
- 1【数据结构从菜鸟到大牛】 顺序表的实现_顺序表采用数组存储有什么特别要求
- 2[职场] 找工作的简历怎么写 #学习方法#微信#学习方法
- 3深度学习之图像分类(十六)-- EfficientNetV2 网络结构
- 4IntelliJ IDEA使用Alibaba Java Coding Guidelines编码规约扫描插件_阿里巴巴规约插件
- 5深度学习之卷积神经网络CNN及tensorflow代码实现示例_简单卷积神经网络代码
- 6C语言题目:寻找矩阵最值
- 7ubuntu服务器关机重新开机之后nvidia-smi不显示但nvcc -C没问题
- 8UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xc7 in position 1: invalid continuation byte_syntaxerror: (unicode error) 'utf-8' codec can't d
- 9基于 vue.js 开发构建的可视化低代码平台_vue.js引入低代码平台
- 10【Spark NLP】第 10 章:主题建模_unique term语料库
文心一言和讯飞星火全面对比测试:(五)编程能力_测试文心一言的代码能力
赞
踩
相关文章:
实战 | 用ChatGPT处理word表格数据:直接采用ChatGPt和利用ChatGPT编写python脚本两种方法
「文心一言」 vs ChatGPT,结果没有你想向中的那么不堪
前文回顾:
在(一)语言理解能力测试中,我们主要测试了两个大语言模型对复杂语义的理解、对文章情绪的识别、对文章进行摘要总结、对文章进行要素提取,测试结果表明:在语言理解能力上:除了有些问题他拒绝回答之外,讯飞星火的表现明显要好于文心一言,可以说很接近ChatGPT3.5的水平。
在(二)任务完成能力中,我们测试了模型对表格的处理能力,完成了藏头诗,拟定了跑步计划,总体发现,两个模型在这方面的能力上表现一般。
在(三)常识问题中,回答不够满意,不知到具体的原因,在逻辑推理上,文心一言和讯飞星火都要比ChatGPT差不少。最后,面对错误的问题,测试关公战秦琼和林妹妹倒拔垂杨柳,AI本着你胡说八道,我就更胡说八道的理念,基本上的就是错上加错。
在(四)逻辑数学中,测试了简单的逻辑推理和文字逻辑题,表现都不如意,测试了几个小学的数学题和奥数题,除了鸡兔问题外,其他的题完成也不好,AI在数学上的表现还要继续努力
今天我们来测试两个模型在编程能力上的表现。比较AI在编程能力上还是有优势的。
1.测试内容设计
自深度学习使得AI技术进入跨越式发展阶段以来,业界就一直在尝试用AI来写代码。
他们自己也表明熟悉多种语言
文心一言:
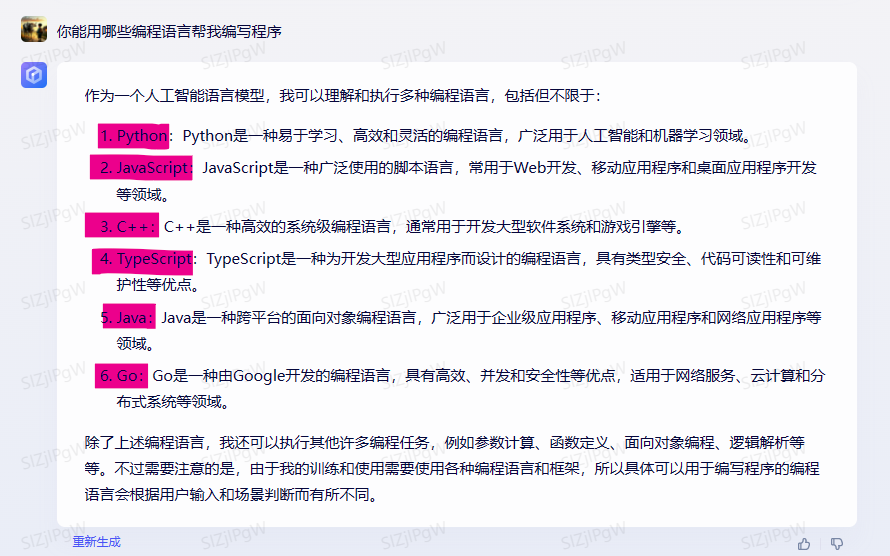
讯飞星火:

ChatGPT:

测试分为两个方面:
1. 简单代码完成:常见入门级别的编程问题(洛谷入门级),主要的语言为Python和C++;
2. 代码阅读和debug:给一段代码,代码进行注释;根据AI自己编的错误程序,看能不能完成Debug。
2.简单逻辑推理
用例1:B2010 带余除法
请用Python和C++分别帮我编写程序实现如下功能:
给定被除数和除数,求整数商及余数。此题中请使用默认的整除和取余运算,无需对结果进行任何特殊处理。
输入:
一行,包含两个整数,依次为被除数和除数(除数非零),中间用一个空格隔开。
输出:
一行,包含两个整数,依次为整数商和余数,中间用一个空格隔开。
文心一言:

看程序,文心一言完成没有问题,但是他对输入输出的有问题,提醒后,依然没有修改。
讯飞星火;

这个程序输入到洛谷,可以通过100分
ChatGPT
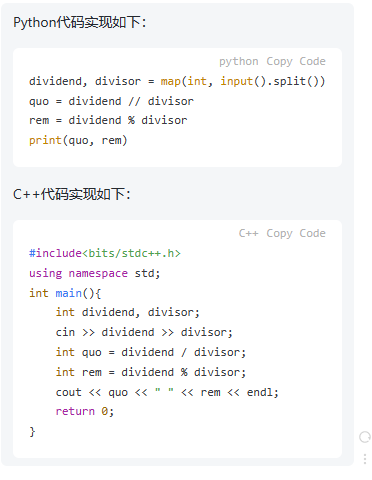
程序正确,提交能够通过,100分。
用例2:B2048 计算邮资
用Python和C++编程计算邮费。计算规则如下:
根据邮件的重量和用户选择是否加急计算邮费。
重量在1000 以内(包括),基本费8 元;
超过1000 克的部分,每500 克加收超重费4 元,不足500克部分按500克计算;
如果用户选择加急,多收5元。
输入格式:
一行,包含一个正整数x(大于1小于10e6)和一个字符c(取值为y或n),之间用一个空格隔开,分别表示重量和是否加急。
如果字符是 y,说明选择加急;如果字符是 n,说明不加急。
输出格式:
输出一行一个正整数,表示邮费。
文心一言:
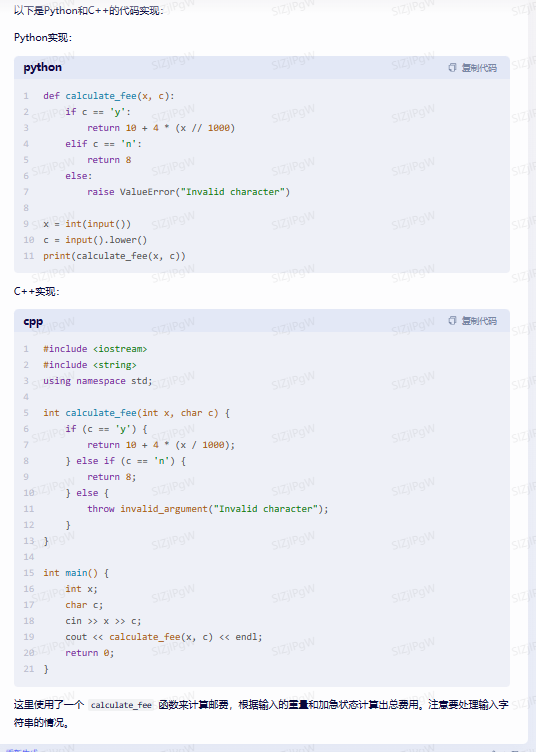
看程序,文心一言完全没有理解到题意,从前几次的测试上来看,文心一言的理解能力是比较差的,这样的程序肯定是通不过的。
讯飞星火;


讯飞星火的Python程序得了20%的分,主要问题在于计算加重没有扣除1000g,C++代码变量定义就有问题,编译没有办法通过,后面的逻辑也是和Python一样的错误。
ChatGPT


python,C++程序提交,10个测试点通过9个,一个应该是超重是500的倍数时,如图中标红的地点,就不要+1。

题目只是稍微变难一点,就拉开差距了。后面的测试觉得没有必要做了,很多的题目完成度太低,就不贴出来了
2.程序标注和debug
用例1:对一个简单的程序进行注释

文心一言:

