
- 1【教程】Android系统手机 菜鸟扫盲汇总
- 2uniapp 的基础_uniapp在哪看下了什么依赖
- 3【JAVA】通过JAVA实现用户界面的登录_用户登录 java设计
- 4手把手教你搭建MongoDB分片式部署集群+实战_mongodb分片集群部署
- 5python小游戏————兔子_python小兔子代码
- 6Java基础知识解析:从入门到精通_java从入门到精通
- 7最全的 Charles 抓包工具详解
- 8BAT 批处理脚本教程_bat脚本编写教程菜鸟
- 9【自然语言处理】第3部分:识别文本中的个人身份信息_pipeline("ner", grouped_entities=true)的输出是什么
- 10ESP-12F模块使用指南
Jieba分词模式详解、词库的添加与删除、自定义词库失败的处理
赞
踩
Jieba(结巴)是一个中文分词第三方库,它可以帮助我们将一段中文文本分成一个个独立的词语。Jieba具有以下特点:
- 简单易用:Jieba提供了简洁的API接口,易于使用和扩展。可以快速地实现中文分词功能。
- 高效准确:Jieba采用了基于前缀词典和动态规划算法的分词方法,能够高效准确地处理各种中文文本。
- 支持多种分词模式:Jieba提供了三种分词模式:精确模式、全模式和搜索引擎模式,可以根据不同的应用场景选择合适的模式。
- 支持用户自定义词典:Jieba允许用户自定义词典,可以根据实际需要添加新的词语或调整已有词语的词频和词性等信息。
- 支持并发分词:Jieba采用多进程和协程的方式实现并发分词,可以提高分词速度和效率。
除了中文分词功能之外,Jieba还提供了关键词提取、词性标注、繁体转简体、词语拼音转换等功能。可以满足不同的中文文本处理需求。

1 Jieba的搜索模式
1.1 全模式
全模式会将需要分词的文本中所有可能的词语都进行匹配,因此会产生大量的冗余词语。使用Jieba的全模式,比如我们希望把美国数据仓库巨头发布开源模型,公开挑战ChatGPT这句话进行分词:
import jieba
text = '美国数据仓库巨头发布开源模型,公开挑战ChatGPT'
seg_list = jieba.cut(text, cut_all=True)
print("/".join(seg_list))
- 1
- 2
- 3
- 4
在上述代码中,cut_all=True指定了使用全模式进行分词,"/".join(seg_list)会将分词结果以斜杠分隔输出。这段的输出结果为:
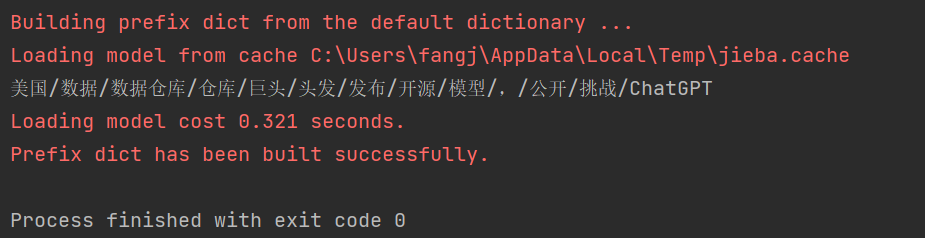
可以看到分词结果中,数据仓库被分为了数据、仓库、数据仓库三个独立的词语,因此会产生大量的冗余词语。全模式适合于对文本中所有可能的词语进行匹配的场景,例如搜索引擎的索引处理、关键词提取等。
1.2 精确模式
精确模式会将需要分词的文本中可能存在的词语都进行匹配,但不会产生冗余词语。使用Jieba的精确模式,可以通过以下方式实现:
import jieba
