
- 1Python小白学习:超级详细的字典介绍(字典的定义、存储、修改、遍历元素和嵌套)_python 定义字典
- 2C语言排序算法之冒泡排序_冒泡算法c语言程序
- 3extcon驱动及其在USB驱动中的应用
- 4(建议收藏)OpenHarmony系统能力SystemCapability列表
- 5ios微信浏览器App下载链接怎样跳转到苹果App Store_ios在微信浏览器跳转appstore
- 6Ardupilot代码学习笔记
- 7Bert生成句向量(tensorflow)_max_seq_len
- 82023最新AI绘画Midjourney注册使用教程_midjourney 2023 mac
- 9使用YOLOv8和Grad-CAM技术生成图像热图_yolov8 gradcam
- 10jmeter+ant+jenkins进行结合,实现Web HTTP请求的接口自动化测试_jmeter+jenkins+ant的测试报告获取请求接口
【高可用AI推理服务】使用WSL2部署Triton Inference Server推理服务器_triton inference server windows
赞
踩
Triton Inference Server概述
Triton Inference Server(Triton推理服务器)是NVIDIA推出的高性能推理服务器,皆在实现简化ML Ops的工作流程。提供多种可支持的Backend:
- Pytorch
- ONNX
- TensorRT
Triton Inference Sever部署
(以下介绍摘选自NVIDIA NGC官网)
NVIDIA NGC™ 是企业服务、软件、管理工具以及对端到端 AI 和数字孪生工作流支持的门户。 通过完全托管的服务将您的解决方案更快地推向市场,或者利用性能优化的软件在您首选的云、本地和边缘系统上构建和部署您的解决方案。
在本次部署中,我们需要使用NGC来获取我们的API Key,用于验证NGC身份以及docker io的登录。
NGC CLI安装
对于本次部署我们需要使用NGC CLI来进行身份验证,因此我们首先来安装NGC CLI。
通过访问NGC CLI官方配置页面来进行安装,根据自己的操作系统来选择安装,由于我们本次实验的环境是基于WSL2的Ubuntu20.04,因此Tag选择Ubuntu20.04即可。
选择好Tag后按顺序执行Bash指令即可。
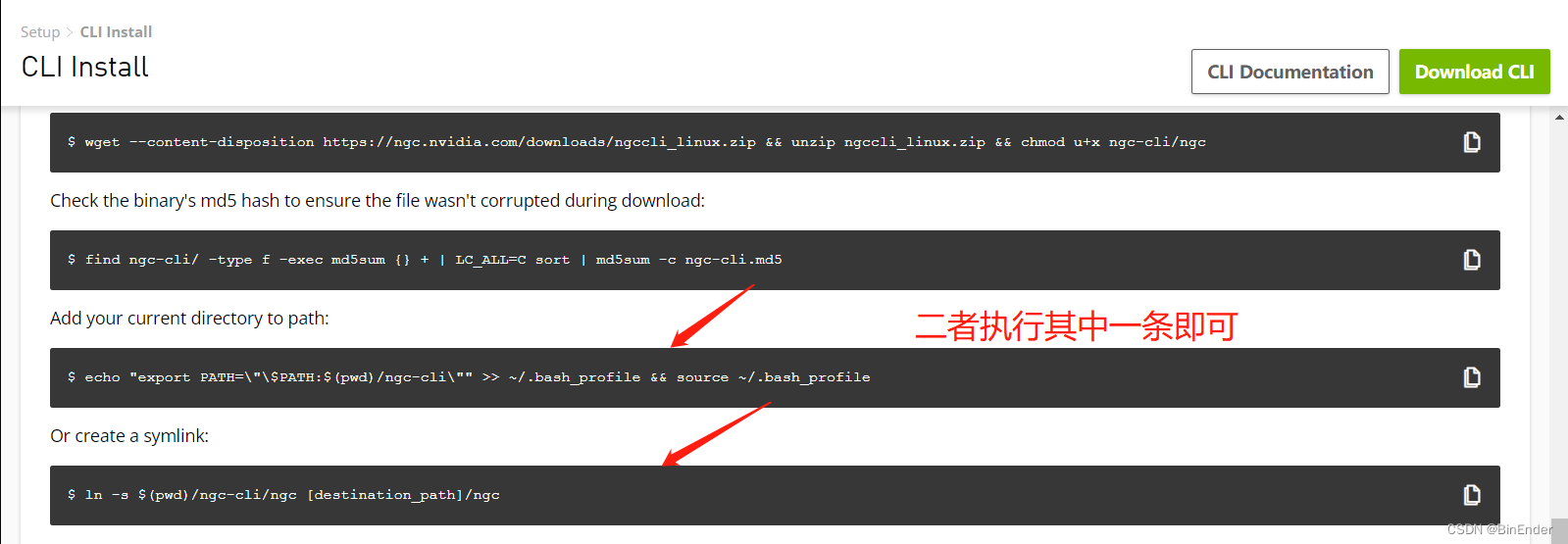
执行好后使用如下指令验证NGC CLI的安装
