
- 1java MD5算法返回数字型字串_java md5加密并将结果用十进制表示
- 2C++初识--------带你从不同的角度理解引用的巧妙之处
- 3【送书福利-第三十期】《Java面试八股文:高频面试题与求职攻略一本通》_java面试八股文高频面试题与求职攻略电子书
- 4Windows中redis怎么设置密码_windows redis设置密码
- 5Vue中组件生命周期过程详解_vue 子组件生命周期
- 6树莓派安装python3.9以及pip换源_树莓派安装pip
- 7python无人机路径规划算法_无人机集群——航迹规划你不知道的各种算法优缺点...
- 8卓越体验的秘密武器:评测ToDesk云电脑、青椒云、天翼云的稳定性和流畅度_青椒云评价
- 9Mybatis 注解实现基本 CRUD_mybatis mapper 注解方式编程:针对模型类设计基本的 crud 功
- 10数据结构-----二叉排序树
预训练模型是什么
赞
踩
1. 什么是预训练和微调
你需要搭建一个网络模型来完成一个特定的图像分类的任务。首先,你需要随机初始化参数,然后开始训练网络,不断调整参数,直到网络的损失越来越小。在训练的过程中,一开始初始化的参数会不断变化。当你觉得结果很满意的时候,你就可以将训练模型的参数保存下来,以便训练好的模型可以在下次执行类似任务时获得较好的结果。这个过程就是 pre-training。
之后,你又接收到一个类似的图像分类的任务。这时候,你可以直接使用之前保存下来的模型的参数来作为这一任务的初始化参数,然后在训练的过程中,依据结果不断进行一些修改。这时候,你使用的就是一个 pre-trained 模型,而过程就是 fine-tuning。
所以,预训练 就是指预先训练的一个模型或者指预先训练模型的过程;微调就是指将预训练过的模型作用于自己的数据集,并使参数适应自己数据集的过程。
1.1 预训练模型
- 预训练模型就是已经用数据集训练好了的模型。
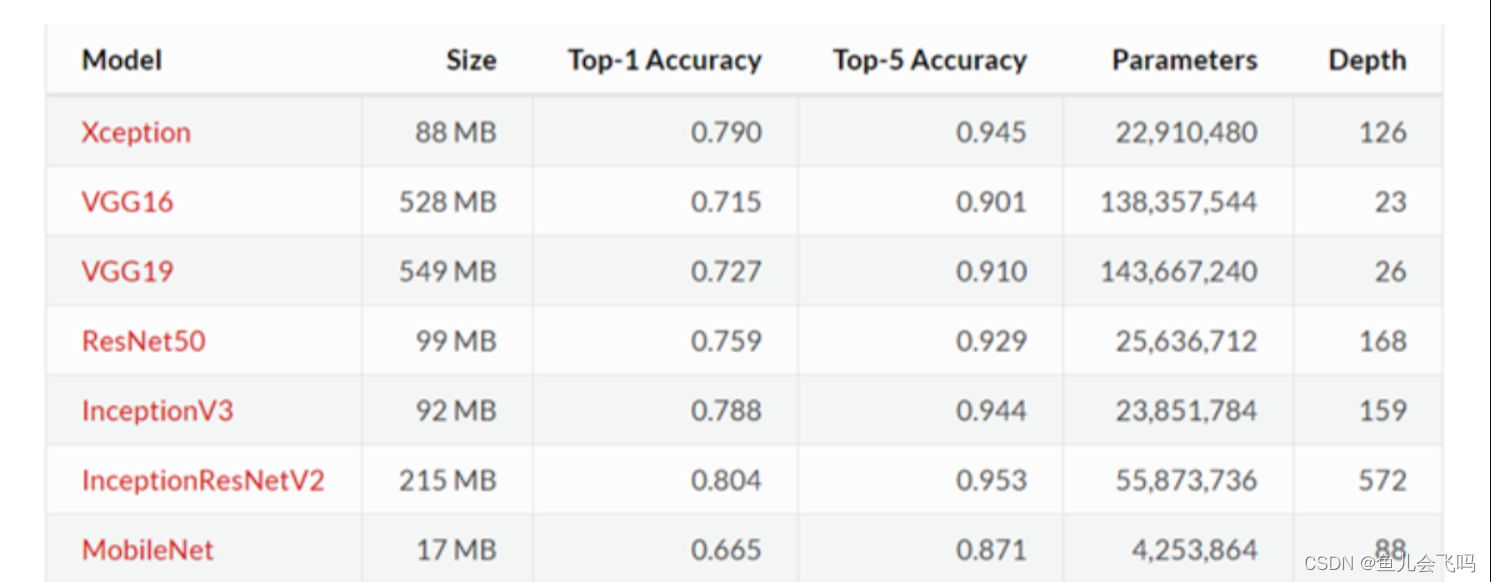
- 现在我们常用的预训练模型就是他人用常用模型,比如VGG16/19,Resnet等模型,并用大型数据集来做训练集,比如Imagenet, COCO等训练好的模型参数;
- 正常情况下,我们常用的VGG16/19等网络已经是他人调试好的优秀网络,我们无需再修改其网络结构。
2. 预训练和微调的作用
在 CNN 领域中,实际上,很少人自己从头训练一个 CNN 网络。主要原因是自己很小的概率会拥有足够大的数据集,基本是几百或者几千张,不像 ImageNet 有 120 万张图片这样的规模。拥有的数据集不够大,而又想使用很好的模型的话,很容易会造成过拟合。
所以,一般的操作都是在一个大型的数据集上(ImageNet)训练一个模型,然后使用该模型作为类似任务的初始化或者特征提取器。比如 VGG,ResNet 等模型都提供了自己的训练参数,以便人们可以拿来微调。这样既节省了时间和计算资源,又能很快的达到较好的效果。
3. 模型微调


3.1 微调的四个步骤
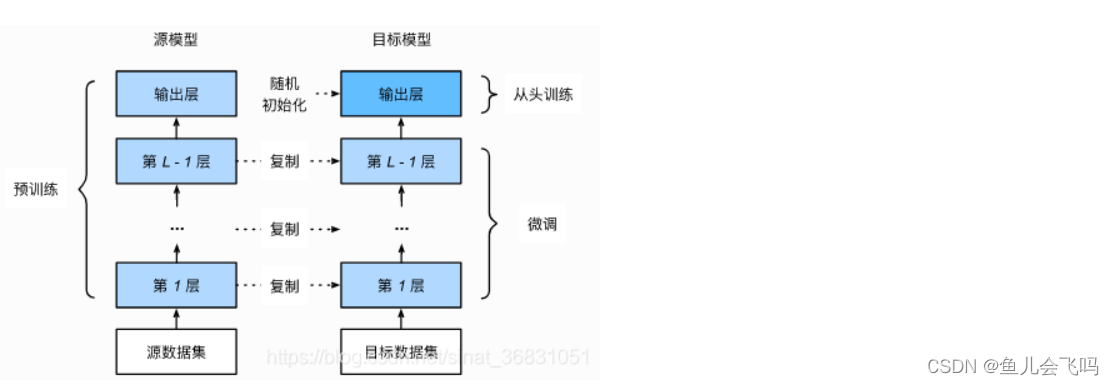
- 在源数据集(例如 ImageNet 数据集)上预训练一个神经网络模型,即源模型。
- 创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。
