
- 1k8s 部署集群遇到的“一丢丢”问题_the object provided is unrecognized (must be of ty
- 2Unity UGUI事件输入,点击UI无反应_ugui按钮无响应的原因
- 3VMware17虚拟机安装macos Sonoma 14.2.1 23C71教程以及镜像CDR/ISO下载_vmware mac镜像
- 4SuperEdge 云边隧道新特性:从云端SSH运维边缘节点
- 5黑马学Docker(三)_黑马程序员docker-compose
- 6Qt——Qt实现数据可视化之QChart的使用总结(使用QChart画出动态显示的实时曲线)
- 7Docker详解:如何创建运行Memcached的Docker容器_docker memcached
- 8如何在自定义数据集上训练 YOLOv9
- 9数据库的魅力:深入探索与应用
- 10CVPR 2021 审稿意见出了,你也许需要这份学术论文投稿与返修指南
【数据结构与算法】图论及其相关算法_图论算法
赞
踩
图的基本介绍
线性表局限于一个直接前驱和一个直接后继的关系,树也只能有一个直接前驱也就是父节点,当我们需要表示多对多的关系时, 这里我们就用到了图。
图是一种数据结构,其中结点可以具有零个或多个相邻元素。两个结点之间的连接称为边。 结点也可以称为顶点。如图:
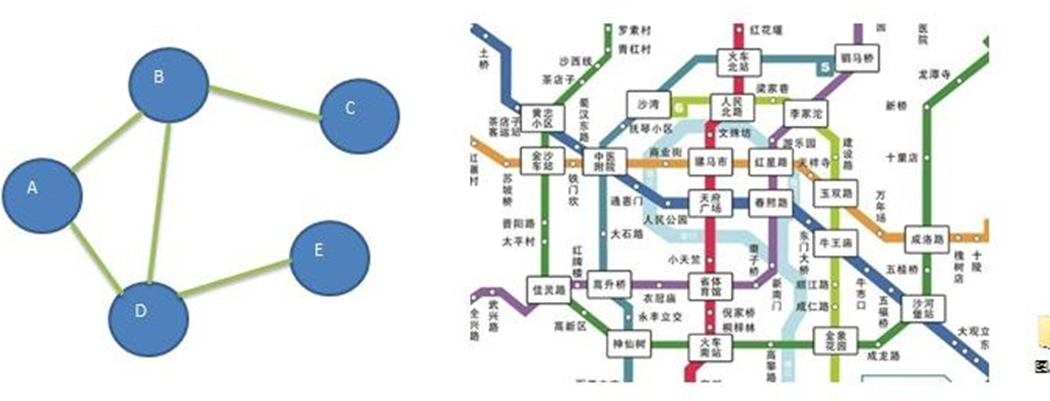
简单来说,图就是由顶点的有穷非空集合和顶点之间的边组成的集合。通常表示为:G(V,E),其中,G 表示一个图,V 表示顶点的集合,E 表示边的集合。
然后我们说说图中的一些常见概念:
-
节点(Vertex):图中的基本元素,用于表示某个实体。 -
边(Edge):连接两个节点的线段,用于表示节点之间的关系。 -
度(Degree):度表示一个顶点包含多少条边,在有向图中,还分为出度和入度,出度表示从该顶点出去的边的条数,入度表示进入该顶点的边的条数。 -
有向图和无向图:边是否有方向决定图是有向图还是无向图。有向边指明了边的起点和终点,无向边的两个节点没有起点和终点之分。
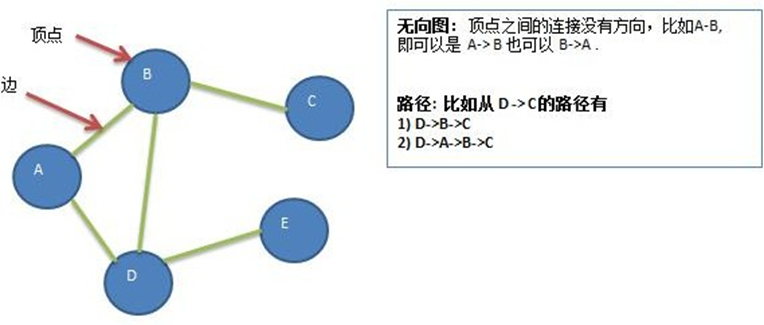
-
带权图和无权图:边是否有权值决定图是带权图还是无权图。带权边有一个数值,表示边的权重,无权边的权重视为1。
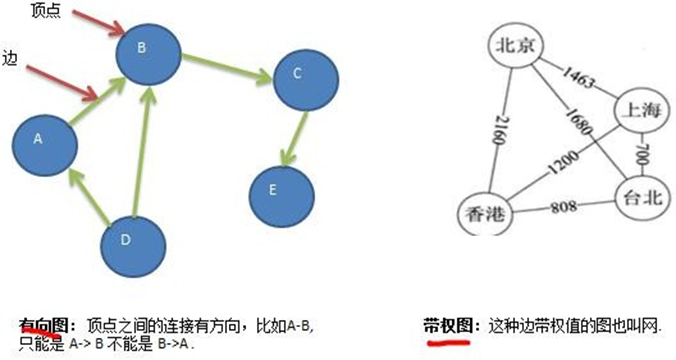
-
路径:图中一系列顶点之间的边的序列叫做路径。 -
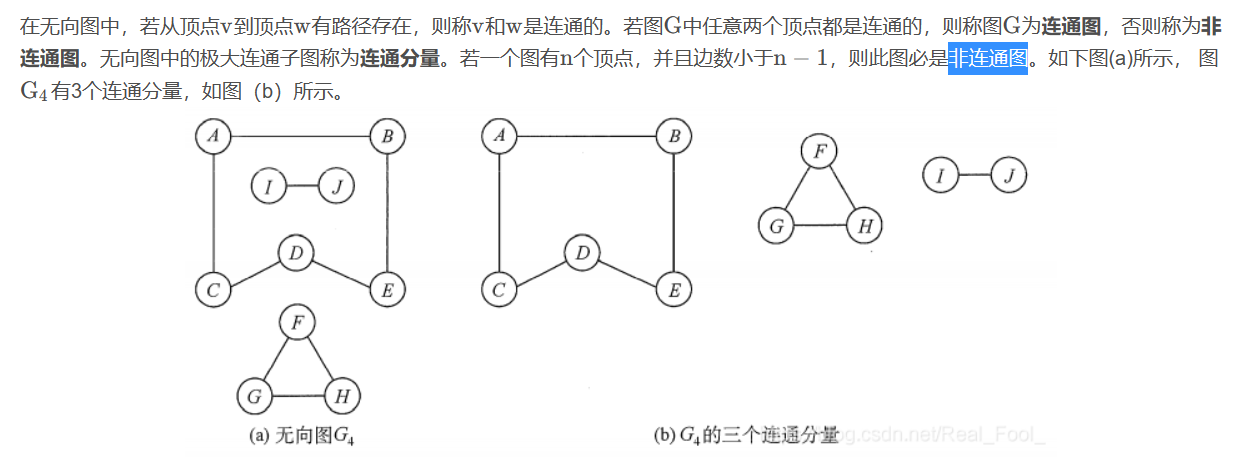
连通性:如果任何两个节点之间都存在路径,那么该图是连通的。否则是非连通图。 -
海量图:节点和边的数量巨大,远远超出计算机内存大小,需要特殊的算法和存储结构才能处理的图。
图的表示方式
图的表示方式有两种:
- 二维数组表示(邻接矩阵)
- 链表表示(邻接表)
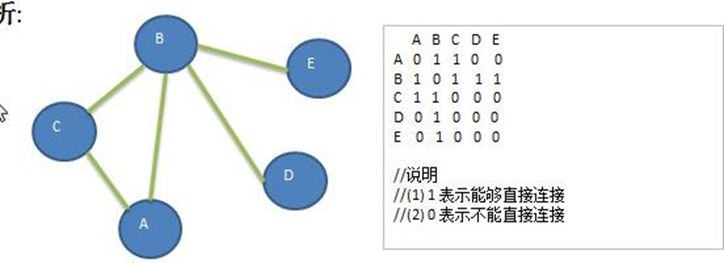
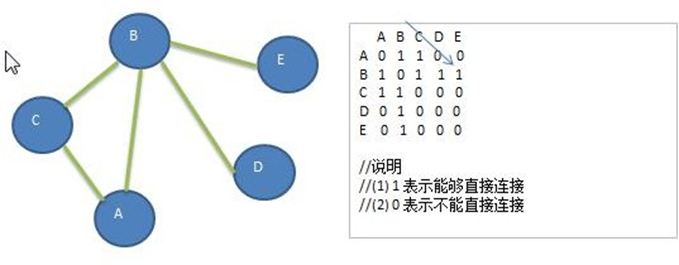
邻接矩阵
邻接矩阵是图的一种存储结构,它使用一个二维数组来表示图中节点之间的边。
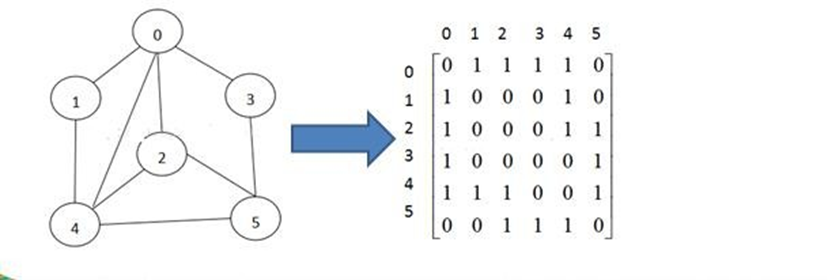
具体来说:
- 邻接矩阵的行数和列数都是图中的节点数n。
- 矩阵中的每个元素都代表一条边。如果节点i和节点j之间有边,则矩阵的第i行第j列元素为1,否则为0。
- 对于带权图,矩阵的元素为对应的权值,而不是1。
- 矩阵的主对角线上的元素都是0,因为节点不会和自身相连。
- 邻接矩阵适用于表示稠密图,空间复杂度为O(n2)。如果图是稀疏的,空间利用率比较低。
邻接矩阵的优点是:
- 可以在O(1)时间内判断任意两节点之间是否有边。
- 方便实现一些算法,如广度优先搜索、深度优先搜索等。
邻接矩阵的缺点是:
- 空间复杂度高,如果图是稀疏的会造成空间浪费。
- 难以表示动态图,如果频繁添加和删除边,需要频繁重建邻接矩阵。
邻接表
邻接表是图的另一种存储结构,它使用链表来存储每个节点的相邻节点。
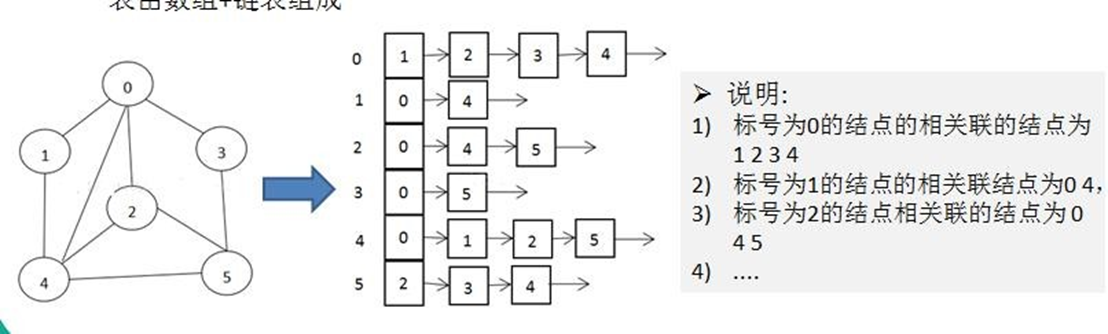
具体来说:
- 邻接表由数组和链表组成。数组的每个元素都是一个链表,表示对应节点的相邻节点列表。
- 数组的索引就是节点的序号,数组大小为节点数n。
- 如果节点i和节点j有边,则将j添加到i对应的链表中。
- 对于带权图,每个节点在链表中的元素不再只存储相邻节点的序号,而是存储一个结构体,包含相邻节点序号和对应的权值。
- 邻接表适用于稀疏图,空间复杂度为O(n+e),e是边数。对于稠密图,空间利用率会比较高。
邻接表的优点是:
6. 空间复杂度较低,适用于表示稀疏图。
7. 易于实现动态图的增加和删除操作。
邻接表的缺点是:
8. 难以在O(1)时间内判断任意两节点之间是否有边,需要遍历链表。
9. 不太方便实现一些算法,如广度优先搜索和深度优先搜索。
图的深度优先遍历(DFS)
所谓图的遍历,即是对结点的访问。一个图有那么多个结点,如何遍历这些结点,需要特定策略,一般有两种访问策略:
深度优先遍历(DFS)广度优先遍历(BFS)
