的需求。
-
GPU上所支持的计算都是以张量(Tensor)为单位展开的。
-
因此在实际场景中,我们需要把Embedding Lookup的过程转换为张量计算。

如何让向量具有语义信息
得到每个单词的向量表示后,我们需要思考下一个问题:比如在多数情况下,“香蕉”和“橘子”更加相似,而“香蕉”和“句子”就没有那么相似;同时,“香蕉”和“食物”、“水果”的相似程度可能介于“橘子”和“句子”之间。那么如何让存储的词向量具备这样的语义信息呢?
word2vec
是一个将单词转换成向量形式的工具。
通过上下文来学习语义信息
包含两个经典模型 CBOW 和 Skip-gram
CBOW
通过上下文的词向量推理中心词。
-
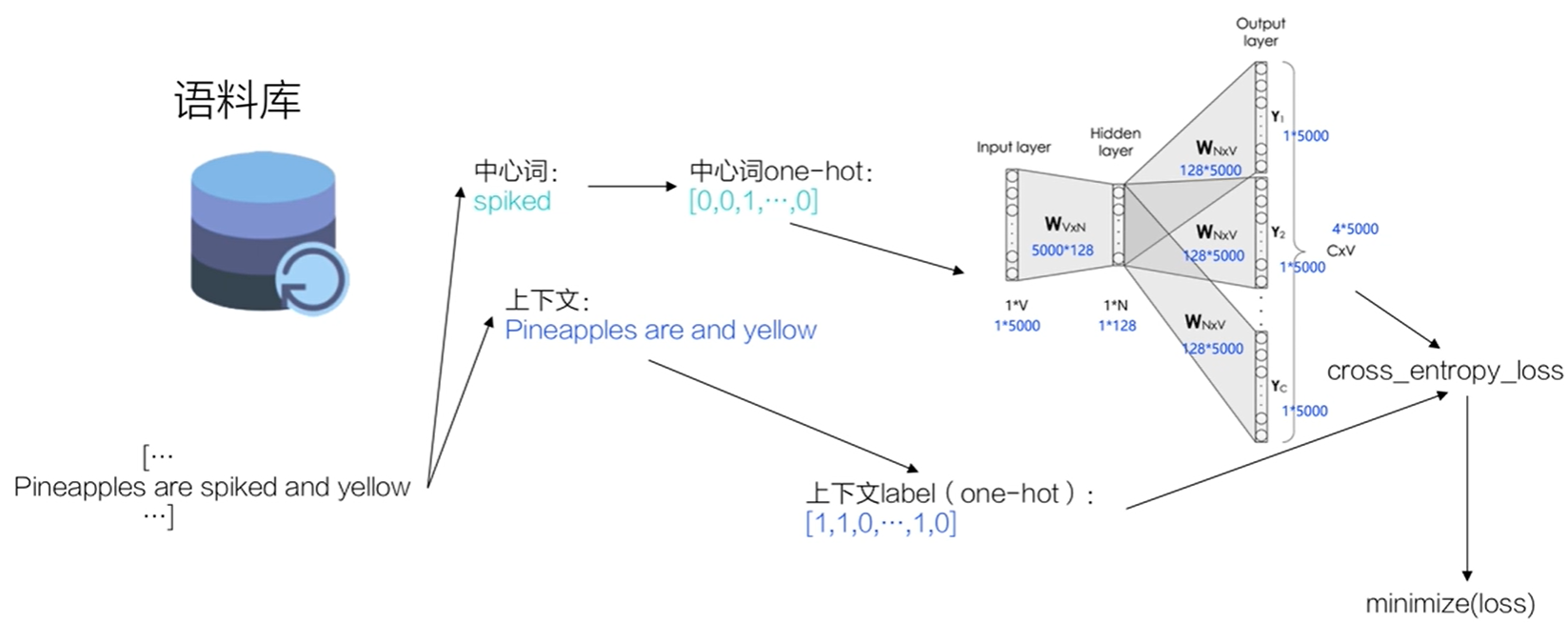
假设有一个句子“Pineapples are spiked and yellow"
-
先在句子中选定一个中心词,并把其它词作为这个中心词的上下文。
-
把“Spiked”作为中心词,把“Pineapples、are、and、yellow”作为中心词的上下文。
-
使用上下文的词向量推理中心词,这样中心词的语义就被传递到上下文的词向量中,如“Spiked → pineapple”,从而达到学习语义信息的目的。

Skip-gram
根据中心词推理上下文。
-
假设有一个句子“Pineapples are spiked and yellow"
-
先选定一个中心词,并把其他词作为这个中心词的上下文。
-
把“Spiked”作为中心词,把“Pineapples、are、and、yellow”作为中心词的上下文。
-
使用中心词的词向量去推理上下文,这样上下文定义的语义被传入中心词的表示中,如“pineapple → Spiked”, 从而达到学习语义信息的目的。

一般来说,CBOW比Skip-gram训练快且更加稳定一些,然而,skip-gram比CBOW更好的处理生僻字(出现频率低的字),原因也正是因为skip-gram不会刻意回避生僻字。
