
- 110-斐波那契数列-python_编写程序计算此斐波那契数列的前10个值,并按顺序存入一个列表。
- 2Python 机器学习 EM算法_em算法python
- 3Docker实战案例研究:深入行业应用与最佳实践_docker使用案例
- 4这笔钱领了吗?拥有信息系统项目管理师等软考类证书可获技能提升补贴最高2000元!_软考高级 北京补助多少钱
- 5算法数据结构基础——图(Graph)_graph 算法
- 6IDEA(最新版)导入Myeclipse/eclipse的web项目并运行(全) Windows或者Mac系统_idea导入myeclipse web项目
- 7AIGC数字人视频创作平台,赋能企业常态化制作数字内容营销
- 8微信小程序 java失物招领系统uniAPP设计_失物招领微信小程序
- 9解决老旧电脑在win7中浏览器访问https网站出现的Let‘sEncrypt证书过期的问题_dst root ca x3证书下载
- 10网络状态检查工具类_networkinfo info = getactivenetworkinfo();
如何监控Redis性能指标
赞
踩
Redis给人的印象是简单、很快,但是不代表它不需要关注它的性能指标,此文简单地介绍了一部分Redis性能指标.
原文出处:https://www.datadoghq.com/blog/how-to-monitor-redis-performance-metrics/
以下为部分译文:
监控Redis可以帮助解决两个方面的问题:Redis本身的资源问题,以及基础架构中其他方面出现的问题。 在本文中,我们将介绍以下每个类别中最重要的Redis指标:
性能指标: Performance metrics
内存指标: Memory metrics
基本活动指标: Basic activity metrics
持久性指标: Persistence metrics
错误指标: Error metrics
1.性能指标:Performance metrics
除错误率低外,良好的性能是系统健康状况的最佳顶级指标之一。性能不佳通常是由内存问题引起的,如内存部分所述。
Name | Description | Type |
latency | Redis响应一个请求的时间 Average time for the Redis server to respond to a request | Performance |
instantaneous_ops_per_sec | 平均每秒处理请求总数 Total number of commands processed per second | Throughput |
hit rate (calculated) | 缓存命中率(计算出来的) keyspace_hits / (keyspace_hits + keyspace_misses) | Success |
1.1需要告警的指标: latency(延迟)
延迟是客户端请求与实际服务器响应之间的时间的度量。跟踪延迟是检测Redis性能变化的最直接方法。
由于Redis的单线程特性,异常情况下的延迟可能会导致严重的瓶颈。一个请求的长响应时间会增加所有后续请求的延迟。
一旦确定延迟是一个问题,您可以采取一些措施来诊断和解决性能问题。请参阅白皮书“了解前5个Redis性能指标”中的第14页的“使用延迟命令提高性能”一节。
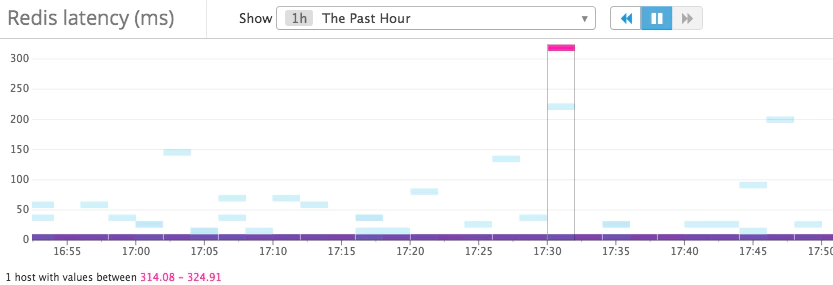
译者注:哪些因素会引起延迟?
1,slowlog 慢查询引起的延迟
slowlog-log-slower-than: 慢查询时间阈值,超过这个阈值的查询将会被记录,默认值10000,但是微妙,也即10毫秒。
slowlog-max-len:慢查询日志最大条数,默认值128,先进先出的队列的形式记录在内存中。
slowlog-get n:获取前n条慢查询日志

2,网络延迟
redis-cli --latency 命令用来检测网络延迟,输出的时间单位为毫秒,它通过Redis PING命令测量Redis服务器响应的时间(以毫秒为单位)来实现这一点。
redis-cli --latency -h 127.0.0.1 -p