ngc config set
- 1
配置NGC CLI
当出现Enter API Key字样的时候切换回NGC页面,点击右上角个人头像的下拉菜单(如果没有NGC账号可以注册一个,挺简单的,这里不赘述了),然后点击Set up按钮,应该看到如下的界面
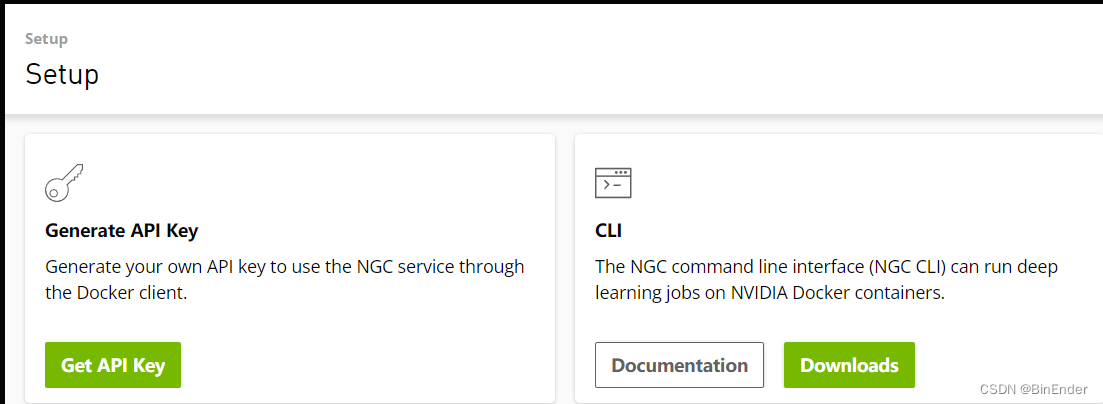
在点击Get API Key按钮来生成您的临时NGC API Key。
进入后点击右上角Genereate API Key按钮生成你的API Key,然后将最下方的API Key复制下来。
复制好后返回到Bash Shell复制API Key后回车。
之后NGC CLI会询问你将以哪种格式输出输出信息,NGC CLI提供了三种方式:
- ascii表格,显示风格和SQL的SELECT 表相似
- csv,标准逗号分割符,看起来很费劲儿
- json,以json格式进行输出,显示的信息也是最全的。
这里我已json进行演示。
之后NGC CLI会设置你的组织和团队,如果您的项目组或企业在NGC上有组织,您可以复制您的组织ID或者团队ID到NGC CLI上,这里默认回车。
配置好后,我们在Bash中输入如下指令:
ngc user who
- 1
之后我们会得到来自NGC服务器响应回来的JSON输出:
"requestStatus": {
"requestId": "443dc477-41c0-4b2e-9373-e5992d31da7e",
"statusCode": "SUCCESS"
},
- 1
- 2
- 3
- 4
当看到statusCode为SUCCESS后,就证明我们的NGC配置成功了。
docker WSL2安装
因为考虑到自己从0编译Triton服务端实在是太费劲了,你会被不计其数的依赖报错(尤其是gRPC)会困扰。所以一步到位,用docker,一劳永逸。
但是又因为众所周知的原因,所以我们需要在Windows上安装Docker Desktop来使得WSL2可以使用Docker CLI以及Docker Daemon等核心组件。
具体操作打开Docker Desktop后,点击右上角齿轮,进入Docker Desktop设置。
点击Resources->WSL Intergration。
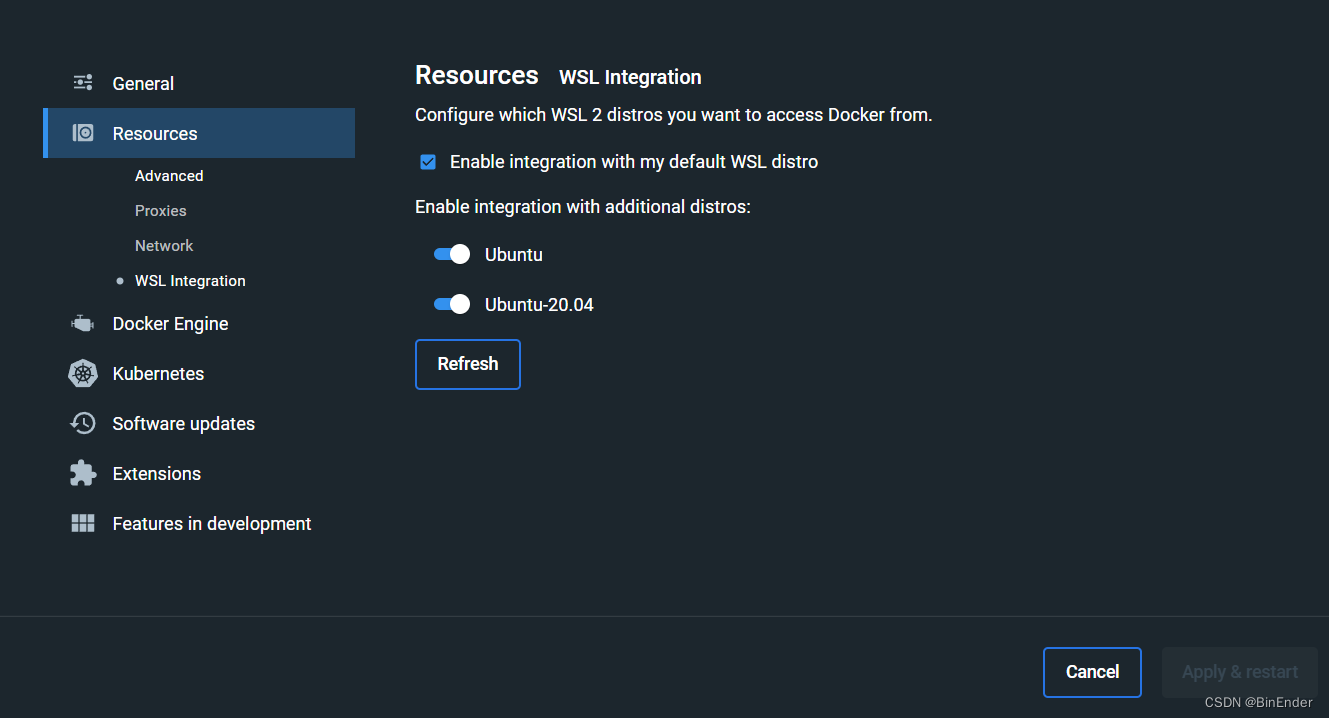
这里我的WSL2虚拟机有两个,因此全部打开了,如果你有多个WSL2虚拟机的docker需求,那就都打开,然后点击Apply & Restart,直到Docker Desktop左下角的状态指示器变成绿色,才能证明docker服务已经正常启动。

