
- 1你真的懂PCIe吗?
- 2译:用Swift并行编程(基础篇)
- 3java程序员_Java程序员必备的一些流程图
- 4精准定时任务管理:探究Linux下timerfd与epoll的默契_timerfd 更新时间 epoll时
- 5二叉树 根据后序遍历生成二叉树
- 6Flink 1.11.1:flink CDC Debezium自定义修改debezium-json格式_corrupt debezium json message
- 7ZYNQ SDK开发调试踩坑指南_error: [labtools 27-3165] end of startup status: l
- 8经典目标检测算法模型总结汇总_目标检测模型
- 9NocoDB:在任何数据库上创建即时电子表格和 REST API。
- 10可解释性AI_可解释人工智能
【目标检测实验系列】使用yolov3 spp训练西工大遥感数据集NWPU VHR-10(包括如何将NWPU VHR-10转为VOC格式和yolov3 spp实验调试的详细步骤,且附上训练完的权重文件)
赞
踩
1. 文章主要内容
此篇博客为[目标检测实验系列]的首篇博客,该系列主要记录在目标检测实验过程中的详细步骤和所思所想,欢迎大家互相交流。
本篇博客参考的主要内容来源于:
大彤小忆–使用Python将NWPU VHR-10数据集的格式转换成VOC2007数据集的格式
霹雳吧啦Wz–YOLOv3 SPP源码解析-1代码使用简介
本篇博客主要涉及两个主体内容。第一个:将西工大遥感数据集NWPU VHR-10的格式转为VOC通用的数据集。第二个:再次将转换后的VOC格式的数据集转变成yolov3 spp所需要格式的数据集,之后调试项目内容,达到成功跑通项目的要求。(通读本篇博客大概需要10分钟左右的时间)。
2. 西工大数据集转换为VOC格式数据集
2.1 VOC数据集结构
VOC通用数据集格式如下图所示:
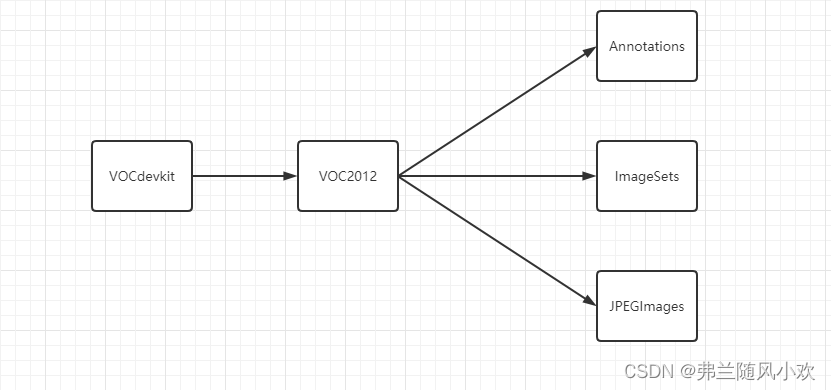
特别注意以下几点内容:
1.这里的箭头表示的文件夹由外到内,比如VOCdevkit文件夹包含了VOC2012文件,而VOC2012文件夹包含Annotations、ImageSets和JPEGImages
2.这里的VOC2012文件夹名字也可以换成VOC2007,代表不同的版本。事实上,只要保证整体的文件夹结构没有问题,所有的文件夹名字都可以自定义,只需要在对应的模型代码中指定好自定义的文件夹名字。
3.和Annotations、ImageSets和JPEGImages同级目录下,还有两个文件夹SegmentationClass、SegementionObject。因为这里用不到,所以不过多赘述。各个文件内容代表什么,请各位同学自己研究。
2.2 西工大数据集
特别注意:西工大数据集-(提取密码:1234)
西工大NWPU VHR-10数据集包含10种类别,其主要结构如下图所示: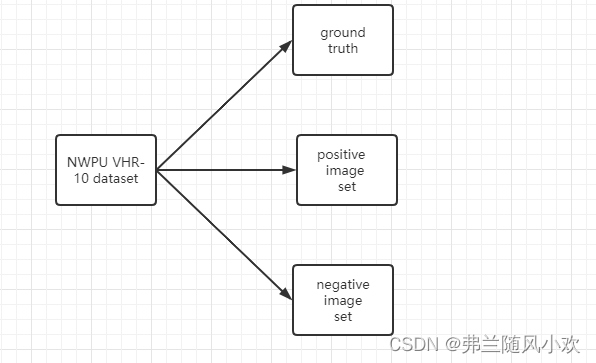
特别注意以下几点内容:
1.groud truth文件夹内容是坐标信息以及所对应的类别;positive image set文件夹内容是正样本的图片; negative image set文件夹内容是负样本的图片
2.3 转换格式
2.3.1 构建与VOC类似的数据集文件结构(文件夹名可以自定义)
本篇博客构建的文件结构如下图所示:(用于存放转换后的数据集)
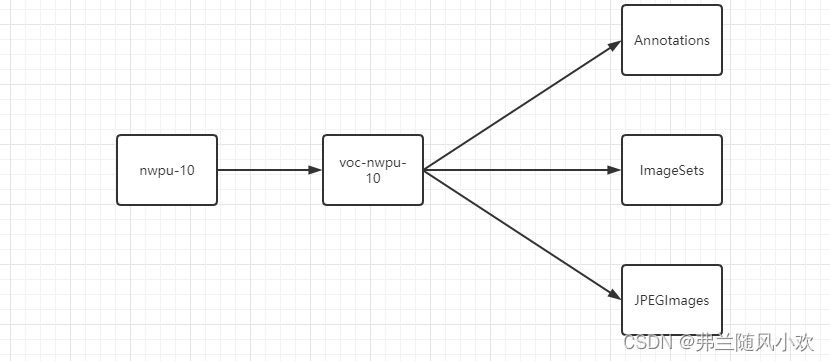
2.3.2 数据预处理
因为NWPU VHR-10数据集的positive image set图片内容是从001.jpg-650.jpg,而negative image set图片内容是从001.jpg到150.jpg。首先,需要将正样本的数据和负样本的数据合并,并且重写进行顺序编号处理,改成000001.jpg-000800.jpg。其中positive image set文件夹内的图片被重命名为000001.jpg-000650.jpg,negative image set文件夹内的图片被重命名为000651.jpg-000800.jpg。
最后将这800张图片存放在D:/deeplearning-by-liaohuan/object-detection/datasets/NWPU-VHR-10 dataset/nwpu-10/voc-nwpu-10/JPEGImages(注意:这里的文件夹路径是自定义的,需按照每个同学文件夹的实际绝对路径填写),具体的转换代码如下所示:
import os import shutil def imag_rename(old_path, new_path,start_number = 0): filelist = os.listdir(old_path) # 该文件夹下所有的文件(包括文件夹) if os.path.exists(new_path) == False: os.mkdir(new_path) for file in filelist: # 遍历所有文件 Olddir = os.path.join(old_path, file) # 原来的文件路径 if os.path.isdir(Olddir): # 如果是文件夹则跳过 continue filename = os.path.splitext(file)[0] # 文件名 filetype = os.path.splitext(file)[1] # 文件扩展名 if filetype == '.jpg': Newdir = os.path.join(new_path, str(int(filename) + start_number).zfill(6) + filetype) # 用字符串函数zfill 以0补全所需位数 shutil.copyfile(Olddir, Newdir) if __name__ == "__main__": # 解决positive image set文件夹中的重命名问题,start_number = 0 old_path = "D:/deeplearning-by-liaohuan/object-detection/datasets/NWPU-VHR-10 dataset/positive image set/" new_path = "D:/deeplearning-by-liaohuan/object-detection/datasets/NWPU-VHR-10 dataset/nwpu-10/voc-nwpu-10/JPEGImages" imag_rename(old_path, new_path) # 解决negative image set文件夹中的重命名问题,start_number = 650 old_path = "D:/deeplearning-by-liaohuan/object-detection/datasets/NWPU-VHR-10 dataset/negative image set/" new_path = "D:/deeplearning-by-liaohuan/object-detection/datasets/NWPU-VHR-10 dataset/nwpu-10/voc-nwpu-10/JPEGImages" imag_rename(old_path,new_path,start_number = 650) print("done!")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
特别注意以下几点内容:
1.代码需要修改的部分在main函数里面,分别是old_path、new_path一共两对。其中old_path分别对应于西工大数据集的positive image set、negative image set文件夹路径,而new_path对应于转换合并后创建的新文件夹路径,上面有提到。
接下来处理Annoatations文件夹的内容:将NWPU VHR-10数据集的ground truth文件夹内的标注信息txt文件转换为与VOC2007数据集的Annotations文件夹内的标注信息xml文件格式相同的xml文件,并重命名为000001.xml-000650.xml;由于negative image set文件夹内的图片没有对应的标注信息文件,所以生成包含图片的size信息、不包含object的bounding box信息的xml文件,并命名为000651.xml-000800.xml,并且存放在路径为D:/deeplearning-by-liaohuan/object-detection/datasets/NWPU-VHR-10 dataset/nwpu-10/voc-nwpu-10/Annoatations下(和上面一样,这里也是自定义的路径),具体的代码如下所示:
from lxml.etree import Element,SubElement,tostring from xml.dom.minidom import parseString import xml.dom.minidom import os import sys from PIL import Image # 处理NWPU VHR-10数据集中的txt标注信息转换成 xml文件 # 此处的path应该传入的是NWPU VHR-10数据集文件夹下面的ground truth文件夹的目录 # 即 path = "E:/Remote Sensing/Data Set/NWPU VHR-10 dataset/ground truth" def deal(path): files=os.listdir(path) # files获取所有标注txt文件的文件名 # 此处可以自行设置输出路径 按照VOC数据集的格式,xml文件应该输出在数据集文件下面的Annotations文件夹下面 outpath = "D:/deeplearning-by-liaohuan/object-detection/datasets/NWPU-VHR-10 dataset/nwpu-10/voc-nwpu-10/Annoatations/" # 如果输出文件夹不存在,就创建它 if os.path.exists(outpath) == False: os.mkdir(outpath) # 遍历所有的txt标注文件,一共650个txt文件 for file in files: filename=os.path.splitext(file)[0] # 获取ground truth文件夹中标注txt文件的文件名,比如如果文件名为001.txt,那么filename = '001' sufix=os.path.splitext(file)[1]# 获取标注txt文件的后缀名 判断是否为txt if sufix=='.txt': # 标注txt文件中每一行代表一个目标,(x1,y1),(x2,y2),class_number来表示 xmins=[] ymins=[] xmaxs=[] ymaxs=[] names=[] # num,xmins,ymins,xmaxs,ymaxs,names=readtxt(path + '/' + file) # 调用readtxt文件获取信息,转到readtxt函数 path_txt = path + '/' + file # 获取txt标注文件的路径信息 # 打开txt标注文件 with open(path_txt, 'r') as f: contents = f.read() # 将txt文件的信息按行读取到contents列表中 objects=contents.split('\n') # 以换行划分每一个目标的标注信息,因为每一个目标的标注信息在txt文件中为一行 for i in range(objects.count('')): objects.remove('') # 将objects中的空格移除 num=len(objects) # 获取一个标注文件的目标个数,objects中一个元素代表的信息就是一个检测目标 # 遍历 objects列表,获取每一个检测目标的五维信息 for objecto in objects: xmin=objecto.split(',')[0] # xmin = '(563' xmin=xmin.split('(')[1] # xmin = '563' 可能存在空格 xmin=xmin.strip() # strip函数去掉字符串开头结尾的空格符 ymin=objecto.split(',')[1] # ymin = '478)' ymin=ymin.split(')')[0] # ymin = '478' 可能存在空格 ymin=ymin.strip() # strip函数去掉字符串开头结尾的空格符 xmax=objecto.split(',')[2] # xmax同理 xmax=xmax.split('(')[1] xmax=xmax.strip() ymax=objecto.split(',')[3] # ymax同理 ymax=ymax.split(')')[0] ymax=ymax.strip() name=objecto.split(',')[4] # 与上 同理 name=name.strip() if name=="1 " or name=="1": # 将数字信息转换成label字符串信息 name='airplane' elif name=="2 "or name=="2": name='ship' elif name== "3 "or name=="3": name='storage tank' elif name=="4 "or name=="4": name='baseball diamond' elif name=="5 "or name=="5": name='tennis court' elif name=="6 "or name=="6": name='basketball court' elif name=="7 "or name=="7": name='ground track field' elif name=="8 "or name=="8": name='harbor' elif name=="9 "or name=="9": name='bridge' elif name=="10 "or name=="10": name='vehicle' else: print(path) # print(xmin,ymin,xmax,ymax,name) xmins.append(xmin) ymins.append(ymin) xmaxs.append(xmax) ymaxs.append(ymax) names.append(name) filename_fill = str(int(filename)).zfill(6) # 将xml的文件名填充为6位数,比如1.xml就改为000001.xml filename_jpg = filename_fill + ".jpg" # 由于xml中存储的文件名为000001.jpg,所以还得对所有的NWPU数据集中的图片进行重命名 print(filename_fill) dealpath = outpath + filename_fill +".xml" # 注意,经过重命名转换之后,图片都存放在E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/JPEGImages/中 imagepath = "D:/deeplearning-by-liaohuan/object-detection/datasets/NWPU-VHR-10 dataset/nwpu-10/voc-nwpu-10/JPEGImages/" + filename_fill + ".jpg" with open(dealpath, 'w') as f: img=Image.open(imagepath) # 根据图片的地址打开图片并获取图片的宽 和 高 width=img.size[0] height=img.size[1] # 将图片的宽和高以及其他和VOC数据集向对应的信息 writexml(dealpath,filename_jpg,num,xmins,ymins,xmaxs,ymaxs,names, height, width) # 同时也得给negative image set文件夹下面的所有负样本图片生成xml标注 negative_path = "D:/deeplearning-by-liaohuan/object-detection/datasets/NWPU-VHR-10 dataset/negative image set/" negative_images = os.listdir(negative_path) for file in negative_images: filename = file.split('.')