text = '美国数据仓库巨头发布开源模型,公开挑战ChatGPT'
seg_list = jieba.cut(text, cut_all=False)
print("/".join(seg_list))
- 1
- 2
- 3
- 4
在上述代码中,cut_all=False指定了使用精确模式进行分词。这段的输出结果为:
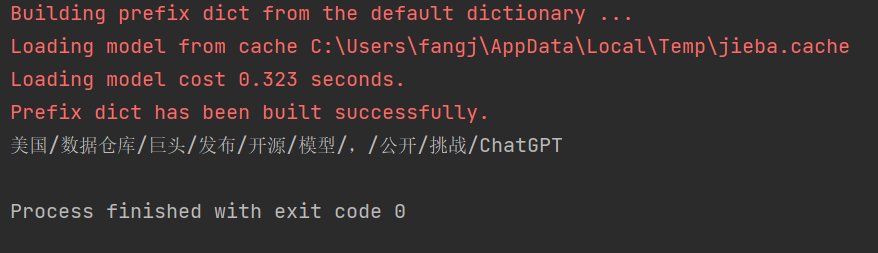
可以看到,在精确模式下,Jieba会将数据仓库作为一个词语进行匹配,不会产生冗余词语。精确模式适合于对文本中存在的词语进行匹配的场景,例如文本分类、情感分析等。精确模式不会产生冗余词语,因此可以得到准确的分词结果。
1.3 搜索引擎模式
搜索引擎模式使用了基于前缀匹配算法的正向最大匹配(FMM)和逆向最大匹配(RMM)算法,会对需要分词的文本进行分词,并且尽可能多地匹配分词结果。因此,在分词时,搜索引擎模式会优先匹配较长的词语。使用Jieba的搜索引擎模式,可以通过以下方式实现:
import jieba
text = '美国数据仓库巨头发布开源模型,公开挑战ChatGPT'
seg_list = jieba.cut_for_search(text)
print("/".join(seg_list))
- 1
- 2
- 3
- 4
这段函数的输出结果为;
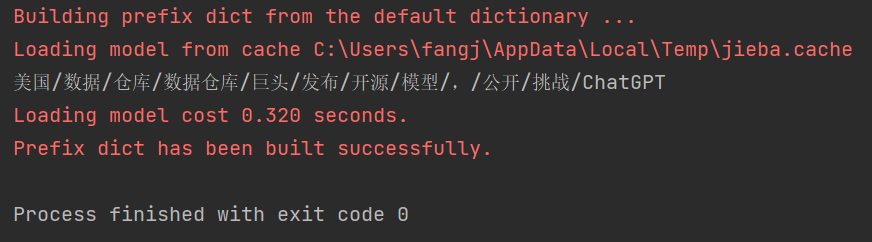
由于我们的实例文本过段,在这里的结果与全模式的分词结果并未表现出区别。搜索引擎模式适合于对长文本进行分词的场景,例如自然语言处理、信息检索等。搜索引擎模式使用了基于前缀匹配算法的正向最大匹配(FMM)和逆向最大匹配(RMM)算法,可以尽可能多地匹配分词结果,但可能会对一些新词造成误判,需要进行进一步的处理和校对。
1.4 分词结果的形式选择
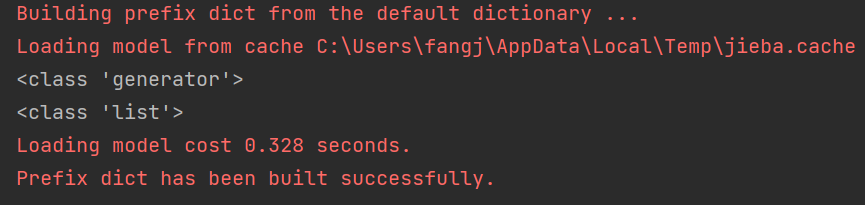
正常情况下,分词结果将会以生成器的形式保存,这意味着,当我们像上面一样将分词结果全部打印之后,这个生成器就不能二次使用了。
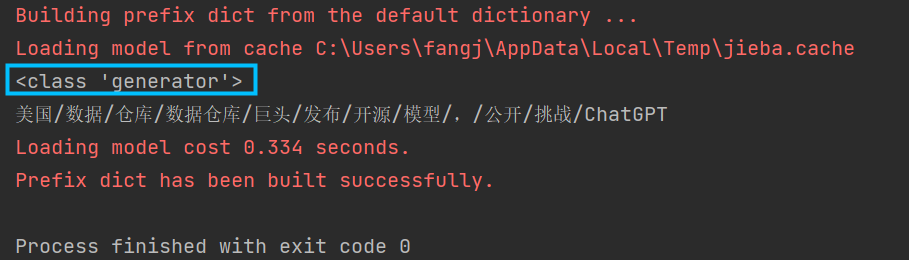
如果希望以列表的形式报错结果。可以将生成器转为list格式:
seg_list = jieba.cut(text)
print(type(seg_list))
seg_list = list(seg_list)
print(type(seg_list))
- 1
- 2
- 3
- 4
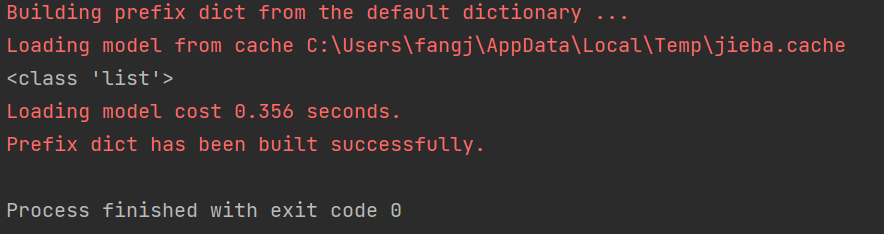
也可以直接指定函数的返回为list,此时我们需要使用函数lcut
seg_list = jieba.lcut(text)
print(type(seg_list))
- 1
- 2
2 词库的添加与删除
在Jieba中,词库是指用于分词的词典,Jieba提供了内置的词典和用户自定义的词典。用户可以通过添加或删除词语来定制自己的词典。
2.1 添加单个词语