概述
深度优先遍历,从初始访问结点出发,初始访问结点可能有多个邻接结点,深度优先遍历的策略就是首先访问第一个邻接结点,然后再以这个被访问的邻接结点作为初始结点,访问它的第一个邻接结点。
可以这样理解: 每次都在访问完当前结点后首先访问当前结点的第一个邻接结点。我们可以看到,这样的访问策略是优先往纵向挖掘深入,而不是对一个结点的所有邻接结点进行横向访问。显然,深度优先搜索是一个递归的过程
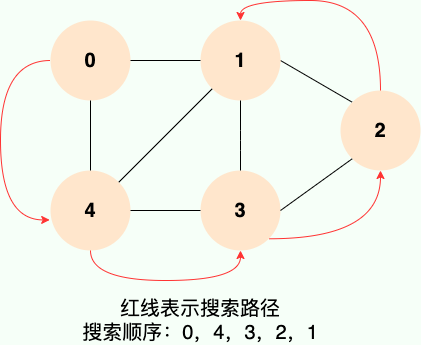
总的来说:深度优先搜索(Depth-First Search)是一种图的遍历算法。它从某个节点出发,尽可能深地搜索下去,直到遍历完当前路径上所有节点。然后回溯,继续尽可能深地搜索下一条路径。
深度优先搜索的主要应用是图的连通性检查,拓扑排序,求解切分数以及求解二分图的最大匹配数等。
实现步骤
深度优先搜索的过程可以用递归实现。主要步骤如下:
- 从目标图的某个节点v出发,访问该节点。
- 如果v的相邻节点w未被访问,则递归访问w。
- 如果w已被访问,则回到v节点,转而访问v的另一个未访问相邻节点。
- 如果v的所有相邻节点都已被访问,则回溯到v的上一个节点。
- 重复步骤3和4,直到所有节点被访问。
既然是使用递归,那么我们肯定也可以使用栈的思路去理解:
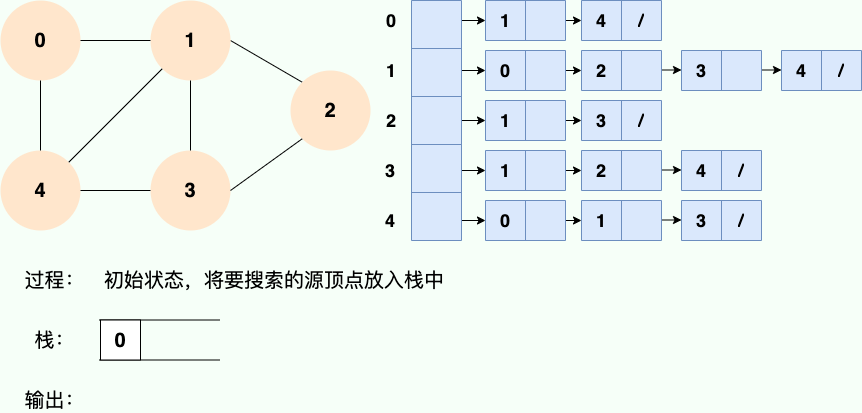
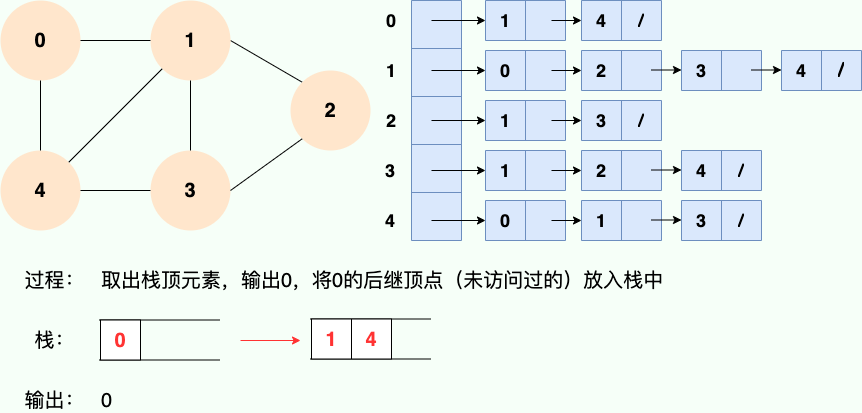
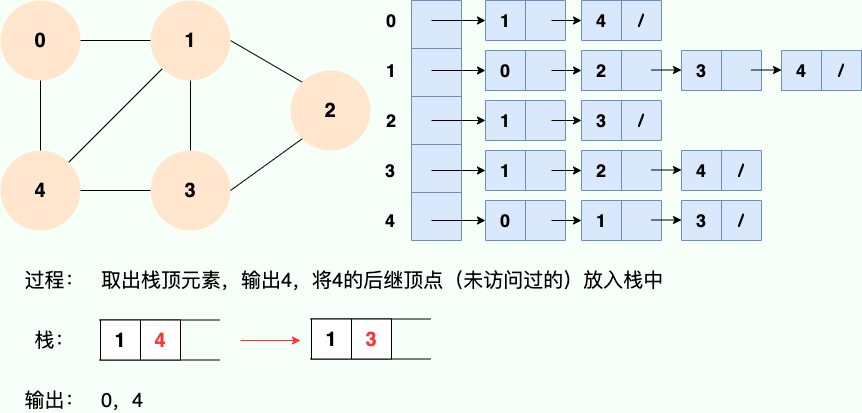
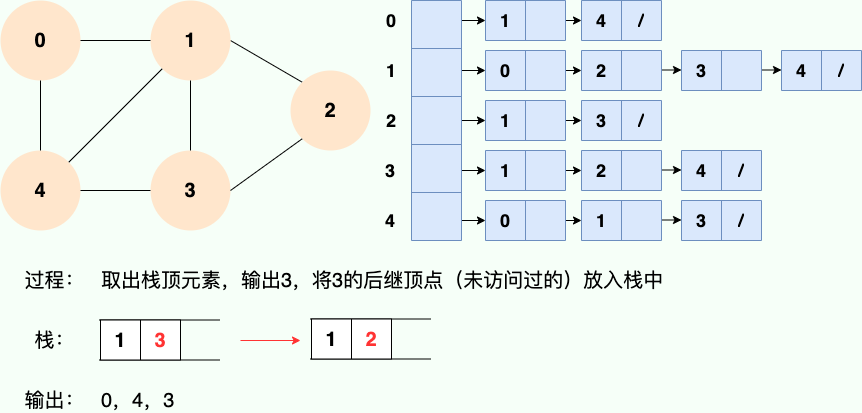
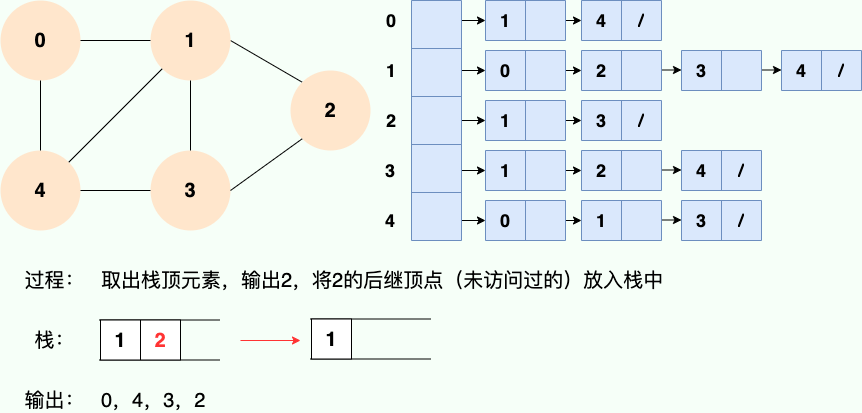
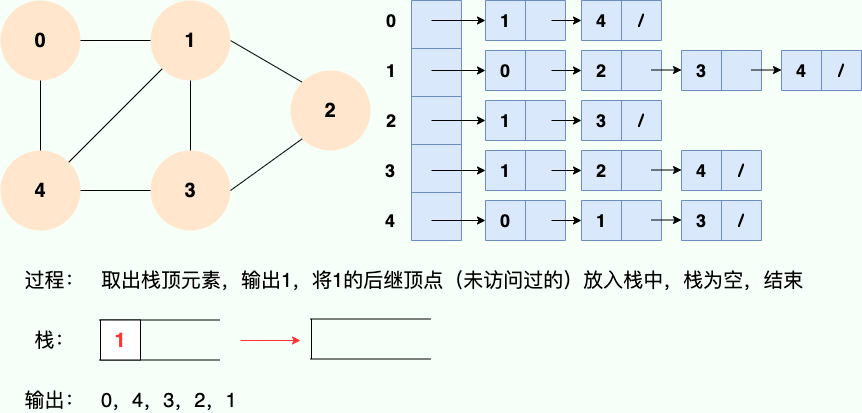
代码实现
public class Graph {
//存储顶点集合
private ArrayList<String> vertexList;
//存储图对应的邻结矩阵
private int[][] edges;
//表示边的数目
private int numOfEdges;
//定义给数组 boolean[], 记录某个结点是否被访问
private boolean[] isVisited;
//dfs部分
public void dfs(){
//初始化访问数组
isVisited = new boolean[vertexList.size()];
for (int i = 0;i < isVisited.length;i++) {
if (!isVisited[i]) {
dfs(i);
}
}
}
public void dfs(int index){
//打印出当前节点
System.out.print(getValueByIndex(index) + " -> ");
//设置当前节点已被访问
isVisited[index] = true;
//找出该节点的第一个邻接点
int firstNeighbor = getFirstNeighbor(index);
//说明存在第一个临界点
if (firstNeighbor != -1) {
dfs(firstNeighbor);
}
}
/**
* 找到index节点的第一个临界点,如果没有返回-1
* @param index
* @return
*/
public int getFirstNeighbor(int index) {
for (int i = 0; i < edges.length; i++) {
if (edges[index][i] == 1 && !isVisited[i]) {
return i;
}
}
return -1;
}
//返回结点i(下标)对应的数据 0->"A" 1->"B" 2->"C"
public String getValueByIndex(int i) {
return vertexList.get(i);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
注意:
- 我们getFirstNeighbor方法中,这里的j一定是从0开始的,有的人容易弄成index+1开始,这是没有考虑到不从A开始遍历的情况。
- 之所以要遍历我们的节点列表,是因为可能是非连通图,从一个节点开始遍历可能不会把整个图的节点都遍历到
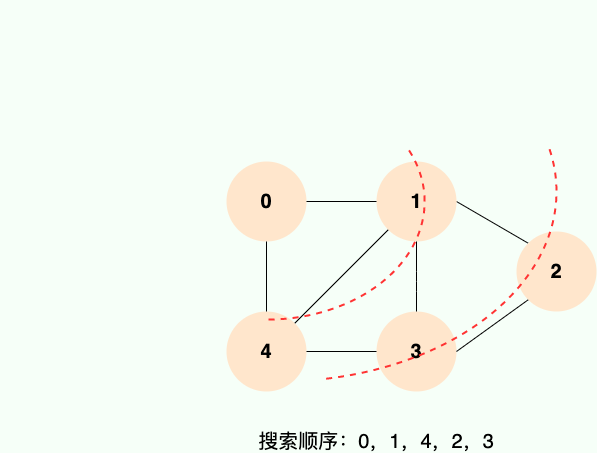
图的广度优先遍历(BFS)
概述
广度优先搜索(Breadth-First Search)是一种图的遍历算法。它从某个节点出发,首先访问该节点相邻的所有节点,然后访问相邻节点的相邻节点,以此类推,直到遍历完所有节点为止。
广度优先搜索就像水面上的波纹一样一层一层向外扩展:
与深度优先搜索相比,广度优先搜索的特点是:
- 会先访问离起点节点更近的节点。深度优先搜索会尽可能深的搜索,可能离起点更远。
- 使用队列实现,空间复杂度较高。深度优先搜索使用递归栈,空间复杂度较低。
广度优先搜索主要用于图的最短路径问题,拓扑排序等。
