
热门标签
热门文章
- 1Laravel Debug mode RCE(CVE-2021-3129)漏洞复现_/_ignition/execute-solution
- 2前端换肤的五种思路和优缺点_前端 换肤
- 3如何在Ubuntu 20.04上安装MongoDB_mongodb4.4.22
- 4Hadoop大数据概论
- 5Mac下,IntelliJ IDEA+maven+tomcat,实现页面前后端分离及页面跳转(web开发第二课)_idea怎么实现页面跳转
- 6Electron 小白介绍,你能看懂吗?_electron框架
- 7知乎热议 如何利用ChatGPT搞科研?_知乎 gpt科普
- 8CPU、GPU、TPU、NPU等到底是什么?_tpu和npu
- 9从零开始基于imagenet 1k数据集训练CNN分类模型_imagenet-1k
- 10各种中文乱码的解决方法 (转)
当前位置: article > 正文
Huggingface遇到OSError: We couldn‘t connect to ‘https://huggingface.co‘ to load this file解决方法_chat with rtx huggingface.co
作者:2023面试高手 | 2024-04-14 22:10:08
赞
踩
chat with rtx huggingface.co
遇到问题
在服务器上使用llama2的7b模型在自己数据集上进行微调,由于实验室的服务器不能上外网,加载模型的时候遇到问题
OSError: We couldn't connect to 'https://huggingface.co' to load this file,
couldn't find it in the cached files and it looks like meta-llama/Llama-2-7b-hf
is not the path to a directory containing a file named config.json.
Checkout your internet connection or see how to run the library in offline mode at
'https://huggingface.co/docs/transformers/installation#offline-mode'.
- 1
