
- 1综合评价指标权重方法汇总
- 2程序员转正述职报告/总结_员工述职表 前端开发工作不足怎么写
- 3Qt 三维柱状图 Q3DBar 和 三维条形图中的数据序列 QBar3DSeries_q3dbars 重
- 4git使用命令拉取、推送代码_git拉取代码并推送本地
- 5数独问题的解决办法_数独是一个我们都非常熟悉的经典游戏,运用计算机我们可以很快地解开数独难题,现在
- 6【Hadoop】分布式文件系统 HDFS_基于hadoop的分布式文件系统hdfs
- 72020.3 IDEA Gitee提交_idea git 提交gitee文件如何判断是否提交
- 8sanic + A-Frame / Three.js 构建虚拟现实VR场景_three.js虚拟场景
- 9动态规划题目汇总(持续更新)_动态规划算法题目
- 10用python计算圆周率
数据挖掘:特征工程——特征提取与选择_特征提取的目的
赞
踩
数据挖掘:特征工程——特征提取与选择
特征的处理和构建已经在上一篇特征处理和构建文章中有所总结。接来下对特征提取和选择进行说明。
注:特征提取的范围很大,一般理解的话,它提取的对象是原始数据,目的就是自动地构建新的特征,将原始数据转换为一组具有明显物理意义(比如几何特征、纹理特征)或者统计意义的特征。
一般常用的方法包括降维(PCA、ICA、LDA等)、图像方面的SIFT、Gabor、HOG等、文本方面的词袋模型、词嵌入模型等,这里简单介绍这几种方法的一些基本概念。
而本文章仅对结构性数据进行说明,因此,特征提取=特征降维。
一、什么是特征降维与特征选择?
一般经过特征处理和生成后,会产生大量的特征,而这些特征中有的特征是很重要的,但不是每一项特征都对模型有用,因此,要将这类没用的特征剔除掉。所以,特征提取(降维)与特征选择的主要目的就是为了剔除无用的特征。
之前一直有个疑惑,既然特征降维与特征选择都是为了剔除特征,那这两者之间有什么区别和联系?
二、特征降维与选择的区别和联系
特征提取与特征选择都是为了从原始特征中找出最有效的特征。
降维:本质上是从一个维度空间映射到另一个维度空间,特征的多少别没有减少,当然在映射的过程中特征值也会相应的变化。特征的多少并没有减少,只是换了个维度进行表示。强调通过特征转换的方式得到一组具有明显物理或统计意义的特征。
举例:现在的特征是1000维,我们想要把它降到500维。降维的过程就是找个一个从1000维映射到500维的映射关系。原始数据中的1000个特征,每一个都对应着降维后的500维空间中的一个值。假设原始特征中有个特征的值是9,那么降维后对应的值可能是3。
特征选择:就是单纯地从提取到的所有特征中选择部分特征作为训练集特征,特征在选择前和选择后不改变值,但是选择后的特征维数肯定比选择前小,毕竟我们只选择了其中的一部分特征。特征的多少发生了改变,选取最有利于模型的特征。是从特征集合中挑选一组具有明显物理或统计意义的特征子集。
举例:现在的特征是1000维,现在我们要从这1000个特征中选择500个,那个这500个特征的值就跟对应的原始特征中那500个特征值是完全一样的。对于另个500个没有被选择到的特征就直接抛弃了。假设原始特征中有个特征的值是9,那么特征选择选到这个特征后它的值还是9,并没有改变。
总结:两者都能帮助减少特征的维度、数据冗余,特征提取有时能发现更有意义的特征属性,特征选择的过程经常能表示出每个特征的重要性对于模型构建的重要性。可以先进行特征的提取,再从中选择更有效的特征。
特征降维
降维,降低数据特征的维度。
机器学习之降维方法总结
- 降维意义
维数灾难:在给定精度下,准确地对某些变量的函数进行估计,所需样本量会随着样本维数的增加而呈指数形式增长。降维可以消除。
降维的作用:- 降低时间复杂度和空间复
- 节省了提取不必要特征的开销
- 去掉数据集中夹杂的噪声
- 较简单的模型在小数据集上有更强的鲁棒性
- 当数据能有较少的特征进行解释,我们可以更好 的解释数据,使得我们可以提取知识。
- 实现数据可视化
举两个例子来说明降维的作用:
示例一:假如现在我们只有两个variables,为了了解这两者之间的关系,可以使用散点图将它们两者的关系画出:
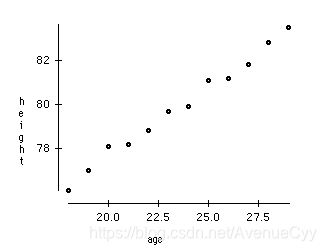
那如果我们有100variables时,如果我们要看每个变量之间的关系,那需要100(100-1)/2 = 5000个图,而且把它们分开来看也没什么意义?