实现步骤
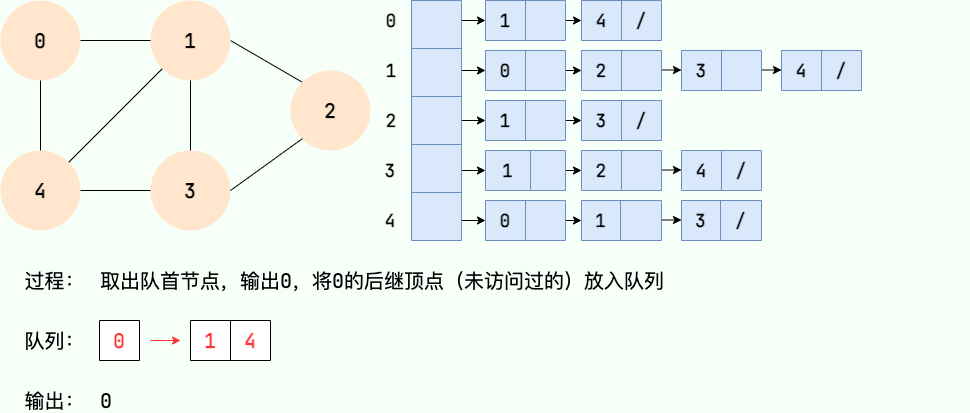
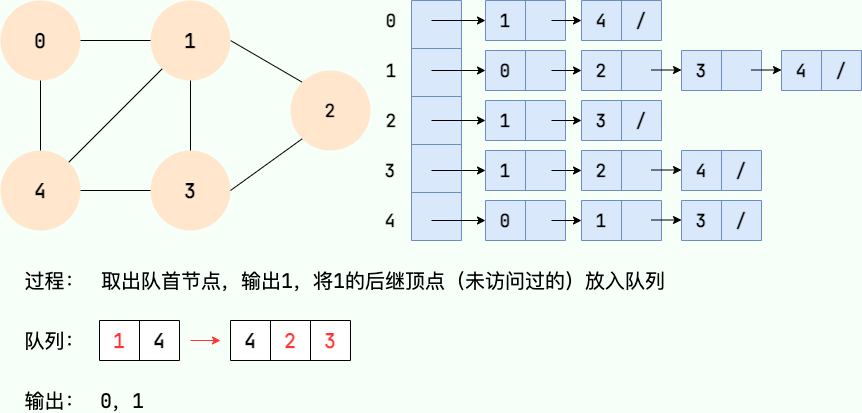
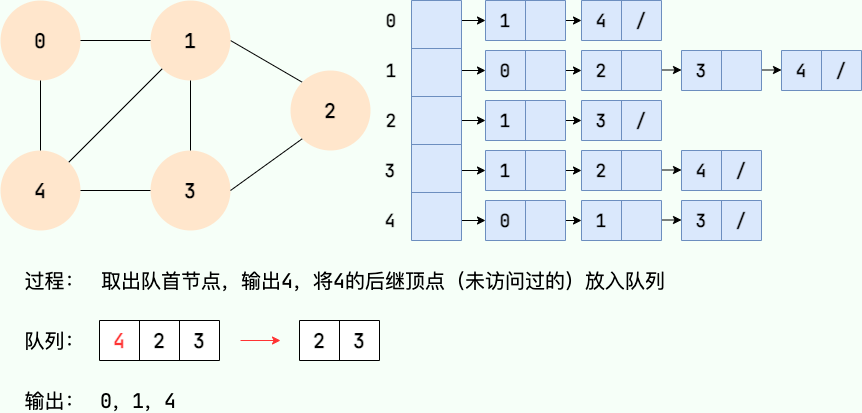
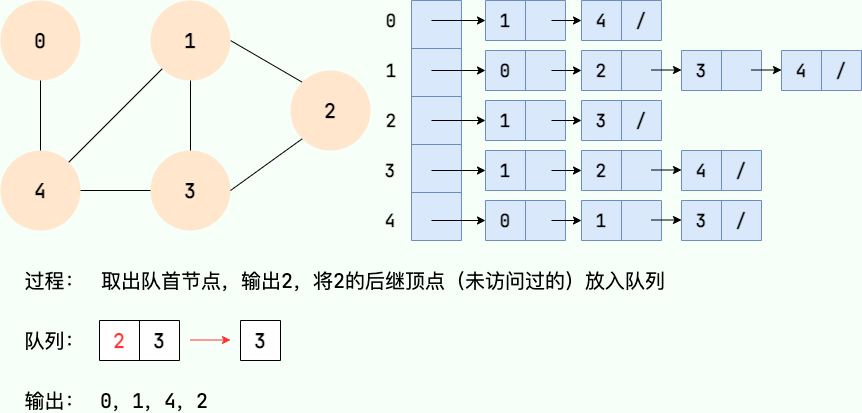
广度优先搜索的过程可以用队列实现。主要步骤如下:
- 从图的某个节点v出发,访问该节点并将其入队。
- 取出队首节点,访问该节点的所有未访问相邻节点,并将相邻节点入队。
- 重复步骤2,直到队列为空。
- 如果图中还有未访问节点,则以其中一个未访问节点为起点,重复步骤1~3。
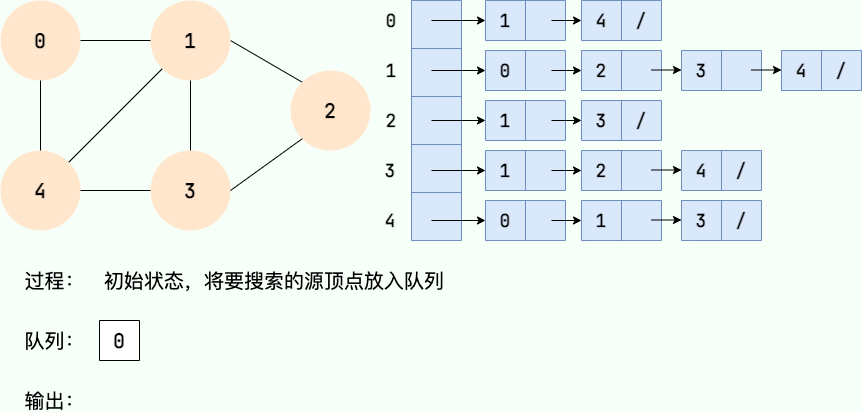
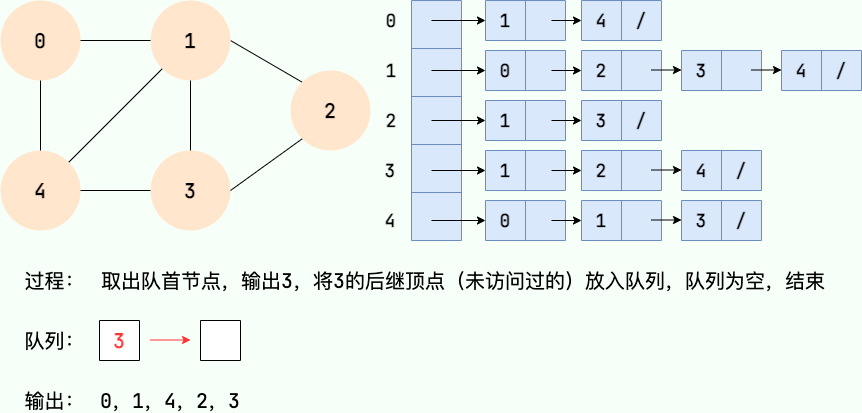
代码实现
public class Graph {
//存储顶点集合
private ArrayList<String> vertexList;
//存储图对应的邻结矩阵
private int[][] edges;
//表示边的数目
private int numOfEdges;
//定义给数组 boolean[], 记录某个结点是否被访问
private boolean[] isVisited;
/**
* 在bfs中负责找到指定节点的所有未遍历节点
* @param index
*/
public void getNeighbors(int index, Queue<Integer> queue){
for (int i = 0; i < edges.length; i++) {
if (edges[index][i] == 1 && !isVisited[i]) {
queue.add(i);
//将入队节点标为已访问
isVisited[i] = true;
}
}
}
public void bfs(){
//初始化访问数组
isVisited = new boolean[vertexList.size()];
for (int i = 0;i < isVisited.length;i++) {
if (!isVisited[i]) {
bfs(i);
}
}
}
public void bfs(int index) {
//创建队列
Queue<Integer> queue = new LinkedList<>();
//首先将起始节点加入队列,并设为已访问
queue.add(index);
isVisited[index] = true;
//每次弹出的队头
Integer head;
while (!queue.isEmpty()) {
//弹出头节点
head = queue.poll();
//并将其临界点全部放入队列
getNeighbors(head,queue);
//打印该节点
System.out.print(getValueByIndex(head) + " -> ");
}
}
//返回结点i(下标)对应的数据 0->"A" 1->"B" 2->"C"
public String getValueByIndex(int i) {
return vertexList.get(i);
}
//返回结点的个数
public int getNumOfVertex() {
return vertexList.size();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
图的常用代码汇总
public class Graph {
private ArrayList<String> vertexList; //存储顶点集合
private int[][] edges; //存储图对应的邻结矩阵
private int numOfEdges; //表示边的数目
private boolean[] isVisited; //记录某个结点是否被访问
public static void main(String[] args) {
//测试一把图是否创建ok
int n = 8; //结点的个数
//String Vertexs[] = {"A", "B", "C", "D", "E"};
String Vertexs[] = {"1", "2", "3", "4", "5", "6", "7", "8"};
//创建图对象
Graph graph = new Graph(n);
//循环的添加顶点
for(String vertex: Vertexs) {
graph.insertVertex(vertex);
}
//添加边
//A-B A-C B-C B-D B-E
// graph.insertEdge(0, 1, 1); // A-B
// graph.insertEdge(0, 2, 1); //
// graph.insertEdge(1, 2, 1); //
// graph.insertEdge(1, 3, 1); //
// graph.insertEdge(1, 4, 1); //
//更新边的关系