对于以上返回信息的含义,参考:https://stackoverflow.com/questions/27735411/understanding-latency-using-redis-cli
在此上下文中,延迟是客户机发出命令到客户机接收到对命令的响应之间的最大延迟。通常Redis处理时间非常低,在亚微秒范围内,但是有一些条件会导致更高的延迟数字。
What's (1815samples)? 这是redis-cli记录发出PING命令并接收响应的次数。换句话说,这是采样数据。在当前示例中,记录了1815个请求和响应。
What's min: 0? 最小值表示CLI发出PING的时间到收到回复的时间之间的最小延迟。换句话说,这是来自采样数据的最佳响应时间。
What's max: 15? 最大值表示CLI发出PING信号到收到命令的响应之间的最大延迟。这是来自采样数据的最长响应时间。在我们1815个示例中,最长的事务花费了1ms。
What's avg: 0.12? avg值是所有采样数据的平均响应时间(以毫秒为单位)。平均而言,个个样本的响应时间是0.12毫秒。
redis-cli --latency-history,以分段的形式展现Redis延迟
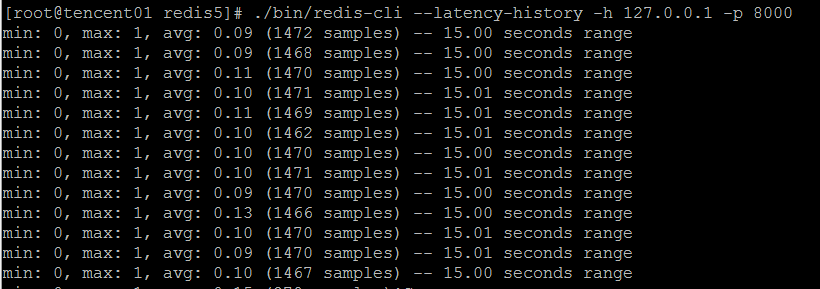
redis-cli --latency-dist,以图表的形式展现Redis延迟,这个图表的结果看不怎么懂

3,Intrinsic latency 固有延迟
顾名思义,任何请求响应都要经过代码的处理,必然有延迟,Intrinsic latency是Redis自身处理指令需要消耗的时间,这部分时间耗费无法避免。
当然Intrinsic latency的延迟非常低,在微妙级别
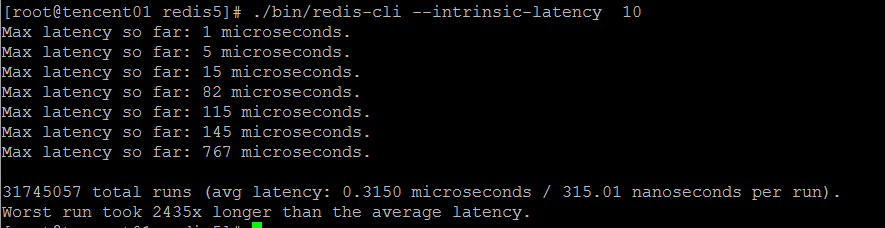
如何检测延迟?
参考:https://blog.csdn.net/dc_726/article/details/47699739
http://www.redis.cn/topics/latency-monitor.html
CONFIG SET latency-monitor-threshold 100
延迟检测模式是关闭的,可以通过配置打开延迟监控

打开延迟监控后,人为制造一个产生高延迟的save操作指令,通过latency latest观测延迟信息
latency latest:四列分别表示事件名、最近延迟的Unix时间戳、最近的延迟(毫秒)、最大延迟(毫秒)。

latency 可以通过以下参数检测延迟信息
LATEST:四列分别表示事件名、最近延迟的Unix时间戳、最近的延迟、最大延迟。
HISTORY:延迟的时间序列。可用来产生图形化显示或报表。
GRAPH:以图形化的方式显示。最下面以竖行显示的是指延迟在多久以前发生。
RESET:清除延迟记录。
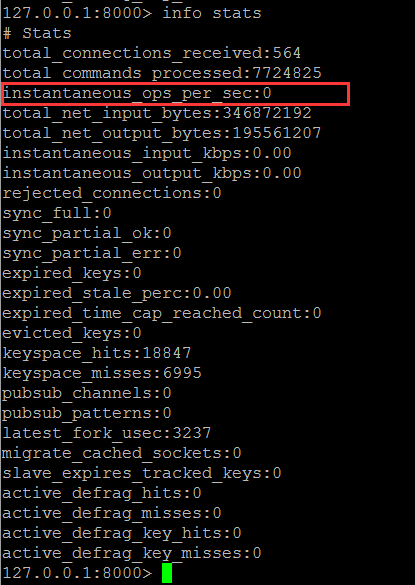
1.2需要观察的指标:instantaneous_ops_per_sec
跟踪处理的命令吞吐量对于诊断Redis实例中的高延迟原因至关重要。
高延迟可能是由许多问题引起的,从积压命令队列到慢速命令,再到网络过度使用。
可以通过测量每秒处理的命令数来进行诊断 - 如果它相对比较平稳,则原因不是计算密集型命令(Redis本身引起的)。
如果一个或多个慢速命令导致延迟问题,您将看到每秒的命令数量完全下降或停止。
与历史基线相比,每秒处理的命令数量的下降可能是低命令量或阻塞系统的慢命令的标志。
1.OPS较低可能是正常的,或者它可能表示上游存在问题(译者注:表示Redis本身被负载量较低)。
2.有关慢速命令的详细信息,请参阅第2部分,了解有关收集Redis指标的信息。

