
- 1web基础漏洞之CSRF(跨站请求伪造漏洞)_cookie session token配置导致的漏洞
- 2Vue+ Electron 开发的一个跨三端的应用(Taro开发多端应用)
- 3《阿里工程师的自我修养》笔记_阿里工程师文化的精髓
- 4Elasticsearch教程(二)java集成Elasticsearch
- 5Gartner发2017技术成熟度曲线,和愈发明显的技术“小真空期”
- 6常见web应用防护软件下载2021_web终端防护软件
- 7中间件几百万消息持续积压及小时,怎么处理?_线上生产出现消息积压怎么办
- 8利用Android studio设计一个计算器_android studio 计算器
- 9java毕业设计成品源码网站基于ssm的NBA球队|篮球管理系统[包运行成功]_java成品网站
- 10华为数通配置旁挂二层组网直接转发实验
R绘制柱形图及其变换(bar chart)_r语言柱形图变量名改变方向
赞
踩
我自己在用R做各种分析时有不少需要反复用到的基础功能,比如一些简单的统计呀,画一些简单的图如柱形图,箱形图等等,虽说具体实现的代码也不麻烦,但有一些细节如给箱形图加上显著性分组,将柱形图按照metadata合并或分面等事情还是不太想每次用的时候去找之前的代码。
索性将常用的各种函数整成了一个包:pcutils,
网址:https://github.com/Asa12138/pcutils
最近也成功将pcutils提交到CRAN了。将包提交到CRAN或Bioconductor也是一件有意思的事(有机会下次讲讲)。
但目前还是建议从github安装,包含的功能会多一些:
install.packages("devtools")
devtools::install_github('Asa12138/pcutils',dependencies=T)
- 1
- 2
当然,今天主要要来讲的是柱形图以及其各种变换形式图形的绘制。
Introduction
柱形图(Bar chart)是一种常用的数据可视化图表,用于展示离散类别数据的分布和比较不同类别之间的数量或频率关系。柱形图通过在水平或垂直轴上绘制矩形柱来表示数据。
在柱形图中,每个类别对应一个矩形柱,其高度表示该类别的数据量或频率。类别通常显示在水平轴上,而数量或频率则显示在垂直轴上。矩形柱的宽度通常是固定的,相互之间没有间隔,这样便于比较不同类别之间的差异。