用神经网络实现CBOW
-
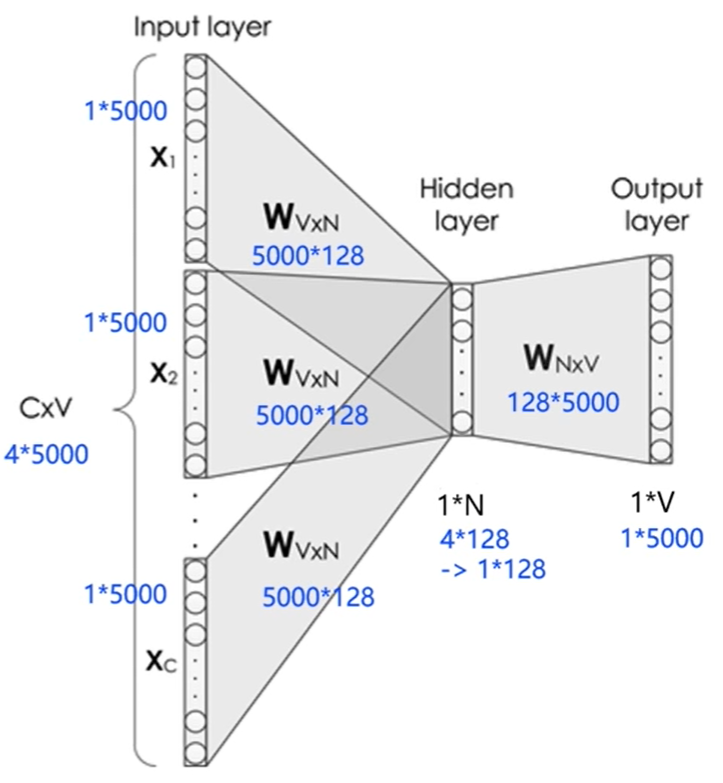
给定一句话 ” Pineapples are spiked and yellow" , C = 4 , V = 5000 , N = 128
-
模型分为3层
-
输入层: 一个形状为 C×V 的 one-hot 张量,其中C代表上下文中词的个数,通常是一个偶数,我们假设为4;V表示词表大小,我们假设为5000,该张量的每一行都是一个上下文词的 one-hot 向量表示,比如“Pineapples, are, and, yellow”。
-
隐藏层: 一个形状为V×N的参数张量 W1 ,一般称为word-embedding,N表示每个词的词向量长度,我们假设为128。
-
输入张量和word embedding W1进行矩阵乘法,就会得到一个形状为C×N的张量。综合考虑上下文中所有词的信息去推理中心词,因此将上下文中 C 个词 相加 得一个 1×N 的向量,是整个上下文的一个隐含表示。
-
-
输出层(预测中心词): 创建另一个形状为N×V的参数张量,将隐藏层得到的1×N的向量乘以该N×V的参数张量,得到了一个形状为1×V的向量。最终,1×V的向量代表了使用上下文去推理中心词,每个候选词的打分,再经过 softmax 函数的归一化,即得到了对中心词的推理概率:
-
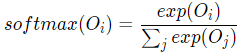
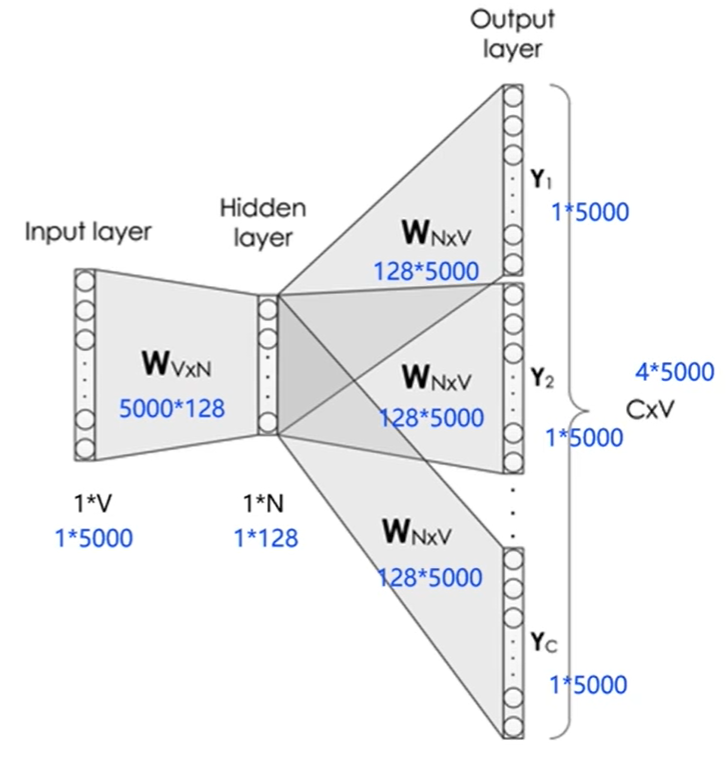
用神经网络实现Skip-gram
-
给定一句话 ” Pineapples are spiked and yellow" , C = 4 , V = 5000 , N = 128
-
模型分为3层
-
输入层:一个形状为 1*V的 one-hot 向量,代表中心词
-
隐藏层:一个形状为 V*N 的参数向量 W1,一般称为 word-embedding , N表示每个词的向量表示长度。将输入向量和参数向量 W1 进行矩阵乘法,得到一个形状为 1×N的张量,即词语的向量表示。
