
- 1[C++][算法基础]判定质数(试除法)
- 2银河麒麟V10 ARM架构部署docker_docker arm 安装
- 3mysql 非关系型数据库_关系型数据库和非关系型数据库的区别有哪些?
- 4波奇学Linux:ip协议
- 5git查看当前用户名密码并修改
- 6基于微信小程序的汽车租赁系统 源码免费获取 可做毕业设计参考_基于微信小程序的汽车租赁系统免费源码
- 722年最新Java笔记:day02-Java基础注释、关键词、标识符等(日更)_22年java
- 8二分查找的三种方法
- 9对于windows安装fabric的安装步骤_setupssh381-20040709.zip
- 10OpenHarmony实战开发-FaultLoggerd组件。
2022年认证杯SPSSPRO杯数学建模B题(第一阶段)唐宋诗的定量分析与比较研究求解全过程文档及程序_spsspro数学建模历年题
赞
踩
2022年认证杯SPSSPRO杯数学建模
B题 唐宋诗的定量分析与比较研究
原题再现:
唐诗和宋诗在文学风格上有较为明显的区别,这一点在古代文学研究中早有定论。所以唐诗和宋诗有时甚至会直接指代两类不同的诗作风格。历史学家缪钺在《论宋诗》一文中说:“唐诗以韵胜,故浑雅,而贵蕴藉空灵;宋诗以意胜,故精能,而贵深折透辟。唐诗之美在情辞,故丰腴;宋诗之美在气骨,故瘦劲。唐诗如芍药海棠,秾华繁采;宋诗如寒梅秋菊,幽韵冷香。……譬诸游山水,唐诗则如高峰远望,意气浩然;宋诗则如曲漳寻幽,情境冷峭。唐诗之弊为肤廓平滑,宋诗之弊为生涩枯淡。虽唐诗之中,亦有下开宋诗派者,宋诗之中,亦有酷肖唐人者;然论其大较,固如此矣。”在钱钟书的《谈艺录》中也谈到“诗分唐宋”的问题:“唐诗、宋诗,亦非仅朝代之别,乃体格性分之殊。天下有两种人,斯分两种诗。唐诗多以丰神情韵擅长,宋诗多以筋骨思理见胜。严仪卿首倡断代言诗,《沧浪诗话》即谓‘本朝人尚理,唐人尚意兴’云云。曰唐曰宋,特举大概而言,为称谓之便,非曰唐诗必出唐人,宋诗必出宋人也。故唐之少陵、昌黎、香山、东野,实唐人之开宋调者;宋之柯山、白石、九僧、四灵,则宋人之有唐音者。”他们的观点都认为唐诗和宋诗并非只有年代上的区分,而且在文学风格上也代表着完全不同的类型,甚至有个别唐朝诗人的诗作是宋诗的风格,而个别宋朝诗人的诗作更接近唐诗。
我们试图使用定量分析的手段来研究唐宋诗之差异。附件中包含了《全唐诗》收录的 5 万余首诗,《全宋诗》收录的约 26 万首诗。为了研究唐诗与宋诗在风格上的差异,请你建立合理的数学模型,研究如下问题:
第一阶段问题:
1. 请研究诗中出现的常见字(词),研究是否能够通过比较字(词)频上的差异来区分不同诗人的风格。请注意,由于诗的特殊格式限制,所以诗
作中的字词用法与散文或日常语言中可能会有不同。
2. 如果有一对字(词)在同一首诗中(或同一句中)同时出现,我们可以认为它们之间具有某种关联,以下将其称为字词关联。请统计不同时代的诗中的字词关联,并研究这项指标是否能够体现诗作时代的变化。