柱形图常用于以下情况:
- 展示不同类别的数量或频率关系。
- 比较多个类别之间的数据。
- 强调特定类别的重要性或异常值。
之前强力推荐过的绘图教程网站:https://r-graph-gallery.com/ ,上面也提供了很多柱形图从基础到不断美化的画法:
再次建议大家在上面看看具体实现的代码。
Plot
Stackplot
因为常做的是微生物组等组学数据的分析,所以一般会用到两个表,一个是abundance table(行为基因名/物种名,列为样本名),另一个是metadata(行为样本名,列为各种实验分组或表型数据),
要做的柱形图也经常是堆积柱形图,用来看composition的情况。
我们都知道要用ggplot画图,一般都要把我们的表格从宽格式变为长格式,
具体的转换方法也有很多,我常用的是reshape2的melt,
但是柱形图太常用了,我便把格式转换和分组映射包含在了函数stackplot中,方便自己的每一次画图。
library(pcutils)
library(ggplot2)
#?stackplot
data(otutab)
#将species level表上升到class level
class=hebing(otutab,taxonomy$Class,1,"sum")
head(class)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
## NS1 NS2 NS3 NS4 NS5 NS6 WS1 WS2 WS3 WS4 WS5 WS6 CS1 CS2
## c__Acidobacteria_Gp10 0 10 2 12 0 0 15 0 27 0 36 11 30 0
## c__Acidobacteria_Gp11 9 0 15 0 7 8 21 0 2 0 5 10 1 12
## c__Acidobacteria_Gp17 8 12 3 4 7 0 11 4 0 12 9 9 11 14
## c__Acidobacteria_Gp25 11 18 2 0 3 0 0 0 2 5 9 5 3 0
## c__Acidobacteria_Gp3 13 0 10 0 12 18 16 14 14 0 20 12 8 5
## CS3 CS4 CS5 CS6
## c__Acidobacteria_Gp10 