
- 1SpringBoot 通过AOP + Redis 防止表单重复提交_.netcore aop防止表单重复提交
- 2大数据算法系列3:基本数据结构及应用_大数据中的算法具体应用
- 3AI软件工程师闪亮登场,程序员是否心生危机呢?
- 4springboot失踪人口寻找互助信息系统m4685[独有源码]如何选择高质量的计算机毕业设计_失踪人口寻找互助信息系统毕业设计
- 5Data-Copilot: 大语言模型做你最贴心省事的数据助手
- 6数据分析在人力资源管理中的应用:提高员工满意度和绩效
- 7数据可视化项目
- 8rabbitmq 手动提交_springboot-rabbitmq
- 9【机器学习】机器学习学习笔记 - 无监督学习 - k-means/均值漂移聚类/凝聚层次聚类/近邻传播聚类 - 05
- 10通俗理解CTF网络安全比赛_ctf网络安全大赛
【Dify知识库】(10):Dify0.4.9改造支持MySQL,成功接入通义千问-7B-Chat-Int4做对话,本地使用fastchat启动,占6G显存,可以成功配置LLM和 embedding_qwen2.0 dify
赞
踩
0,视频地址
https://www.bilibili.com/video/BV1ia4y1y7VM/?vd_source=4b290247452adda4e56d84b659b0c8a2
【Dify知识库】(10):Dify0.4.9版本,支持MySQL,成功接入通义千问-7B-Chat-Int4做对话,本地使用fastchat启动,占6G显存
项目地址:
https://gitee.com/fly-llm/dify-mysql-llm
1,关于qwen7b 大模型
项目地址:https://www.modelscope.cn/models/qwen/Qwen-7B-Chat/summary
介绍(Introduction)
**通义千问-7B(Qwen-7B)**是阿里云研发的通义千问大模型系列的70亿参数规模的模型。Qwen-7B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在Qwen-7B的基础上,我们使用对齐机制打造了基于大语言模型的AI助手Qwen-7B-Chat。相较于最初开源的Qwen-7B模型,我们现已将预训练模型和Chat模型更新到效果更优的版本。本仓库为Qwen-7B-Chat的仓库。
下载完成:
18G Qwen-7B-Chat
然后会执行git解压缩:
29G Qwen-7B-Chat
- 1
- 2
- 3
- 4
2,下载项目,但是发现11G的显存运行不了,选择int4版本的
2024-01-20 02:03:36 | INFO | stdout | Loading GPTQ quantized model…
2024-01-20 02:03:36 | INFO | stdout | Error: Failed to load GPTQ-for-LLaMa. No module named ‘llama’
2024-01-20 02:03:36 | INFO | stdout | See https://github.com/lm-sys/FastChat/blob/main/docs/gptq.md
2024-01-20 02:01:09 | ERROR | stderr | [–worker-address WORKER_ADDRESS]
2024-01-20 02:01:09 | ERROR | stderr | [–controller-address CONTROLLER_ADDRESS]
2024-01-20 02:01:09 | ERROR | stderr | [–model-path MODEL_PATH] [–revision REVISION]
2024-01-20 02:01:09 | ERROR | stderr | [–device {cpu,cuda,mps,xpu,npu}] [–gpus GPUS]
2024-01-20 02:01:09 | ERROR | stderr | [–num-gpus NUM_GPUS] [–max-gpu-memory MAX_GPU_MEMORY]
2024-01-20 02:01:09 | ERROR | stderr | [–dtype {float32,float16,bfloat16}] [–load-8bit]
2024-01-20 02:01:09 | ERROR | stderr | [–cpu-offloading] [–gptq-ckpt GPTQ_CKPT]
2024-01-20 02:01:09 | ERROR | stderr | [–gptq-wbits {2,3,4,8,16}]
2024-01-20 02:01:09 | ERROR | stderr | [–gptq-groupsize GPTQ_GROUPSIZE] [–gptq-act-order]
2024-01-20 02:01:09 | ERROR | stderr | [–awq-ckpt AWQ_CKPT] [–awq-wbits {4,16}]
2024-01-20 02:01:09 | ERROR | stderr | [–awq-groupsize AWQ_GROUPSIZE] [–enable-exllama]
2024-01-20 02:01:09 | ERROR | stderr | [–exllama-max-seq-len EXLLAMA_MAX_SEQ_LEN]
2024-01-20 02:01:09 | ERROR | stderr | [–exllama-gpu-split EXLLAMA_GPU_SPLIT]
2024-01-20 02:01:09 | ERROR | stderr | [–exllama-cache-8bit] [–enable-xft]