[0] # 获取文件名,不包括后缀名 filename_fill = str(int(filename) + 650).zfill(6) # 将xml的文件名填充为6位数。同时加上650,比如1.xml就改为00001.xml filename_jpg = filename_fill + '.jpg' # 比如第一个负样本001.jpg的filename_jpg 为000651.jpg ## 重命名为6位数 print(filename_fill) ## 生成不含目标的xml文件 dealpath = outpath + filename_fill +".xml" # 注意,经过重命名转换之后,图片都存放在E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/JPEGImages/中 imagepath = "D:/deeplearning-by-liaohuan/object-detection/datasets/NWPU-VHR-10 dataset/nwpu-10/voc-nwpu-10/JPEGImages/" + filename_fill + ".jpg" with open(dealpath, 'w') as f: img = Image.open(imagepath) width = img.size[0] height = img.size[1] # 将宽高和空的目标标注信息写入xml标注 writexml(dealpath,filename_jpg,num = 0,xmins = [],ymins = [],xmaxs = [],ymaxs = [],names = [],width=width,height=height) # NWPU数据集中标注的五维信息 (x1,y1) denotes the top-left coordinate of the bounding box, # (x2,y2) denotes the right-bottom coordinate of the bounding box # 所以 xmin = x1 ymin = y1, xmax = x2, ymax = y2 同时要注意这里的相对坐标是以图片左上角为坐标原点计算的 # VOC数据集对于包围框标注的格式是bounding-box(包含左下角和右上角xy坐标 # 将从txt读取的标注信息写入到xml文件中 def writexml(path,filename,num,xmins,ymins,xmaxs,ymaxs,names,height, width):# Nwpu-vhr-10 < 1000*600 node_root=Element('annotation') node_folder=SubElement(node_root,'folder') node_folder.text="VOC2007" node_filename=SubElement(node_root,'filename') node_filename.text="%s" % filename node_size=SubElement(node_root,"size") node_width = SubElement(node_size, 'width') node_width.text = '%s' % width node_height = SubElement(node_size, 'height') node_height.text = '%s' % height node_depth = SubElement(node_size, 'depth') node_depth.text = '3' for i in range(num): node_object = SubElement(node_root, 'object') node_name = SubElement(node_object, 'name') node_name.text = '%s' % names[i] node_name = SubElement(node_object, 'pose') node_name.text = '%s' % "unspecified" node_name = SubElement(node_object, 'truncated') node_name.text = '%s' % "0" node_difficult = SubElement(node_object, 'difficult') node_difficult.text = '0' node_bndbox = SubElement(node_object, 'bndbox') node_xmin = SubElement(node_bndbox, 'xmin') node_xmin.text = '%s'% xmins[i] node_ymin = SubElement(node_bndbox, 'ymin') node_ymin.text = '%s' % ymins[i] node_xmax = SubElement(node_bndbox, 'xmax') node_xmax.text = '%s' % xmaxs[i] node_ymax = SubElement(node_bndbox, 'ymax') node_ymax.text = '%s' % ymaxs[i] xml = tostring(node_root, pretty_print=True) dom = parseString(xml) with open(path, 'wb') as f: f.write(xml) return if __name__ == "__main__": # path指定的是标注txt文件所在的路径 path = "D:/deeplearning-by-liaohuan/object-detection/datasets/NWPU-VHR-10 dataset/ground truth" deal(path) print("done!")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