译者注:如何获取Redis的OPS
1.3Metric to watch: hit rate
使用Redis作为缓存时,监视缓存命中率可以告诉您缓存是否被有效使用。命中率低意味着客户端正在寻找不再存在(Redis内存中)的Key值。
Redis不直接提供命中率指标。我们仍然可以像这样计算:
HitRate=keyspace_hits/(keyspace_hits+keyspace_misses)
低缓存命中率可能由许多因素引起,包括数据到期和分配给Redis的内存不足(这可能导致key值被清除)。
低命中率可能会导致应用程序延迟增加,因为它们必须从较慢的备用资源中获取数据。
译者注:如何获取Redis的keyspace_hits+keyspace_misses,同样是info stats

2.Memory metrics
Name | Description | Type |
used_memory | 已使用内存 Amount of memory (in bytes) used by Redis | Utilization |
mem_fragmentation_ratio | 内存碎片率 Ratio of memory allocated by the operating system to memory requested by Redis | Saturation |
evicted_keys | 由于最大内存限制被移除的key的数量 Number of keys removed due to reaching the maxmemory limit | Saturation |
blocked_clients | 由于BLPOP, BRPOP, or BRPOPLPUSH而备阻塞的客户端 Number of keys removed due to reaching the maxmemory limit | Other |
2.1需要注意的指标: used_memory
内存使用是Redis性能的关键组成部分。
如果实例超过可用内存(used_memory > total available memory),操作系统将开始交换老的/未使用的部分内存(pages),将该部分pages写入磁盘,为较新/活动页腾出内存空间。
每个交换的部分都写入磁盘,严重影响性能。从磁盘写入或读取速度比写入或从存储器读取速度慢5个数量级(100,000)(内存为0.1μs,磁盘为10 ms)。
可以将Redis配置为仅限于指定的内存量。在redis.conf文件中设置maxmemory指令可以直接控制Redis的内存使用情况。
启用maxmemory需要您为Redis配置驱逐(过期)策略以确定它应如何释放内存。
当Redis用作缓存时,这种“扁平线”模式很常见;消耗掉所有可用内存,并以与插入新数据相同的速率清理旧数据。

译者注:关于Redis的内存参数 info memory
used_memory和used_memory_human都是Redis使用到的内存,used_memory_human是一更加可读性的方式展示Redis的内存使用
used_memory_rss和used_memory_rss_human 表示操作系统为Redis进程分配的内存总量,两者的含义类似如上。
为什么会出现Redis使用的内存大于操作系统给Redis分配的内存,参考https://stackoverflow.com/questions/44385820/redis-used-memory-is-largger-than-used-memory-rss
used_memory being < used_memory_rss意味着内存碎片的存在。
used_memory > used_memory_rss 意味着物理内存不足,发生了内存swap。