2024-01-20 02:01:09 | ERROR | stderr | [–xft-max-seq-len XFT_MAX_SEQ_LEN]
2024-01-20 02:01:09 | ERROR | stderr | [–xft-dtype {fp16,bf16,int8,bf16_fp16,bf16_int8}]
2024-01-20 02:01:09 | ERROR | stderr | [–model-names MODEL_NAMES]
2024-01-20 02:01:09 | ERROR | stderr | [–conv-template CONV_TEMPLATE] [–embed-in-truncate]
2024-01-20 02:01:09 | ERROR | stderr | [–limit-worker-concurrency LIMIT_WORKER_CONCURRENCY]
2024-01-20 02:01:09 | ERROR | stderr | [–stream-interval STREAM_INTERVAL] [–no-register]
2024-01-20 02:01:09 | ERROR | stderr | [–seed SEED] [–debug DEBUG] [–ssl]
2024-01-20 02:05:38 | INFO | stdout | Loading AWQ quantized model…
2024-01-20 02:05:38 | INFO | stdout | Error: Failed to import tinychat. No module named ‘tinychat’
2024-01-20 02:05:38 | INFO | stdout | Please double check if you have successfully installed AWQ
2024-01-20 02:05:38 | INFO | stdout | See https://github.com/lm-sys/FastChat/blob/main/docs/awq.md
同时需要安装 einops transformers_stream_generator auto-gptq optimum
这些库才可以启动成功
3,启动成功
https://github.com/QwenLM/Qwen/issues/385
"disable_exllama": true,
- 1
执行 shell 替换字符串:
sed -i 's/"gptq"/"gptq","disable_exllama": true/g' Qwen-7B-Chat-Int4/config.json
- 1
最后启动成功:
2024-01-20 03:15:08 | INFO | model_worker | args: Namespace(host='0.0.0.0', port=8001, worker_address='http://fastchat-worker-llm:8001', controller_address='http://fastchat-controller:21001', model_path='/data/models/Qwen-7B-Chat-Int4', revision='main', device='cuda', gpus=None, num_gpus=1, max_gpu_memory=None, dtype=None, load_8bit=False, cpu_offloading=False, gptq_ckpt=None, gptq_wbits=16, gptq_groupsize=-1, gptq_act_order=False, awq_ckpt=None, awq_wbits=16, awq_groupsize=-1, enable_exllama=False, exllama_max_seq_len=4096, exllama_gpu_split=None, exllama_cache_8bit=False, enable_xft=False, xft_max_seq_len=4096, xft_dtype=None, model_names=['Qwen-7B-Chat', 'gpt-3.5-turbo-0613', 'gpt-3.5-turbo', 'gpt-3.5-turbo-instruct', 'gpt-35-turbo'], conv_template=None, embed_in_truncate=False, limit_worker_concurrency=5, stream_interval=2, no_register=False, seed=None, debug=False, ssl=False)
2024-01-20 03:15:08 | INFO | model_worker | Loading the model ['Qwen-7B-Chat', 'gpt-3.5-turbo-0613', 'gpt-3.5-turbo', 'gpt-3.5-turbo-instruct', 'gpt-35-turbo'] on worker 7fc2703b ...
2024-01-20 03:15:08 | INFO | datasets | PyTorch version 2.1.0 available.
Using `disable_exllama` is deprecated and will be removed in version 4.37. Use `use_exllama` instead and specify the version with `exllama_config`.The value of `use_exllama` will be overwritten by `disable_exllama` passed in `GPTQConfig` or stored in your config file.