3. 请设计一个或多个有效的指标,来衡量唐诗和宋诗的风格差异。如果能给研究带来便利的话,我们也可以考虑选择唐代和宋代的某些风格强烈且时间距离较远的时期(例如初唐时期和南宋时期)的诗作来进行比较研究。
4. 请分别选出 50 首风格最具代表性的(并非文学成就最高的)唐诗和宋诗,并说明选择标准的合理性。
整体求解过程概述(摘要)
针对问题一,我们选择分词工具 jieba 对诗进行分词,并使用 Python 将诗词中的繁体字转化为简体字。我们在分词时采取了逐字切分为主、逐词切分为辅的处理方式,同时去掉了一些常见的虚词、代词、介词、语气词等无明显含义的字词。最后,唐诗和宋诗的常见字(词)分别为 210 个和 230 个。
在得到常见字后,运用 LDA 主题模型对所有的常见字(词)分为 8 类主题,然后统计每个诗人的诗在这些主题下的分布情况,使用 K-Means 聚类模型将唐朝诗人和宋朝诗人分为 5 种和 2 种风格,最后使用轮廓系数和 CH 分数对模型进行检验。
针对问题二,在检索字词关联时遵循两个原则:①两个常见字(词)只要在同一首诗中出现一次,则相应的字词关联频数就加 1;②若没有出现则频数记为 0。我们分别得到唐诗关联字词 107 个、宋诗关联字词 112 个。在得到字词关联后,运用 LDA 主题模型将唐诗和宋诗的字词关联分为 7 类和 5 类,然后统计各朝代的诗在这些主题下频数的分布情况。为了更直观准确地对比唐宋代的特色差异,我们将频数转化成了百分比并减去平均百分比,然后通过比较大小得到唐宋诗作的变化,具体结果请详见图 5-4。
针对问题三,我们基于 TF-IDF 算法生成新指标——关键字(词)。该指标同时兼顾了衡量诗的共性与个性。在得到关键字(词)后,运用 LDA 主题模型将唐诗和宋诗的关键字(词)分为 5 类和 4 类,然后统计各朝代的诗在这些主题下频数的分布情况。我们按照问题二的做法将频数进行转化、计算,并通过比较大小得到唐宋诗作的变化,变化情况请详见图 6-6。最后,我们将问题二、问题三的结果两两比较,认为关键字(词)可以衡量唐诗和宋诗的风格差异。
针对问题四,为了把唐代和宋代中最具风格的 50 首诗挑选出来,我们利用熵权法综合评价模型,把第三问得到的每首诗在不同主题下的关键字(词)频数的指标,作为风格的评价指标,得到每首诗风格显著程度的分数,按照从大到小排序后,选取前 50 首诗,唐诗的前三首依次是李白的《梦游天姥吟留别》、杜甫的《自京赴奉先县咏怀五百字》、杜甫的《茅屋为秋风所破歌》,具体见表 7-1,宋诗的前三首依次是苏轼的《题西林壁》、刘克庄的《归至武阳渡作》、邵雍的《寄谢三城太守韩子华舍人》,详细排名见表7-2。
模型假设:
1.假设所有字词在诗中等概率出现。
2.假设所有数据是真实准确的,不存在错别字。
3.假设虚词、代词、介词、语气词等无明显含义的字词无法构成具有重要含义的字词,可以直接剔除。
模型的建立与求解
问题分析