特别注意以下几点内容:
1.代码里只需要修改outpath 、negative_path、imagepath、path这四个变量的路径值(也就是代码里面所有和路径相关的变量,都需要改成自己的实际路径) ,其他不需要修改。修改后Annotations文件夹的部分内容如下:
最后我们来处理ImageSets文件夹,我们对NWPU VHR-10数据集进行划分,划分为train、val、trainval、test四个文件(其中train代表训练集数据信息,val代表验证集数据信息,trainval代表训练和验证集合并的数据信息,test为测试集数据的信息)。需要注意到trainval、test组成了整个数据集的信息,仔细分清楚各个之间的关系。我们给出划分数据集信息的代码,划分后的数据集信息存放在D:/deeplearning-by-liaohuan/object-detection/datasets/NWPU-VHR-10 dataset/nwpu-10/voc-nwpu-10/ImageSets/Main文件夹里面(注意:这里的路径同样是自定义路径,不再做过多解释),具体的代码如下:
import os import random trainval_percent = 0.8 # 表示训练集和验证集(交叉验证集)所占总图片的比例 train_percent = 0.75 # 训练集所占交叉验证集的比例 xmlfilepath = 'D:/deeplearning-by-liaohuan/object-detection/datasets/NWPU-VHR-10 dataset/nwpu-10/voc-nwpu-10/Annotations' txtsavepath = 'D:/deeplearning-by-liaohuan/object-detection/datasets/NWPU-VHR-10 dataset/nwpu-10/voc-nwpu-10/ImageSets/Main' total_xml = os.listdir(xmlfilepath) num = 650 # 有目标的图片数 list = range(num) tv = int(num * trainval_percent) # xml文件中的交叉验证集数 tr = int(tv * train_percent) # xml文件中的训练集数,注意,我们在前面定义的是训练集占交叉验证集的比例 trainval = random.sample(list, tv) train = random.sample(trainval, tr) ftrainval = open('D:/deeplearning-by-liaohuan/object-detection/datasets/NWPU-VHR-10 dataset/nwpu-10/voc-nwpu-10/ImageSets/Main/trainval.txt', 'w') ftest = open('D:/deeplearning-by-liaohuan/object-detection/datasets/NWPU-VHR-10 dataset/nwpu-10/voc-nwpu-10/ImageSets/Main/test.txt', 'w') ftrain = open('D:/deeplearning-by-liaohuan/object-detection/datasets/NWPU-VHR-10 dataset/nwpu-10/voc-nwpu-10/ImageSets/Main/train.txt', 'w') fval = open('D:/deeplearning-by-liaohuan/object-detection/datasets/NWPU-VHR-10 dataset/nwpu-10/voc-nwpu-10/ImageSets/Main/val.txt', 'w') for i in list: name = total_xml[i][:-4] + '\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) for i in range(150): num = str(651 + i).zfill(6) + '\n' ftest.write(num) ftrainval.close() ftrain.close() fval.close() ftest.close() print("done!")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
特别注意以下几点内容:
1.代码里修改的变量为xmlfilepath 、txtsavepath 、ftrainval、ftest、ftrain和fval.
