
- 1【ros】vscode 断点调试 ROSnode
- 2java语言基础面试题(二)
- 3Uniapp 和Vue3 小程序 获取页面dom 方法_uniapp获取dom元素 vue3写法
- 4【脚本语言】windows下bat文件常用语法学习_window11 bat脚本编写
- 5Leetcode647.回文子串_尽可能多的回文子串
- 62020年阿里云基础认证(ACA - Alibaba Cloud Certification Associate)_alibaba cloud certification是什么
- 7OneNET物联网平台11 使用OneNET平台提供的API向设备发送命令_onent 发送命令connection: close
- 8安卓大作业:使用Android Studio开发天气预报APP(使用sqlite数据库)_安卓天气预报app代码
- 9备战金九银十,java中高级核心知识全面解析,让你吊打面试官
- 10大模型(大型语言模型,LLM)_大模型和大语言模型的关系
视觉大模型的全面解析_开源视觉大模型
赞
踩
前言
本文主要围绕Foundational Models,即基础模型(通过自监督或半监督方式在大规模数据上训练的模型,可以适应其它多个下游任务。)这个概念,向大家全面阐述一个崭新的视觉系统。例如,通过 SAM,我们可以轻松地通过点或框的提示来分割特定对象,而无需重新训练;通过指定图像或视频场景中感兴趣的区域,我们可以与模型进行多轮针对式的交互式对话;再如李飞飞团队最新展示的科研成果所示的那样,我们可以轻松地通过语言指令来操作机器人的行为。
具体地,我们将一起讨论一些典型的架构设计,这些设计结合了不同的模态信息,包括视觉、文本、音频;此外,我们还将着重讨论不同的训练目标,如对比式学习和生成式学习。随后,关于一些主流的预训练数据集、微调机制以及常见的提示模式,我们也将逐一介绍。
最后,希望通过今天的学习让大家对基础模型在计算机视觉领域的发展情况,特别是在大规模训练和不同任务之间的适应性方面的最新进展有一个大致的认知。共勉。废话不多说直接主题!
背景
近年来,基础模型取得了显著的成功,特别是通过大型语言模型(LLMs),主要归因于数据和模型规模的大幅扩展。例如,像GPT-3这样的十亿参数模型已成功用于零/少样本学习,而无需大量的任务特定数据或模型参数更新。与此同时,有5400亿参数的Pathways Language Model(PaLM)在许多领域展现了先进的能力,包括语言理解、生成、推理和与代码相关的任务。
反观视觉领域,诸如CLIP这样的预训练视觉语言模型在不同的下游视觉任务上展现了强大的零样本泛化性能。这些模型通常使用从网络收集的数百上千万图像-文本对进行训练,并提供具有泛化和迁移能力的表示。因此,只需通过简单的自然语言描述和提示,这些预训练的基础模型完全被应用到下游任务,例如使用精心设计的提示进行零样本分类。

除了此类大型视觉语言基础模型外,一些研究工作也致力于开发可以通过视觉输入提示的大型基础模型。例如,最近 META 推出的 SAM 能够执行与类别无关的分割,给定图像和视觉提示(如框、点或蒙版),指定要在图像中分割的内容。这样的模型可以轻松适应特定的下游任务,如医学图像分割、视频对象分割、机器人技术和遥感等。

当然,我们同样可以将多种模态一起串起来,组成更有意思的管道,如RAM+Grounding-DINO+SAM:

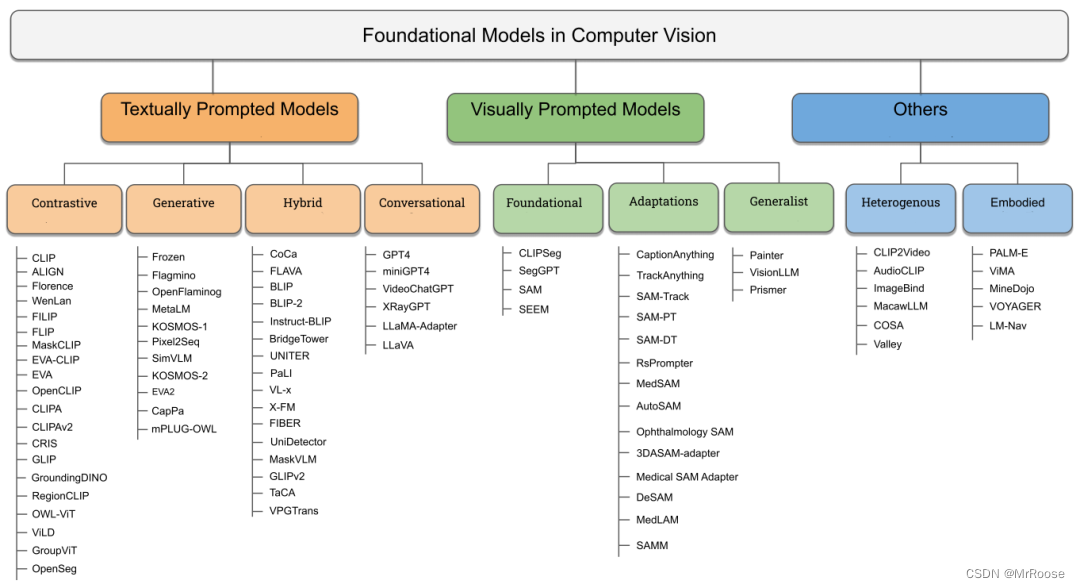
这里我们用 RAM 提取了图像的语义标签,再通过将标签输入到 Grounding-DINO 中进行开放世界检测,最后再通过将检测作为 SAM 的提示分割一切。目前视觉基础大模型可以粗略的归为三类:
1.textually prompted models, e.g., contrastive, generative, hybrid, and conversational;
2.visually prompted models, e.g., SAM, SegGPT;
3. heterogeneous modalities-based models, e.g., ImageBind, Valley.

