
- 1已解决(pymysqL连接数据库报错)pymysqL.err.ProgrammingError: (1146,“Table ‘test.students‘ doesn‘t exist“)_raise errorclass(errno, errval) pymysql.err.progra
- 2vue 报错this.$Api.sendEmail is not a function 和TypeError: Cannot set property 'pageCode' of undefined_vue this.$api.不存在
- 3自用的8款AI工具!提升学习/工作/赚钱效率,轻松超过99%的人!
- 4数据结构与算法——归并排序_数据结构归并排序
- 5使用 Xcode 运行 python等脚本语言(perl, ruby)_伊织code
- 6深入理解Elasticsearch的索引映射(mapping)_elasticsearch 类型 映射
- 7三分钟掌握PHP操作数据库_php数据库
- 8远程仓库——GitHub
- 9Hadoop之HBase基本简介_hadoop hbase
- 10[深度学习]yolov8+pyqt5搭建精美界面GUI设计源码实现一_yolo pyqt界面设计代码
【深度学习】Subword Tokenization算法
赞
踩
在自然语言处理中,面临的首要问题是如何让模型认识我们的文本信息,词,是自然语言处理中基本单位,神经网络模型的训练和预测都需要借助词表来对句子进行表示。
1.构建词表的传统方法
在字词模型问世之前,做自然语言处理任务时,一般通过传统方法构建词表,具体的构建流程如下:
1.首先对数据集中的所有句子进行分词,通过jieba、ltp等分词工具将句子粒度缩小到词粒度。例如:我/爱/北京/天安门。
2.对切分出来的词进行统计,统计并选出频数最高的前N个词组成词表,对低频词舍弃。
通过筛选词频的方式构建的词表会存在以下问题:
1.出于计算效率的考虑,通常N的选取无法包含训练集中的所有词,对于未在词表中出现的词(Out Of Vocabulary, OOV),模型将无法处理及生成;