-
输出层:创建另一个形状为 N*V 的参数张量 W2 ,将隐藏层输出的 1×N 的向量乘以 W2的张量,得到一个形状为 1 ×V 的向量。代表每个候选词的打分,使用 softmax 函数,对这些打分进行归一化,即得到中心词的预测概率。
-
用二分类实际实现Skip-gram
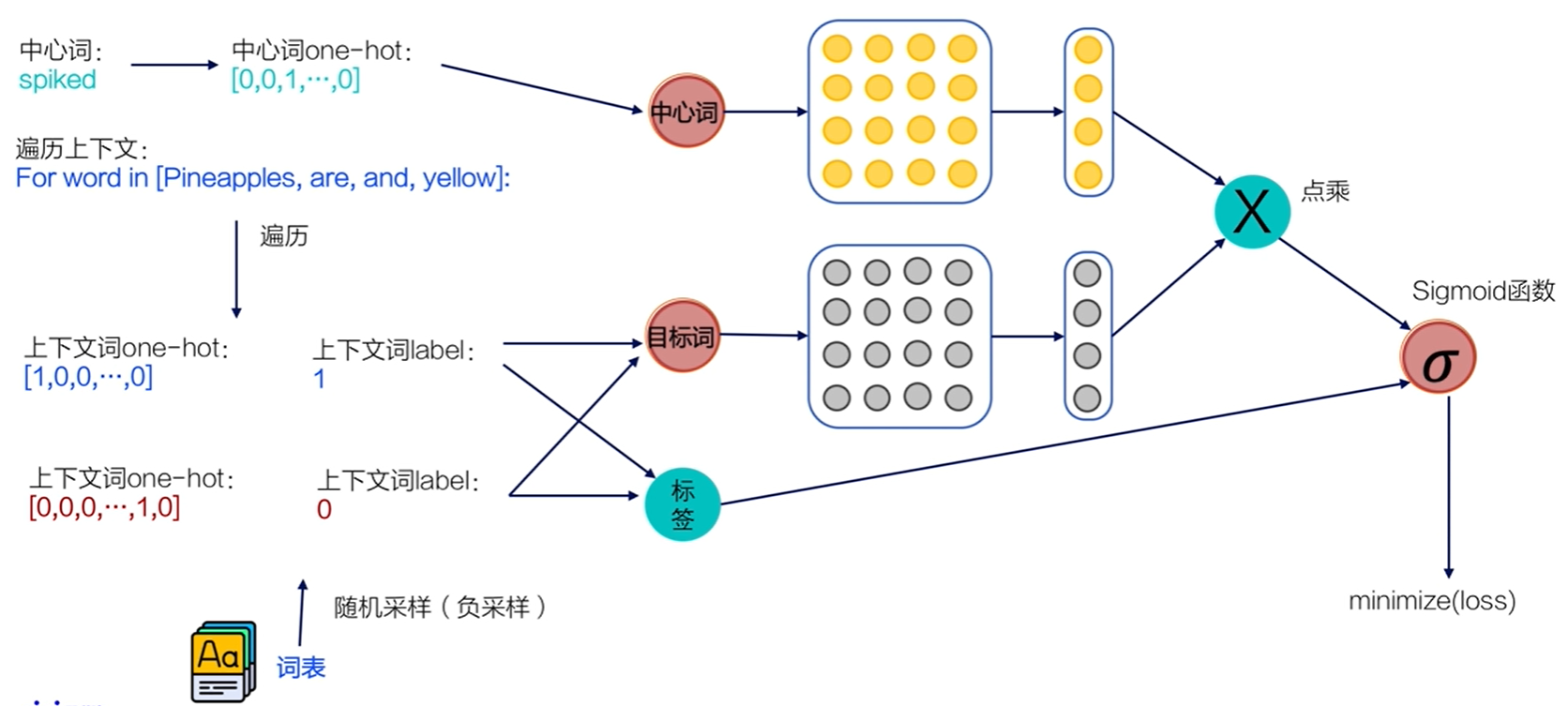
因为在实际情况中,vocab_size通常很大(几十万甚至几百万),导致W0 W1也会非常大。所参与的矩阵运算并不是通过一个矩阵乘法实现,而是通过指定ID,对参数W0获取。对W1一个非常大的矩阵运算
随机从词表中选择几个代表词,通过最小化这几个代表词的概率,去近似最小化整体的预测概率。
负采样 :比如,先指定一个中心词(如“人工”)和一个目标词正样本(如“智能”),再 随机 在词表中采样几个目标词负样本(如“日本”,“喝茶”等)。有了这些内容,我们的skip-gram模型就变成了一个二分类任务。对于目标词正样本,我们需要最大化它的预测概率;对于目标词负样本,我们需要最小化它的预测概率。通过这种方式,我们就可以完成计算加速。上述做法,我们称之为负采样。
使用飞桨实现Skip-gram
找到一个合适的语料用于训练word2vec模型。
使用text8数据集,这个数据集里包含了大量从维基百科收集到的英文语料。
数据处理
-
下载语料
-
把下载的语料读取到程序里
-
切词(分词)
# 对语料进行预处理(分词)
def data_preprocess(corpus):
# 由于英文单词出现在句首的时候经常要大写,所以我们把所有英文字符都转换为小写,
# 以便对语料进行归一化处理(Apple vs apple等)
corpus = corpus.strip().lower()
corpus = corpus.split(" ")
return corpus
corpus = data_preprocess(corpus)