在Jieba中,可以通过调用add_word(word, freq=None, tag=None)方法来向词库中添加单个词语。其中,word为需要添加的词语,freq为该词语的词频,tag为该词语的词性。
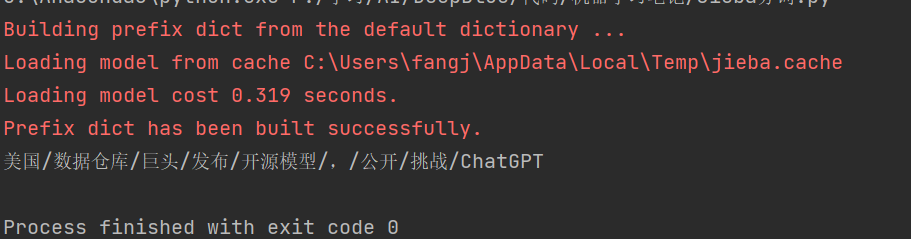
例如,假设需要将词语开源模型添加到Jieba的词库中,可以通过如下代码实现:
import jieba
text = '美国数据仓库巨头发布开源模型,公开挑战ChatGPT'
jieba.add_word("开源模型")
seg_list = jieba.cut(text)
print('/'.join(seg_list))
- 1
- 2
- 3
- 4
- 5
此时,开源模型就被分为一个词了:
2.2 添加自定义词典
当需要添加的词过多时,建议使用添加词典的方式。自定义词典可以包含用户自己添加的词语及其词频和词性等信息。
添加自定义词典的方法如下:
- 创建一个文本文件,例如
userdict.txt,用于存储自定义词典。每行格式为:词语 词频 词性。 - 将需要添加的词语及其词频和词性等信息写入到
userdict.txt中,每个词语一行。 - 调用Jieba的
load_userdict()方法加载自定义词典文件。
词典示例如下:
开源模型 10 n
深度学习 8 n
- 1
- 2
其中,10和8为词语的词频,n为词语的词性。之后调用词典即可。
jieba.load_userdict("userdict.txt")
- 1
词典加入之后,再次进行分词,词典中的内容就可以被分出来了。
2.3 词库的删除
在Jieba中,可以通过调用del_word(word)方法来删除词库中的单个词语。其中,word为需要删除的词语。刚刚我们在词典中添加了开源模型这个词,接下来我们将其删除:
jieba.del_word("开源模型")
seg_list = jieba.cut(text)
print('/'.join(seg_list))
- 1
- 2
- 3
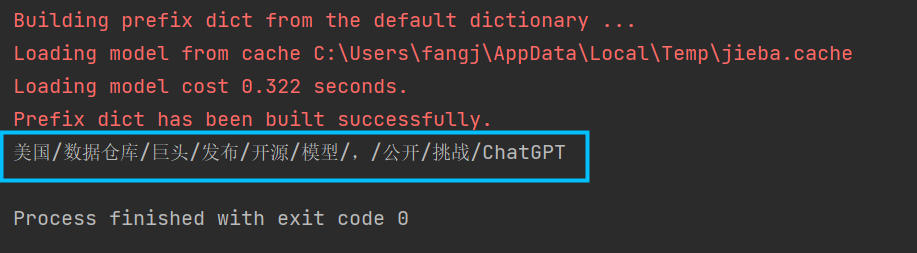
此时开源和模型就又变为两个词了。
3.4 添加词库失效的情况
如果想要添加的词包含标点符号,则这个添加操作会失效(无论是添加单个的词语还是使用自定义字典),比如:
import jieba
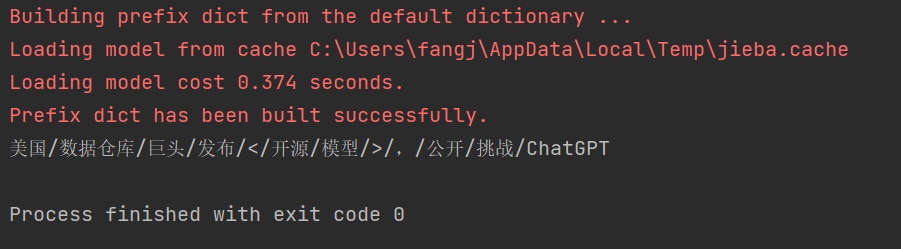
text = '美国数据仓库巨头发布<开源模型>,公开挑战ChatGPT'
jieba.add_word("<开源模型>")
seg_list = jieba.cut(text)
print('/'.join(seg_list))
- 1
- 2
- 3
- 4
- 5
这段代码希望将<开源模型>分为一个词,然而jieba默认标点符号会被单独分割,因此这个添加词库的操作会失效,不但<开源模型>不能被分出来,开源模型也不能被分出来。
因此,在添加词库时要避免这种情况的出现。