20 13 3 19
## c__Acidobacteria_Gp11 9 0 0 0
## c__Acidobacteria_Gp17 3 16 0 14
## c__Acidobacteria_Gp25 23 0 3 6
## c__Acidobacteria_Gp3 8 0 10 9
## [ reached 'max' / getOption("max.print") -- omitted 1 rows ]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
head(metadata)
- 1
## Id Group env1 env2 env3 env4 env5 env6
## NS1 NS1 NS 3.057248 10.23571 5.554576 8.084997 25.00795 -1.15456682
## NS2 NS2 NS 4.830219 11.13453 5.613455 8.556829 16.67690 0.81168745
## NS3 NS3 NS 3.753133 10.06232 5.582916 10.226572 21.68926 1.40733211
## NS4 NS4 NS 4.262264 10.84401 5.258419 9.002256 24.81046 1.47805320
## NS5 NS5 NS 2.476135 7.52584 6.255314 9.357587 19.70553 0.05813095
## NS6 NS6 NS 5.131004 10.82761 5.180966 8.141506 18.39021 -1.70032569
## lat long
## NS1 38.72412 118.2493
## NS2 38.31086 115.2322
## NS3 36.82439 118.1361
## NS4 37.59774 117.1563
## NS5 35.94188 118.9504
## NS6 37.68713 116.2984
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
#基础绘制,无分组信息,单纯展示每个样本Top7的相对丰度,Top7以外的自动归为Other