示例二:假如我们现在有两个意义相似的variables——Kg (X1) and Pound (X2),如果两个变量都使用会存在共线性,所以在这种情况下只使用一个变量就行。可以将二维数据降维一维。
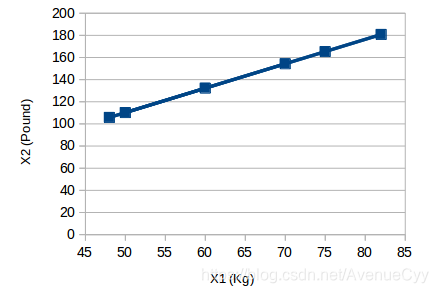
降维——机器学习笔记——降维(特征提取)
特征降维与选择的区别和联系
要找到k个新的维度的集合,这些维度是原来k个维度的组合,这个方法可以是监督的,也可以是非监督的,(PCA-非监督的,LDA(线性判别分析)-监督的),这两个都是线性投影来进行降为的方法。另外,因子分析,和多维标定(MDS)也是非监督的线性降为方法。
接下来按照线性和非线性降维方法进行说明。主要在sklearn.decomposition中。
三、线性降维方法
假设数据集采样来自高维空间的一个全局线性的子空间,即构成数据的各变量之间是独立无关的。通过特征的线性组合来降维,本质上是把数据投影到低维线性子空间。线性方法相对比较简单且容易计算,适用于具有全局线性结构的数据集。
3.1 主成分分析(PCA)
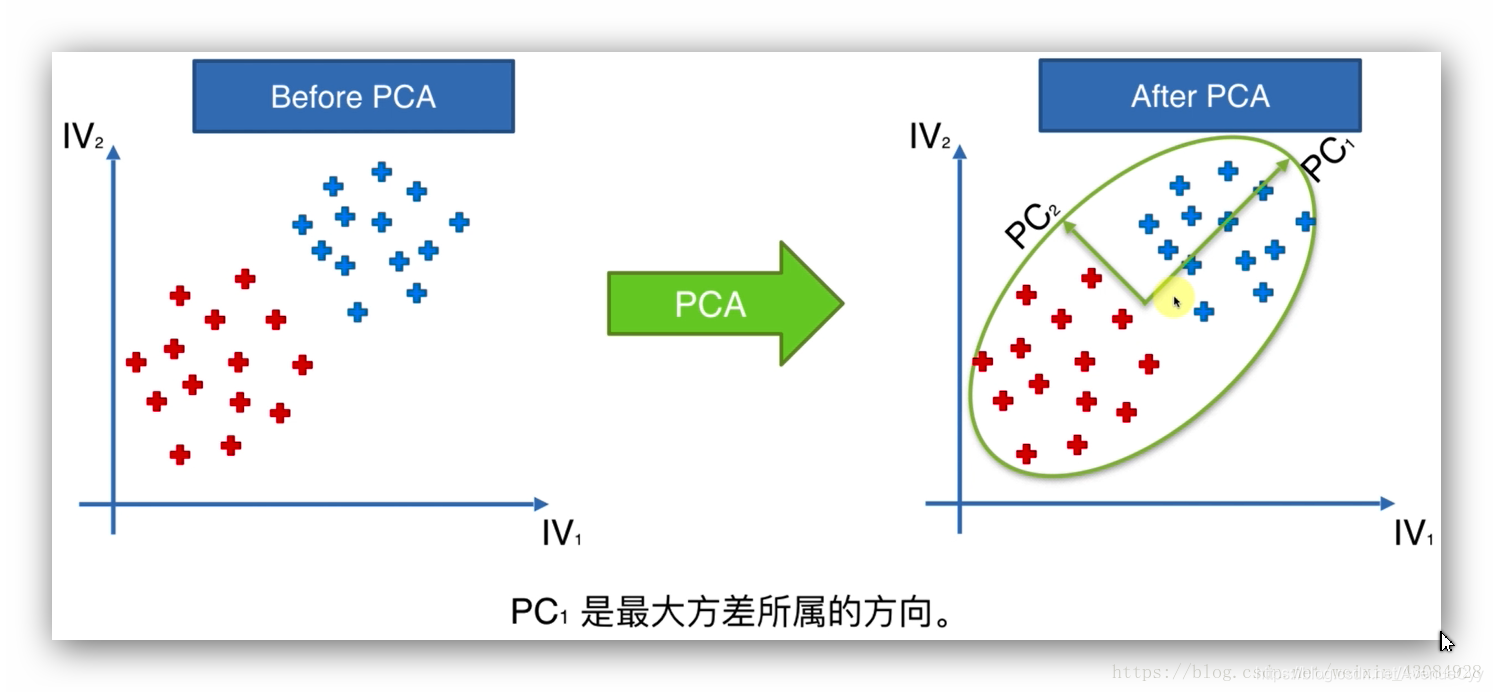
PCA方法是一种无监督学习方法,把原始n维数据x变换到一个新的坐标系统中,找到第一个坐标,数据集在该坐标的方差最大(方差最大也就是我们在这个数据维度上能更好的区分不同类型的数据),然后找到第二个坐标,该坐标与原来的坐标正交。该过程会一直重复,直到新坐标的数目与原来的特征个数相同,这时候我们会发现数据打大部分方差都在前面几个坐标上表示,这些新的维度就是我们所说的主成分。