2024-01-20 03:15:09 | WARNING | transformers_modules.Qwen-7B-Chat-Int4.modeling_qwen | Your device does NOT support faster inference with fp16, please switch to fp32 which is likely to be faster
2024-01-20 03:15:09 | WARNING | transformers_modules.Qwen-7B-Chat-Int4.modeling_qwen | Try importing flash-attention for faster inference...
2024-01-20 03:15:09 | WARNING | transformers_modules.Qwen-7B-Chat-Int4.modeling_qwen | Warning: import flash_attn rotary fail, please install FlashAttention rotary to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/rotary
2024-01-20 03:15:09 | WARNING | transformers_modules.Qwen-7B-Chat-Int4.modeling_qwen | Warning: import flash_attn rms_norm fail, please install FlashAttention layer_norm to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/layer_norm
2024-01-20 03:15:09 | WARNING | transformers_modules.Qwen-7B-Chat-Int4.modeling_qwen | Warning: import flash_attn fail, please install FlashAttention to get higher efficiency https://github.com/Dao-AILab/flash-attention
Loading checkpoint shards: 0%| | 0/3 [00:00<?, ?it/s]
Loading checkpoint shards: 33%|███▎ | 1/3 [00:00<00:00, 9.35it/s]
Loading checkpoint shards: 67%|██████▋ | 2/3 [00:00<00:00, 8.40it/s]
