
- 1iOS Runtime原理及使用
- 2数据结构 第三章 线性表(三)
- 3【刷题】备战蓝桥杯 — dfs 算法
- 4Elasticsearch文档内部的父子关系_elasticsearch父子关系
- 5MySQL5种索引类型_mysql 索引类型
- 63DGS(3D Guassian Splatting)部署验证+个人数据训练
- 7MindManager2023中文版本思维导图_mindmanager 2023 license key
- 8OpenCV+Cuda+Cmake+VStudio配置踩坑记录_cmake --help-policy cmp0148
- 9Git和GitHub资料汇总_github buct资料
- 10音频调试(2)
基于YOLOV8检测和OCR识别的车牌识别_yolo ocr
赞
踩
一、简介
基于YOLOv8和OCR的车牌号码识别是一种结合了目标检测和光学字符识别技术的车牌识别方法。YOLOv8(You Only Look Once version 8)是一种实时目标检测算法,可以快速准确地检测图像中的物体,如车辆、行人等。OCR(Optical Character Recognition)是一种光学字符识别技术,可以将图像中的文本转换为计算机可编辑的文本数据。
二、实现
2.1 数据集
数据集用中科大团队建立了CCPD数据集,截取了其中的5500张图,分别有5000张base、100张ccpd_fn(增加了噪声)、100张ccpd_db(模糊图片) 、100张(增加了旋转)ccpd_rotate、 100张(不同天气)ccpd_weather、100张(增加了模糊度)ccpd_blur。
2.1.1 数据格式
图片名的标注:
00245450191571-90_90-276&480_370&520-364&524_274&519_275&486_365&491-0_0_30_29_10_30_26-80-16.jpg 由分隔符‘-’分为以下几个部分:
1)00245450191571:表示区域
2)90_90:表示两个角度,水平90和竖直90
3)276&480_370&520:表示边界框的坐标左上(276,480)右下(370,520)
4)364&524_274&519_275&486_365&491 对应车牌的4个顶点
5)0_0_30_29_10_30_26:表示车牌号,第一个0表示省份,第二个0表示市,后面5位表示车牌号码
6)80:表示亮度
7)16:表示模糊度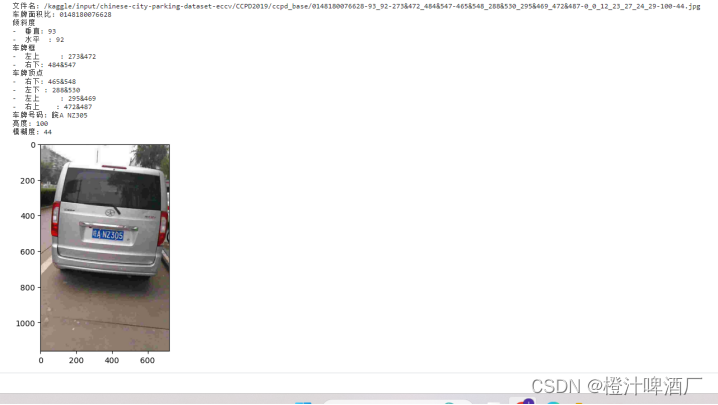
# Image Description ccpd_base_path = os.path.join(BASE_PATH, "ccpd_base") ccpd_base_files = os.listdir(ccpd_base_path) for file in ccpd_base_files[:3]: # File Name file_name = os.path.join(ccpd_base_path, file) file_splitting = file_name.split("/")[-1][:-4] file_splitting = file_splitting.split("-") print("文件名:", file_name) # Area Ratio area_ratio = file_splitting[0] print("车牌面积比:", area_ratio) # Tilt Degrees tilt_degrees = file_splitting[1] hor_tilt_degrees = tilt_degrees.split("_")[0] ver_tilt_degrees = tilt_degrees.split("_")[1] print("倾斜度") print("- 垂直:", hor_tilt_degrees) print("- 水平 :", ver_tilt_degrees) # Bounding Box bounding_box = file_splitting[2] left_up_bbox = bounding_box.split("_")[0] right_bot_bbox = bounding_box.split("_")[1] print("车牌框") print("- 左上 :", left_up_bbox) print("- 右下:", right_bot_bbox) # Exact Vertices vertices = file_splitting[3] right_bot_vtc = vertices.split("_")[0] left_bot_vtc = vertices.split("_")[1] left_up_vtc = vertices.split("_")[2] right_up_vtc = vertices.split("_")[3] print("车牌顶点") print("- 右下:", right_bot_vtc) print("- 左下 :", left_bot_vtc) print("- 左上 :", left_up_vtc) print("- 右上 :", right_up_vtc) # License Plate Numbers lcn = file_splitting[4] chi_let = provinces[int(lcn.split("_")[0])] alp_let = alphabets[int(lcn.split("_")[1])] alp_num_let = lcn.split("_")[2:] alp_num_let = "".join([ads[int(char)] for char in alp_num_let]) all_let = chi_let + alp_let + " " + alp_num_let print("车牌号码:", all_let) # Brightness brightness = file_splitting[5] print("亮度:", brightness) # Blurriness blurriness = file_splitting[6] print("模糊度:", blurriness) img = cv2.imread(file_name) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) plt.imshow(img) plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
2.2数据的预处理
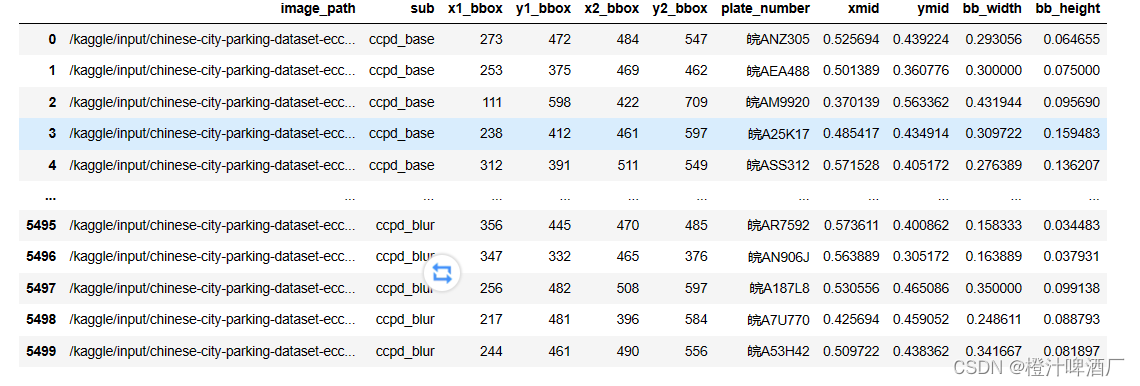
1.定义一个名为extract_plate_number的函数,用于从给定的车牌号码字符串中提取省份、字母和数字信息,并将它们组合成一个完整的车牌号码。
2.创建一个空的DataFrame,用于存储元数据。
3.遍历list_sub列表中的每个子文件夹,获取子文件夹中的所有文件路径,并将这些路径添加到df_metadata中。
4.重命名df_metadata的列名,并重置索引。
5.从文件路径中提取子文件夹名称和详细信息,并将它们分别存储在"sub"和"detail"列中。
6.从详细信息中提取车牌框的位置信息,并将它们分别存储在"x1_bbox"、“y1_bbox”、"x2_bbox"和"y2_bbox"列中。
7.从详细信息中提取车牌号码信息,并使用extract_plate_number函数将其转换为完整的车牌号码,然后将结果存储在"plate_number"列中。
8.删除"detail"和"bbox"列,以简化DataFrame的结构。
9.计算车牌框的中心点坐标(xmid, ymid),以及车牌框的宽度和高度(bb_width, bb_height)。
def extract_plate_number(plate_number): chi_let = provinces[int(plate_number.split("_")[0])] alp_let = alphabets[int(plate_number.split("_")[1])] alp_num_let = plate_number.split("_")[2:] alp_num_let = "".join([ads[int(char)] for char in alp_num_let]) all_let = chi_let + alp_let + alp_num_let return all_let df_metadata = pd.DataFrame() for sub in list_sub: sub_path = os.path.join(BASE_PATH, sub, "*") sub_files = glob.glob(sub_path) df_metadata = df_metadata.append(sub_files) df_metadata = df_metadata.rename(columns={0: "image_path"}).reset_index(drop=True) df_metadata["sub"] = df_metadata["image_path"].apply(lambda x: x.split("/")[5]) df_metadata["detail"] = df_metadata["image_path"].apply(lambda x: x.split("/")[6]) df_metadata["bbox"] = df_metadata["detail"].apply(lambda