这里的RAM并非系统内存,而是你的Docker虚拟机内存,当然这一指标在我们本次的实验中无关紧要,忽略即可。
看到蓝绿色的状态指示灯后,在WSL终端输入
docker --version
- 1
得到如下的输出:
elin@ElinsLaptop:~$ docker --version
Docker version 20.10.22, build 3a2c30b
elin@ElinsLaptop:~$
- 1
- 2
- 3
可以看到,WSL2 Hook完成,但是这并不以为着我们可以直接使用docker pull指令来进行镜像的拉取的。由于NVIDIA的镜像位于nvcr.io这个域名下,而非大家熟悉的docker hub,因此我们需要登录到这个镜像仓库上来完成我们的授权操作。
使用如下指令来进行登录:
docker login nvcr.io
- 1
此时回车会提示你输入用户名和密码,这里用户名输入:$oauthtoken即可,密码则是刚才我们在NGC生成的API Key,点击回车,当docker cli显示Login Sucessed的字样后,我们便可以顺利访问NGC上的镜像列表了。
从NGC拉取镜像
这时我们将浏览器切回到NGC,点击左侧catlog下来菜单->containers按钮,进入到NGC容器列表

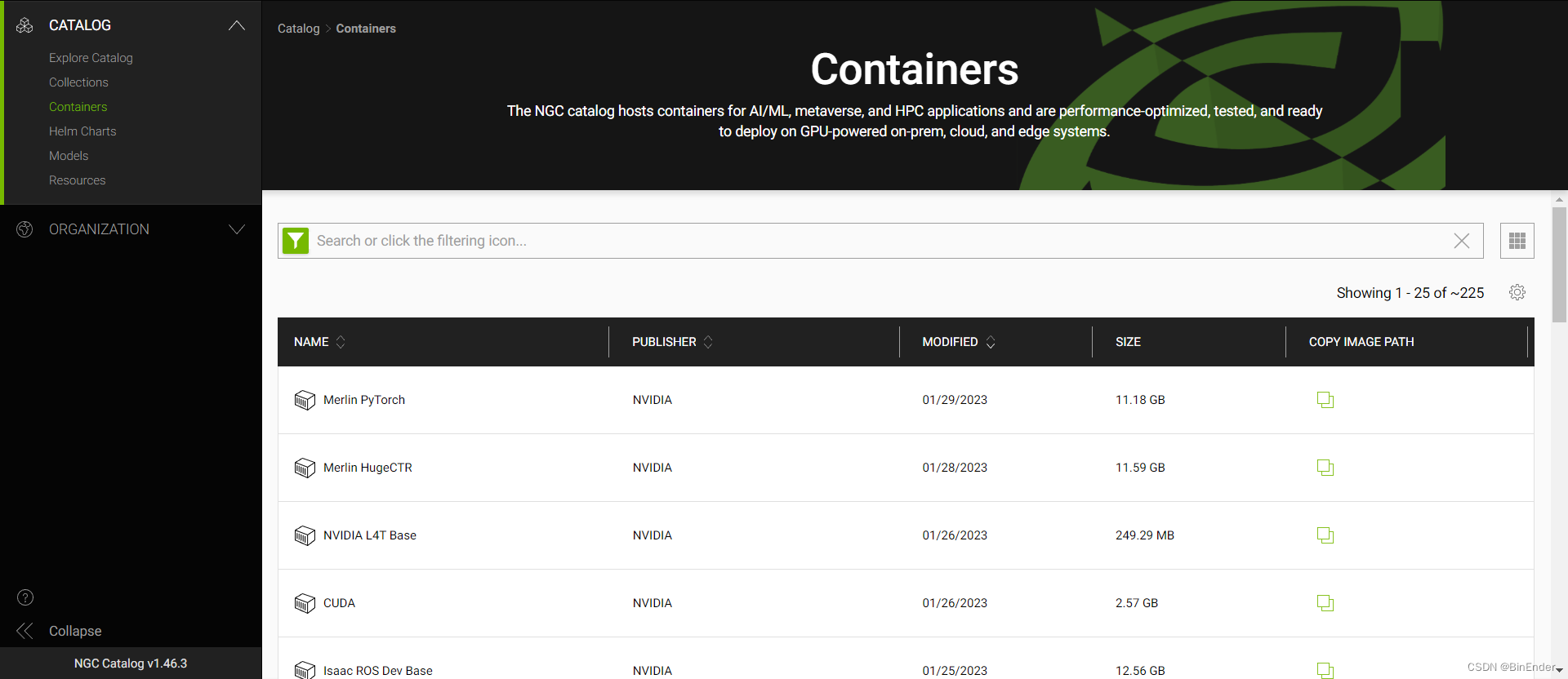
在Filter搜索框中输入Triton后,选择Triton Infercen Server进入该镜像的页面。
进入页面,点击右上角Copy Image Path即可,这里需要注意的是:需要同时拉取22.12-py3和22.12-py3-sdk才能测试您的Triton推理服务器是否启动正确。这里我把两个image的拉取指令放在这里:
docker pull nvcr.io/nvidia/tritonserver:22.12-py3
docker pull nvcr.io/nvidia/tritonserver:22.12-py3-sdk
- 1
- 2
拉取好镜像后,使用docker images list检查本地镜像:
elin@ElinsLaptop:~$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
nvcr.io/nvidia/tritonserver 22.12-py3 20d3e6634cd3 6 weeks ago 14GB