- 为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
- 在目标数据集(例如椅子数据集)上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
3.2 为什么要微调
卷积神经网络的核心是:
浅层卷积层提取基础特征,比如边缘,轮廓等基础特征。
深层卷积层提取抽象特征,比如整个脸型。
全连接层根据特征组合进行评分分类。
普通预训练模型的特点是:用了大型数据集做训练,已经具备了提取浅层基础特征和深层抽象特征的能力。
如果不做微调的话:
- 从头开始训练,需要大量的数据,计算时间和计算资源。
- 存在模型不收敛,参数不够优化,准确率低,模型泛化能力低,容易过拟合等风险。
3.3 什么情况下使用微调
- 要使用的数据集和预训练模型的数据集相似。如果不太相似,比如你用的预训练的参数是自然景物的图片,你却要做人脸的识别,效果可能就没有那么好了,因为人脸的特征和自然景物的特征提取是不同的,所以相应的参数训练后也是不同的。
- 自己搭建或者使用的CNN模型正确率太低。
- 数据集相似,但数据集数量太少。
- 计算资源太少。
不同数据集下使用微调
- 数据集1 - 数据量少,但数据相似度非常高 - 在这种情况下,我们所做的只是修改最后几层或最终的softmax图层的输出类别。
- 数据集2 - 数据量少,数据相似度低 - 在这种情况下,我们可以冻结预训练模型的初始层(比如k层),并再次训练剩余的(n-k)层。由于新数据集的相似度较低,因此根据新数据集对较高层进行重新训练具有重要意义。
- 数据集3 - 数据量大,数据相似度低 - 在这种情况下,由于我们有一个大的数据集,我们的神经网络训练将会很有效。但是,由于我们的数据与用于训练我们的预训练模型的数据相比有很大不同。使用预训练模型进行的预测不会有效。因此,最好根据你的数据从头开始训练神经网络(Training from scatch)。
- 数据集4 - 数据量大,数据相似度高 - 这是理想情况。在这种情况下,预训练模型应该是最有效的。使用模型的最好方法是保留模型的体系结构和模型的初始权重。然后,我们可以使用在预先训练的模型中的权重来重新训练该模型。
3.4 微调注意事项
- 通常的做法是截断预先训练好的网络的最后一层(softmax层),并用与我们自己的问题相关的新的softmax层替换它。例如,ImageNet上预先训练好的网络带有1000个类别的softmax图层。如果我们的任务是对10个类别的分类,则网络的新softmax层将由10个类别组成,而不是1000个类别。然后,我们在网络上运行预先训练的权重。确保执行交叉验证,以便网络能够很好地推广。
- 使用较小的学习率来训练网络。由于我们预计预先训练的权重相对于随机初始化的权重已经相当不错,我们不想过快地扭曲它们太多。通常的做法是使初始学习率比用于从头开始训练(Training from scratch)的初始学习率小10倍。
- 如果数据集数量过少,我们进来只训练最后一层,如果数据集数量中等,冻结预训练网络的前几层的权重也是一种常见做法。这是因为前几个图层捕捉了与我们的新问题相关的通用特征,如曲线和边。我们希望保持这些权重不变。相反,我们会让网络专注于学习后续深层中特定于数据集的特征。
参考:
深入理解预训练(pre-learning)、微调(fine-tuning)、迁移学习(transfer learning)三者的联系与区别-CSDN博客