graph.insertEdge(0, 1, 1);
graph.insertEdge(0, 2, 1);
graph.insertEdge(1, 3, 1);
graph.insertEdge(1, 4, 1);
graph.insertEdge(3, 7, 1);
graph.insertEdge(4, 7, 1);
graph.insertEdge(2, 5, 1);
graph.insertEdge(2, 6, 1);
graph.insertEdge(5, 6, 1);
//显示一把邻结矩阵
graph.showGraph();
//测试一把,我们的dfs遍历是否ok
System.out.println("深度遍历");
graph.dfs(); // A->B->C->D->E [1->2->4->8->5->3->6->7]
// System.out.println();
System.out.println("广度优先!");
graph.bfs(); // A->B->C->D-E [1->2->3->4->5->6->7->8]
}
//构造器
public Graph(int n) {
//初始化矩阵和vertexList
edges = new int[n][n];
vertexList = new ArrayList<String>(n);
numOfEdges = 0;
}
//得到第一个邻接结点的下标 w
/**
*
* @param index
* @return 如果存在就返回对应的下标,否则返回-1
*/
public int getFirstNeighbor(int index) {
for(int j = 0; j < vertexList.size(); j++) {
if(edges[index][j] > 0) {
return j;
}
}
return -1;
}
//根据前一个邻接结点的下标来获取下一个邻接结点
public int getNextNeighbor(int v1, int v2) {
for(int j = v2 + 1; j < vertexList.size(); j++) {
if(edges[v1][j] > 0) {
return j;
}
}
return -1;
}
//深度优先遍历算法
//i 第一次就是 0
private void dfs(boolean[] isVisited, int i) {
//首先我们访问该结点,输出
System.out.print(getValueByIndex(i) + "->");
//将结点设置为已经访问
isVisited[i] = true;
//查找结点i的第一个邻接结点w
int w = getFirstNeighbor(i);
while(w != -1) {//说明有
if(!isVisited[w]) {
dfs(isVisited, w);
}
//如果w结点已经被访问过
w = getNextNeighbor(i, w);
}
}
//对dfs 进行一个重载, 遍历我们所有的结点,并进行 dfs
public void dfs() {
isVisited = new boolean[vertexList.size()];
//遍历所有的结点,进行dfs[回溯]
for(int i = 0; i < getNumOfVertex(); i++) {
if(!isVisited[i]) {
dfs(isVisited, i);
}
}
}
//对一个结点进行广度优先遍历的方法
private void bfs(boolean[] isVisited, int i) {
int u ; // 表示队列的头结点对应下标
int w ; // 邻接结点w
//队列,记录结点访问的顺序
LinkedList queue = new LinkedList();
//访问结点,输出结点信息
System.out.print(getValueByIndex(i) + "=>");
//标记为已访问
isVisited[i] = true;
//将结点加入队列
queue.addLast(i);
while( !queue.isEmpty()) {
//取出队列的头结点下标
u = (Integer)queue.removeFirst();
//得到第一个邻接结点的下标 w
w = getFirstNeighbor(u);
while(w != -1) {//找到
//是否访问过
if(!isVisited[w]) {
System.out.print(getValueByIndex(w) + "=>");
//标记已经访问
isVisited[w] = true;
//入队
queue.addLast(w);
}
//以u为前驱点,找w后面的下一个邻结点
w = getNextNeighbor(u, w); //体现出我们的广度优先
}
}
}
//遍历所有的结点,都进行广度优先搜索
public void bfs() {
isVisited = new boolean[vertexList.size()];
for(int i = 0; i < getNumOfVertex(); i++) {
