
- 1基于PRECHIN普中51-实验板学习—蜂鸣器相关学习(2)_普中单片机蜂鸣器
- 2Linux下的CentOS7连接不上外网,yum失败_yum install rpm 无法联网失败
- 3docker修改已运行容器的映射端口_docker容器的端口映射可以修改吗
- 4德国人工智能战略
- 50基础入门 | bluecms前后台代码审计_bluecms 系统
- 6ai论文写作免费网站推荐哪个?ai人工智能写作免费
- 7数字图像处理 第四章 数字图像处理中的基本运算_数字图像前向衍射
- 8androidstudio配置,基于android的app开发详细步骤_基于android studio的app开发
- 9ubuntu 离线安mysql_Ubuntu离线安装MySQL
- 10error: RPC failed; curl 56 GnuTLS recv error (-110): The TLS connection was non-properly terminated._error: rpc failed; curl 56 gnutls recv error (-110
在Elasticsearch 7.9.2中安装IK分词器并进行自定义词典配置
赞
踩
Elasticsearch是一个强大的开源搜索引擎,而IK分词器是针对中文文本分析的重要插件。本文将引导您完成在Elasticsearch 7.9.2版本中安装IK分词器、配置自定义词典以及验证分词效果的全过程。
步骤一:下载IK分词器
访问IK分词器的GitHub发布页面:
[下载地址](https://github.com/infinilabs/analysis-ik/releases)
- 1
针对您的Elasticsearch 7.9.2版本,请下载对应版本的IK分词器:
[IK分词器7.9.2版本](https://objects.githubusercontent.com/github-production-release-asset-2e65be/2993595/b2790500-feb6-11ea-8bc9-c674a2b144ce?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIAVCODYLSA53PQK4ZA%2F20240426%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20240426T004946Z&X-Amz-Expires=300&X-Amz-Signature=331c06e100afc3c10c492d982dfd1c6d4bc04554e5ce7a677b8389239b0425e1&X-Amz-SignedHeaders=host&actor_id=0&key_id=0&repo_id=2993595&response-content-disposition=attachment%3B%20filename%3Delasticsearch-analysis-ik-7.9.2.zip&response-content-type=application%2Foctet-stream)
- 1
步骤二:安装IK分词器
下载完成后,解压缩文件,并将解压后的elasticsearch-analysis-ik-7.9.2目录复制到Elasticsearch的插件目录(修改文件加名称为ik)。假设您的Elasticsearch安装在D:\ProgramFiles\elasticsearch-7.9.2,则应将IK分词器复制到以下位置:
D:\ProgramFiles\elasticsearch-7.9.2\plugins
#安装后目录
D:\ProgramFiles\elasticsearch-7.9.2\plugins\ik
- 1
- 2
- 3
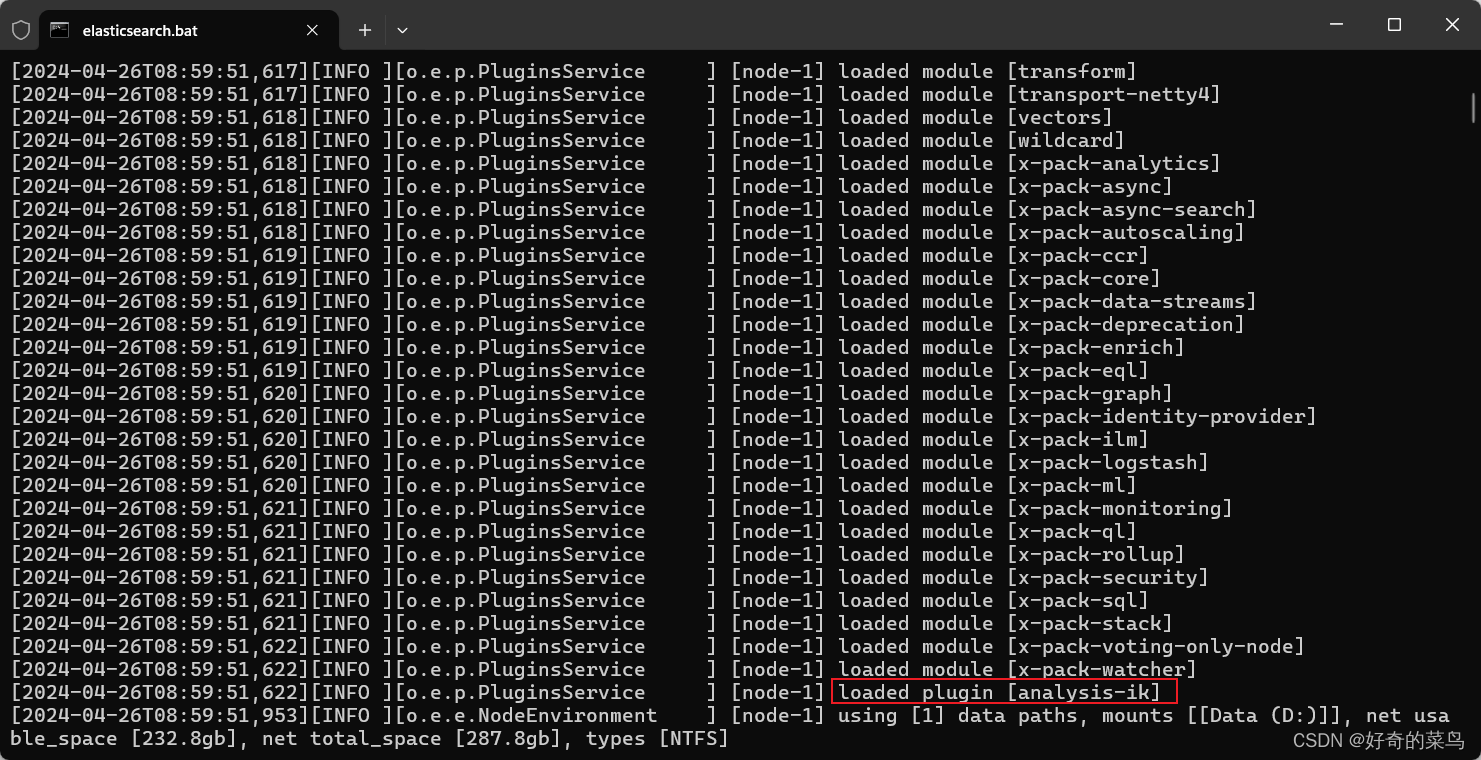
步骤三:重启Elasticsearch