问题一分为两个步骤:一是检索常见字(词),二是根据字的字频差异来区分诗人的风格。针对第一个步骤,首先需要将附件中的诗句进行分词,由于唐诗和宋诗数目巨大、检索繁重,因此我们选择当前十分流行的分词工具 jieba 对诗进行分词;其次,我们发现部分诗词中存在繁体字,这会对文字识别产生干扰,进而影响分词效果,所以需要将其转化为简体字;最后,对于古汉语(文言文),尤其是诗的分词处理并不是看上去那么简单,因为单字词约占古汉语词汇统计信息的 80%以上,再加上古汉语微言大义,字字千钧,所以针对现代汉语的分词技术往往不适用于它。鉴于此种情况,我们在分词时采取了逐字切分为主、逐词切分为辅的处理方式。同时去掉了一些常见的虚词、代词、介词、语气词等无明显含义的字词。
在得到常见字后,第二个步骤的具体操作如下:第一,运用 LDA 主题模型将所有的常见字(词)分为 n 类;第二,使用 Python 统计每首诗中 n 类常见字(词)出现的频数,然后将同一诗人的诗进行加总,从而得到每个诗人的 n 类常见字(词)出现频数;第三,每个诗人的 n 类常见字(词)出现频数宛如诗人的 n 项“属性值”,因此我们可以据此应用 K-Means 聚类模型划分诗人的风格
本题具体分析流程如下:

常见字(词)的检索
本文在参考 README 文件以及熟悉掌握 json 文件中数据的格式及含义后,分别对唐诗、宋诗进行文本分析,运用 Python 中的 jieba 库对 57000 余首唐诗和 254000 余首宋诗进行分词,并统计每个字词出现的次数。为了使常见词的意义更加鲜明,我们对得到的字词进行了筛选,剔除了标点符号、介词、语气词以及代词等没有诗词意象的字词,部分被剔除的字词展示如下:
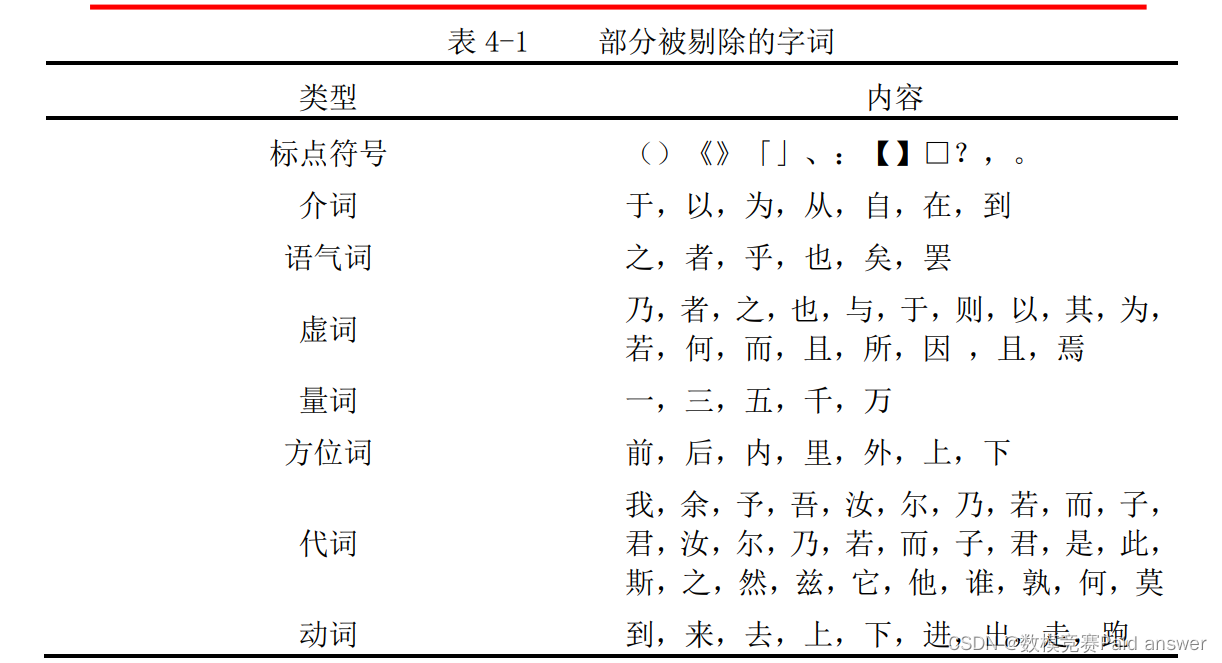
原始样本在经过分词处理和剔除无用字词后,得到了唐诗和宋诗的全部字词以及频数。在参考网上的有关文章[3]和相关文献[4]后,本文又根据唐诗和宋诗的样本量大小、字词总量以及字词频数的分布情况,决定唐诗选取频数大于等于 500 的字词作为常见字(词),共 210 个,其中出现最多的分别是月;宋诗选取频数大于等于 2000 的字词作为常见字(词),共 238 个,其中出现最多的分别是人。唐诗、宋诗的常见字(词)结果如下图所示:

基于 LDA 主题模型对常见字(词)分类
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型[5][6],也称为三层贝叶斯概率模型,是一种非监督机器学习技术,可以用来识别大规模文档集或语料库中潜藏的主题信息,包含词、主题和文档三层结构。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“文章以一定概率选择了某个主题,并从这个主题中以一定概率选择某个字词”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。
在 LDA 模型中,工作原理[7]如下所示:
Step1:对于每个文档,随机将每个字词初始化为
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

