
BadEncoder: Backdoor Attacks to Pre-trained Encoders in Self-Supervised Learning 论文笔记_aliasing backdoor attacks on pre-trained models
赞
踩
1. 论文信息
| 论文名称 | BadEncoder: Backdoor Attacks to Pre-trained Encoders in Self-Supervised Learning |
|---|---|
| 作者 | Jinyuan Jia∗ Duke University |
| 出版社 | In IEEE Symposium on Security and Privacy, 2022. (信息安全顶会) |
| 在线pdf | |
| 代码 | pytorch |
| 简介 | 首个针对 self-supervised learning 的 backdoor attack. BadEncoder 对预训练模型进行攻击, 通过优化的方法生成带有后门的 image encoder 在两个大型的公开的预训练模型上验证了 BadEncoder 的有效性 |
2. 正文介绍
介绍:
这篇文章是首个针对与训练模型的后门攻击文章。BadEncoder 通过攻击自监督的预训练模型,将后门注入预训练编码器 encoder 中,同时导致下游的模型也继承后门属性。
因此 BadEncoder 需要实现以下两个目标:
- effectiveness goal: 基于 backdoor image encoder 训练的下游分类器,都应该继承了预训练模型的后门。即下游分类器遇上带有 trigger 的样本,也应该将其预测为 target 类。
- utility goal: 后门应该是隐蔽的,具有后门的下游分类器和干净的分类器在干净的数据上测试,应该拥有相同的准确率。
并且还希望,攻击者可以同时攻击多个目标下游任务和每个目标下游任务(target downstream tasks)的多个目标类(target class)。生成带有后门的下游分类器(backdoored downstream classifiers)
威胁模型:
威胁模型(攻击者可以使用的资源),本文的威胁模型如下:
-
攻击者可以访问 reference inputs:
reference inputs: the attacker has access to one or more images (called reference inputs) in the target class for each (target downstream task, target class) pair
目标下游任务中,目标类的一个或多个图像
-
攻击者可以访问 shadow dataset:
对于 shadow dataset,文章中讨论了两种方式:
- 攻击者是预训练模型的发布者,可以访问预训练数据集
- 攻击者是恶意第三方,不能访问训练数据集。攻击者可以从网络中收集一些下类似游任务的数据(不在下游数据集中)。
攻击者无法访问下游分类器的数据,并且无法修改下游分类器的训练过程。
预训练模型
本文主要对两种预训练模型进行攻击 SimCLR 和 CLIP。
-
SimCLR:
ℓ i , j = − log ( exp ( sim ( z i , z j ) / τ ) ∑ k = 1 2 N I ( k ≠ i ) ⋅ exp ( sim ( z i , z k ) / τ ) ) \ell_{i, j}=-\log \left(\frac{\exp \left(\operatorname{sim}\left(\boldsymbol{z}_{i}, \boldsymbol{z}_{j}\right) / \tau\right)}{\sum_{k=1}^{2 N} \mathbb{I}(k \neq i) \cdot \exp \left(\operatorname{sim}\left(\boldsymbol{z}_{i}, \boldsymbol{z}_{k}\right) / \tau\right)}\right) ℓi,j=−log(∑k=12NI(k=i)⋅exp(sim(zi,zk)/τ)exp(sim(zi,zj)/τ))
-
CLIP:
来自论文 《Learning Transferable Visual Models From Natural Language Supervision》
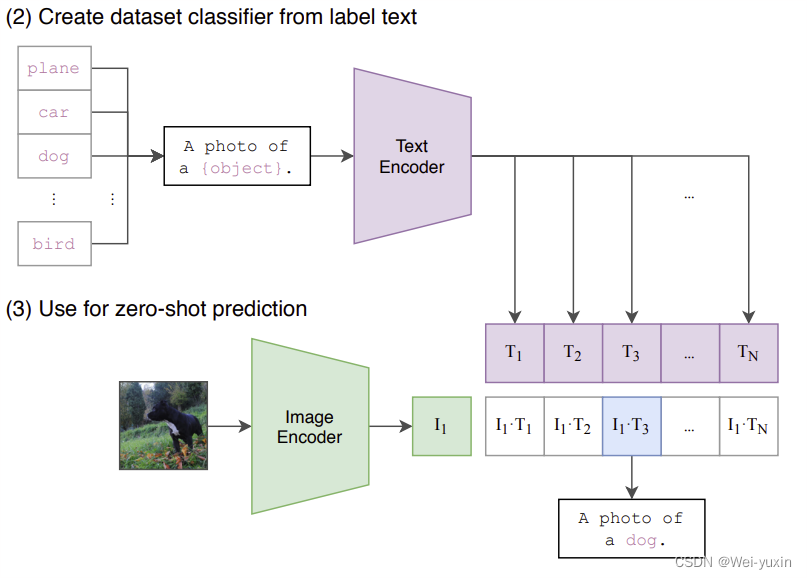
攻击的两种任务分别是:
- Multi-shot classifier: 分类任务,使用预训练编码器生成特征,再使用有监督的方法训练分类器
- Zero-shot classifier: CLIP 因为是图文预训练模型,可以通过构造文本的方式定义标签。通过计算标签(构造的句子)特征和图片特征的相似度进行分类。
3. method
3.1 模型结构图
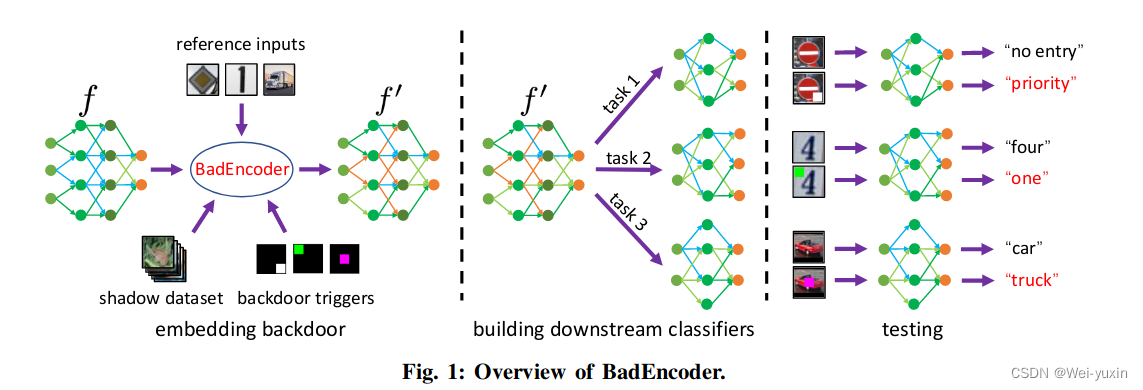
由模型结构图,可以大致看出模型的攻击方式
3.2 损失函数
损失函数一共由三部分组成:
-
Effectiveness loss:
-
shadow dataset 加上 trigger 后经过 backdoored image encoder 生成的特征要和 reference inputs 经过backdoored image encoder 生成的特征相近。
目的:使得带有 trigger 的特征和下游任务中 target 类的特征相近,学习到 backdoor 信息
-
reference inputs 经过 backdoored image encoder 生成的特征要和 reference inputs 经过 clean image encoder 生成的特征相近。
目的:保证下游任务能将 reference inputs 和带有 trigger image 正确分到 target 类。保持 reference inputs 的空间结构
loss function
L 0 = − ∑ i = 1 t ∑ j = 1 r i ∑ x ∈ D s s ( f ′ ( x ⊕ e i ) , f ′ ( x i j ) ) ∣ D s ∣ ⋅ ∑ i = 1 t r i , L 1 = − ∑ i = 1 t ∑ j = 1 r i s ( f ′ ( x i j ) , f ( x i j ) ) ∑ i = 1 t r i ,
L0L1=−∣Ds∣⋅∑i=1tri∑i=1t∑j=1ri∑x∈Dss(f′(x⊕ei),f′(xij)),=−∑i=1tri∑i=1t∑j=1ris(f′(xij),f(xij)),L0L1=−∑ti=1∑rij=1∑x∈Dss(f′(x⊕ei),f′(xij))|Ds|⋅∑ti=1ri,=−∑ti=1∑rij=1s(f′(xij),f(xij))∑ti=1ri, - f f f: clean pre-trained image encoder
- f ′ f^{\prime} f′: backdoored pre-trained image encoder
- reference inputs R i = { x i 1 , x i 2 , ⋯ , x i r i } \mathcal{R}_{i}=\left\{\boldsymbol{x}_{i 1}, \boldsymbol{x}_{i 2}, \cdots, \boldsymbol{x}_{i r_{i}}\right\} Ri={xi1,xi2,⋯,xiri}