只保留前k个主成分,这前k个主成分的方差是最大的,因此对模型的贡献最大。而抛弃的n-k个维度对于模型的影响很有限,这样我们就降低了运算量。
PCA工作其实是在寻找最大方差所属的方向。其中PCA中特征缩放是必须的,因为必须保证变量在同一个数量级,否则,数值大的贡献很大,导致我们可能忽略了数值小却很至关重要的特征。
基本思想:构造原变量的一系列线性组合形成几个综合指标,以去除数据的相关性,并使低维数据最大程度保持原始高维数据的方差信息。
PCA基本工作步骤:
- 将X记为包含了m个自变量的矩阵,对x进行特征缩放
- 计算x的方差矩阵,记作A
- 计算矩阵A的特征值和特征向量,对特征值进行自大到小排序
- 选择需要解释方差的百分比P,借此进行特征选择p个(这里的特征是我们提取到的,区别于m中的任意一个变量)

- 这里的p个特征就是我们留下的新特征了
主成分个数P的确定:
- 贡献率:第i个主成分的方差在全部方差中所占比重,反映第i个主成分所提取的总信息的份额。
- 累计贡献率:前k个主成分在全部方差中所占比重
主成分个数的确定:累计贡献率>0.85 - 相关系数矩阵or协方差阵?
当涉及变量的量纲不同或取值范围相差较大的指标时,应考虑从相关系数矩阵出发进行主成分分析;相关系数矩阵消除了量纲的影响。
对同度量或取值范围相差不大的数据,从协方差阵出发.