基础架构

- 双编码器架构:其中,独立的编码器用于处理视觉和文本模态,这些编码器的输出随后通过目标函数进行优化。
- 融合架构:包括一个额外的融合编码器,它获取由视觉和文本编码器生成的表示,并学习融合表示。
- 编码器-解码器架构:由基于编码器-解码器的语言模型和视觉编码器共同组成。
- 自适应 LLM 架构:利用大型语言模型(LLM)作为其核心组件,并采用视觉编码器将图像转换为与 LLM 兼容的格式(模态对齐)。
目标函数
对比式学习
为了从无标签的图像-文本数据中学习,CLIP 中使用了简单的图像-文本对比(ITC)损失来通过学习正确的图像-文本配对来学习表示。此外还有图像-文本匹配(ITM)损失,以及包括简单对比式学习表示(SimCLR)和 ITC 损失的变体(如 FILIP Loss、TPC Loss、RWA、MITC、UniCL、RWC 损失)等其他对比损失。
L
v
2
t
=
−
log
[
exp
(
sin
(
v
i
,
t
i
)
/
τ
)
∑
j
=
1
N
exp
(
sin
(
v
i
,
t
j
)
/
τ
)
]
\mathcal{L}_{v2t}=-\log\bigg[\frac{\exp(\sin(v_i,t_i)/\tau)}{\sum_{j=1}^N\exp(\sin(v_i,t_j)/\tau)}\bigg]
Lv2t=−log[∑j=1Nexp(sin(vi,tj)/τ)exp(sin(vi,ti)/τ)]这里
τ
\tau
τ表示温度系数。因此我们可以将
ℓ
I
T
C
\ell _{ITC} \,
ℓITC简单表示为
1
N
∑
i
=
1
N
[
ℓ
v
2
t
+
ℓ
t
2
v
]
\frac1N\sum_{i=\mathbf{1}}^N[\ell_{v2t}+\ell_{t2v}]
N1∑i=1N[ℓv2t+ℓt2v]. 可以看出,本质上还是在计算图像与文本之间的相似度得分,比如常见的余弦相似性。
生成式学习
生成目标包括以下几种典型的损失:
- 掩码语言建模(MLM)损失
L M L M = − E x t ∼ D [ log p ( x t ∣ x ^ t ) ] \mathcal{L}_{\mathrm{MLM}}=-\mathbb{E}_{x^{t}\sim D}\big[\log p(x^{t}|\hat{x}^{t})\big] LMLM=−Ext∼D[logp(xt∣x^t)] - 语言建模(LM)损失
L L M = − E x t ∼ D [ ∑ l = 1 L log p ( x l t ∣ x < l t ) ] \mathcal{L}_{\mathrm{LM}}=-\mathbb{E}_{x^t\sim D}\bigg[\sum_{l=1}^{L}\log p(x_{l}^t|x_{<l}^t)\bigg] LLM=−Ext∼D[l=1∑Llogp(xlt∣x<lt)] - 标准字幕(Cap)损失
L C a p = − E x ∼ D ∑ l = 0 L log p ( x l t ∣ x < l t , x v ) \mathcal{L}_{\mathrm{Cap}}=-\mathbb{E}_{x\sim D}\sum_{l=0}^{L}\log p(x_{l}^{t}|x_{<l}^{t},x^{v}) LCap=−Ex∼Dl=0∑Llogp(xlt∣x<lt,xv)
以及 Flamingo Loss、Prefix Language Modeling, PrefixML 等。从上述公式我们也可以很容易看出,生成式 AI 本质还是条件概率模型,如 Cap 损失便是根据上一个已知 token 或 图像来预测下一个 token。
预训练
预训练数据集
如上所述,现代视觉-语言基础模型的核心是大规模数据,大致可分为几类:
- 图像-文本数据:例如CLIP使用的WebImageText等,这些数据通常从网络抓取,并经过过滤过程删除噪声、无用或有害的数据点。
- 部分伪标签数据:由于大规模训练数据在网络上不可用,收集这些数据也很昂贵,因此可以使用一个好的教师将图像-文本数据集转换为掩码-描述数据集,如GLIP和SA-1B等。
- 数据集组合:有些工作直接将基准视觉数据集组合使用,这些作品组合了具有图像-文本对的数据集,如字幕和视觉问题回答等。一些工作还使用了非图像-文本数据集,并使用基于模板的提示工程将标签转换为描述。
微调
微调主要用于三个基本设置:
- 提高模型在特定任务上的性能(例如开放世界物体检测,Grounding-DINO);
- 提高模型在某一特定能力上的性能(例如视觉定位);
- 指导调整模型以解决不同的下游视觉任务(例如InstructBLIP)。
首先,许多工作展示,即使只采用线性探测,也可以提高模型在特定任务上的性能。因此,特定任务的数据集(例如ImageNet)是可以用来改善预训练模型的特定任务性能。其次,一些工作已经利用预训练的视觉语言模型,通过在定位数据集上微调模型来进行定位任务。
例如,谷歌的一篇 OVD 工作 OWL-ViT,将 CLIP 预训练模型去掉 Token Pooling+projection 和 Image projection,加上一个新的 Linear Projection 作为分类头与文本进行匹配,学习出每个 Patch 的语义信息。此外在将 Patch 的表征经过 MLP head 回归出相应检测狂。通过 Patch 的语义特征与 BBox 的位置最终获得目标检测框。最后,像 InstructBLIP 则将视觉数据集转换为指导调整数据集,使视觉语言模型能够用于下游任务。