4、在经过切词后,需要对语料进行统计,为每个词构造ID。
一般来说,可以根据每个词在语料中出现的频次构造ID,频次越高,ID越小,便于对词典进行管理。
word_freq_dict = sorted(word_freq_dict.items(), key = lambda x:x[1], reverse = True)
5、构造3个不同的词典,分别存储
每个词到id的映射关系:word2id_dict
每个id出现的频率:word2id_freq
每个id到词的映射关系:id2word_dict
word2id_dict = dict() word2id_freq = dict() id2word_dict = dict()
6、按照频率,从高到低,开始遍历每个单词,并为这个单词构造一个独一无二的id
7、得到 word2id 词典后,把每个词替换成对应的ID,便于神经网络进行处理
8、需要使用二次采样法处理原始文本。
二次采样法的主要思想是降低高频词在语料中出现的频次。方法是随机将高频的词抛弃,频率越高,被抛弃的概率就越大;频率越低,被抛弃的概率就越小。标点符号或冠词这样的高频词就会被抛弃,从而优化整个词表的词向量训练效果。
# 使用二次采样算法(subsampling)处理语料,强化训练效果
def subsampling(corpus, word2id_freq):
# 这个discard函数决定了一个词会不会被替换,这个函数是具有随机性的,每次调用结果不同
# 如果一个词的频率很大,那么它被遗弃的概率就很大
def discard(word_id):
return random.uniform(0, 1) < 1 - math.sqrt(
1e-4 / word2id_freq[word_id] * len(corpus))
corpus = [word for word in corpus if not discard(word)]
return corpus
corpus = subsampling(corpus, word2id_freq)