if(!isVisited[i]) {
bfs(isVisited, i);
}
}
}
//图中常用的方法
//返回结点的个数
public int getNumOfVertex() {
return vertexList.size();
}
//显示图对应的矩阵
public void showGraph() {
for(int[] link : edges) {
System.err.println(Arrays.toString(link));
}
}
//得到边的数目
public int getNumOfEdges() {
return numOfEdges;
}
//返回结点i(下标)对应的数据 0->"A" 1->"B" 2->"C"
public String getValueByIndex(int i) {
return vertexList.get(i);
}
//返回v1和v2的权值
public int getWeight(int v1, int v2) {
return edges[v1][v2];
}
//插入结点
public void insertVertex(String vertex) {
vertexList.add(vertex);
}
//添加边
/**
*
* @param v1 表示点的下标即使第几个顶点 "A"-"B" "A"->0 "B"->1
* @param v2 第二个顶点对应的下标
* @param weight 表示
*/
public void insertEdge(int v1, int v2, int weight) {
edges[v1][v2] = weight;
edges[v2][v1] = weight;
numOfEdges++;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
最小生成树算法
最小生成树是图论中的一个很重要的概念。它指的是连接图中所有节点的一棵树,且这棵树上的所有边的权值之和最小。
最小生成树有几个重要的性质:
- 它包含图中所有节点,没有孤立点。
- 它是一个树,没有环。
- 它的权值之和最小。
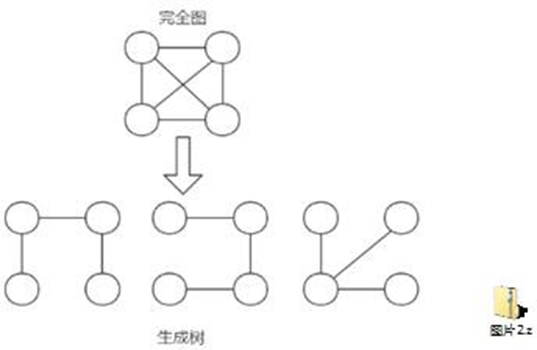
常见的最小生成树算法有:
4. Prim算法:从一个节点开始,不断向生成树中添加新的节点和边,直到包含所有的节点。每次添加的新边是到树中节点的最短边。
5. Kruskal算法:按照边的权值从小到大选择边,只要这条边不形成环,就添加到最小生成树中。
6. Dijkstra算法:用Dijkstra最短路径算法求出每个节点到其它所有节点的最短路径,最小生成树由这些最短路径形成。
最小生成树有许多实际应用,比如网络的连通性、电路布线等。它为这些实际问题提供了一种效率较高的解决方案。
总之,最小生成树是图论中一个非常经典和重要的概念,相关算法也比较重要,值得好好理解和掌握。
最小生成树(Kruskal(克鲁斯卡尔)和Prim(普里姆))算法动画演示
普里姆(Prim)算法
Prim算法是最小生成树的经典算法之一。它的基本思想是:
- 从图中的任意一个节点开始,逐步添加边和节点,形成最小生成树。每次添加的新边必须连接的树中的节点和不在树中的节点,并且这条新边必须是所有候选边中权值最小的一条。
Prim算法的步骤如下:
- 选择图中的任意一个节点作为起始节点,标记该节点已经被访问。
- 找出所有已访问节点连通的还未访问的节点中,权值最小的一条边。该边连接的未访问节点标记为已访问。
- 重复步骤2,直到所有节点都被访问为止。
- 形成的边集合即为最小生成树。
或者可以参考,下面这个视频讲得非常的清楚:
算法图解:

Prim算法的时间复杂度为O(n2),如果使用优先队列实现,可以降低到O(nlogn)。
Prim算法仅适用于带权无向连通图,如果图是有向图或非连通图,Prim算法无法得到最小生成树。
算法实践
代码实现:
import java.util.*;
public class PrimAlgorithm {
private static final int INF = Integer.MAX_VALUE;
public static int prim(int[][] graph) {
int n = graph.length;
//创建距离表,代表索引对应节点距离最小生成树的距离
int[] dist = new int[n];
//记录每个节点是否被添加,未添加记为false
boolean[] visited = new boolean[n];
//先将距离表都初始化为最大值
Arrays.fill(dist, INF);
//从0节点开始遍历,将距离更新一下
dist[0] = 0;
//记录要返回的最小权值
int res = 0;
for (int i = 0; i < n; i++) {
//u代表要添加的节点(距离最近且未访问)
int u = -1;
for (int j = 0; j < n; j++) {
if (!visited[j] && (u == -1 || dist[j] < dist[u])) {