提示工程
提示工程主要是搭配大型语言模型(LLMs)一起使用,使它们能够完成某些特定的任务。在视觉语言模型或视觉提示模型的背景下,提示工程主要用于两个目的:
将视觉数据集转换为图像文本训练数据(例如,用于图像分类的 CLIP),为基础模型提供交互性
使用视觉语言模型进行视觉任务。
大多数视觉数据集由图像和相应文本标签组成。为了利用视觉语言模型处理视觉数据集,一些工作已经利用了基于模板的提示工程。在这种提示工程中,使用一组模板从标签生成描述。例如:
text_descriptions = [f"This is a photo of a {label}" for label in cifar100.classes]
text_tokens = clip.tokenize(text_descriptions).cuda()
- 1
- 2
这种额外的上下文有助于模型学习,因此,这些文本提示可以在训练或评估期间被 VLM 所使用。下面让我们一起了解下这三类视觉基础模型。

基于文本提示的基础模型
在本章节中,我们专注于探讨依赖文本作为主要监督来源的方法。这些文字提示模型大致分为三个主要类型,即基于不同的训练目标:对比学习、生成学习和混合方法。
基于对比学习的方法
首先,让我们一起回顾下 CLIP 架构及其衍生的变体:

此处我们集中探讨两类扩展方法,包括通用模型的对比方法和视觉定位基础模型的方法。
基于通用模型的对比方法


佛罗伦萨是微软、OpenAI 等联合提出的一个真正意义上的计算机视觉基础模型,能够处理不同的空间、时间和模态。它从CLIP样的预训练开始,然后扩展为具有三个不同适配器头的每个空间。弱弱的说一句,虽然这个模型的预训练参数只有 893M,但却需要在 512 块 A100 上训练 10 天的时间。

此外还有基于掩码对比学习的方法,这是一种通过遮挡输入像素来提高对比学习效率的有效方法。下面我们也将介绍几种典型方法。



通过重构 CLIP 特征来进行 MIM 操作。首先, CLIP 模型输入为完整的图像,而 EVA 模型的输入为有遮挡的图像,训练过程是让 EVA 模型遮挡部分的输出去重构 CLIP 模型对应位置的输出,从而以简单高效的方式让 EVA 模型同时拥有了最强语义学习 CLIP 的能力和最强几何结构学习 MIM 的能力。
很多的方法,总体而言,这些方法通过各种技术,如调整架构,改进对比目标,引入噪声鲁棒性,和探索多模态交互等,不断推动了 CLIP 及其变种的发展。这些努力已经展示了在许多任务上,包括零样本分类和图像-文本检索任务等方面,如何改善模型的性能,从而使这些模型在计算机视觉和自然语言处理的交叉领域中变得越来越重要。
基于视觉定位基础模型的方法

首先我们看下上图展示的结果,可以观察到,原始的 CLIP 模型其实是不擅长视觉定位任务的,特别是针对语义分割这种像素级定位任务来说。



Grounding DINO 是由沈向洋领导的 IDEA 实验室开源的,该方案利用了强大的预训练模型,并通过对比学习进行修改,以增强与语言的对齐。当然,像 OWL-ViT 也是类似的工作。此外, IDEA 还基于 SAM 等基础模型开源了一个集各大基础模型的仓库Grounded-Segment-Anything,仓库几乎涵盖了市面上主流的视觉基础模型。