2.由于NWPU-VHR-10 dataset中只有positive image set文件夹中的650张图片包含目标的标注信息,所以训练集train及验证集val只能在从这650张图片中划分,negative image set文件夹中的150张图片不包含目标的标注信息,划分在测试集test中.
3.代码中的trainval_percent 代表trainval.txt所占总数据集的比例,train_percent 代表在train.txt所占trainval.txt数据集(这里的总数据集是650张图片,不包括不标注的150张图片)的比例,千万别搞混了,这里的比例自己也可以进行修改!这样我们就成功的将西工大数据集转为VOC格式的数据集了。最后,ImageSets的Main文件夹的内容为:
3. yolov3 spp 训练NWPU-VHR-10 dataset
3.1 源码下载及其相关准备文件
前提说明:以下操作都在本地环境OK的情况下进行的,如果没有配置好环境,请根据下面源码链接里环境配置一栏一一配置完成。
首先下载yolov3 spp 源码(yolov3 spp源码链接),之后准备新建一个pascal_voc_classes.json放在源码的data文件夹下(注意:如果源码里面本来存在pascal_voc_classes.json,那么修改其内容如下即可),因为我们这里使用的NWPU-VHR-10 dataset数据集,所以种类一共有10类,其json文件的代码如下所示:
{
"airplane": 1,
"ship": 2,
"storage tank": 3,
"baseball diamond": 4,
"tennis court": 5,
"basketball court": 6,
"ground track field": 7,
"harbor": 8,
"bridge": 9,
"vehicle": 10
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
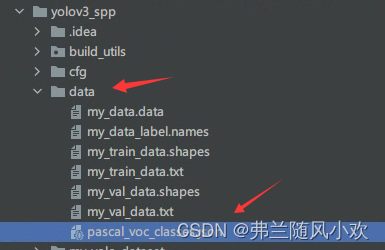
其json文件在源代码的目录摆放位置如下图所示(data文件夹里面其他文件暂时先别管,后面会生成):
3.2 VOC格式数据集转换为yolo格式
使用源码根目录当中trans_voc2yolo.py脚本进行转换,并在源码下的data文件夹下生成my_data_label.names标签文件.执行脚本前,需要根据自己的路径修改trans_voc2yolo.py中的一些参数:(特别注意:这里的voc_root、voc_version正好对应于我们在上一部分处理得到的VOC格式的西工大数据集的最外面两层的文件夹名字,其他的路径按照以下代码照搬即可)
voc_root = "nwpu-10"
voc_version = "voc-nwpu-10"
# 转换的训练集以及验证集对应txt文件
train_txt = "train.txt"
val_txt = "val.txt"
# 转换后的文件保存目录
save_file_root = "./my_yolo_dataset"
# label标签对应json文件
label_json_path = './data/pascal_voc_classes.json'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
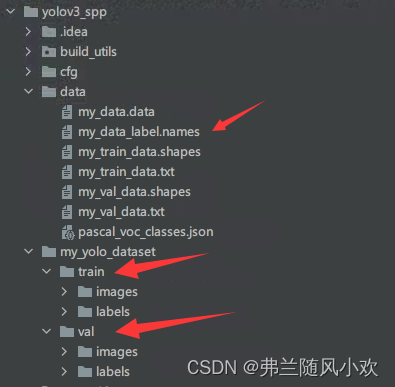
转换之后生成my_data_label.names标签文件、以及train、val文件夹,其中文件夹内的labels为图片的标签,而image为图片的路径信息,生成的内容如下图所示:
然后,我们先来处理一下源码cfg文件夹下的yolov3-spp.cfg文件,这里我们需要修改两个参数,分别是如下代码的filters、classes,特别注意:我们的种类是10,所以classes为10,filters的计算公式为(classes + 5)x3,所以filters为45.