PCA讲解
from sklearn.preprocessing import StandardScaler ss = StandardScaler() x = ss.fit_transform(x) from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.25,random_state = 0) from sklearn.decomposition import PCA pca = PCA(n_components=None) #当为None时我们只是取p = m,并没有进行取舍,展示所有的结果。 x_train = pca.fit_transform(x_train) x_test = pca.transform(x_test) print('各个变量的解释方差能力:'+str(pca.explained_variance_)) #这个步骤会自动得出每个变量的解释方差的能力,并自大到小排序。方便我们进行取舍。 ---------------------------------------------------------------------- #假设我们的P设置为85%,则我们需要用到上述代码的结果的p个变量解释方差达到85%。这里就确定了p的取值。 pca = PCA(n_components=p) #这里的p时上个代码片得出的p x_train = pca.fit_transform(x_train) x_test = pca.transform(x_test)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3.2 线性判别分析(LDA)
LDA 是一种有监督学习算法,相比较 PCA,它考虑到数据的类别信息,而 PCA 没有考虑,只是将数据映射到方差比较大的方向上而已。
因为考虑数据类别信息,所以 LDA 的目的不仅仅是降维,还需要找到一个投影方向,使得投影后的样本尽可能按照原始类别分开,即寻找一个可以最大化类间距离以及最小化类内距离的方向。(通过将数据在低纬度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大)
LDA的算法步骤:
- 计算类内散度矩阵Sw
- 计算类间散度矩阵Sb
- 计算矩阵Sw^−1*Sb
- 计算Sw^−1*Sb的最大的d个特征值和对应的d个特征向量(w1,w2,…wd),得到投影矩阵W
- 对样本集中的每一个样本特征xi,转化为新的样本zi=WT*xi
- 得到输出样本集
- LDA 的优点如下:
- 相比较 PCA,LDA 更加擅长处理带有类别信息的数据;
- 线性模型对噪声的鲁棒性比较好,LDA 是一种有效的降维方法。
- 相应的,也有如下缺点:
- LDA 对数据的分布做出了很强的假设,比如每个类别数据都是高斯分布、各个类的协方差相等。这些假设在实际中不一定完全满足。
- LDA 模型简单,表达能力有一定局限性。但这可以通过引入核函数拓展 LDA 来处理分布比较复杂的数据。
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
lda = LinearDiscriminantAnalysis(n_components=2)
lda.fit(X,y)
X_new = lda.transform(X)
- 1
- 2
- 3
- 4
3.3 PCA和LDA之间的区别
LDA与PCA都是常用的降维方法,二者的区别在于:
- 出发思想不同。PCA主要是从特征的协方差角度,去找到比较好的投影方式,即选择样本点投影具有最大方差的方向( 在信号处理中认为信号具有较大的方差,噪声有较小的方差,信噪比就是信号与噪声的方差比,越大越好。);而LDA则更多的是考虑了分类标签信息,寻求投影后不同类别之间数据点距离更大化以及同一类别数据点距离最小化,即选择分类性能最好的方向。
- 学习模式不同。PCA属于无监督式学习,因此大多场景下只作为数据处理过程的一部分,需要与其他算法结合使用,例如将PCA与聚类、判别分析、回归分析等组合使用;LDA是一种监督式学习方法,本身除了可以降维外,还可以进行预测应用,因此既可以组合其他模型一起使用,也可以独立使用。
- 降维后可用维度数量不同。LDA降维后最多可生成C-1维子空间(分类标签数-1),因此LDA与原始维度N数量无关,只有数据标签分类数量有关;而PCA最多有n维度可用,即最大可以选择全部可用维度。
3.3 奇异值分解(SVD)
奇异值分解(SVD)原理详解及推导
SVD和PCA区别和联系
3.4 因子分析
因子分析是通过研究变量间的相关系数矩阵,把这些变量间错综复杂的关系归结成少数几个综合因子,并据此对变量进行分类的一种统计分析方法。由于归结出的因子个数少于原始变量的个数,但是它们又包含原始变量的信息,所以,这一分析过程也称为降维。
因子分析的主要目的有以下三个:
(1)探索结构:在变量之间存在高度相关性的时候我们希望用较少的因子来概括其信息;
(2)简化数据:把原始变量转化为因子得分后,使用因子得分进行其他分析,比如聚类分析、回归分析等;