最后,我们一起看下 OpenSeg 和 GroupViT,这些方法着重于分组机制和分割效果,以通过对比学习实现更好的语义分割和目标检测。值得关注的是,MetaAI 近期也开放了一篇最新的工作 ZeroSeg,无需借助文本信息便可以轻松实现高质量的分割效果
简单来说,以上讨论涵盖了一系列现代基础模型研究,这些方法试图通过对比学习、掩码学习、扩展和复现等技术来改进CLIP和其它基础模型。这些工作不仅推动了大规模图像-文本建模的前沿,还为诸如目标检测、语义分割等特定视觉任务的解决方案提供了新的方法和框架。
基于生成式的方法
基于生成式方法的视觉基础模型的总结涵盖了多个领域和方向,下面笔者简单归纳总结下。
首先是结合大语言模型(Large Language Model, LLM)的多模态学习范式:
- 结合上下文的多模态输入学习:例如 Frozen 方法将图像编码器与 LLM 结合,无需更新 LLM 的权重,而是在带有图像标注的数据集上训练视觉编码器。类似地,Flamingo 模型采用了固定的预训练视觉和语言模型,并通过Perceiver Resampler进行连接。
- 使用LLM作为其它模态的通用接口:如MetaLM模型采用半因果结构,将双向编码器通过连接层连接到解码器上,可实现多任务微调和指令调整零样本学习。此外,KOSMOS系列也在LLM上整合了多模态学习的能力。
- 开源版本的模型:如OpenFlamingo,是Flamingo模型的开源版本,训练于新的多模态数据集。
其次我们来看下视觉-语言对齐与定位相关的模型:
- 具备定位能力的模型:KOSMOS-2通过添加一条管线来抽取文本中的名词短语并将其与图像中的相应区域链接起来,进而实现视觉定位。
另外就是通用生成目标下的训练:
- 简化视觉语言建模:如SimVLM使用前缀语言建模(PrefixLM)目标进行训练,不需要任务特定的架构或训练,可在多个视觉语言任务上实现优秀的性能。
- 掩码重构与对齐:如MaskVLM,采用联合掩码重构语言建模,其中一个输入的掩码部分由另一个未掩码输入重构,有效对齐两个模态。
- 模块化视觉语言模型:如mPLUG-OWL,由图像编码器、图像抽象器和冻结LLM组成,通过两阶段的训练实现多模态对话和理解。
此外还有与对比学习的比较与结合:

总体而言,上述的方法和模型通过在视觉条件下训练语言生成任务,为 LLM 增添了“看世界”的能力。这些工作在视觉语言任务,如图像标注、多模态对话和理解等方面取得了显著进展,有的甚至在少样本情况下达到或超越了最先进的性能。通过将视觉和语言模态结合,这些模型为计算机视觉和自然语言处理的交叉领域提供了强大的新工具。
基于对比学习和生成式的混合方法
通用视觉-语言学习的基础模型:
- UNITER:结合了生成(例如掩码语言建模和掩码区域建模)和对比(例如图像文本匹配和单词区域对齐)目标的方法,适用于异构的视觉-语言任务。
- Pixel2Seqv2:将四个核心视觉任务统一为像素到序列的接口,使用编码器-解码器架构进行训练。
- Vision-Language:使用像 BART 或 T5 等预训练的编码器-解码器语言模型来学习不同的计算机视觉任务。
通用架构:

- Contrastive Captioner (CoCa):结合了对比损失和生成式的字幕损失,可以在多样的视觉数据集上表现良好。
- FLAVA:适用于单模态和多模态任务,通过一系列损失函数进行训练,以便在视觉、语言和视觉-语言任务上表现良好。
- BridgeTower:结合了不同层次的单模态解码器的信息,不影响执行单模态任务的能力。
- PaLI:一种共同扩展的多语言模块化语言-视觉模型,适用于单模态和多模态任务。
- X-FM:包括语言、视觉和融合编码器的新基础模型,通过组合目标和新技术进行训练。
BLIP 框架范式:
- BLIP:利用生成和理解能力有效利用图像文本数据集,采用Multimodal mixture of Encoder-Decoder (MED)架构。
- BLIP-2:通过查询转换器来实现计算效率高的模态间对齐。
指令感知特征提取和多模态任务解决方案:
- InstructBLIP:利用视觉编码器、Q-Former和LLM,通过指令感知的视觉特征提取来进行训练。 对预训练模型的高效利用:
- VPGTrans:提供了一种高效的方法来跨 LLM 传输视觉编码器。
- TaCA:提到了一种叫做 TaCA 的适配器,但没有进一步详细描述。

基于 Visual Grounding 的方法:
- ViLD: 这一方法使用了一个两阶段的开放词汇对象检测系统,从预训练的单词汇分类模型中提取知识。它包括一个 RPN 和一个类似于 CLIP 的视觉语言模型,使用 Mask-RCNN 创建对象提案,然后将知识提取到对象检测器中。
- UniDetector: 此方法旨在进行通用对象检测,以在开放世界中检测新的类别。它采用了三阶段训练方法,包括类似于上面我们提到的RegionCLIP的预训练、异构数据集训练以及用于新类别检测的概率校准。UniDetector 为大词汇和封闭词汇对象检测设立了新的标准。
- X-Decoder: 在三个粒度层次(图像级别、对象级别和像素级别)上运作,以利用任务协同作用。它基于 Mask2Former,采用多尺度图像特征和两组查询来解码分割掩码,从而促进各种任务。它在广泛的分割和视觉语言任务中展现出强大的可转移性。
这些方法共同探讨了视觉定位任务的不同维度,包括开放词汇对象检测、通用对象检测、两阶段训练、多级粒度和新颖的损失功能。它们共同通过以创新的方式整合视觉和语言来推动视觉理解的界限,往往超越了该领域以前的基准。
简单总结下,上面我们展示了如何通过对比和生成式学习,以及混合这些方法,来设计和训练可以处理各种视觉和语言任务的模型。有些模型主要关注提高单模态和多模态任务的性能,而有些模型关注如何高效地训练和利用预训练模型。总的来说,这些研究提供了视觉-语言融合研究的丰富视角和多样化方法,以满足不同的实际需求和应用场景。
基于对话式的视觉语言模型
这一块我们不做过多介绍,仅介绍比较有代表性的几个工作:

GPT-4:这是首个结合视觉和语言的模型,能够进行多模态对话。该模型基于Transformer架构,通过使用公开和私有数据集进行预训练,并通过人类反馈进行强化学习微调。根据公开的数据,GPT-4 在多个 NLP、视觉和视觉-语言任务上表现出色,但很可惜目前并未开源。

XrayGPT: 这个模型可以分析和回答有关 X 射线放射图的开放式问题。使用Vicuna LLM作为文本编码器和MedClip作为图像编码器,通过更新单个线性投影层来进行多模态对齐。
LLaVA: 这是一个开源的视觉指令调整框架和模型,由两个主要贡献组成:开发一种用于整理多模态指令跟踪数据的经济方法,以及开发一个大型多模态模型,该模型结合了预训练的语言模型LLaMA和CLIP的视觉编码器。

LLaMA-Adapter V2: 通过引入视觉专家,早期融合视觉知识,增加可学习参数等方式,改善了LLaMA的指令跟随能力,提高了在传统视觉-语言任务上的性能。
综上所述,基于对话的视觉语言模型在理解、推理和进行人类对话方面取得了显著进展。通过将视觉和语言结合在一起,这些模型不仅在传统 NLP 任务上表现出色,而且能够解释复杂的视觉场景,甚至能够与人类进行复杂的多模态对话。未来可能会有更多的工作致力于提高这些模型的可解释性、可用性和可访问性,以便在更广泛的应用领域中实现其潜力。
基于视觉提示的基础模型
这一块内容我们先为大家阐述几个代表性的基于视觉提示的基础模型,如 SAM 和 SEEM等;随后再介绍基于 SAM 的一系列改进和应用,例如用在医疗、遥感、视频追踪等领域;最后再简单介绍下几个通用的扩展。
视觉基础模型
CLIPSeg

- 概述:CLIPSeg 利用 CLIP 的泛化能力执行 zero-shot 和 one-shot 分割任务。
- 结构:由基于 CLIP 的图像和文本编码器以及具有 U-net 式跳跃连接的基于 Transformer 的解码器组成。
- 工作方式:视觉和文本查询通过相应的 CLIP 编码器获取嵌入,然后馈送到 CLIPSeg 解码器。因此,CLIPSeg 可以基于任意提示在测试时生成图像分割。
SegGPT

SAM

- 概述:SAM 是一种零样本分割模型,从头开始训练,不依赖于 CLIP。
- 结构:使用图像和提示编码器对图像和视觉提示进行编码,然后在轻量级掩码解码器中组合以预测分割掩码。训练方法:通过三阶段的数据注释过程(辅助手动、半自动和全自动)训练。
SEEM

与 SAM 相比,SEEM 涵盖了更广泛的交互和语义层面。例如,SAM 只支持有限的交互类型,如点和框,而由于它本身不输出语义标签,因此错过了高语义任务。
首先,SEEM 有一个统一的提示编码器,将所有视觉和语言提示编码到联合表示空间中。因此,SEEM 可以支持更通用的用途。它有潜力扩展到自定义提示。其次,SEEM 在文本掩码(基础分割)方面非常有效,并输出语义感知预测。
SAM 的改进与应用
SAM for Medical Segmentation

Medical SAM 总览
- Adapting by Fine-Tuning
MedSAM:通过在大规模医学分割数据集上微调 SAM,创建了一个用于通用医学图像分割的扩展方法 MedSAM。这一方法在 21 个 3D 分割任务和 9 个 2D 分割任务上优于 SAM。

paper: https://arxiv.org/pdf/2304.12306.pdf
github: https://github.com/bowang-lab/MedSAM
- Adapting through Auxiliary Prompt Encoder
AutoSAM:为SAM的提示生成了一个完全自动化的解决方案,基于输入图像由AutoSAM辅助提示编码器网络生成替代提示。AutoSAM 与原始的 SAM 相比具有更少的可训练参数。

- Adapting Through Adapters


3DSAM-adapter:为了适应3D空间信息,提出了一种修改图像编码器的方案,使原始的2D变换器能够适应体积输入。

Medical SAM Adapter:专为SAM设计了一个通用的医学图像分割适配器,能够适应医学数据的高维度(3D)以及独特的视觉提示,如 point 和 box。
- Adapting by Modifying SAM’s Decoder