[convolutional] size=1 stride=1 pad=1 filters=45 activation=linear [yolo] mask = 6,7,8 anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 classes=10 num=9 jitter=.3 ignore_thresh = .7 truth_thresh = 1 random=1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
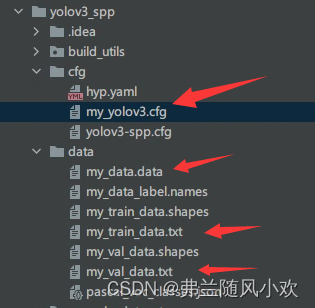
之后使用源码根目录下的calculate_dataset.py脚本生成my_train_data.txt文件、my_val_data.txt文件以及my_data.data文件,并生成新的my_yolov3.cfg文件,执行脚本前,需要修改以下参数:
train_annotation_dir = "./my_yolo_dataset/train/labels"
val_annotation_dir = "./my_yolo_dataset/val/labels"
classes_label = "./data/my_data_label.names"
cfg_path = "./cfg/yolov3-spp.cfg"
- 1
- 2
- 3
- 4
特别注意:这里的train_annotation_dir、val_annotation_dir、classes_label、cfg_path 在之前的操作中都已经生成,只需要根据实际路径进行相关修改(如果一直跟着我的操作,则不需要修改路径)
运行calculate_dataset.py脚本之后,会在data文件夹下生成my_train_data.txt文件、my_val_data.txt文件以及my_data.data文件,并在cfg文件夹下生成新的my_yolov3.cfg文件,如下图所示:
特别注意:至此,我们已经将NWPU-VHR-10 dataset的VOC格式数据集转换成了yolo格式的数据集.
4. yolov3 spp 项目参数解析、如何获取best.pt以及定位到对应的epoch
首先,我们在上面yolov3 spp源码链接预训练权重下载地址一栏,下载相应的权重,博主使用的是yolov3-spp-ultralytics-512.pt权重,并存放在根目录下的weight文件夹下,如下图所示:

4.1 yolov3 spp 项目部分参数解析
为了成功启动项目,首先我们在项目中定位到train.py文件,找到如下代码所在位置,将nw设置为0,因为博主是在windows下跑项目,所以需要设置为0:
nw = 0 # min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers windows默认设置为0
- 1
继续在train.py文件的关注以下代码:
if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--epochs', type=int, default=200) parser.add_argument('--batch-size', type=int, default=8) parser.add_argument('--cfg', type=str, default='cfg/my_yolov3.cfg', help="*.cfg path") parser.add_argument('--data', type=str, default='data/my_data.data', help='*.data path') parser.add_argument('--hyp', type=str, default='cfg/hyp.yaml', help='hyperparameters path') parser.add_argument('--multi-scale', type=bool, default=True, help='adjust (67%% - 150%%) img_size every 10 batches') parser.add_argument('--img-size', type=int, default=512, help='test size') parser.add_argument('--rect', action='store_true', help='rectangular training') parser.add_argument('--savebest', type=bool, default=True, help='only save best checkpoint') parser.add_argument('--notest', action='store_true', help='only test final epoch') parser.add_argument('--cache-images', action='store_true', help='cache images for faster