stackplot(class,legend_title ="Class")+scale_fill_manual(values =get_cols(10))
- 1
- 2
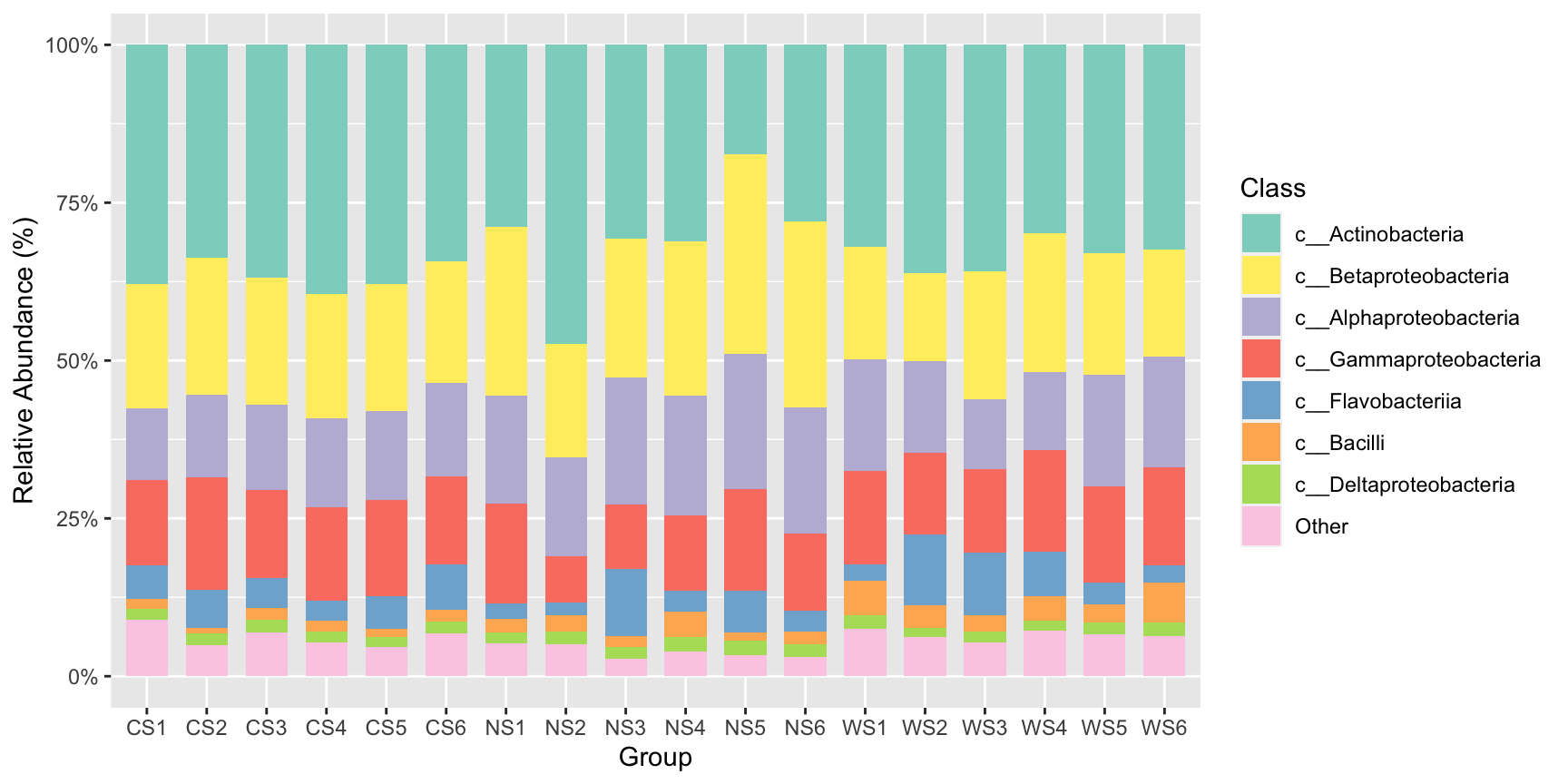
#按分组合并丰度值,展示合并后的相对丰度变化
stackplot(class, metadata, group = "Group",legend_title ="Class")+
scale_fill_manual(name="Class",values =get_cols(10))
- 1
- 2
- 3

#geom_bar可指定的参数可以传入bar_params中
stackplot(class, metadata, group = "Group",bar_params = list(position=position_dodge()),
legend_title ="Class")+
scale_fill_manual(values =get_cols(10))
- 1
- 2
- 3
- 4
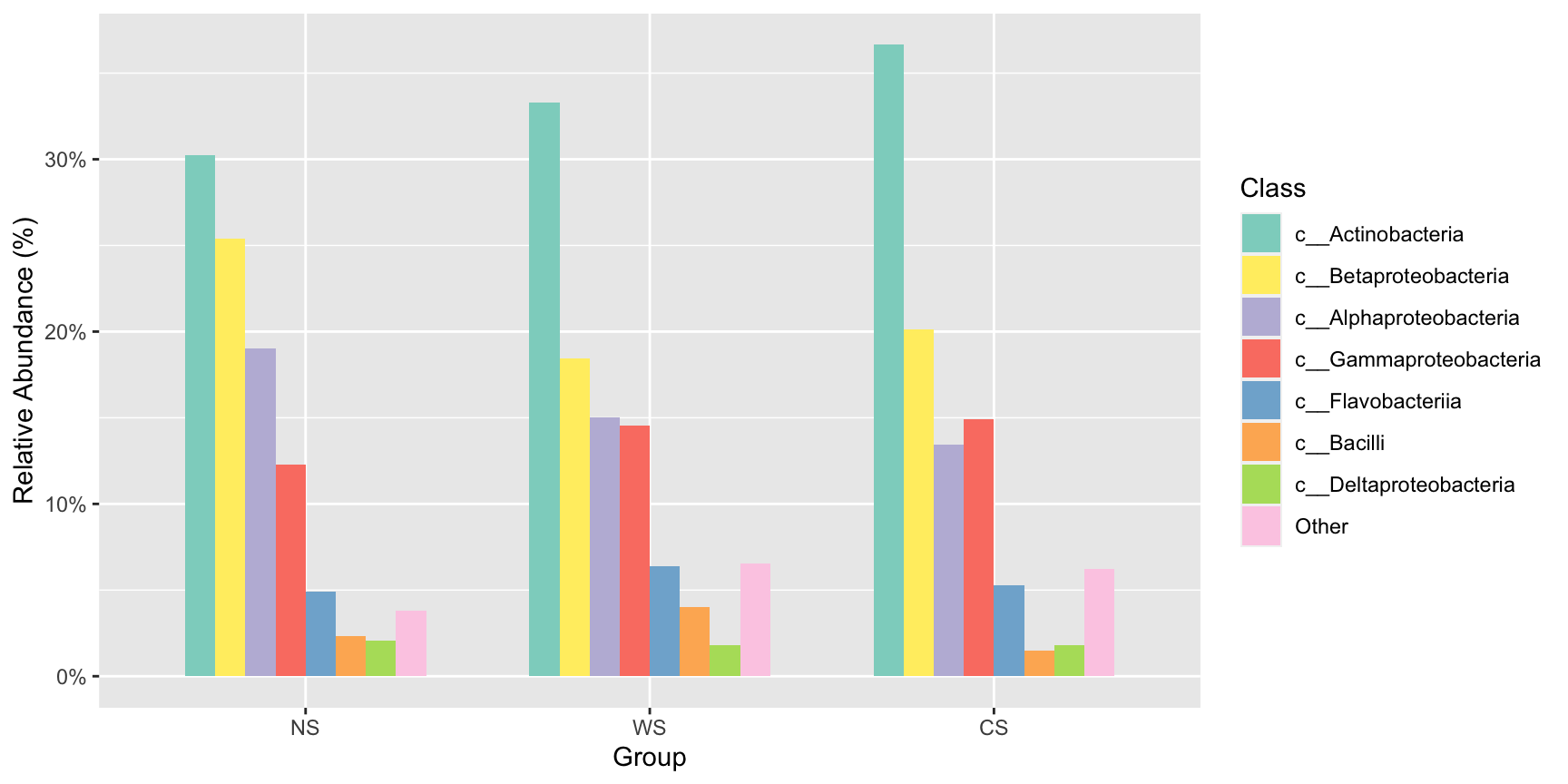
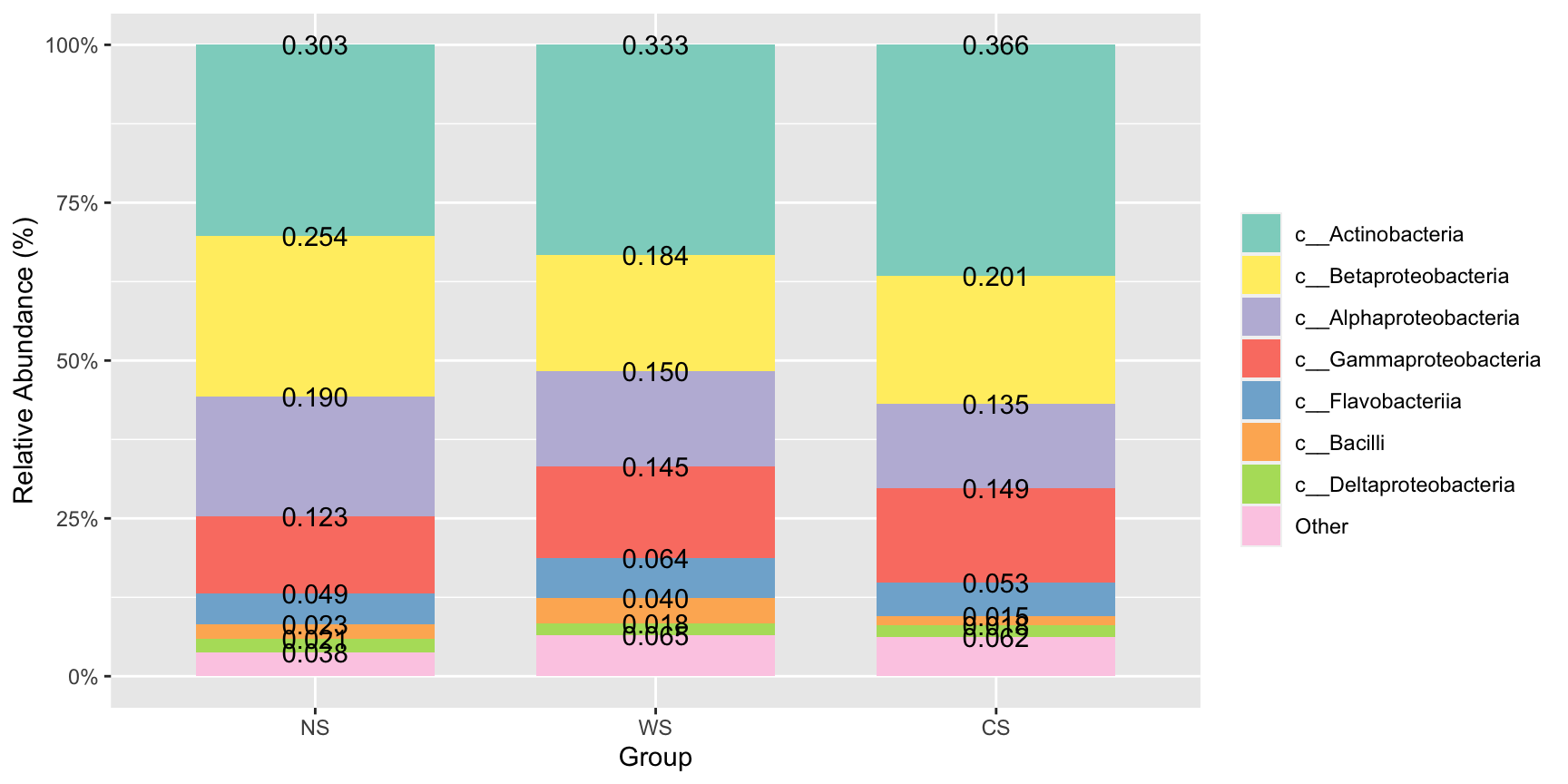
#展示每一个部分的数字?number = T
stackplot(class, metadata, group = "Group",number = T)+
scale_fill_manual(name="Class",values =get_cols(10))
- 1
- 2
- 3
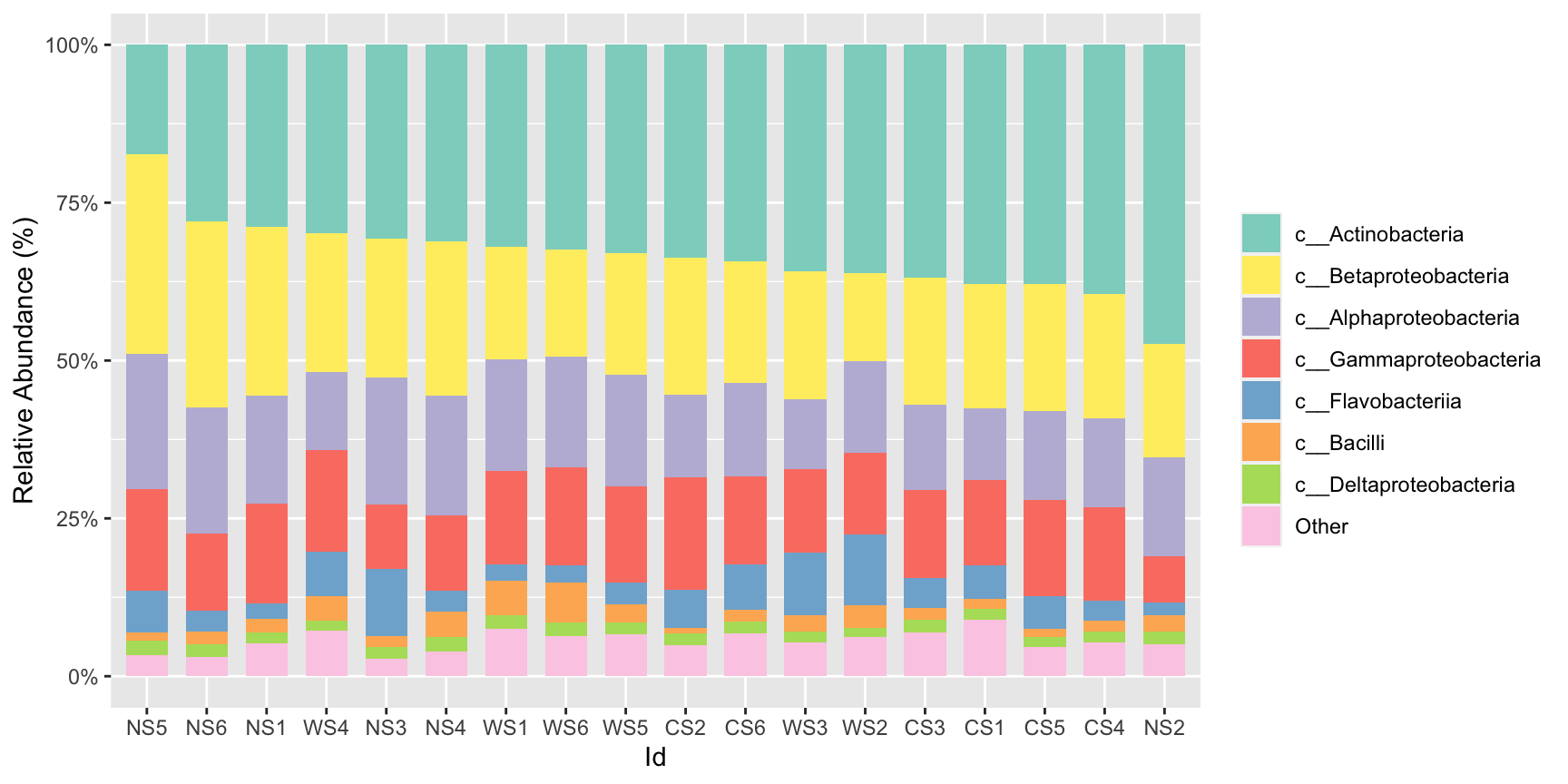
#如果想把分组中的单个样本展示出来的话,可以设置style = "sample"
stackplot(class, metadata, group = "Group",style = "sample")+
scale_fill_manual(name="Class",values =get_cols(10))
- 1
- 2
- 3

#如果想看的是绝对量而不是相对丰度:relative = F
stackplot(class, metadata, group = "Group",style = "sample",relative = F)+
scale_fill_manual(name="Class",values =get_cols(10))