2.2 需要告警的指标: mem_fragmentation_ratio
mem_fragmentation_ratio度量标准给出了操作系统看到的内存与Redis分配的内存的比率。
MemoryFragmentationRatio =Used_Memory_RSS(Used_Memory)
操作系统负责为每个进程分配物理内存。操作系统的虚拟内存管理器处理由内存分配器调解的实际映射。
如果Redis实例的内存占用为1GB,内存分配器将首先尝试找到一个连续内存段来存储数据。如果没有找到连续的段,分配器必须将进程的数据划分为多个段,从而导致内存开销的增加。
跟踪碎片比率对于了解Redis实例的性能非常重要。
碎裂率大于1表示发生碎片。比率超过1.5表示碎片过多,Redis实例占用了所请求的物理内存的150%。
碎片率低于1会告诉您Redis需要的内存比系统上可用的内存多,这会导致交换。交换到磁盘将导致延迟显着增加(请参阅已用内存)。
理想情况下,操作系统会在物理内存中分配一个连续的段,碎片比率等于1或稍大一些。
1,如果您的服务器的碎片率高于1.5,则重新启动Redis实例将允许操作系统恢复以前因碎片而无法使用的内存。在这种情况下,作为通知的警报可能就足够了。
2,如果Redis服务器的碎片比率低于1,则可能需要以发出告警,以便快速增加可用内存或减少内存使用量。
从Redis 4开始,当Redis配置为使用包含的jemalloc副本时,可以使用新的活动碎片整理功能。
可以将此工具配置为在碎片达到特定级别时启动,并开始将值复制到连续的内存区域并释放旧副本,从而减少服务器运行时的碎片。
译者注,info memory可以查看内存碎片信息

配置文件中增加activedefrag yes选项,不用重启的方式自动重整内存碎片。

2.3需要告警的指标:evicted_keys(仅限缓存)
如果您使用Redis作为缓存,可能将其配置为在达到maxmemory限制时(按照某种方式)自动清除key值。
如果您使用Redis作为数据库或队列,可能需要交换而不是清除key值,在这种情况下,因此可以跳过此指标。
跟踪key值清理指标非常重要,因为Redis按顺序处理每个操作,这意味着驱逐大量key可以降低命中率,从而增加延迟时间。
如果您使用TTL,您可能不会期望清理key值。在这种情况下,如果此指标始终高于零,您可能会看到实例中的延迟增加。
大多数不使用TTL的其他配置最终会耗尽内存并开始清理key值。只要您的响应时间可以接受,就可以接受稳定的清除率。
您可以使用以下命令配置key值过期策略:
config set maxmemory-policy = ***
其中policy是以下之一:
noeviction-----------------------当达到内存限制并且用户尝试添加其他键时,将返回错误(也就是说达到内存限制之后不允许写入)
volatile-lru-----------------------在已过期的key值中,删除最近最少使用的key值
volatile-ttl------------------------在已过期的key值中,删除最短过期时间的key值
volatile-random-----------------在已过期的key值中,随机删除key值
allkeys-lru-----------------------从所有key值中删除最近最少使用的key
allkeys-random-----------------从所有key值中随机删除
volatile-lfu-----------------------在Redis 4中新增选项,在已过期的key值中,“最近最不常用”的key值
allkeys-lfu-----------------------在Redis 4中新增选项,从所有key值中,删除“最近最不常用”的key值
注意:出于性能原因,当使用LRU,TTL或Redis 4的LFU策略时,Redis实际上不会从整个key值集进行采样。
Redis首先对key值集的随机子集进行采样,然后对样本应用清理策略。
通常,Redis的较新(> = 3)版本采用LRU采样策略,该策略更接近真实LRU。
例如,可以通过设置必须经过多少时间而无需访问项目在排名中向下移动来调整LFU策略。有关更多详细信息,请参阅Redis的文档。
译者注:
关于LRU和LFU,分别是最近最少使用和最近最不频繁使用,LFU理论上是比LRU更加合理的算法,清理key的时候,LFU认为“最近最不频繁”使用要比“最近最少”使用更加合理。
LRU和LFU的区别:
LRU是最近最少使用页面置换算法(Least Recently Used),也就是首先淘汰最长时间未被使用的页面!
LFU是最近最不常用页面置换算法(Least Frequently Used),也就是淘汰一定时期内被访问次数最少的页!
2.4 需要注意的指标: blocked_clients
Redis提供了许多在List上运行的阻塞命令。
BLPOP,BRPOP和BRPOPLPUSH分别是命令LPOP,RPOP和RPOPLPUSH的阻塞变体。
当List非空时,命令按预期执行。但是,当List为空时,阻塞命令将一直等到源被填充或达到超时。
等待数据的被阻止客户端数量的增加可能是一个麻烦的迹象。
延迟或其他问题可能会阻止源列表被填充。虽然被阻止的客户端本身不会引起警报,但如果您看到此指标的值始终为非零值,则应该引起注意。
3. 基本活动指标
Name | Description | Type |
connected_clients | 客户端连接数 Number of clients connected to Redis | Utilization |
connected_slaves | Slave数量 Number of slaves connected to current master instance | Other |
master_last_io_seconds_ago | 最近一次主从交互之后的秒数 Number of slaves connected to current master instance | Other |
keyspace | 数据库中的key值总数 Total number of keys in your database | Utilization |
3.1 需要告警的指标: connected_clients
由于对Redis的访问通常由应用程序发起(用户通常不直接访问数据库),因此对于大多数场景,连接客户端的数量将有合理的上限和下限。
如果数字偏离正常范围,这表示可能存在问题。
如果它太低,表示客户端连接可能已经丢失,如果它太高,大量的并发客户端连接可能会打垮服务器处理请求的能力。
无论如何,客户端连接始终是有限的资源 - 无论是通过操作系统,Redis的配置还是网络限制。
监视客户端连接可帮助您确保有足够的可用资源用于新客户端或管理会话。
译者注:查看Redis的最大连接数,这个配置相当于MySQL的变量(show variables ***),是一个不随Redis服务负载改变的值,因此不在info中查看。