training') parser.add_argument('--weights', type=str, default='weights/yolov3-spp-ultralytics-512.pt', help='initial weights path') parser.add_argument('--name', default='', help='renames results.txt to results_name.txt if supplied') parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)') parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset') parser.add_argument('--freeze-layers', type=bool, default=False, help='Freeze non-output layers') parser.add_argument('--seed', type=int, default=42, help='Random seed.') # 是否使用混合精度训练(需要GPU支持混合精度) parser.add_argument("--amp", default=False, help="Use torch.cuda.amp for mixed precision training") opt = parser.parse_args() # 检查文件是否存在 opt.cfg = check_file(opt.cfg) opt.data = check_file(opt.data) opt.hyp = check_file(opt.hyp) print(opt) with open(opt.hyp) as f: hyp = yaml.load(f, Loader=yaml.FullLoader) print('Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/') tb_writer = SummaryWriter(comment=opt.name) seed_torch(opt.seed) train(hyp)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
特别注意以下几点:
1.epoch为项目训练的次数,batch_size为批量数,cfg指定到我们生成的my_yolov3.cfg(自己数据集生成的配置文件)路径,其他的都是类似.
2.代码中的–seed是我后来添加进去的,这是为了能够复现实验效果而编写的(注意,即使固定了随机种子,两次同样的实验也不保证实验数据完全一样,还有很大因素会影响最终的实验结果,只能说尽可能减少两次相同实验的数据误差),建议加上,其在seed_torch(opt.seed)中调用,seed_torch的函数也申明在train.py中(seed的具体取值可以自定义),代码如下所示:
def seed_torch(seed=42):
seed = int(seed)
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.enabled = False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3.特别注意到–savebest参数,我这里设置的是true,是因为我的需求只要最好生成的权重文件best.pt;如果想要每一个epoch的权重文件,设置为False即可。
4.2 如何获取best.pt以及定位到对应的epoch
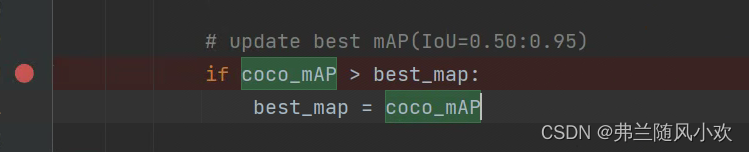
训练完成之后,会生成一个best.pt存放在weight文件夹下,可yolov3 spp 项目本身不会告诉这个best.pt对应于哪一个epoch,因为我的需求是寻找到best.pt所对应epoch的map。我们在train.py文件夹中找到了best.pt即为map(0.5-0.9-all)最大一个所对应的epoch的权重,如下所示:
仔细的发现,在训练完毕之后,会生成存放每一个epoch控制台输出的信息在根目录下的resultxxxx.txt文件中(xxxx中间代表的是数字,每个人或许都不相同),我们利用这个文件导入到excel表格中,找到第二列即为map(0.5-0.9-all)的值,这样再通过excel表格公式就可以计算出这一列最大的值所对应的epoch,从而获取到对应的map等相关数据。
5. 本篇小结
本篇博客主要分析了从NWPU-VHR-10 dataset格式转换为VOC,再次转换为yolo格式,以及在模型配置、模型参数解析方法的内容,通过仔细一步步的实验,完成了相关实验要求。
之所以比较啰嗦、详细的写实验文章,最重要的是记录实验的所思所想。而且对于本人基础比较差,网上的一些博客跳跃比较大,不太适合我,所以本人就详细、一步步的记录和分析实验的心路历程,希望能够让大家和自己能顺心的阅读。如在复现本文博客中有任何问题,请在评论区进行交流,这样大家就会有更多的收获,博主也会及时的进行交流。最后文末附上本人训练好的权重文件,供大家以需要时使用。