- 1
- 2
- 3

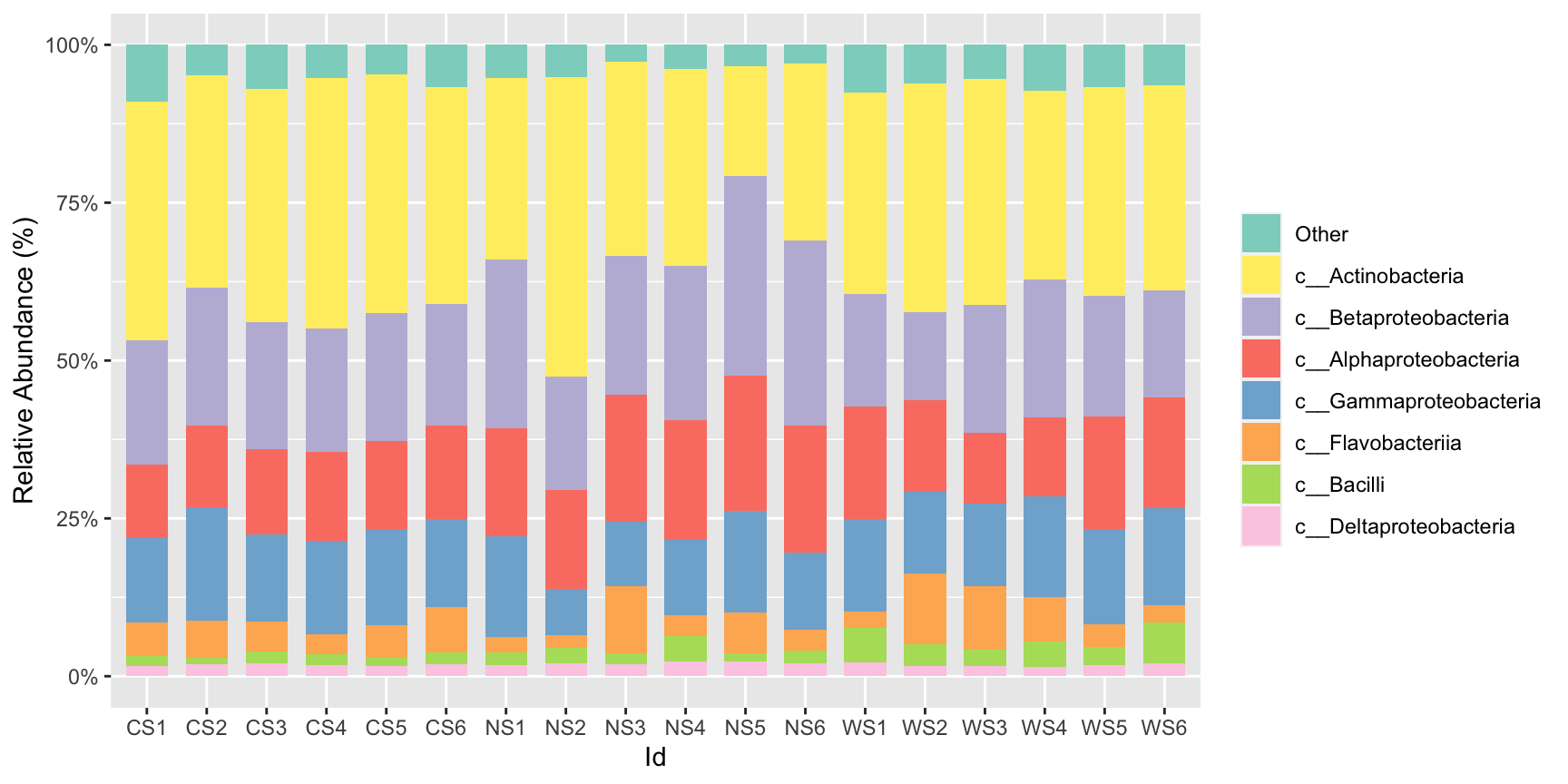
#我们有时候可以希望按照某个物种/基因的丰度排序,设置group_order:
stackplot(class, metadata, group = "Id",group_order = "c__Actinobacteria")+
scale_fill_manual(name="Class",values =get_cols(10))
- 1
- 2
- 3
#或者是直接更改每一个fill的上下顺序,设置stack_order:
stackplot(class, metadata, group = "Id",stack_order = "Other")+
scale_fill_manual(name="Class",values =get_cols(10))
- 1
- 2
- 3
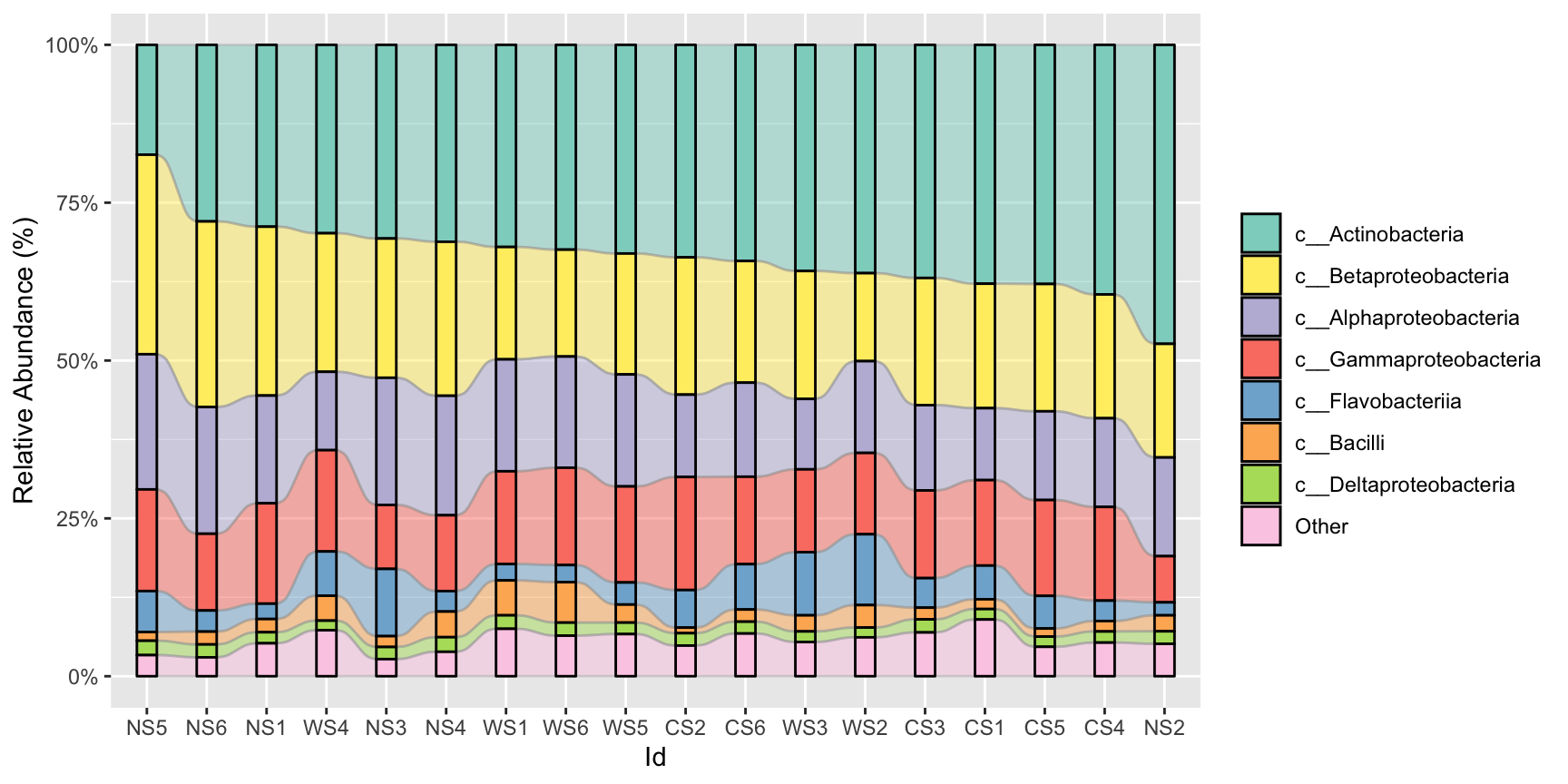
#或是做出流动的效果,时间数据最佳:flow=T
stackplot(class, metadata, group = "Id",group_order = "c__Actinobacteria",flow = T)+
scale_fill_manual(name="Class",values =get_cols(10))
- 1
- 2
- 3
Polar coordinate
ggplot2没有提供直接绘制饼图的geom对象,但柱形图可以通过极坐标变换生成饼图或环形图等图形,使用coord_polar()函数可以实现极坐标变换。
library(ggplot2)
# 创建示例数据
data <- data.frame(
category = c("A", "B", "C", "D"),
value = c(30, 20, 15, 35)
)
# 绘制饼图
p <- ggplot(data, aes(x = "", y = value, fill = category)) +
geom_bar(width = 1, stat = "identity") +
theme_void()
# 显示图形
p
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