print("%d tokens in the corpus" % len(corpus))
print(corpus[:50])
9、构造训练数据,使用一个滑动窗口对语料从左到右扫描,在每个窗口内,中心词需要预测它的上下文,并形成训练数据。
-
给定一个中心词和一个需要预测的上下文词,把这个上下文词作为正样本。
-
通过词表随机采样的方式,选择若干个负样本。
-
把一个大规模分类问题转化为一个2分类问题,通过这种方式优化计算速度。
negative_sample_num代表了对于每个正样本,我们需要随机采样多少负样本用于训练,一般来说,negative_sample_num的值越大,训练效果越稳定,但是训练速度越慢。
附
sorted()
1、先创建一个列表a
2、直接使用sorted方法,返回一个列表就是排序好的
a = [1,5,3,6,2] sorted(a) >>[1,2,3,5,6]
3、假如a是一个由元组构成的列表,需要用到参数key,也就是关键词。
lambda是一个隐函数,是固定写法,不要写成别的单词;x表示列表中的一个元素,在这里,表示一个元组,x只是临时起的一个名字,你可以使用任意的名字;x[0]表示元组里的第一个元素,当然第二个元素就是x[1];所以这句命令的意思就是按照列表中第一个元素排序。
x:x[] 字母可以随意修改,排序方式按照中括号 [] 里面的维度进行排序,[0]按照第一维排序,[1]按照第二维排序
a = [('b',4),('a',0),('c',2),('d',3)]
sorted(a,key = lambda x:x[0])
>>[('a',0),('b',4),('c',2),('d',3)]
# 按照第二个元素排序
sorted(a,key = lambda x:x[1])
>>[('a',0),('c',2),('d',3),('b',4)]
4、还可以使用 reverse 参数实现倒序排列
a = [1,5,3,6,2] sorted(a,reverse = True) >>[6,5,3,2,1]