nvcr.io/nvidia/tritonserver 22.12-py3-sdk 2d12690ae145 6 weeks ago 9.63GB
elin@ElinsLaptop:~$
- 1
- 2
- 3
- 4
- 5
同理,由于我们WSL2上的docker是由Docker Desktop Hook上去的,因此在Docker Desktop上亦可以进行查询:

服务启动与验证
在开始验证我们的Triton是否启动正常,没有错误之前,我们需要将Triton Server的github库克隆下来,由于这里已经提前准备好了很多的onnx模型以及测试使用的图片,因此需要用到它:
git clone -b r22.12 https://github.com/triton-inference-server/server.git
- 1
克隆好后,cd到server路径下执行fetch_models.sh,来下载ONNX格式的测试模型。
当这一切全部妥当后,我们cd 到docs/examples路径下执行如下的指令:
docker run --gpus=1 --rm --net=host -v ${PWD}/model_repository:/models nvcr.io/nvidia/tritonserver:22.12-py3 tritonserver --model-repository=/models
- 1
启动项解析
这里我们来解释一下这串容器启动的参数都分别是什么意思:
- run:不用解释了吧,启动容器的意思啊
- -gpus=1:代表是否启动GPU容器,如果该值为0,则Triton将运行在CPU Only模式,此时Triton的吞吐量和单个request的执行延迟会大幅增加,建议在条件允许的情况下默认打开。
- –rm:如果您学习过docker应该不难理解,–rm启动项是指当exit signal(即结束信号量)被docker cli接受到后,docker dameon将不会保留该容器,取而代之是当docker容器停止运行后就地销毁。这对于服务式容器(无需进行内部文件修改的容器)是很友好的,即用即开,生命周期虽然短,但是部署更灵活。
- –net:用于指定docker容器的网络环境,这里指定host即代表该容器的网络环境同步主机。
- -v:代表目录挂载。这里我们将examples下的model_repository目录挂载到了
/models下。 - nvcr.io/nvidia/tritonserver:22.12-py3:代表着我们启动的镜像名