标注得不错,但是输出不是很稳定,有时会出错。
讯飞星火:
回答也不错。
ChatGPT:
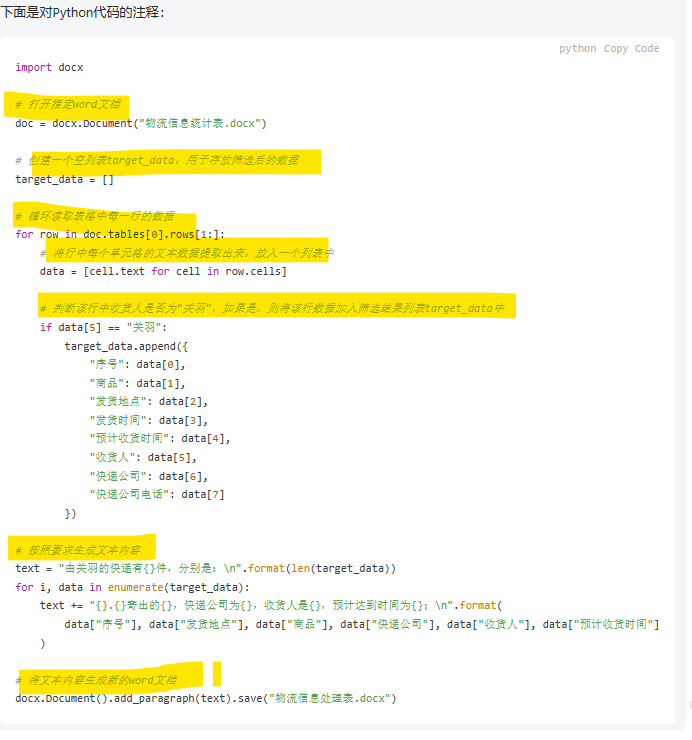
就标注来说,整体完成不错。
用例2:对程序进行Debug
选择的是ChatGPT编写的计算邮费的程序,指出当重量是2000时计算错误。
我用Python编程计算邮费。计算规则如下:根据邮件的重量和用户选择是否加急计算邮费。重量在1000 以内(包括),基本费8 元;超过1000 克的部分,每500 克加收超重费4 元,不足500克部分按500克计算;如果用户选择加急,多收5元。输入格式:一行,包含一个正整数x(大于1小于10e6)和一个字符c(取值为y或n),之间用一个空格隔开,分别表示重量和是否加急。如果字符是 y,说明选择加急;如果字符是 n,说明不加急。输出格式:输出一行一个正整数,表示邮费。
我编写的程序如下:
weight, is_urgent = input().split()
weight = int(weight)
basic_fee = 8
if weight > 1000:
overweight = weight - 1000
extra_fee = (overweight // 500 + 1) * 4
else:
overweight = 0
extra_fee = 0
if is_urgent == 'y':
total_fee = basic_fee + extra_fee + 5
else:
total_fee = basic_fee + extra_fee
print(total_fee)
但是,当重量超出部分刚好被500整除时,计算错误,请帮我修改程序,并将程序输出。
文心一言:
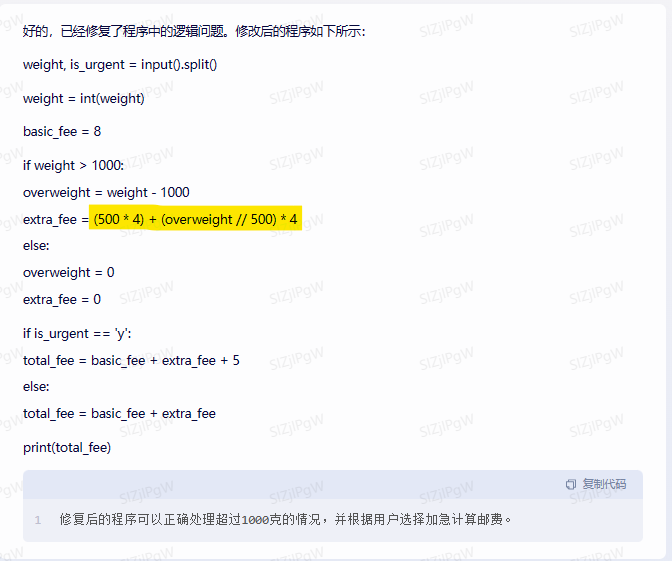
首先做了一个修改,但是这修改变得更差了,我提醒他:

我提醒他,但是,他就这样回答我?,是我的描述不对吗?算了吧
讯飞星火:

没有做任何的修改,提醒之后:
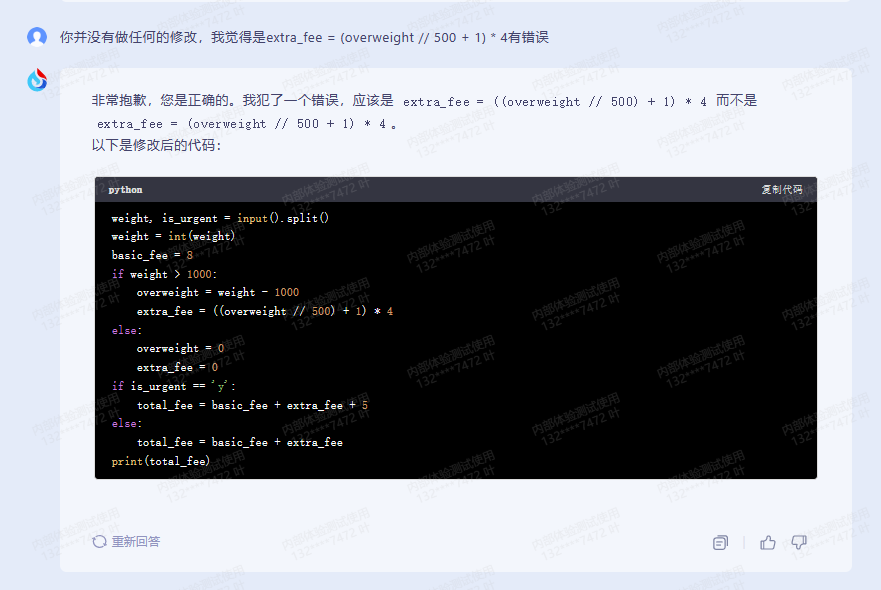
指出,但是就不改,像极了我自己,

ChatGPT:

当我提出整除出现错误时,立马体会到了我的意思,而且这个+499向上取整的做法也挺巧妙的,要我会加一个判断

。
差距啊,差距!!
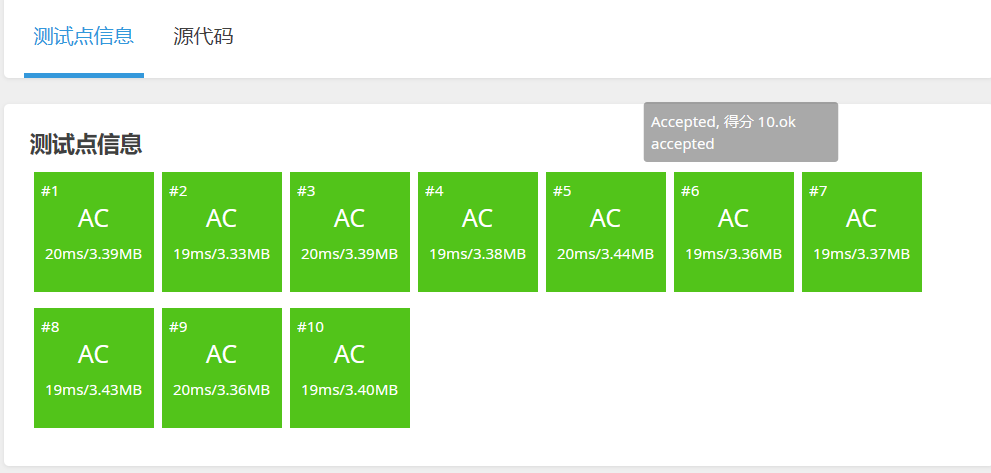
提交,全部通过!
4.总结
今天测试了三个模型的编程能力,ChatGPT的能力还是可以的,我在其他的测试中已经体会道路,但是文心一言和讯飞星火还要努力。
关于文心一言和讯飞星火的测试就全部结束。
还有没有测试到的地方,或是测试方法有错误的地方,希望大家指出,后期看有没有时间做更详细的测试。
希望国产的AI大模型越来越好。