DeSAM:提出了将 SAM 的掩码解码器分成两个子任务:提示相关的 IoU 回归和提示不变的掩码学习。DeSAM 最小化了错误提示在“分割一切”模式下对SAM性能的降低。
- SAM as a Medical Annotator

MedLAM:提出了一个使用 SAM 的医学数据集注释过程,并引入了一个少量定位框架。MedLAM 显著减少了注释负担,自动识别整个待注释数据集的目标解剖区域。

Segment Any Medical Model, SAMM:这是一个结合了3D Slicer和SAM的医学图像分割工具,协助开发、评估和应用SAM。通过与3D Slicer的整合,研究人员可以使用先进的基础模型来分割医学图像。
总体来说,通过各种微调、适配和修改方法,SAM 已被成功适应了用于医学图像分割的任务,涵盖了从器官、病变到组织的不同医学图像。这些方法也突出了将自然图像的深度学习技术迁移到医学领域的潜力和挑战。在未来,SAM 及其变体可能会继续推动医学图像分析领域的进展。
SAM for Tracking
SAM 在跟踪任务方面的应用集中在通过视频中的帧跟踪和分割任意对象,通常被称为视频对象分割(VOS)。这个任务涉及在一般场景中识别和追踪感兴趣的区域。以下总结下 SAM 在跟踪方面的一些主要应用和方法:
- Track Anything (TAM)

- 概述:TAM 使用 SAM 和现成的跟踪器 XMem 来分割和跟踪视频中的任何对象。
- 操作方式:用户可以简单地点击一个对象以初始化 SAM 并预测掩码。然后,XMem 使用 SAM提供的初始掩码预测在视频中基于时空对应关系跟踪对象。用户可以暂停跟踪过程并立即纠正任何错误。挑战:虽然表现良好,但 TAM 在零样本场景下不能有效保留 SAM 的原始性能。
- SAM-Track

概述:与 TAM 类似,SAM-Track 使用 DeAOT 与 SAM 结合。挑战:与 TAM 类似,SAM-Track 在零样本场景下也存在性能挑战。
- SAM-PT

- 概述:SAM-PT 通过结合 SAM 的稀疏点跟踪来解决视频分割问题。只需要第一帧的稀疏点注释来表示目标对象。
- 强项:在开放世界 UVO 基准测试中展示了对未见对象的泛化能力。
- 操作方式:使用像 PIPS 这样的先进点跟踪器,SAM-PT 为视频分割提供稀疏点轨迹预测。进一步地,为了区分目标对象及其背景,SAM-PT 同时跟踪正点和负点。
- SAM-DA

- 概述:SAM-DA 是另一种使用 SAM 自动分割能力进行跟踪的方法。
- 具体应用:通过使用 SAM 自动分割功能从每个夜间图像自动确定大量高质量目标域训练样本,从而跟踪夜间无人机(UAVs)。
SAM 在视频对象跟踪和分割方面的应用表明了其作为分割基础模型的潜力。尽管有一些挑战,特别是在未见数据和零样本场景下,但通过与现成的跟踪器的结合以及稀疏点跟踪的使用,SAM 能够实现在视频中跟踪和分割对象。这些方法为计算机视觉社区提供了一个实现通用场景中任意对象跟踪的有力工具,有助于推动视频分析和监控等领域的进展。
SAM for Remote Sensing
SAM 在遥感图像分割方面的应用集中在通过点、框和粗粒度掩码的引导来理解和分割遥感图像。以下是 SAM 在遥感分割方面的应用以及相关挑战。
SAM在遥感分割的基本应用
- 交互性质:由于 SAM 的交互特性,它主要依赖于点、框和粗粒度掩码的手动引导。
- 限制:
- 全自动分割困难:SAM在完全自动地理解遥感图像方面效果不佳。
- 结果依赖性:SAM的结果严重依赖于用于分割遥感图像目标的提示的类型、位置和数量。
- 手动提示优化需求:要实现理想的结果,通常需要对手动提示进行精炼。

概述:RsPrompter 是一个将语义分类信息与 SAM 结合的方法,用于遥感图像的自动实例分割。
操作方式:学习生成提示:RsPrompter 提出了一种学习生成适当的SAM输入提示的方法。
生成提示包含的信息:通过分析编码器的中间层来生成包含关于语义类别的信息的提示,并生成提示嵌入,这可以视为点或框嵌入。 目标:通过自动化生成适当的输入提示,RsPrompter 试图克服 SAM 在遥感图像分割方面的局限性。
尽管 SAM 在遥感图像分割方面存在一些限制,主要与其交互性质和对手动引导的依赖有关,但通过引入如 RsPrompter 这样的方法,可以利用 SAM 实现遥感图像的自动实例分割。这些努力标志着朝着减少人工干预和提高遥感图像分析自动化的方向迈出的重要一步,有势必推动遥感科学、地理信息系统(GIS)和环境监测等领域的进展。
SAM for Captioning
SAM 与大型语言模型如 ChatGPT 的组合在可控图像字幕(controlled image captioning)方面开辟了新的应用领域。下面概述下这种组合在图像字幕上的具体应用。
先给大家介绍下概念,可控图像字幕使用自然语言来根据人类目标解释图像,例如检查图像的某些区域或以特定方式描述图像。然而,这种交互式图像字幕系统的可扩展性和可用性受到缺乏良好注释的多模态数据的限制。一个典型的案例便是 Caption AnyThing,下面一起看看。