u = j;
}
}
//将要添加的节点标为已访问
visited[u] = true;
//记录权值
res += dist[u];
//更新距离表
for (int v = 0; v < n; v++) {
if (!visited[v] && graph[u][v] != INF && graph[u][v] < dist[v]) {
dist[v] = graph[u][v];
}
}
}
return res;
}
public static void main(String[] args) {
int[][] graph = new int[][]{
{0, 2, INF, 6, INF},
{2, 0, 3, 8, 5},
{INF, 3, 0, INF, 7},
{6, 8, INF, 0, 9},
{INF, 5, 7, 9, 0}
};
int res = prim(graph);
System.out.println(res);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
在这个实现中,我们首先初始化了距离数组dist和访问标记数组visited,并将距离数组的所有元素初始化为无穷大(表示尚未访问到的节点)。
然后,我们从节点0开始遍历所有节点,每次选取距离数组中最小的值作为下一个要访问的节点。然后,我们将这个节点标记为已访问,并将其与尚未访问的节点的距离更新到距离数组中。最后,我们将所有边的权值之和作为最小生成树的权值返回。
这个实现的时间复杂度为O(n^2),其中n是节点数。
克鲁斯卡尔(Kruskal)算法
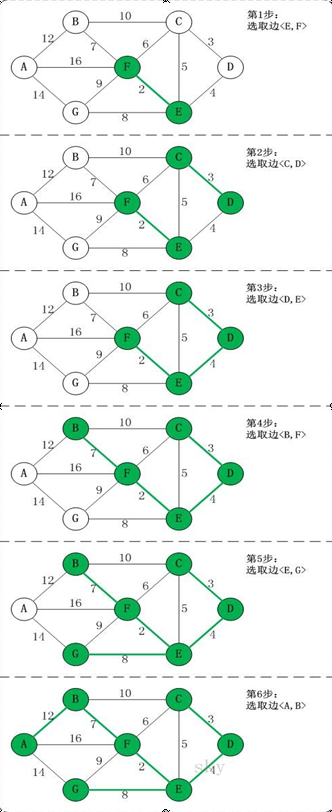
Kruskal算法是最小生成树的另一种经典算法。它的基本思想是:
将图中的所有边按权值从小到大排序。选取权值最小的边,只要该边不形成环,就将其添加到最小生成树中。重复该步骤,直到最小生成树包含了图中所有节点。
Kruskal算法的步骤如下:
- 对图中的所有边按权值从小到大进行排序。
- 选取权值最小的边,判断是否形成环。如果不形成环,就添加到最小生成树中。
- 重复步骤2,直到最小生成树包含了图中的所有顶点。
- 输出最小生成树。
Kruskal算法的时间复杂度为O(ElogE),其中E是图中的边数。
Kruskal算法的实现需要使用到并查集,来判断选取的边是否会形成环。并查集可以在O(1)时间内判断两个元素是否属于同一集合,这是实现Kruskal算法的关键。
与Prim算法相比,Kruskal算法适用于边数较多的稀疏图,因为其时间复杂度不依赖于节点数,仅与边数相关。但Kruskal算法需要提前对所有边进行排序,增加了空间复杂度。
图解:
并查集
并查集是一种树型的数据结构,用于处理一些不交集合的合并及查询问题。
它支持三种操作:
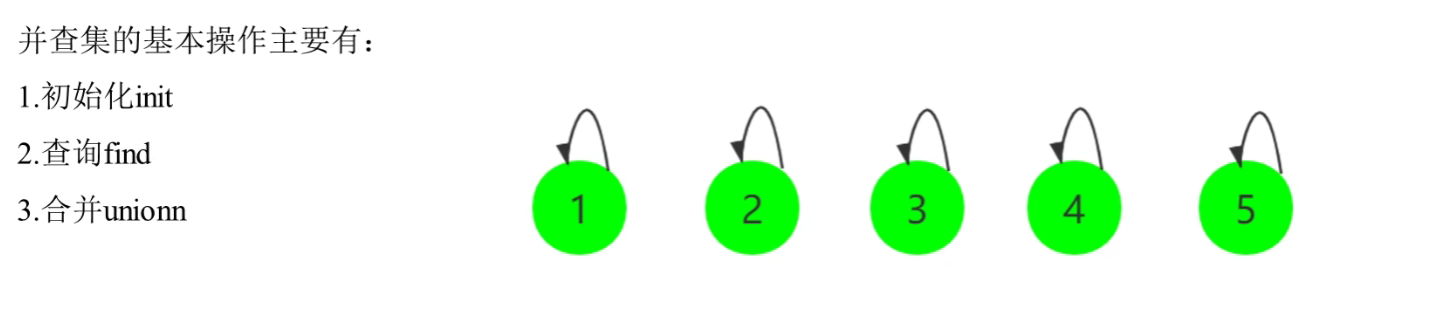
- 初始化init
union(x, y):合并元素x和元素y所在的集合。find(x):找到元素x所在的集合代表,该集合代表是该集合中最早加入的元素。
并查集实现了一种动态连通性,在初始时,每个元素自成一个集合,通过union操作不断合并集合,最后形成几个不相交的大集合。
并查集的典型应用是解决图论中的离线查询问题,比如在一个无向图中查询两个节点是否处于同一个连通图中。
并查集实现有两种常见方式:
- 快速查找:使用树结构,find操作需要遍历到根节点,时间复杂度为O(n)。
- 带路径压缩的快速合并:在find操作的遍历过程中,将节点直接指向根节点,实现路径压缩,降低树的深度。平衡之后,时间复杂度可以达到O(1)。

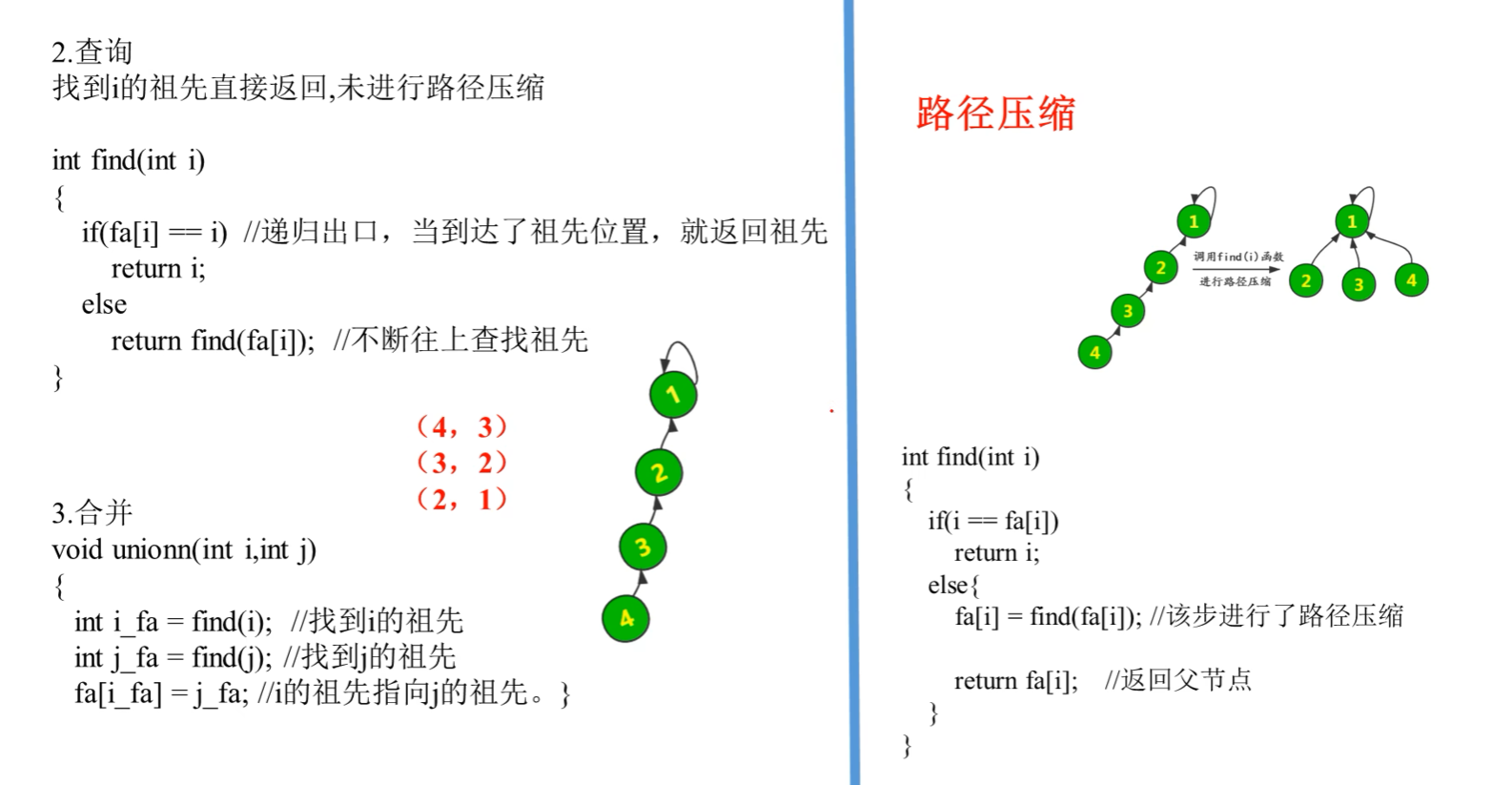
算法实践
import java.util.*;
public class KruskalAlgorithm {
private static class Edge implements Comparable<Edge> {
int u, v, w;
public Edge(int u, int v, int w) {
this.u = u;
this.v = v;
this.w = w;
}
@Override
public int compareTo(Edge o) {
return Integer.compare(this.w, o.w);
}
}
public static int kruskal(int[][] graph) {
int n = graph.length;
List<Edge> edges = new ArrayList<>();
for (int u = 0; u < n; u++) {
for (int v = u + 1; v < n; v++) {
if (graph[u][v] != 0) {
edges.add(new Edge(u, v, graph[u][v]));
}
}
}
Collections.sort(edges);
int[] parent = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
}