Loading checkpoint shards: 100%|██████████| 3/3 [00:00<00:00, 8.89it/s]
Loading checkpoint shards: 100%|██████████| 3/3 [00:00<00:00, 8.84it/s]
2024-01-20 03:15:10 | ERROR | stderr |
2024-01-20 03:15:29 | INFO | model_worker | Register to controller
2024-01-20 03:15:29 | ERROR | stderr | INFO: Started server process [1]
2024-01-20 03:15:29 | ERROR | stderr | INFO: Waiting for application startup.
2024-01-20 03:15:29 | ERROR | stderr | INFO: Application startup complete.
2024-01-20 03:15:29 | ERROR | stderr | INFO: Uvicorn running on http://0.0.0.0:8001 (Press CTRL+C to quit)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
然后测试接口:
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "gpt-35-turbo",
"messages": [{"role": "user", "content": "你是谁"}],
"temperature": 0.7
}'
# 返回json :
{"id":"chatcmpl-AFGZMvdyKCGLwRNmtgWWeu","object":"chat.completion","created":1705761576,"model":"gpt-35-turbo","choices":[{"index":0,"message":{"role":"assistant","content":"我是通义千问,由阿里云开发的AI预训练模型。我被设计成可以回答各种问题、提供信息和与用户进行对话的模型。我可以帮助您查找各种问题的答案,提供定义、解释和建议,将文本从一种语言翻译成另一种语言,总结文本,生成文本,写故事,分析情绪,提供建议,开发算法,编写代码等。如果您有任何问题,请随时告诉我,我会尽力帮助您。"},"finish_reason":"stop"}],"usage":{"prompt_tokens":20,"total_tokens":116,"completion_tokens":96}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4,然后启动 dify 0.4.9 版本,添加 OpenAI-API-compatible 兼容接口