3.2需要告警的指标: connected_slaves
如果您的数据库是大量读取的,那么您可能正在使用Redis中提供的主从数据库复制功能。
在这种情况下,监控连接的从站数量是关键。如果连接的从站数量意外更改,则可能表示主机已关闭或从站实例出现问题。

注意:在上图中,Redis Master将显示它有两个连接的slave,并且每个slave都有两个slave。
由于slave的slave不直接连接到Redis Master,因此它们不包含在Redis Master的connected_slaves中。
3.3需要告警的指标: master_last_io_seconds_ago
使用Redis的复制功能时,slave会定期检查其主服务器。主从长时间没有通信的可能表示主从Redis实例之间存在问题。并且冒着slave中数据在master中已经发生了变化危险。
由于Redis执行同步的方式,最大限度地减少主从通信的中断至关重要。当从设备在中断后重新连接到master时,它会发送PSYNC命令以尝试仅同步中断期间丢失的命令。
如果无法做到这一点,则从站将请求完整的SYNC,这会迫使master立即开始执行background save命令,同时新增加的命令会被缓冲起来。
当background save命令执行完成时,数据与缓冲的命令一起发送到客户端。每次从机执行SYNC时,都会导致主实例上的延迟显着增加。
3.4需要注意的指标: keyspace
跟踪数据库中的键数通常是个好主意。作为内存数据存储,key值集合空间越大,为了确保性能,Redis需要的物理内存越多。
Redis将继续添加key值,直到它达到maxmemory limit,然后它开始以相同的速率清理key值。这会产生一个“扁平线”图,如上图所示。
如果您使用Redis作为缓存并查看key值空间饱和度 - 如上图所示 - 加上命中率较低,您可能会让客户端请求旧的或已逐出的数据。随着时间的推移跟踪keyspace_misses数量将帮助您查明原因。
或者,如果使用Redis作为数据库或队列,则可能不选择volatile策略。
随着key值空间的增长,如果可能的话,您可能需要考虑在添加物理内存或在主机之间拆分数据集。
添加更多内存是一种简单有效的解决方案。如果单机资源有限,则对数据进行分区或分片可以合并许多计算机的资源。
有了分区计划,Redis可以存储更多key值集合而无需清理或swap。但是,分片比增加内存要困难得多。
值得庆幸的是,Redis文档中有一个关于使用Redis实例实现分区方案的重要部分,请在此处阅读更多内容。