int res = 0;
for (Edge edge : edges) {
int u = edge.u;
int v = edge.v;
int w = edge.w;
int pu = find(parent, u);
int pv = find(parent, v);
if (pu != pv) {
parent[pu] = pv;
res += w;
}
}
return res;
}
private static int find(int[] parent, int x) {
if (parent[x] != x) {
parent[x] = find(parent, parent[x]);
}
return parent[x];
}
public static void main(String[] args) {
int[][] graph = new int[][]{
{0, 2, 0, 6, 0},
{2, 0, 3, 8, 5},
{0, 3, 0, 0, 7},
{6, 8, 0, 0, 9},
{0, 5, 7, 9, 0}
};
int res = kruskal(graph);
System.out.println(res);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
在这个实现中,我们首先将图中所有边存储在一个列表中,并按照权值从小到大进行排序。然后,我们初始化一个并查集,将每个节点的父节点初始化为它本身。
接下来,我们遍历排序后的边列表,对于每条边,如果它的两个端点不在同一个连通块中,就将它们合并到同一个连通块中,并将这条边的权值加入最小生成树的权值中。
这个实现的时间复杂度为O(m log m),其中m是边数。
最短路径算法
图论最短距离(Shortest Path)算法动画演示-Dijkstra(迪杰斯特拉)和Floyd(弗洛伊德)
迪杰斯特拉(Dijkstra)算法
迪杰斯特拉(Dijkstra)算法是典型最短路径算法,用于计算一个结点到其他结点的最短路径。它的主要特点是以起始点为中心向外层层扩展(广度优先搜索思想),直到扩展到终点为止。
Dijkstra算法是一种求解单源最短路径的算法。它的基本思想是:
- 选定一个节点作为起始节点,计算从起始节点到其它节点的最短路径。
- 遍历起始节点可达的所有节点,更新最短路径。选择下一节点继续遍历,直到遍历完所有节点。
- 循环以上步骤,直到最后获得从起始节点到所有节点的最短路径。
Dijkstra算法的步骤如下:
- 选定起始节点source,并将其距离设为0,其它节点距离设为无穷大。
- 找出不在S集合且距离最小的节点u,其距离为dist[u]。
- 将u加入S集合,表示u已经被访问。
- 以u为中间节点,更新与其相邻的节点v的距离。dist[v] = min(dist[v], dist[u] + weight(u, v))。
- 重复步骤2、3和4,直到S包含全部节点。
- 输出各节点最短路径和距离。
Dijkstra算法使用一个数组dist记录各节点最短路径长度,使用小根堆优先队列找出距离最小的节点。时空复杂度分别为O(nlogn)和O(n)。
算法实践
import java.util.*;
public class DijkstraAlgorithm {
private static final int INF = Integer.MAX_VALUE;
public static int[] dijkstra(int[][] graph, int start) {
int n = graph.length;
int[] dist = new int[n];
boolean[] visited = new boolean[n];
Arrays.fill(dist, INF);
dist[start] = 0;
for (int i = 0; i < n; i++) {
int u = -1;
for (int j = 0; j < n; j++) {
if (!visited[j] && (u == -1 || dist[j] < dist[u])) {
u = j;
}
}
visited[u] = true;
for (int v = 0; v < n; v++) {
if (!visited[v] && graph[u][v] != INF && dist[u] + graph[u][v] < dist[v]) {
dist[v] = dist[u] + graph[u][v];
}
}
}
return dist;
}
public static void main(String[] args) {
int[][] graph = new int[][]{
{0, 2, INF, 6, INF},
{2, 0, 3, 8, 5},
{INF, 3, 0, INF, 7},
{6, 8, INF, 0, 9},
{INF, 5, 7, 9, 0}
};
int start = 0;
int[] dist = dijkstra(graph, start);