- tritonserver:即代表我们要执行的二进制程序是
tritonserver - –model-repository=/models:这里指定的是Triton Server的启动参数,用于指定模型的仓库位置,由于我们之前将我们宿主机的模型挂载到容器的/models目录下,所以这里写/models就好了
验证可用性
当我们使用上述指令启动Triton Server后,会看到一个模型状态的表格:
+----------------------+---------+--------+
| Model | Version | Status |
+----------------------+---------+--------+
| densenet_onnx | 1 | READY |
| inception_graphdef | 1 | READY |
| simple | 1 | READY |
| simple_dyna_sequence | 1 | READY |
| simple_identity | 1 | READY |
| simple_int8 | 1 | READY |
| simple_sequence | 1 | READY |
| simple_string | 1 | READY |
+----------------------+---------+--------+
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
看到model_repository中的模型状态全部为READY后即可发送推理请求了,值得一提的是:ONNX和TensorRT模型无需为模型单独编写config.pbtxt的配置文件,但是Pytorch和TensorFlow模型则需要config.pbtxt来为Triton指明启动时的执行后端,否则服务将无法启动。
服务器状态验证
我们可以使用curl来获得服务器的GPRC状态:
curl -v localhost:8000/v2/health/ready
- 1
得到如下的返回:
* Trying 127.0.0.1:8000...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8000 (#0)
> GET /v2/health/ready HTTP/1.1
> Host: localhost:8000