概述:Caption AnyThing 是一种零样本图像字幕模型,通过与 SAM 和大型语言模型(例如ChatGPT)结合,使用预训练的图像字幕器实现。
工作流程:
- 定义视觉控制:用户可以通过视觉提示定义视觉控制。
- 使用SAM转换为掩码:视觉提示随后使用SAM转换为掩码,以选择感兴趣的区域。
- 预测原始字幕:基于原始图像和提供的掩码,图像字幕器预测原始字幕。
- 文本优化:使用大型语言模型(例如ChatGPT)的文本精炼器,根据用户的偏好定制语言风格,从而优化原始描述。
结果:用户可以通过控制视觉和语言方面,更精确地描述图像中的特定部分或属性。
优势和意义
- 用户自定义:通过允许用户定义视觉和语言控制,提供了高度定制的解释。
- 灵活性和准确性:通过结合视觉分割和自然语言处理,增强了描述的灵活性和准确性。
- 零样本学习:由于是零样本模型,因此可以在未经特定训练的新图像和场景上工作。
通过结合 SAM 的图像分割能力和大型语言模型如 ChatGPT 的自然语言处理能力,Caption AnyThing 为可控图像字幕开辟了新的可能性。这不仅增强了字幕的灵活性和准确性,还允许用户定制语言风格和焦点,从而促进了交互图像分析和解释的发展
SAM for Mobile Applications
这一节我们重点梳理下 SAM 的一些移动端应用,主要就是加速 SAM 的推理和提升 SAM 的分割质量。

FastSAM 基于 YOLOv8-seg 实现,它比 SAM 快50倍,且训练数据只有SAM的1/50,同时运行速度不受 point 输入数量的影响

MobileSAM:将原始 SAM 中的图像编码器 ViT-H 的知识蒸馏到一个轻量化的图像编码器中,该编码器可以自动与原始 SAM 中的 Mask 解码器兼容。训练可以在不到一天的时间内在单个 GPU 上完成,它比原始 SAM 小60多倍,但性能与原始 SAM 相当。

RefSAM:这是一种高效的端到端基于 SAM 的框架,用于指代视频对象分割(RVOS)。它使用了高效且轻量级的CrossModal MLP,将指代表达的文本特征转换为密集和稀疏的特征表示。

HQ-SAM: HQ-SAM 为了实现高质量的掩膜预测,将 HQ-Output Token(高质量输出标记)和全局-局部特征融合引入到SAM中。为了保持SAM的零样本能力,轻量级的 HQ-Output Token 复用了 SAM 的掩膜解码器,并生成了新的 MLP(多层感知器)层来执行与融合后的 HQ-Features(高质量特征)的逐点乘积。在训练期间,将预训练的 SAM 的模型参数固定,只有 HQ-SAM 中的少数可学习参数可以进行训练。
通才模型
这一类主要描述如何使用上下文学习快速适应具有不同提示和示例的各种任务。这里特别突出了几个被称为通才模型(Generalist Models)的模型,它们可以执行多个任务,甚至可以通过提示和少量特定于任务的示例来适应新任务。
Painter

工作方式:给定某个任务的输入和输出图像,输出图像的像素被遮挡。Painter 模型的目标是对 masked 的输出图像进行填充。
训练目标:这个简单的训练目标允许统一几个视觉任务,包括深度估计、人体关键点检测、语义分割、实例分割、图像去噪、图像去雨和图像增强。
推理流程:在训练后,Painter 可以使用与输入条件相同任务的输入/输出配对图像来确定在推理过程中执行哪个任务。
VisionLLM

工作方式:给定图像,VisionLLM 使用视觉模型学习图像特征;这些图像特征与例如“详细描述图像”的语言指令一起传递给语言引导的图像分词器。
任务解码器:图像分词器的输出连同语言指令被提供给一个开放式 LLM 为基础的任务解码器,旨在根据语言指令协调各种任务。
Prismer

特点:Prismer 利用各种预训练的领域专家,例如语义分割、对象、文本和边缘检测,表面法线和深度估计,来执行多个推理任务。
应用:例如图像字幕和视觉问题回答。
通才模型表示了一种通用的趋势,其中模型可以通过改变输入或少量特定于任务的训练来适应新的或多样化的任务。这些模型在解决问题时可以灵活地适应,克服了单一任务模型的限制。尤其是在输出表示在任务之间有很大差异的计算机视觉中,这一点变得尤为重要。通过简化训练目标和建立跨任务的框架,这些通才模型为未来计算机视觉任务的多功能性提供了新的机会。
综合性基础模型
基于异构架构的基础视觉模型
在这一部分,我们集中讨论不同的基础视觉模型,这些模型通过对齐多个成对的模态,如图像-文本、视频-音频或图像-深度等,来学习更有意义的表示。
CLIP 与异构模态的对齐