- 2
- 3
- 4
- 5
解决方法
第一步
自己前往要使用的模型的Huggingface主页:https://huggingface.co/meta-llama/Llama-2-7b-hf/tree/main,将里面的文件手动下载到本地,如下图所示:
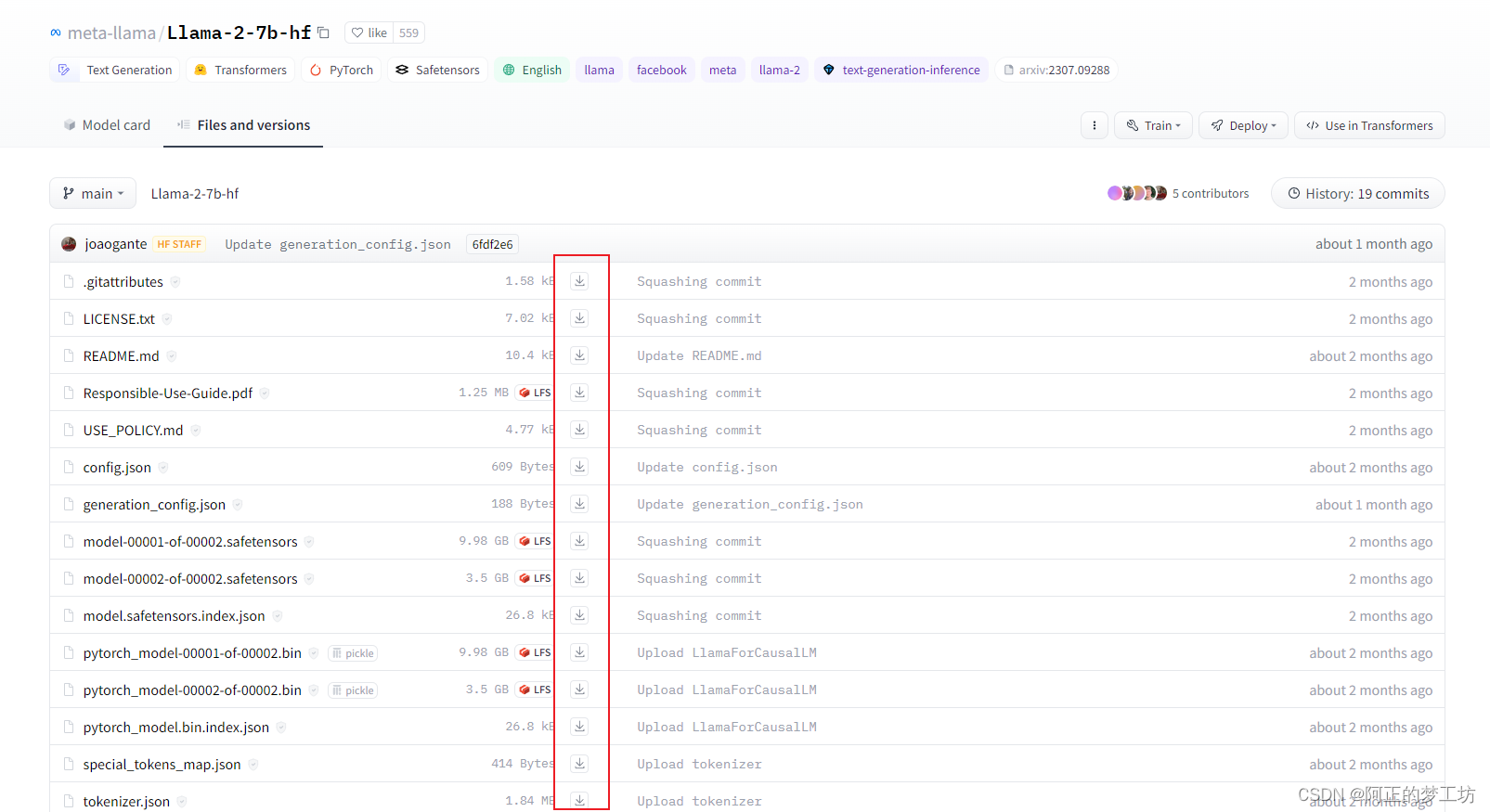
放到名为Llama-2-7b-chat-hf的文件夹下
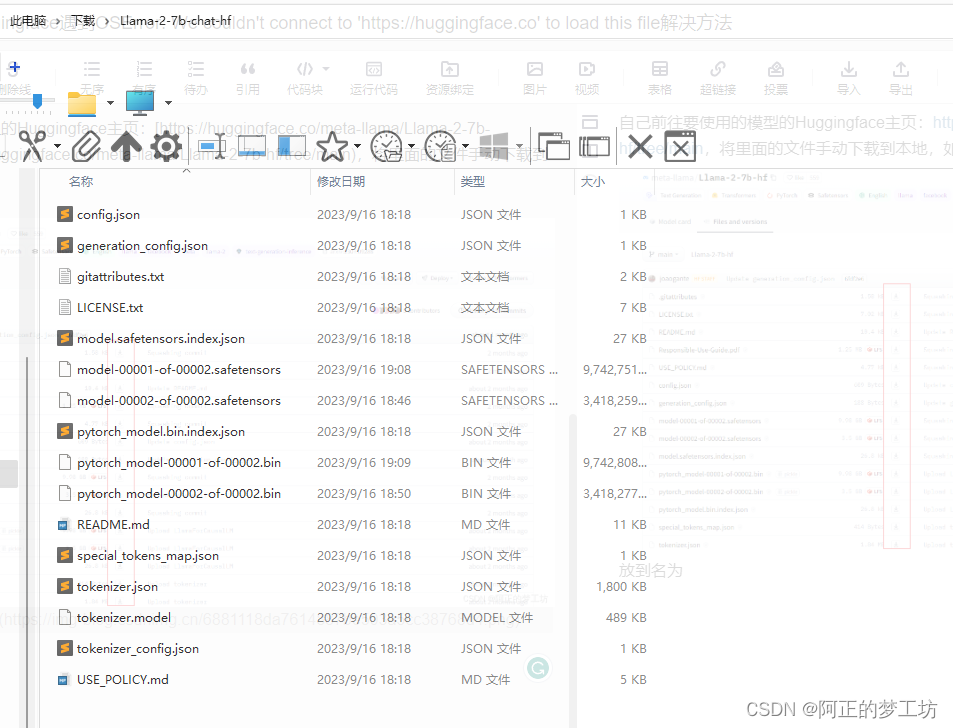
第二步
使用WinSCP(或者其他将文件上传到服务器的软件),上传到服务器,模型参数和代码放在同一目录

第三步
将代码中的from_pretrained中的MODEL_NAME更改为相对路径,如下代码所示
# MODEL_NAME = "meta-llama/Llama-2-7b-hf" MODEL_NAME = "./Llama-2-7b-chat-hf" def create_model_and_tokenizer(): bnb_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.float16, ) model = AutoModelForCausalLM.from_pretrained( MODEL_NAME, use_safetensors=True, quantization_config=bnb_config, trust_remote_code=True, device_map="auto", ) tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME) tokenizer.pad_token = tokenizer.eos_token tokenizer.padding_side = "right" return model, tokenizer

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
经过上述操作,便可以正常加载模型参数。
参考
[1] https://blog.csdn.net/weixin_42209440/article/details/129999962
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/424353
推荐阅读
相关标签