(3)综合评价:通过每个因子得分计算出综合得分,对分析对象进行综合评价。
因子分析就是将原始变量转变为新的因子,这些因子之间的相关性较低,而因子内部的变量相关程度较高。
sklearn中的因子分析问题:
(1)sklearn.decompose.FactorAnalysis:sklearn可以做因子分析,但是只能做因子分析,不能旋转。不能旋转的因子分析对原始维度缺少一定的解释力,并且因子间可能存在一定的相关性,达不到因子分析的既定效果。
(2)factor_analyzer.FactorAnalyzer:既可做因子分析也能做因子的旋转,格式如下:FactorAnalyzer(rotation=None, n_factors=n, method=‘principal’)
因子分析相关概念
因子分析和PCA的区别
四、非线性降维方法
数据的各个属性间是强相关的
4.1 流形学习
流形是线性子空间的一种非线性推广,流形学习是一种非线性的维数约简方法
假设:高维数据位于或近似位于潜在的低维流行上
思想:保持高维数据与低维数据的某个“不变特征量”而找到低维特征表示
以不变特征量分为:
Isomap:测地距离
LLE:局部重构系数
LE:数据领域关系
4.2 等距特征映射(ISOMAP)
基本思想:通过保持高维数据的测地距离与低维数据的欧式距离的不变性来找到低维特征表示
测地距离:离得较近的点间的测地距离用欧氏距离代替;离得远的点间的测地距离用最短路径逼近
4.3 局部线性嵌入(LLE)
假设:采样数据所在的低维流形在局部是线性的,即每个采样点可以用它的近邻点线性表示
基本思想:通过保持高维数据与低维数据间的局部领域几何结构,局部重构系数来实现降维
各种降维方法的代码展示:降维方法 -简直太全!- 附Python代码(Random Forest、Factor Analysis、corr、PCA、ICA、IOSMA
五、特征选择
这两篇文章对特征选择的介绍比较完善,下面的内容也基本上是从这上面摘抄下来,整理的。
从给定的特征集合中选出相关特征子集的过程称为特征选择(feature selection)。其目的是
- 减少特征数量、降维,使模型泛化能力更强,减少过拟合;
- 增强对特征和特征值之间的理解。
特征选择放入思想:
确保不丢失重要的特征,否则就会因为缺少重要的信息而无法得到一个性能很好的模型。非重要特征指的是以下两种:
- 不相关特征,与当前学习任务无关的特征。
- 冗余特征,它们所包含的信息可以从其他特征中推演出来。冗余特征通常都不起作用,去除它们可以减轻模型训练的负担;但如果冗余特征恰好对应了完成学习任务所需要的某个中间概念,则它是有益的,可以降低学习任务的难度。
通常来说,从两个方面考虑来选择特征:
- 特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
- 特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。除移除低方差法外,本文介绍的其他方法均从相关性考虑。
在没有任何先验知识,即领域知识的前提下,要想从初始特征集合中选择一个包含所有重要信息的特征子集,唯一做法就是遍历所有可能的特征组合。但这种做法并不实际,也不可行,因为会遭遇组合爆炸,特征数量稍多就无法进行。
一个可选的方案是:产生一个候选子集,评价出它的好坏。基于评价结果产生下一个候选子集,再评价其好坏。这个过程持续进行下去,直至无法找到更好的后续子集为止。
这里有两个问题:如何根据评价结果获取下一个候选特征子集?如何评价候选特征子集的好坏?
-
子集获取:
给定特征集合 A={A1,A2,…,Ad} ,首先将每个特征看作一个候选子集(即每个子集中只有一个元素),然后对这 d 个候选子集进行评价。
假设 A2 最优,于是将 A2 作为第一轮的选定子集。
然后在上一轮的选定子集中加入一个特征,构成了包含两个特征的候选子集。
假定 A2,A5 最优,且优于 A2 ,于是将 A2,A5 作为第二轮的选定子集。
…
假定在第 k+1 轮时,本轮的最优的特征子集不如上一轮的最优的特征子集,则停止生成候选子集,并将上一轮选定的特征子集作为特征选择的结果。
这种逐渐增加相关特征的策略称作前向 forward搜索。类似地,如果从完整的特征集合开始,每次尝试去掉一个无关特征,这种逐渐减小特征的策略称作后向backward搜索。
也可以将前向和后向搜索结合起来,每一轮逐渐增加选定的相关特征(这些特征在后续迭代中确定不会被去除),同时减少无关特征,这样的策略被称作是双向bidirectional搜索。
该策略是贪心的,因为它们仅仅考虑了使本轮选定集最优。但是除非进行穷举搜索,否则这样的问题无法避免。 -
子集评价
给定数据集 D,假设所有属性均为离散型。对属性子集 A,假定根据其取值将 D 分成了 V 个子集,计算属性子集 A 的信息增益。信息增益越大,表明特征子集 A 包含的有助于分类的信息越多。所以对于每个候选特征子集,可以基于训练集 D 来计算其信息增益作为评价准则。
更一般地,