CLIP2Video:这一模型扩展了CLIP模型,使其适用于视频。通过引入时序一致性和提出的时序差异块(TDB)和时序对齐块(TAB),将图像-文本的CLIP模型的空间语义转移到视频-文本检索问题中。

AudioCLIP:这一模型扩展了CLIP,使其能够处理音频。AudioCLIP结合了ESResNeXt音频模型,并在训练后能够同时处理三种模态,并在环境声音分类任务中胜过先前方法。
学习共享表示的多模态模型

Image Bind:这一模型通过学习配对数据模态(如(视频,音频)或(图像,深度))的共同表示,包括多种模态。ImageBind 将大规模配对数据(图像,文本)与其他配对数据模态相结合,从而跨音频、深度、热和惯性测量单元(IMU)等四种模态扩展零样本能力。

MACAW-LLM:这是一种指令调谐的多模态 LLM(大型语言模型),整合了图像、视频、音频和文本等四种不同模态。通过模态模块、对齐模块和认知模块,MACAW-LLM 实现了各种模态的统一。
视频和长篇幅文本的处理

COSA:通过将图像-文本语料库动态转换为长篇幅视频段落样本来解决视频所需的时序上下文缺失问题。通过随机串联图像-文本训练样本,确保事件和句子的显式对应,从而创造了丰富的场景转换和减少视觉冗余。

Valley: 是另一个能够整合视频、图像和语言感知的多模态框架。通过使用简单的投影模块来桥接视频、图像和语言模态,并通过指令调谐流水线与多语言 LLM 进一步统一。
这一节主要强调了将不同的感知模态(如视觉、听觉和文字)结合到统一框架中的重要性。通过跨模态学习和对齐,这些模型不仅提高了特定任务的性能,还扩展了多种模态的零样本学习能力。此外,考虑到视觉和听觉之间的时序一致性也是重要的创新方向。通过强调如何整合这些不同的输入形式,本节揭示了深度学习在处理更复杂和多样化数据方面的潜力。
基于代理的基础视觉模型
基于代理的基础视觉模型将语言学习模型(LLMs)与现实世界的视觉和物理传感器模式相结合。这不仅涉及文字的理解,还涉及与现实世界的互动和操作,特别是在机器人操作和导航方面。
机器人操控

Palm-E:该模型将连续的传感器输入嵌入到 LLM 中,从而允许机器人进行基于语言的序列决策。通过变换器,LLM将图像和状态估计等输入嵌入到与语言标记相同的潜在空间,并以相同的方式处理它们。

ViMA:使用文本和视觉提示来表达一系列机器人操控任务,通过多模态提示来学习机器人操控。它还开发了一个包含600K专家轨迹的模拟基准测试,用于模仿学习。
持续学习者

MineDojo:为 Minecraft 中的开放任务提供了便利的API,并收集了丰富的 Minecraft 数据。它还使用这些数据为体现代理制定了新的学习算法。

VOYAGER:这是一种由 LLM 驱动的终身学习代理,设计用于在 Minecraft 中探索、磨练技能并不断发现新事物。它还通过组合较小的程序逐渐构建技能库,以减轻与其他持续学习方法相关的灾难性遗忘。
导航规划

LM-Nav:结合预训练的视觉和语言模型与目标控制器,从而在目标环境中进行长距离指导。通过使用视觉导航模型构建环境的“心理地图”,使用 GPT-3 解码自由形式的文本指示,并使用 CLIP将这些文本地标连接到拓扑图中,从而实现了这一目标。然后,它使用一种新的搜索算法找到了机器人的计划。
总体而言,基于代理的基础视觉模型突出了语言模型在现实世界任务中的潜力,如机器人操作、持续学习和复杂导航。它们不仅推动了机器人技术的进展,还为自然语言理解、多模态交互和现实世界应用开辟了新的研究方向。通过将预训练的大型语言模型与机器人技术和视觉导航相结合,基于代理的基础视觉模型能够解决现实世界中的复杂任务,展示了人工智能的跨学科整合和应用潜力。
总结
具有对多种模式(包括自然语言和视觉)基础理解的模型对于开发能有效感知和推理现实世界的AI系统至关重要。本文主要为大家概括了视觉和语言基础模型,重点关注了它们的架构类型、训练目标、下游任务适应性和提示设计。
-
多模态理解:我们提供了对文本提示、视觉提示和异构模态模型的系统分类。这些模型不仅涵盖了自然语言,还包括了视觉和其他感知模式的理解。
-
应用广泛性:这些模型在各种视觉任务中的应用非常广泛,包括零样本识别和定位能力、关于图像或视频的视觉对话、跨模态和医疗数据理解。
-
通用模型:视觉中的基础模型可以作为通用模型来解决多个任务。当与大型语言模型相结合时,它们促生了可以在复杂环境中持续学习和导航的基础实体代理。
整体而言,基础视觉和语言模型的研究不仅深入了解了各种架构和训练目标,还展示了这些模型在多个领域和应用中的潜力。通过集成文本、视觉和其他模态的理解,这些模型促进了机器人技术和现实世界任务的进展。然而,还需要进一步的研究来充分挖掘这些模型的潜力,并解决一些存在的挑战和局限性。