完成插件安装后,需要重启Elasticsearch以加载新安装的IK分词器。确保Elasticsearch服务已经关闭,然后按照常规方式启动它。
步骤四:验证IK分词器安装
重启Elasticsearch后,可以通过发送以下两个请求来验证IK分词器是否成功安装并运行:
GET /_analyze
{
"analyzer": "ik_smart",
"text": "刘亦菲早上好"
}
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "刘亦菲早上好"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这两个请求分别使用ik_smart和ik_max_word两种分词策略对文本“刘亦菲早上好”进行分词。ik_smart倾向于智能切分,减少冗余;ik_max_word则尽可能多地输出分词结果。响应应包含类似如下结构的分词结果:
{ "tokens" : [ { "token" : "刘", "start_offset" : 0, "end_offset" : 1, "type" : "CN_CHAR", "position" : 0 }, ... { "token" : "上好", "start_offset" : 4, "end_offset" : 6, "type" : "CN_WORD", "position" : 5 } ] }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
步骤五:配置自定义词典
接下来,我们将为IK分词器配置一个自定义词典,以添加特定词汇“刘亦菲”。首先,找到IK分词器的配置文件:
D:\ProgramFiles\elasticsearch-7.9.2\plugins\ik\config\IKAnalyzer.cfg.xml
- 1
编辑该文件,添加或修改以下内容:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my.dict</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--其他配置项...-->
</properties>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这里指定了一个名为my.dict的自定义词典文件。接着,在同一目录下创建该文件:
D:\ProgramFiles\elasticsearch-7.9.2\plugins\ik\config\my.dict
- 1
并在其中输入要添加的词汇:
刘亦菲
- 1
步骤六:重启Elasticsearch并验证自定义词典
保存并关闭配置文件及词典文件后,再次重启Elasticsearch。随后,重新执行ik_max_word分词策略的请求:
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "刘亦菲早上好"
}
- 1
- 2
- 3
- 4
- 5
此时,响应中的分词结果应包含新增的自定义词汇“刘亦菲”,如下所示:
{ "tokens" : [ { "token" : "刘亦菲", "start_offset" : 0, "end_offset" : 3, "type" : "CN_WORD", "position" : 0 }, ... { "token" : "上好", "start_offset" : 4, "end_offset" : 6, "type" : "CN_WORD", "position" : 3 } ] }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
至此,您已在Elasticsearch 7.9.2中成功安装了IK分词器,并完成了自定义词典的配置与验证。现在,Elasticsearch已具备对中文文本进行精准分词的能力,并可根据需要灵活扩展词典。