就而可以创建应用配置模型:
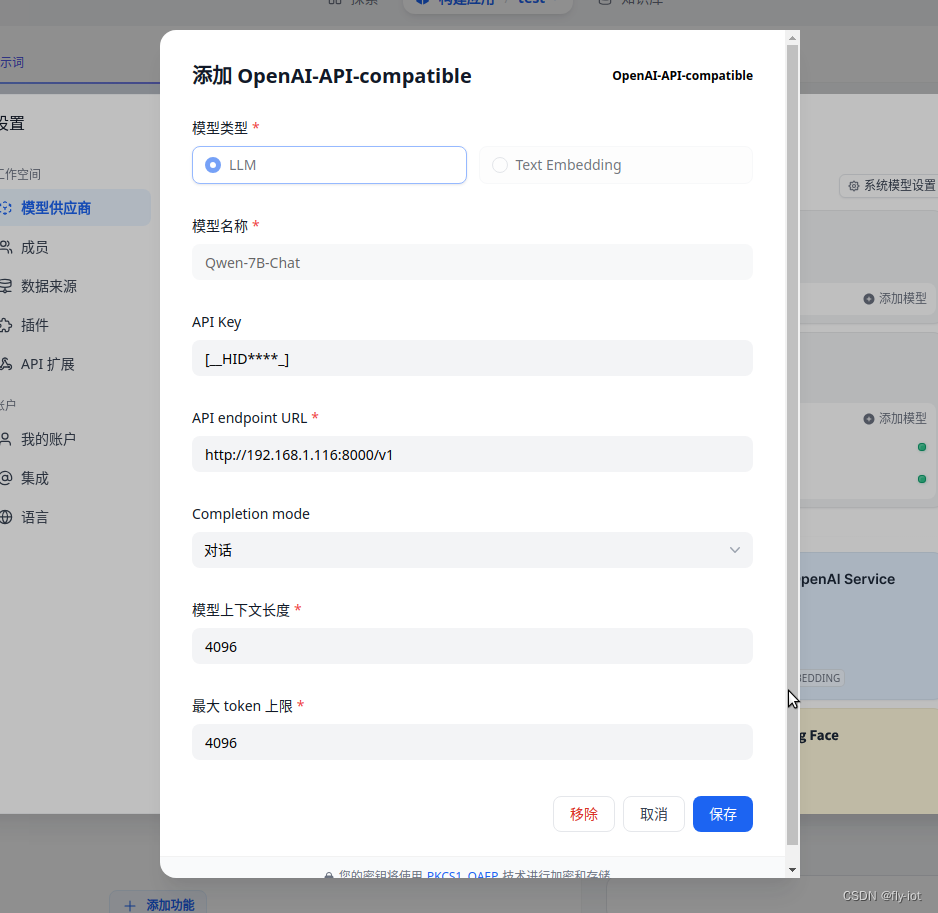
特别注意选择的是本地模型 ,服务器地址是 自己的电脑
但是不要增加 /v1/chat/completions 路径,会自动添加。
embedding 也可以添加成功:
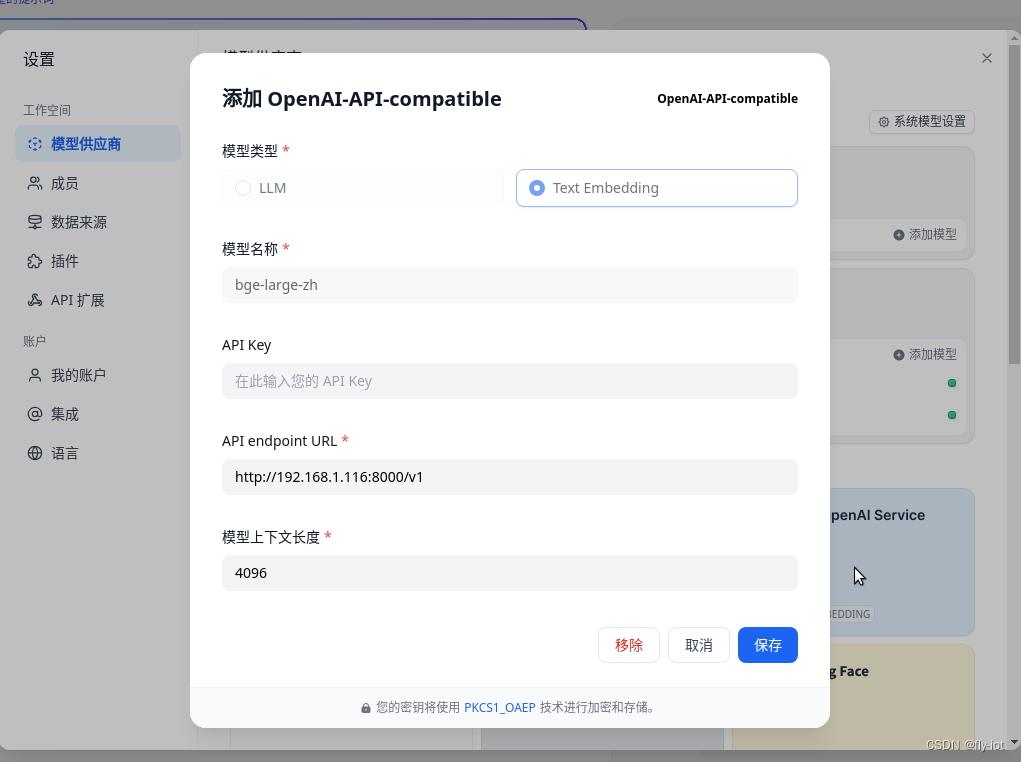
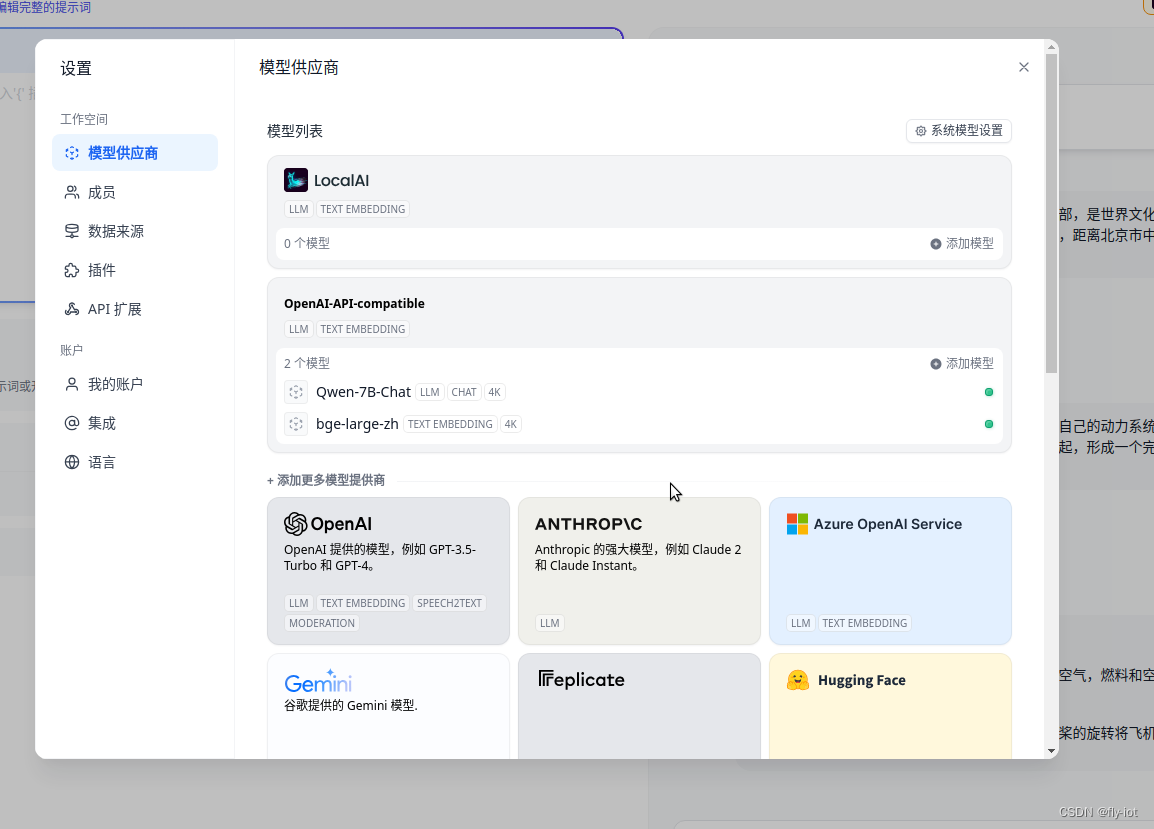
然后就可以对话聊天和配置向量库了。
5,进行对话聊天和向量库的使用
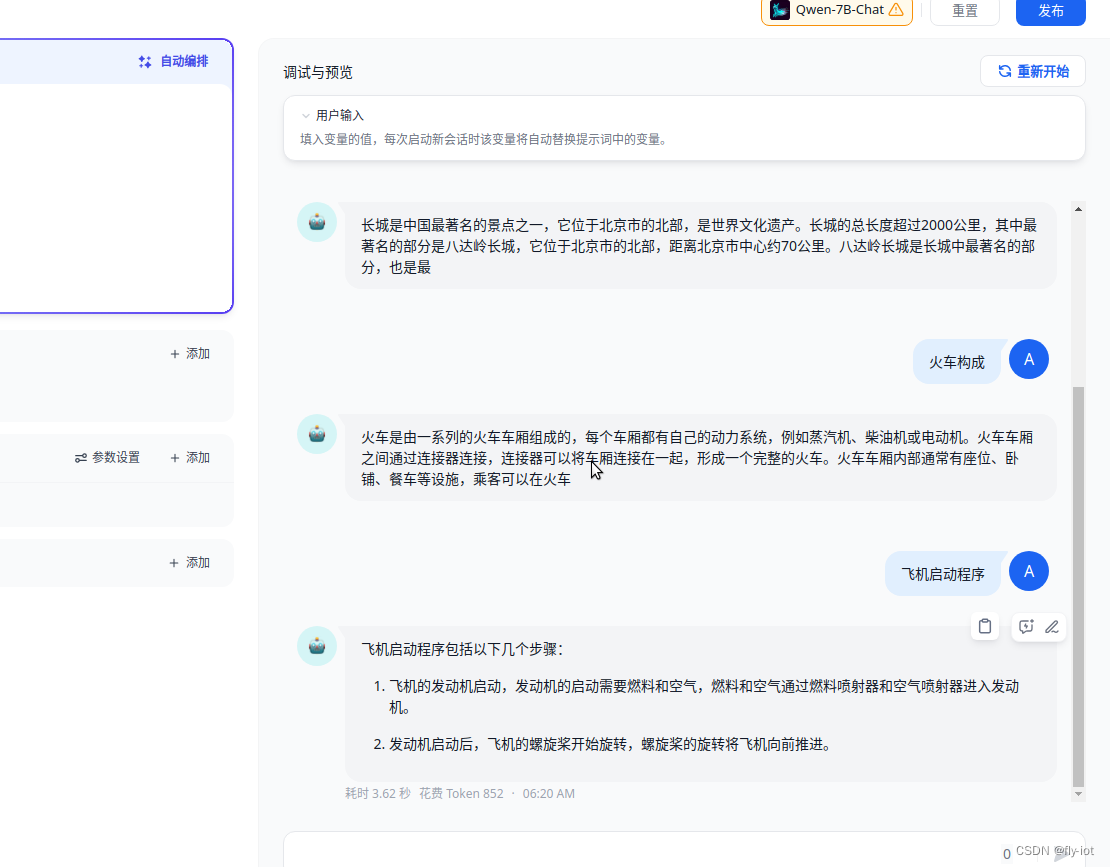
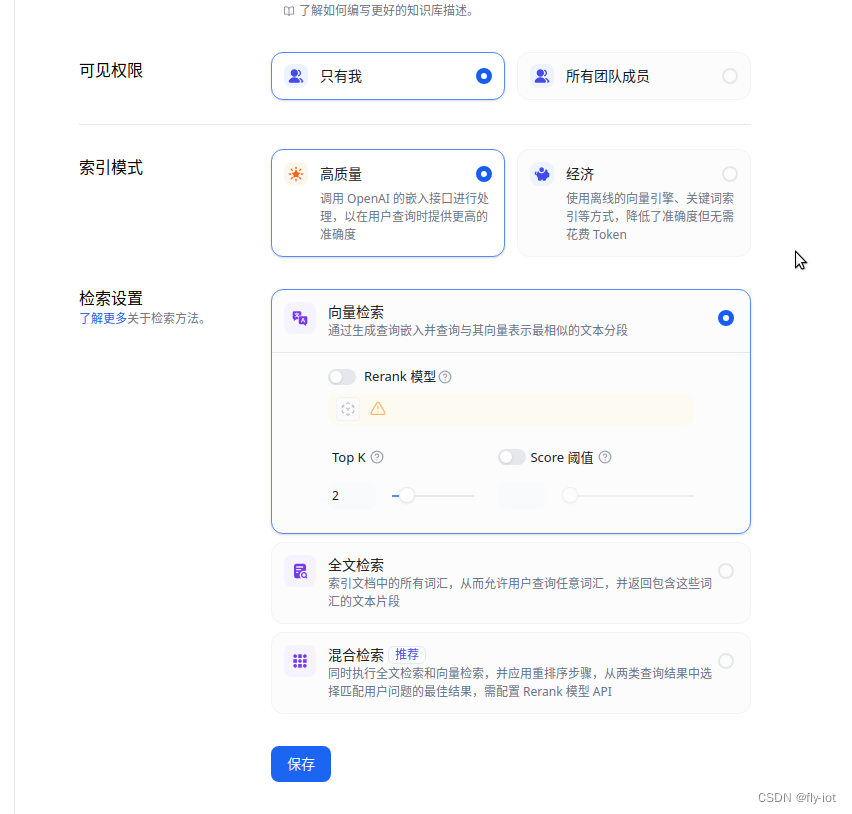
然后就可以配置成功 使用向量索引了。
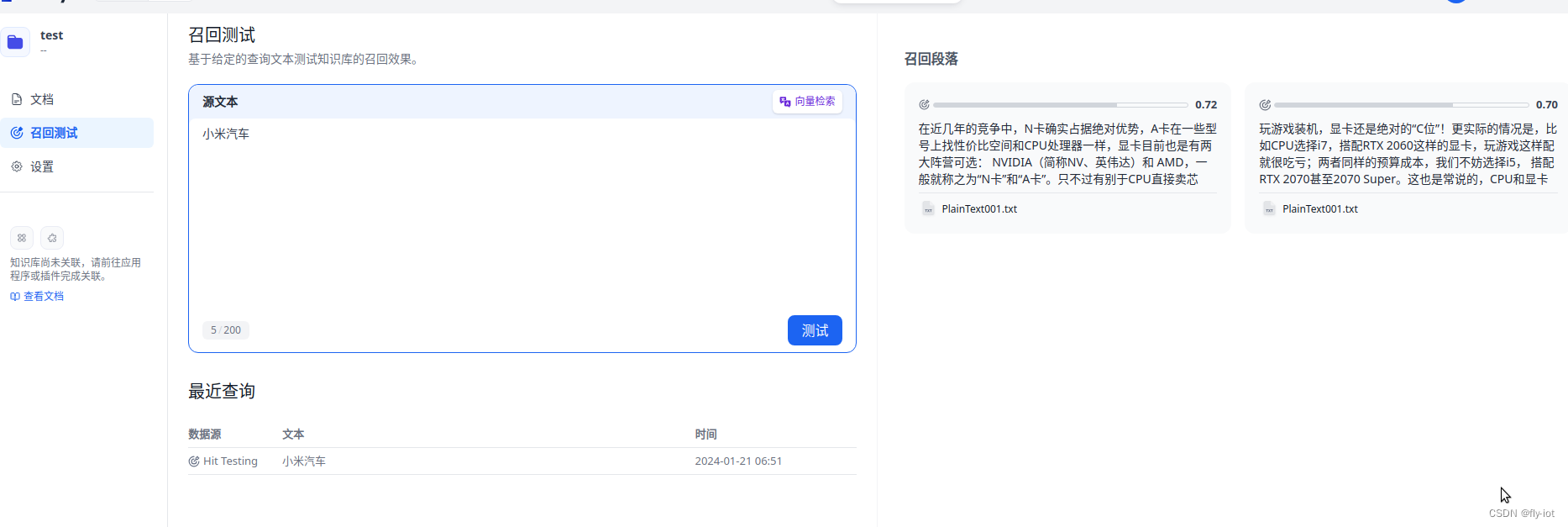
6,总结
对 Dify 项目进行升级,同时可以通过配置 【 OpenAI-API-compatible】
可以支持聊天模型和 embedding 接口。然后就可以搭建自己的知识库系统了。
但是发现 7b的模型聊天的时候还是有点小。后续可以研究下14B的大模型。