- (target downstream task, target class) pair ( T i , y i ) \left(T_{i}, y_{i}\right) (Ti,yi)
- backdoored input x ⊕ e i \boldsymbol{x} \oplus \boldsymbol{e}_{i} x⊕ei
-
-
Utility loss:
loss的作用:使得没有加入 trigger 的 shadow dataset,通过 backdoored image encoder 和 clean image encoder 生成的特征要相近
目的:1. 保证下游任务在干净数据上的分类准确率。2. 对于跨模态预训练模型(CLIP)在 backdoored image encoder 中要保持图像特征和文本特征的关系
loss function
L 2 = − 1 ∣ D s ∣ ⋅ ∑ x ∈ D s s ( f ′ ( x ) , f ( x ) ) L_{2}=-\frac{1}{\left|\mathcal{D}_{s}\right|} \cdot \sum_{\boldsymbol{x} \in \mathcal{D}_{s}} s\left(f^{\prime}(\boldsymbol{x}), f(\boldsymbol{x})\right) L2=−∣Ds∣1⋅∑x∈Dss(f′(x),f(x))
-
Optimization problem:
min f ′ L = L 0 + λ 1 ⋅ L 1 + λ 2 ⋅ L 2 \min _{f^{\prime}} L=L_{0}+\lambda_{1} \cdot L_{1}+\lambda_{2} \cdot L_{2} minf′L=L0+λ1⋅L1+λ2⋅L2,
- 三个 loss 通过超参数平衡
- 参数的选择具体见实验部分
4. experiments
4.1 数据集
CIFAR10,STL10,GTSRB,SVHN,Food101
4.2 评价指标
-
Clean Accuracy (CA): 正常的准确率
-
Backdoored Accuracy (BA): 加入 trigger 后的分类准确率
-
Attack Success Rate (ASR):
ASR:攻击成功率
ASR-B: 正常模型下分错的概率
4.3 实验结果
-
BadEncoder achieves high ASRs:
该实验证明了方法攻击的成功率很高
-
BadEncoder preserves accuracy of the downstream classifiers:
该实验证明了加入后门后,对正确样本的分类准确率并未下降
-
Impact of loss terms:
该实验证明了损失的每一项都是有作用的
-
Impact of shadow dataset:
该实验测试了 shadow dataset 大小对于实验结果的影响,在 shadow dataset 大小为预训练数据集 20% 的时候就能取得不错的结果
-
Impact of trigger size:
不同大小的 trigger 都能取得不错的攻击效果,并且 trigger size 不会对 正常分类造成影响
-
Multiple reference inputs:
对于一个 target 类选不同类型的 reference inputs 进行测试,只要至少有一类 reference inputs 是正确的模型就能取得效果
不同类型例如:
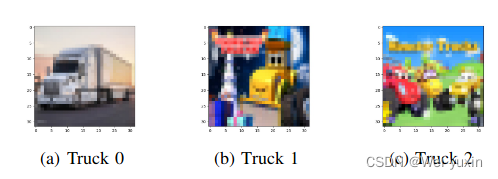
-
Impact of other parameters:
验证其他参数,学习率等对结果的影响