2.词表中的低频词/稀疏词在模型训练过程中无法得到充分训练,进而模型不能充分理解这些词的语义;
3.一个单词因为不同的形态会产生不同的词,如由"look"衍生出的"looks", "looking", "looked",显然这些词具有相近的意思,但是在词表中这些词会被当作不同的词处理,一方面增加了训练冗余,另一方面也造成了大词汇量问题。
2.抛砖引玉
假设要从训练数据集中构建一个词表。为了构建该词表,我们将数据集中的文本拆分成单词,然后把唯一的单词加入到词表。通常,词表包含很多单词(Token),为了举例的简单,假设构造的词表只包含下面的单词:
vocabulary = [game, the, I, played, walked, enjoy]有词表之后,下面基于该词表来对输入进行分词。考虑输入句子I played the game。在英文中,只要通过空格就得得到句子中所有的单词。所以我们有[I, play, the, game]。现在,我们检查是否所有的单词都在词表中。恰好这些单词都在词表中,从给定句子中得到的最终标记就为:
tokens = [I, played, the, game]接着我们考虑另一个句子:I enjoyed the game。首先还是根据空格分词,得到 [I, enjoyed, the, game]。接着,检查是否所有的单词出现在词表中。我们可以看到,除了单词enjoyed,其他的单词都在词表中,因此我把enjoyed替换为未知标记<UNK>,这样我们最终的标记为:
tokens = [ I, <UNK>, the, game] 我们也可以看到,尽管词表中有单词enjoy,但是由于没有完全一样的单词enjoyed,它就变成未知词了。可能是因为词表太小了,然而哪怕有一个超大的词表,先不说这样的词表会带来内存和性能方面的压力,仍然有可能无法处理没有出现过的词(词表中也没有出现过)。