System.out.println(Arrays.toString(dist));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
在这个实现中,我们首先初始化距离数组dist和访问标记数组visited,并将距离数组的所有元素初始化为无穷大(表示尚未访问到的节点)。然后,我们从起点开始遍历所有节点,每次选取距离数组中最小的值作为下一个要访问的节点。然后,我们将这个节点标记为已访问,并将其与尚未访问的节点的距离更新到距离数组中。最后,我们返回距离数组。
这个实现的时间复杂度为O(n^2),其中n是节点数。如果使用优先队列来优化,时间复杂度可以降为O(m log n),其中m是边数。
弗洛伊德(Floyd)算法
Floyd算法是一种求解所有节点对之间最短路径的算法。它的基本思想是:
通过递推的方式,求出从各个节点到其它所有节点的最短路径。
Floyd算法的步骤如下:
- 初始化dist数组,
dist[i][j]表示节点i到节点j的最短路径长度。当i==j时,dist[i][j] = 0;当节点i和节点j之间有直接路径时,dist[i][j]为该路径长度;否则dist[i][j] = ∞。 - 遍历每个中间节点k,更新dist数组:
dist[i][j] = min(dist[i][j], dist[i][k] + dist[k][j])
这意味着节点i到节点j的最短路径可能通过节点k。 - 重复步骤2,直到遍历完所有的中间节点。
- dist数组最后的结果即为各个节点对之间的最短路径长度。
Floyd算法的时间复杂度和空间复杂度均为O(n3),n为节点个数。
Floyd算法适用于求解任意两个节点之间的最短路径,可以解决有向图和带权图最短路径问题。
Dijkstra算法和Floyd算法都是用于求解最短路径问题的经典算法,但二者有以下几个主要区别:
- 适用图的类型:
- Dijkstra算法只能用于求有向图或无向图的单源最短路径,不能求任意两点之间的最短路径。
- Floyd算法可以用于求有向图或无向图任意两点之间的最短路径。
- 最短路径类型:
- Dijkstra算法求出一棵最短路径树,只能得到单源点到其他点的最短路径。
- Floyd算法一次求出全部节点之间的最短路径,得到一个最短路径矩阵。
- 时间复杂度:
- Dijkstra算法使用优先队列实现,时间复杂度为O(nlogn)。
- Floyd算法的时间复杂度为O(n3)。
- 当图的节点数很多但边数较少时,Dijkstra算法效率更高。当图的节点数和边数都很大时,Floyd算法更高效。
- 空间复杂度:
- Dijkstra算法只需要O(n)的空间。
- Floyd算法需要O(n2)的空间来存储最短路径矩阵。
- 是否需要中间节点:
- Dijkstra算法在更新最短路径时只考虑起点到终点的最短路径,不需要中间节点信息。
- Floyd算法在更新最短路径时需要中间节点信息,通过中间节点跳转才能更新最短路径。
算法实践
import java.util.*;
public class FloydAlgorithm {
private static final int INF = Integer.MAX_VALUE;
public static int[][] floyd(int[][] graph) {
int n = graph.length;
int[][] dist = new int[n][n];
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
dist[i][j] = graph[i][j];
}
}
for (int k = 0; k < n; k++) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if (dist[i][k] != INF && dist[k][j] != INF && dist[i][k] + dist[k][j] < dist[i][j]) {
dist[i][j] = dist[i][k] + dist[k][j];
}
}
}
}
return dist;
}
public static void main(String[] args) {
int[][] graph = new int[][]{
{0, 2, INF, 6, INF},
{2, 0, 3, INF, INF},
{INF, 3, 0, 4, INF},
{6, INF, 4, 0, 8},
{INF, INF, INF, 8, 0}
};
int[][] dist = floyd(graph);
for (int i = 0; i < dist.length; i++) {
System.out.println(Arrays.toString(dist[i]));
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
在这个实现中,我们首先将图中的邻接矩阵复制到距离矩阵中。然后,我们遍历所有节点对(i,j),尝试通过节点k来缩短(i,j)之间的距离。如果经过节点k可以缩短距离,则更新距离矩阵中的(i,j)元素。
这个实现的时间复杂度为O(n^3),其中n是节点数。