p+coord_polar(theta = "y")
- 1

为了方便自己日常使用,我将这一类通过柱形图极坐标变换得到的图形整合进了gghuan函数中:
#help(gghuan)
#输入数据格式很简单第一列是类别,第二列是数字(对应的某个值)即可。
a=data.frame(type = letters[1:6], num = c(1, 3, 3, 4, 5, 10))
gghuan(a) + scale_fill_manual(values = get_cols(6, "col3"))
- 1
- 2
- 3
- 4
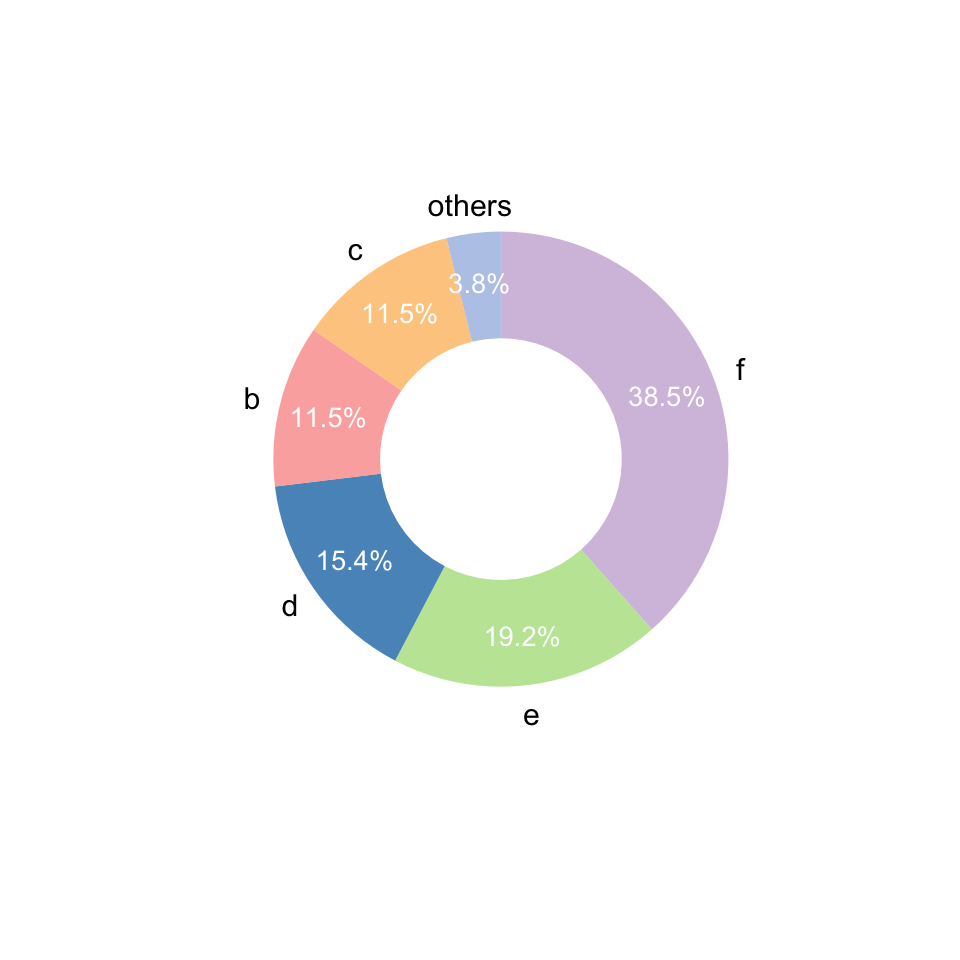
#大胆调节每一个设置
gghuan(a,bar_params=list(col="black"),
text_params=list(col="#b15928",size=3),
text_params2=list(col="#006d2c",size=5))+scale_fill_manual(values = get_cols(6, "col3"))
- 1
- 2
- 3
- 4

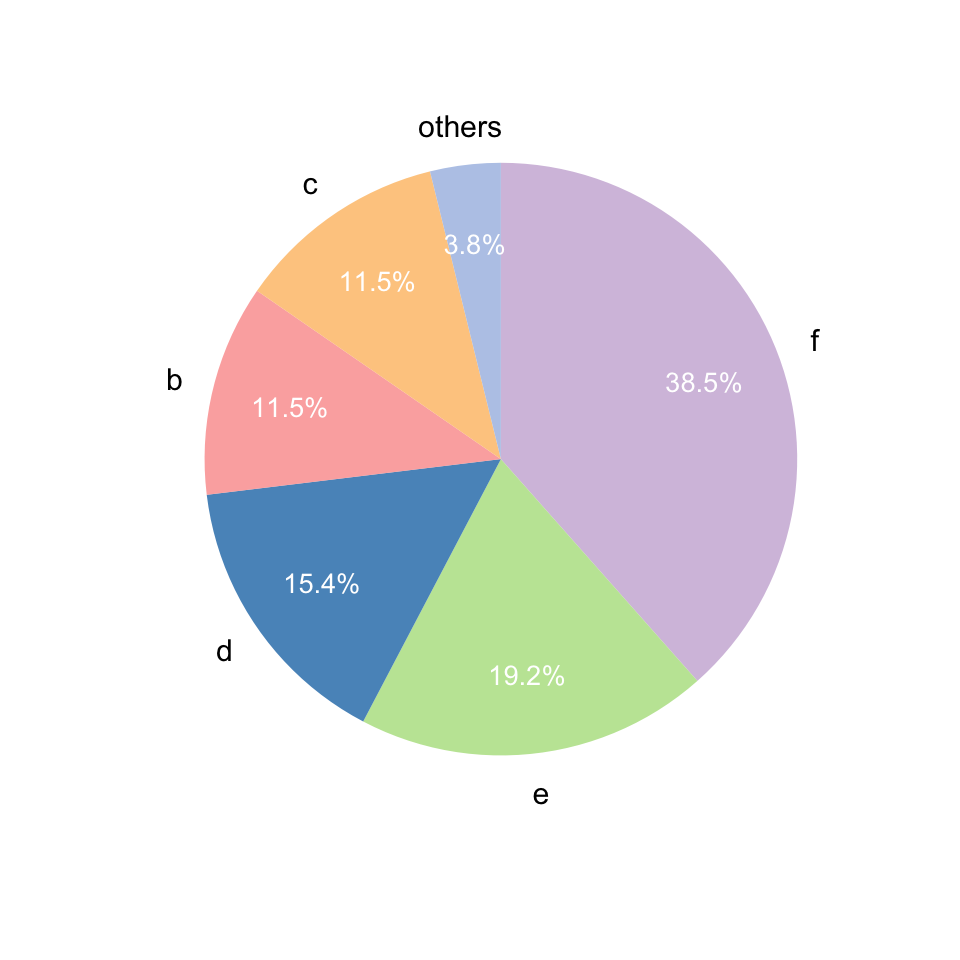
#改变绘图风格:mode=1~3
#mode=3就是饼图
gghuan(a,mode=3) + scale_fill_manual(values = get_cols(6, "col3"))
- 1
- 2
- 3
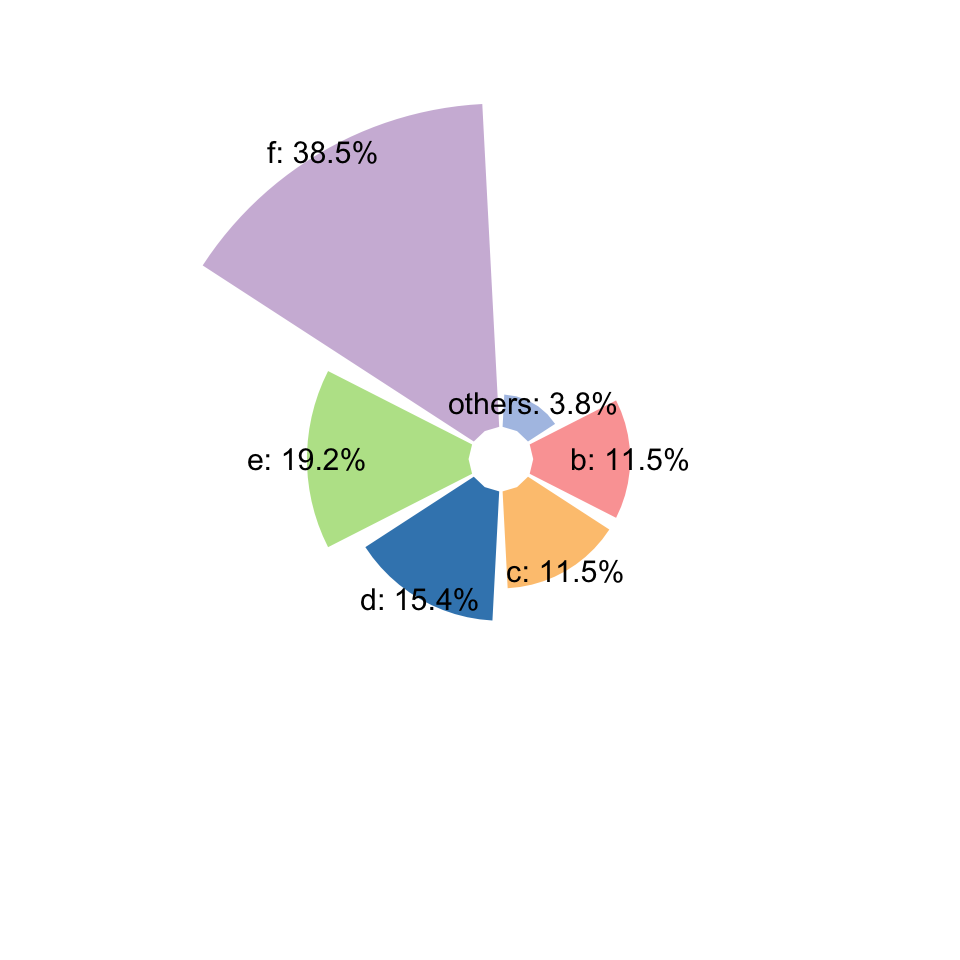
#mode=2就是环状柱形图,相当于coord_polar(theta = "x")的变换
gghuan(a,mode=2) + scale_fill_manual(values = get_cols(6, "col3"))
- 1
- 2
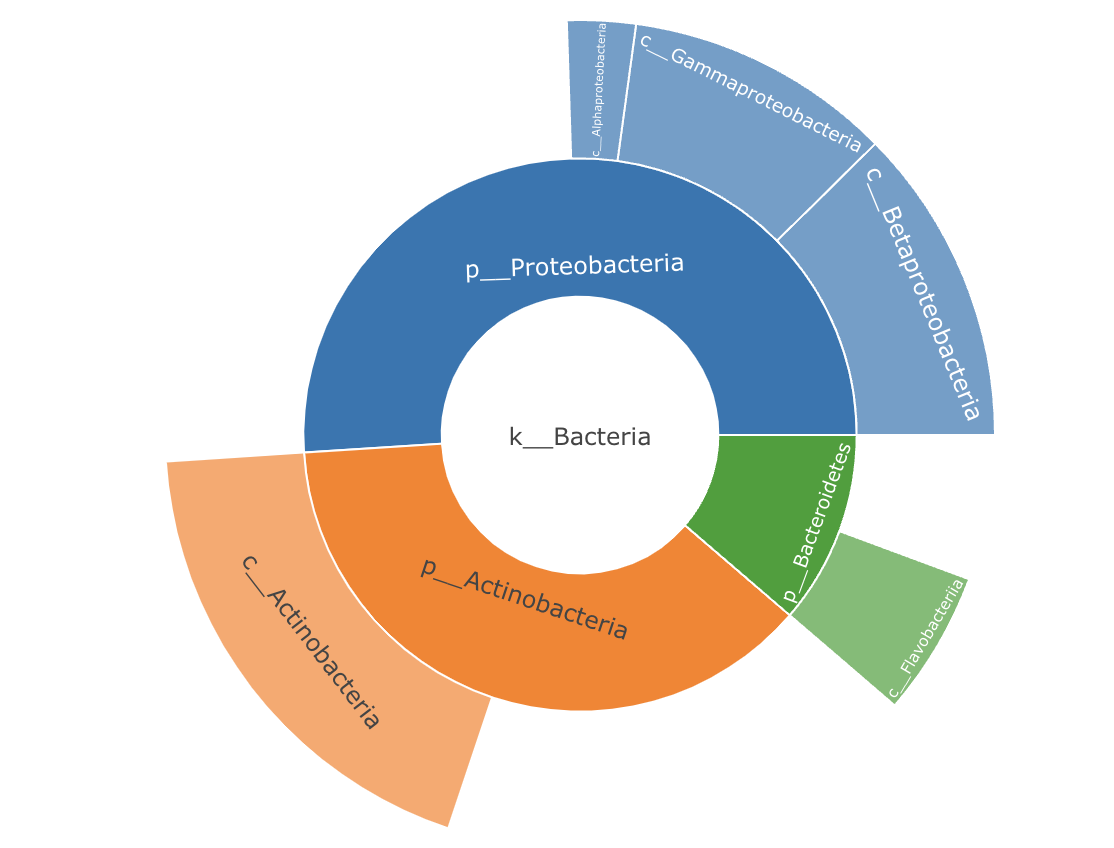
多层的环形图一般用来画具有某种层次关系的表格,比如物种分类信息。
下面使用函数gghuan2来完成多层环形图绘制:
#提供一个具有一定层级关系的表格(除最后一列外有多少列就有多少个环,最后一列为丰度)
cbind(taxonomy,num=rowSums(otutab))[1:10,c(1:3,8)]%>%dplyr::arrange_all()->test