针对上述问题,Subword(子词)模型方法横空出世。它的划分粒度介于词与字符之间,比如可以将”enjoyed”划分为”enjoy”和”ed”两个子词,而划分出来的"enjoy",”ed”又能够用来构造其它词,如"engoy"和"ing"子词可组成单词"engoying",因而Subword方法能够大大降低词典的大小,同时对相近词能更好地处理。
在子词Tokenization中,我们将单词拆分为更小的子词。假设我们拆分单词played为子词[play, ed];拆分单词walked为子词[walk, ed]。在拆分子词后,我们将这些子词加到词表中。由于词表中不包含重复单词,所以我们的词表变成了:
vocabulary = [game, the, I, play, walk, ed, enjoy]
在来看之前的句子: I enjoyed the game。同样我们先根据空格将句子拆分单词,我们有[ I, enjoyed, the, game]。接着我们检测是否所有的单词都在词表中。我们可以看到除了单词enjoyed,其他所有单词都在词表中。此时,我们不会将该单词替换为未知词,而是将它继续拆分为子词:[enjoy, ed]。同样我们先根据空格将句子拆分单词,我们有[ I, enjoyed, the, game]。接着我们检测是否所有的单词都在词表中。我们可以看到除了单词enjoyed,其他所有单词都在词表中。此时,我们不会将该单词替换为未知词,而是将它继续拆分为子词:[enjoy, ed]。
tokens = [ I, enjoy, ##ed, the, game] 我们可以看到ed前面有两个#。这代表##ed是一个子词,而且它前面有另一个单词。我们不会为单词拆分后的第一个子词增加##符号,这就是为什么子词enjoy前面没有#。这样子词Tokenization处理了未知词,也就是没有出现在词表中的单词。
现在问题是,我们知道我们将单词played和walked拆分成子词,然后增加它们的子词到词表中。但是为什么我们只拆分这些单词呢?为什么不是词表中的其他单词?我们如何决定哪些单词要拆分,哪些不要?这就是子词Tokenization算法起作用的地方。
3.Subword Tokenization算法