译者注:Redis的keyspace信息

4.持久化指标
Redis需要启用持久性配置,尤其是在使用Redis的复制功能时。
如果您使用Redis作为缓存,或者在数据丢失无关紧要的用例中,则可能不需要持久性。
Name | description | Type |
rdb_last_save_time | 最后一次持久化保存到磁盘的Unix时间戳 Unix timestamp of last save to disk | other |
rdb_changes_since_last_save | 自最后一次持久化以来数据库的更改数 | other |
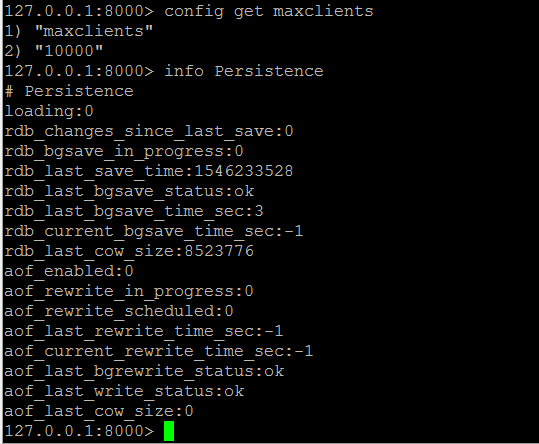
4.1 需要注意的指标: rdb_last_save_time and rdb_changes_since_last_save
通常,关注数据集的波动性是个好主意。写入磁盘之间的时间间隔过长可能会在服务器发生故障时导致数据丢失。
在上次保存时间和故障时间之间对数据集所做的任何更改都将丢失。
监控rdb_changes_since_last_save可让您更深入地了解数据的波动性。如果您的数据集在该间隔内没有太大变化,则写入之间的长时间间隔不是问题。
跟踪这两个指标可以让您清楚地了解在给定时间点发生故障时您将丢失多少数据。
译者注:如何查看Redis的rdb_last_save_time and rdb_changes_since_last_save
info Persistence
5.Error metrics
Name | Description | Type |
rejected_connections | 由于达到maxclient限制而被拒绝的连接数 number of connections rejected due to hitting maxclient limit | Saturation |
keyspace_misses | Key值查找失败(没有命中)次数 number of failed lookups of keys | Errors / Other |
master_link_down_since_seconds | 主从断开的持续时间(以秒为单位) time in seconds of the link between master and slave being down | Errors |
5.1需要告警的指标: rejected_connections
Redis能够处理许多活动连接,默认情况下可以使用10,000个客户端连接。
可以通过更改redis.conf中的maxclient指令将最大连接数设置为不同的值。
如果您的Redis实例当前处于其最大连接数,则将断开任何新的连接尝试。
请注意,Redis可能不支持使用maxclient指令请求的连接数。
Redis检查内核以确定可用文件描述符的数量。如果可用文件描述符的数量小于maxclient + 32(Redis为其自己使用保留32个文件描述符),则忽略maxclient指令并使用可用文件描述符的数量。
有关Redis如何处理客户端连接的更多信息,请参阅有关redis.io的文档。

译者注:rejected_connections可以通过查看Info stat

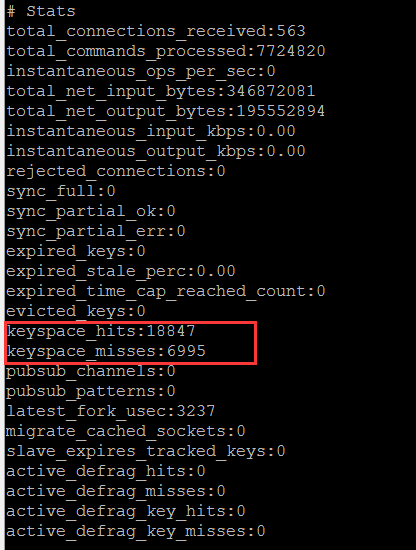
5.2需要告警的指标: keyspace_misses
每次Redis查找key时,只有两种可能的结果:key存在,或key不存在。
查找不存在的键会导致keyspace_misses计数器递增,因此keyspace_misses意味着客户端尝试在数据库中查找不存在的密key。
如果您不使用Redis作为缓存,则keyspace_misses应该为零或接近零。请注意,调用阻塞的任何阻塞操作(BLPOP,BRPOP和BRPOPLPUSH)都将导致keyspace_misses递增。
译者注:keyspace_misses可以通过查看Info stat
5.3需要告警的指标: master_link_down_since_seconds
该指标仅在主从之间的连接丢失时可用。
理想情况下,此值不应超过零-主从之间保持持续通信,以确保slave不提供过时数据。
应该解决连接之间的大的时间间隔。请记住,重新连接后,您的主Redis实例将需要投入资源来更新从站上的数据,这可能会导致延迟增加。
总结
在这篇文章中,我们提到了一些最有用的指标,您可以监控这些指标以密切关注您的Redis服务器。
如果您刚刚开始使用Redis,那么监控下面列表中的指标将提供对数据库基础结构的运行状况和性能的良好可见性:
Number of commands processed per second
Latency
Memory fragmentation ratio
Evictions
Rejected clients
最终,您将认识到与您自己的设备和用例特其他指标。当然,您监控的内容取决于您拥有的工具和可用的指标。有关收集Redis指标的分步说明,请参阅随附文章。