head(test)
- 1
- 2
- 3
## Kingdom Phylum
## s__un_g__Actinoplanes k__Bacteria p__Actinobacteria
## s__Lentzea_flaviverrucosa k__Bacteria p__Actinobacteria
## s__un_g__Streptomyces k__Bacteria p__Actinobacteria
## s__un_f__Thermomonosporaceae k__Bacteria p__Actinobacteria
## s__Flavobacterium_terrae k__Bacteria p__Bacteroidetes
## s__un_g__Rhizobium k__Bacteria p__Proteobacteria
## Class num
## s__un_g__Actinoplanes c__Actinobacteria 8518
## s__Lentzea_flaviverrucosa c__Actinobacteria 9508
## s__un_g__Streptomyces c__Actinobacteria 10813
## s__un_f__Thermomonosporaceae c__Actinobacteria 26147
## s__Flavobacterium_terrae c__Flavobacteriia 16484
## s__un_g__Rhizobium c__Alphaproteobacteria 7789
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
gghuan2(test,percentage = F)+scale_fill_manual(values = get_cols(10))
- 1

这个多层环形图长得跟旭日图也比较像了,不过想画旭日图的话也可以用my_sunburst函数,
输入的数据格式仍然相同:
my_sunburst(test)
- 1
Streamgraph
我们前面已经用stackplot设置flow=T实现了在柱形图的分割间加上了连接的线,
那我们进一步想想,如果这个连接的线扩展到整个柱子,而柱子越来越细时,就成了一个面积图(areaplot):