> User-Agent: curl/7.68.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Content-Length: 0
< Content-Type: text/plain
<
* Connection #0 to host localhost left intact
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
可以看到我们的返回码是200 OK。
同理使用Postman发送GET请求到该目录也是得到一个状态码为200的空响应:
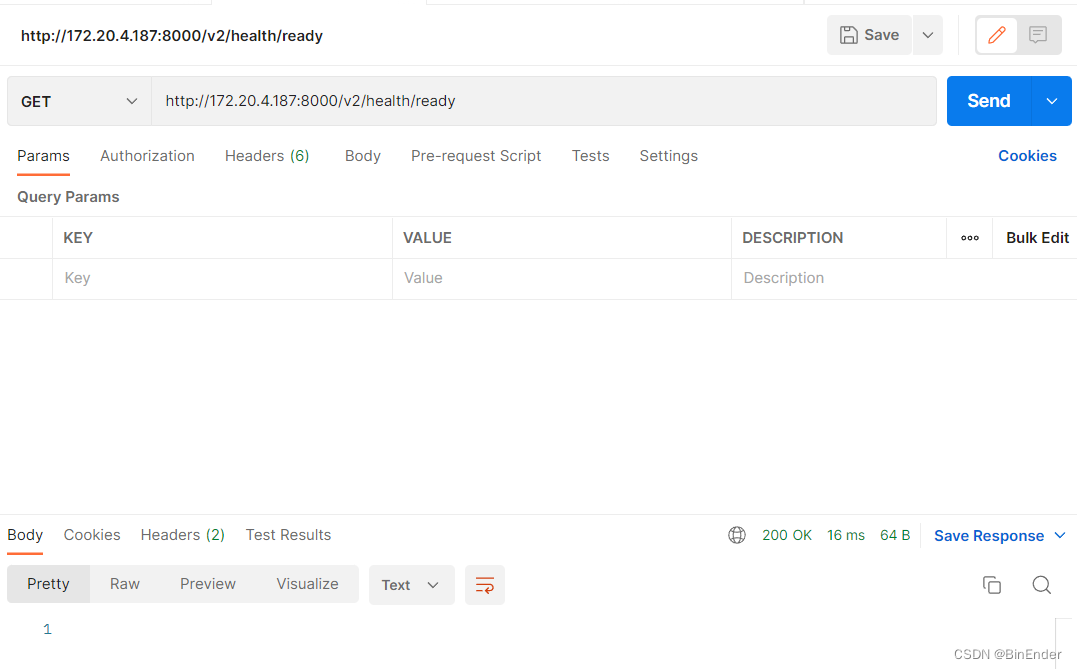
推理服务验证
还记得我们之前pull下来的sdk吗?这时它就派上用场了,使用如下的指令来验证Triton Server的推理服务可用性:
docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:22.12-py3-sdk
/workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpg
- 1
- 2
最后得到了如下的结果:
Image '/workspace/images/mug.jpg':
15.349571 (504) = COFFEE MUG
13.227469 (968) = CUP
10.424896 (505) = COFFEEPOT
- 1
- 2
- 3
- 4
可以看到,Triton Server对我们的推理请求给出了正确的响应,由于我们在启动时使用-c 3指定Triton启动了三个Instance的模型示例,所以返回的结果为3,但是返回的结果都不约而同的指向结果为咖啡杯,所以模型并没有存在异常。
Python API结合
Triton Server为Python和C开发者提供了高可用的Client端API,来与Triton Server之间形成gRPC或者HTTP通信。结合其他的WEB服务器API,如:fast API等,我们就可以构建一个基于Web和GRPC的高可用Web推理服务器了。
结语
Triton Infercen Server极大程度的便利了AI开发者的工作流,通过将模型统一放置在模型仓库内进行统一管理,以及gRPC/HTTP2通信协议,使得Triton在保证了高性能的同时,也有着极强的高可用性和扩展性。
针对如何使用Triton部署自己训练的模型,以及如何编写config.pbtxt和模型结构,我将在过几天的时间后进行补更,喜欢的话记得点赞,收藏加关注哦,下期博客见。