x: x.split("-")[2]) df_metadata["x1_bbox"] = df_metadata["bbox"].apply(lambda x: int(x.split("_")[0].split("&")[0])) df_metadata["y1_bbox"] = df_metadata["bbox"].apply(lambda x: int(x.split("_")[0].split("&")[1])) df_metadata["x2_bbox"] = df_metadata["bbox"].apply(lambda x: int(x.split("_")[1].split("&")[0])) df_metadata["y2_bbox"] = df_metadata["bbox"].apply(lambda x: int(x.split("_")[1].split("&")[1])) df_metadata["plate_number"] = df_metadata["detail"].apply(lambda x: x.split("-")[4]) df_metadata["plate_number"] = df_metadata["plate_number"].apply(lambda x: extract_plate_number(x)) df_metadata = df_metadata.drop(["detail", "bbox"], axis=1) df_metadata df_metadata['xmid'] = (df_metadata['x1_bbox'] + df_metadata['x2_bbox']) / (2*720) df_metadata['ymid'] = (df_metadata['y1_bbox'] + df_metadata['y2_bbox']) / (2*1160) df_metadata['bb_width'] = (df_metadata['x2_bbox'] - df_metadata['x1_bbox']) / 720 df_metadata['bb_height'] = (df_metadata['y2_bbox'] - df_metadata['y1_bbox']) / 1160 df_metadata
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
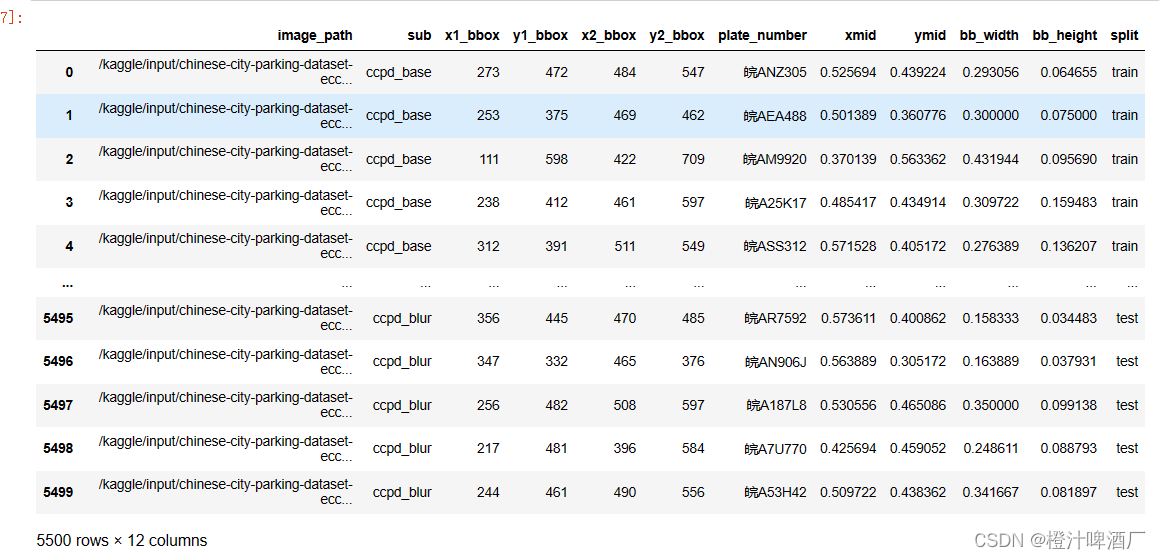
2.3划分数据集
# 训练集为5000 测试为250 val为250
list_split = ["train"] * 5000
for i in range(5):
list_split.extend(["val"]*50)
list_split.extend(["test"]*50)
df_metadata["split"] = list_split
df_metadata
- 1
- 2
- 3
- 4
- 5
- 6
- 7
三、YOLOV8 检测
3.1加载YOLOV8模型
!git clone https://github.com/ultralytics/ultralytics
!pip install ultralytics
- 1
- 2
3.2创建YOLOV8可训练的数据
#将图片和text文本加载进目标目录中 def image_and_text_yolo(split): df = df_metadata[df_metadata["split"]==split].reset_index(drop=True) folder_path = os.path.join("/kaggle/working/ultralytics/datasets", split) values = df[['image_path','xmid','ymid','bb_width','bb_height']].values for file_name, x, y, w, h in values: image_name = os.path.split(file_name)[-1] txt_name = os.path.splitext(image_name)[0] dst_image_path = os.path.join(folder_path, image_name) dst_label_file = os.path.join(folder_path, txt_name+'.txt') # copy each image into the folder shutil.copy(file_name, dst_image_path) # generate .txt which has label info label_txt = f'0 {x} {y} {w} {h}' with open(dst_label_file, mode='w') as f: f.write(label_txt) f.close() image_and_text_yolo("train") print("创建训练集") image_and_text_yolo("val") print("创建验证集") image_and_text_yolo("test") print("创建测试集") #将要训练的图片写入到yaml中 %%writefile /kaggle/working/ultralytics/custom_dataset.yaml #创建自定义数据集配置 train: /kaggle/working/ultralytics/datasets/train val: /kaggle/working/ultralytics/datasets/val test: /kaggle/working/ultralytics/datasets/test nc: 1 names: [ 'license_plate' ]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
3.3YOLOV8的训练
3.3.1GPU使用情况
!pip install GPUtil from GPUtil import showUtilization as gpu_usage def free_gpu_cache(): print("初始 GPU 使用情况") gpu_usage() torch.cuda.empty_cache() cuda.select_device(0) cuda.close() cuda.select_device(0) print("清空缓存后的 GPU 使用情况") gpu_usage() free_gpu_cache()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
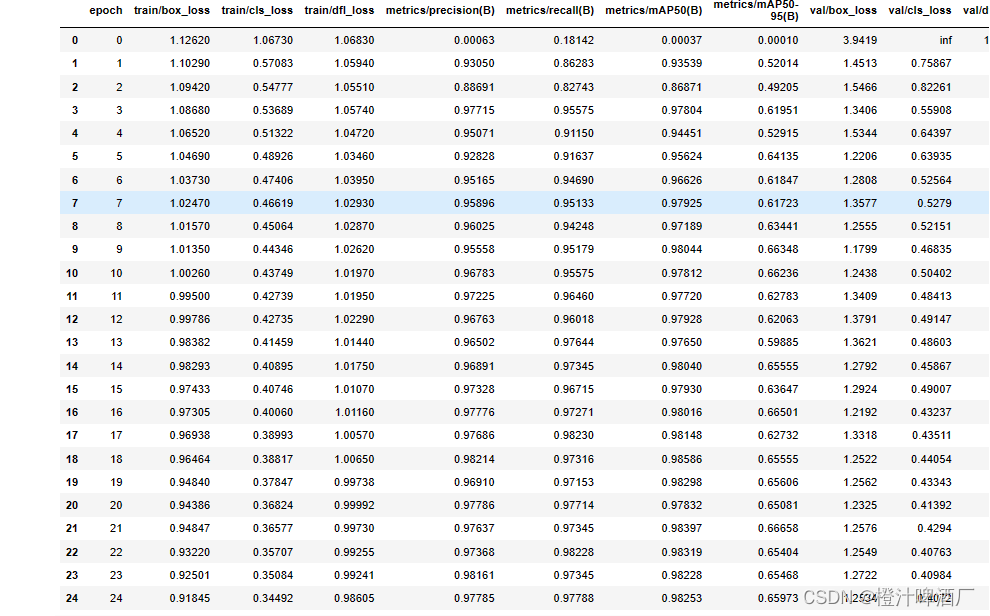
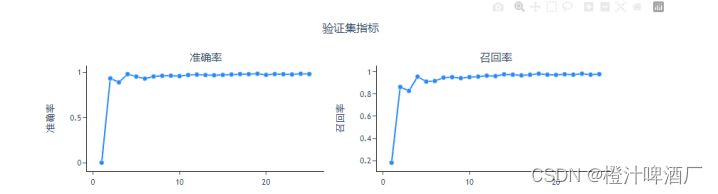
3.3.2性能指标
mAP50达到了0.978,说明检测的效果还是可以的。
四、OCR识别
4.1加载OCR并获取文本
!pip install cnocr from cnocr import CnOcr def get_text_cnocr(idx): ori_path = df_results["image_path"][idx] ori_image = cv2.imread(ori_path) ori_image = cv2.cvtColor(ori_image, cv2.COLOR_BGR2RGB) cnocr_model = CnOcr() text_list = [] bboxs = df_results["pred_bbox"][idx] for bbox in bboxs: # Crop Image with Bounding Box crop_image = ori_image[bbox[1]:bbox[3], bbox[0]:bbox[2]] # Extract Plate Number text_output = cnocr_model.ocr(crop_image) if(len(text_output)>0): text = text_output[0]["text"] # Clean Text del_punc_list = [" ", "·", ":", "-"] clean_text = re.sub(r"[ ·:-]", "", text) clean_text = clean_text.replace("O", "0") clean_text = clean_text.replace("I", "1") clean_text = clean_text.upper() text_list.append(clean_text) return text_list
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
4.2识别后的效果
%matplotlib inline
idxs = [random.randint(0, 250) for _ in range(3)]
for idx in idxs:
print("\n")
print("检测后的车牌框")
show_plate_detection(idx)
print("检测后的图片")
text_ocr = get_text_cnocr(idx)
print("识别后的车牌号",text_ocr)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10