areaplot(class,legend_title ="Class")+scale_fill_manual(values =get_cols(10))
- 1

更有意思的是,如果连接的线是曲线,并且流动的曲线扩展到整个柱子,就能画出流动图(河流图,Streamgraph)了。
这里用streamgraph包的例子
#Install
#devtools::install_github("hrbrmstr/streamgraph")
library(streamgraph)
# Create data:
data <- data.frame(
year=rep(seq(1990,2016) , each=10),
name=rep(letters[1:10] , 27),
value=sample( seq(0,1,0.0001) , 270)
)
# Basic stream graph: just give the 3 arguments
pp <- streamgraph(data, key="name", value="value", date="year", height="300px", width="90%")
pp
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

Sankey
如果我们的数据是每个柱子间有联系的(层级关系或其他包含关系均可),用柱子间的面作为这种通量的量化,
我们就得到了一个这样的图形,
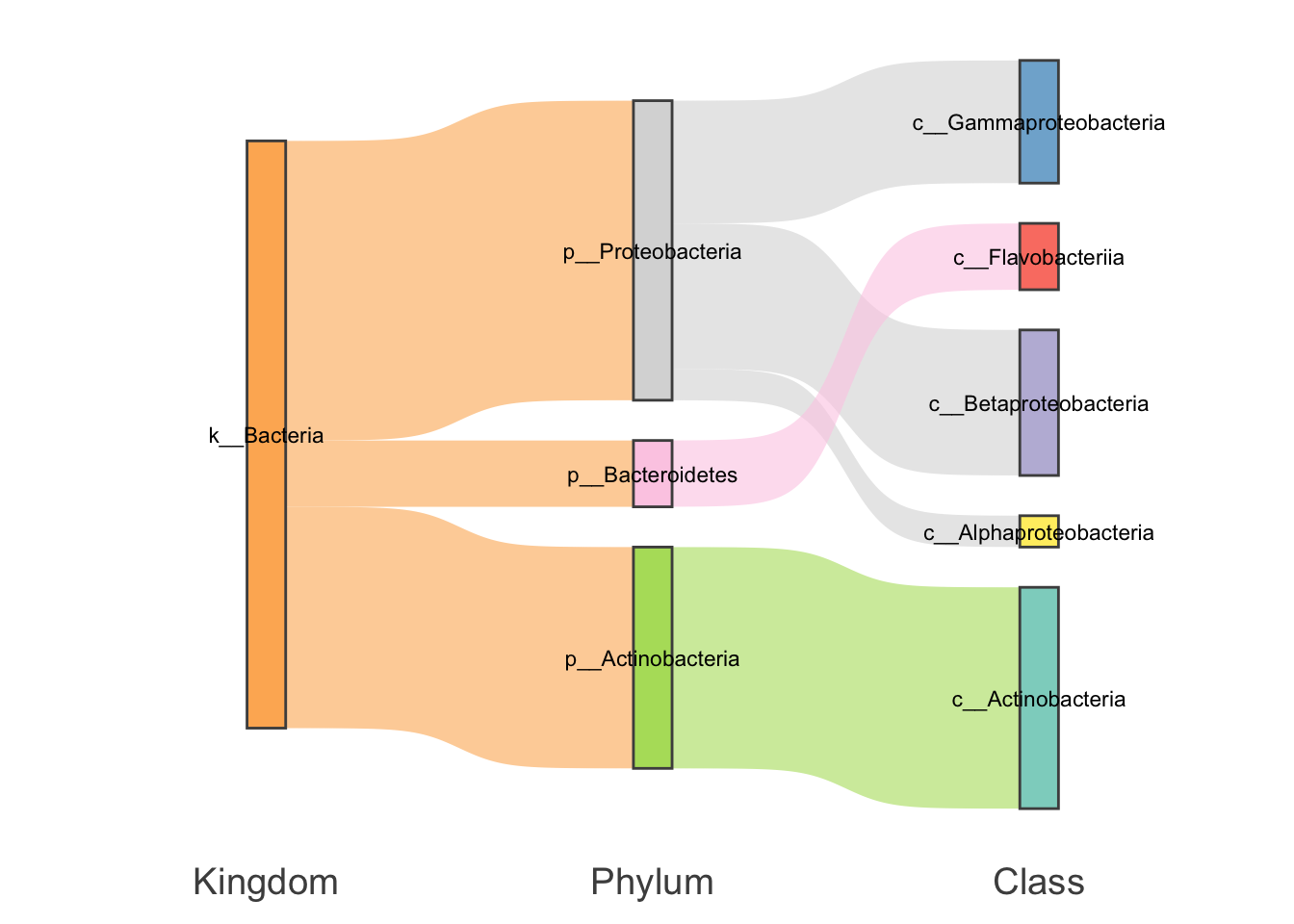
my_sankey(test,mode = "gg")
- 1
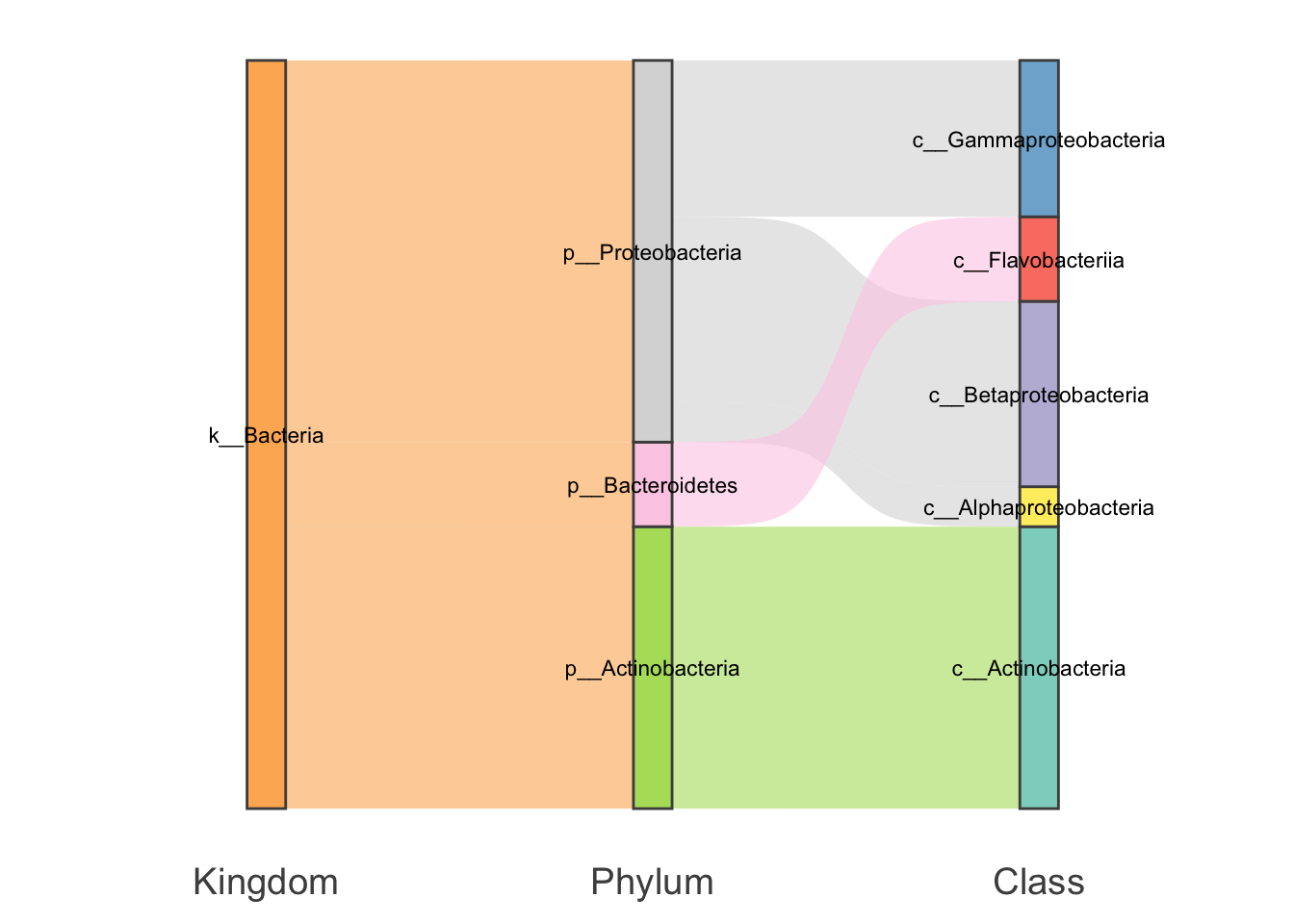
如果柱子之间再拆开一点的话,这便是我们熟悉的桑基图了:
my_sankey(test,mode = "gg",space = 1e4)
- 1
总之,一个简单的柱形图也可以变化出各式各样的衍生图形。
但所有的可视化方法都是为展示数据服务的,
我整合这些函数也是希望可以更关注数据本身,花更少的精力在调节图形上,先快速对我们的数据有整体的把握。
pcutils的初衷还是迎合我自己的编程与数据分析习惯的,所以可能并不适合所有人,大家也可以直接fork并修改我的源码,欢迎大家提出建议与意见。

关注公众号 ‘biollbug’,获取最新推送。