3-1 字节对编码(Byte pair encoding,BPE)
3-1-1 BPE简介
BPE最早是一种数据压缩算法,由Sennrich等人于2015年引入到NLP领域并很快得到推广。该算法简单有效,因而目前它是最流行的方法。GPT-2和RoBERTa使用的Subword算法都是BPE。BPE算法的步骤如下:
1.给定的数据集中抽取单词以及相应的频次,并确定词表大小;
2.将单词拆分为字符序列,比如英文中26个字母加上各种符号,这些作为初始词表;
3.将所有字符序列中的字符不重复地添加到词表中,选择并合并频次最高的相邻字符对;
4.重复步骤3直到满足词表大小。
3-1-2 BPE实例
下面以一个例子来说明。
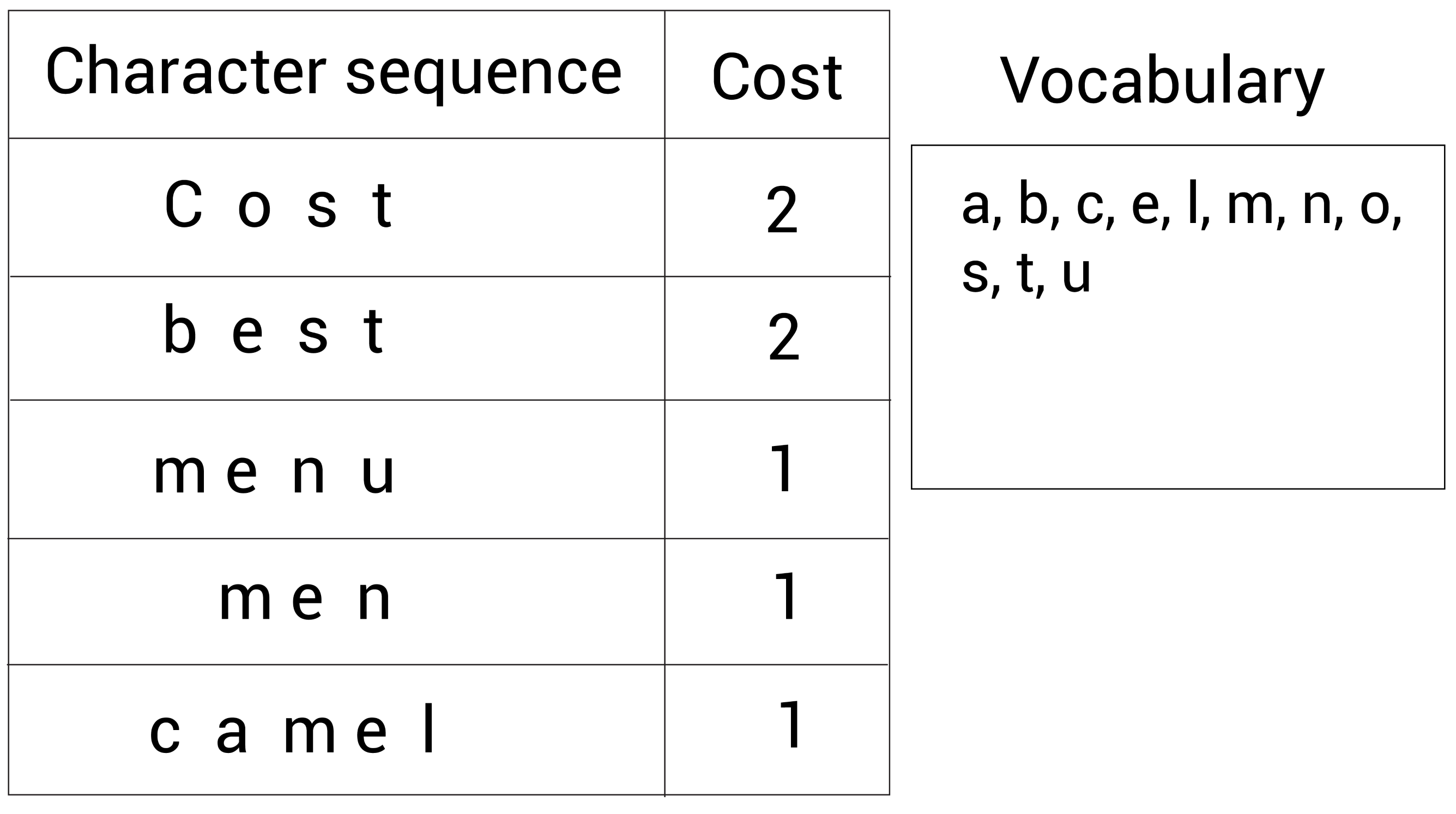
1.假设有语料集经过统计后表示为:(cost, 2), (best, 2), (menu, 1), (men, 1),(camel, 1)。
2.将这些单词拆分成字符变成一个字符序列,并定义要构建Subword词表大小为14。下面的表格显示这些字符序列以及它们对应的单词次数:
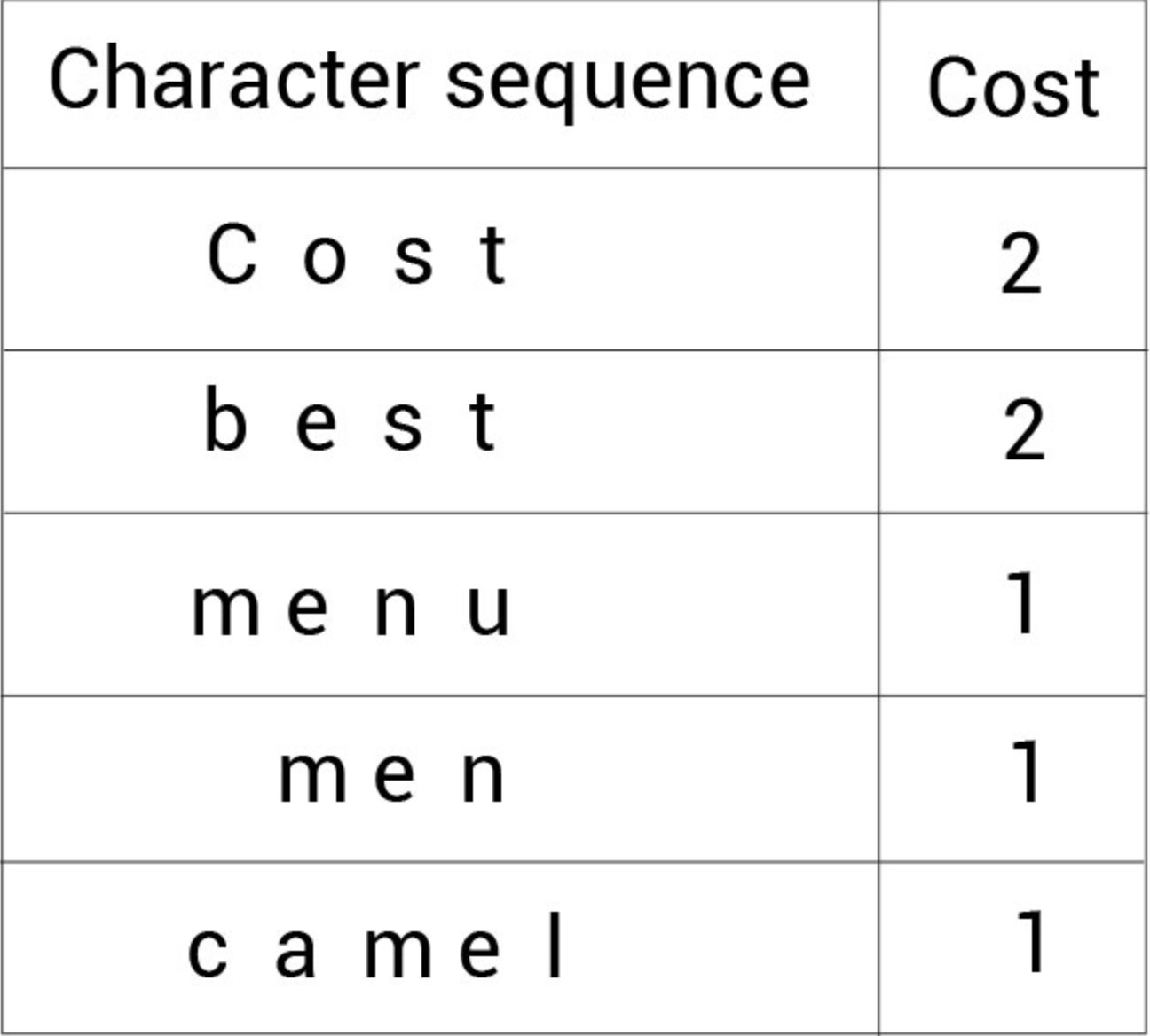
3. 将所有字符序列中的字符不重复地添加到词表中:

现在的词表(右边的Vocabulary)大小为 11。下面看看如何增加新标记到词表中。
首先,我们找出出现次数最多的相邻的字符对。然后我们合并这个字符对并加入到词表中。我们不断重复该步骤知道达到词表大小。让我们来看下具体细节。
看下面的字符序列,我们能观察到出现最多的字符对是s和t,因为s和t相邻地出现了4次:

所以,我们合并这两个字符s和t成st,并将st加入到词表,现在的词表(右边的Vocabulary)大小为 12,仍然需要添加新的subword到词表中。
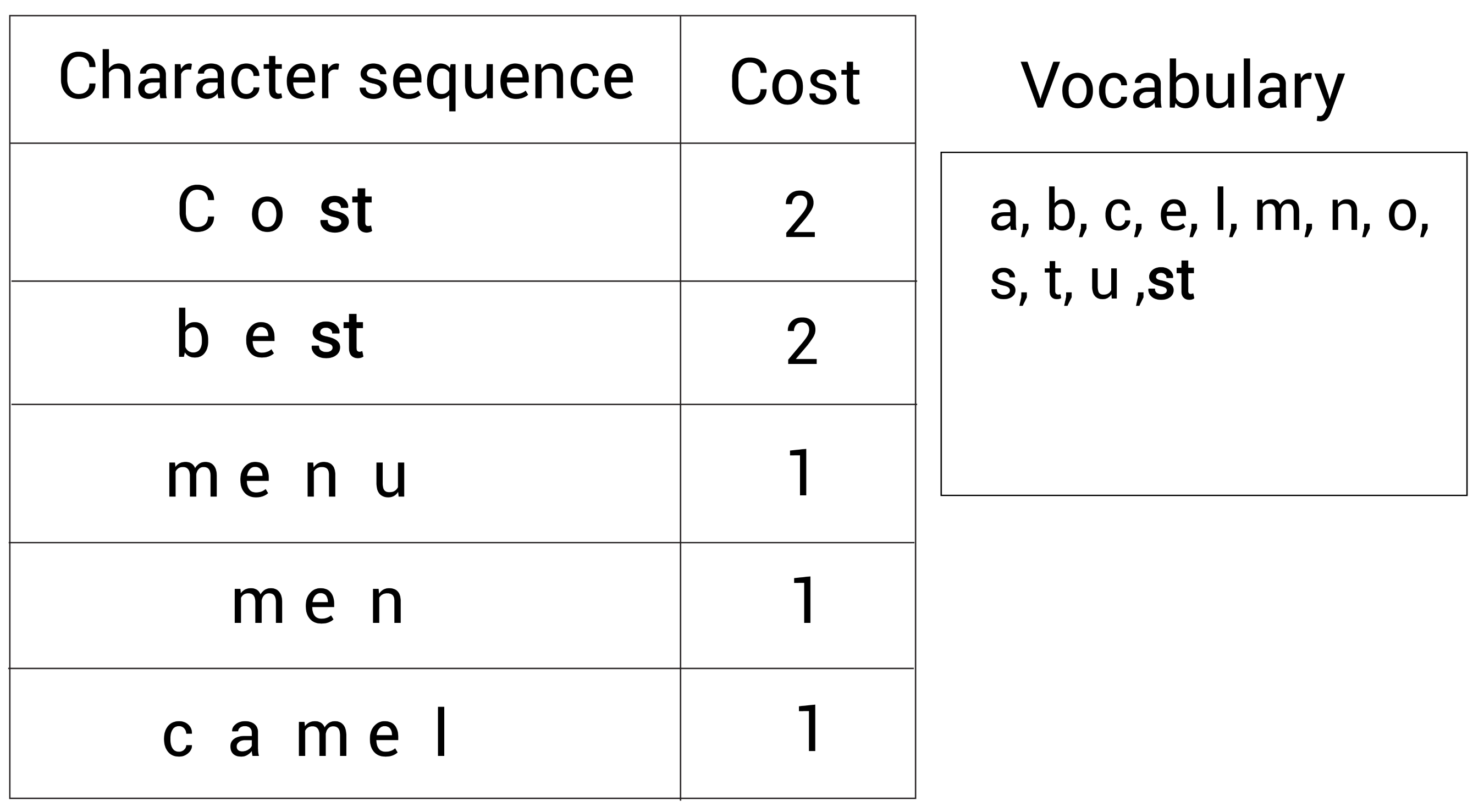
接着,我们重复这一步骤。我们继续寻找出现最多的相邻字符对。我们又发现了现在最频繁的字符对是m和e,它们出现了3次。
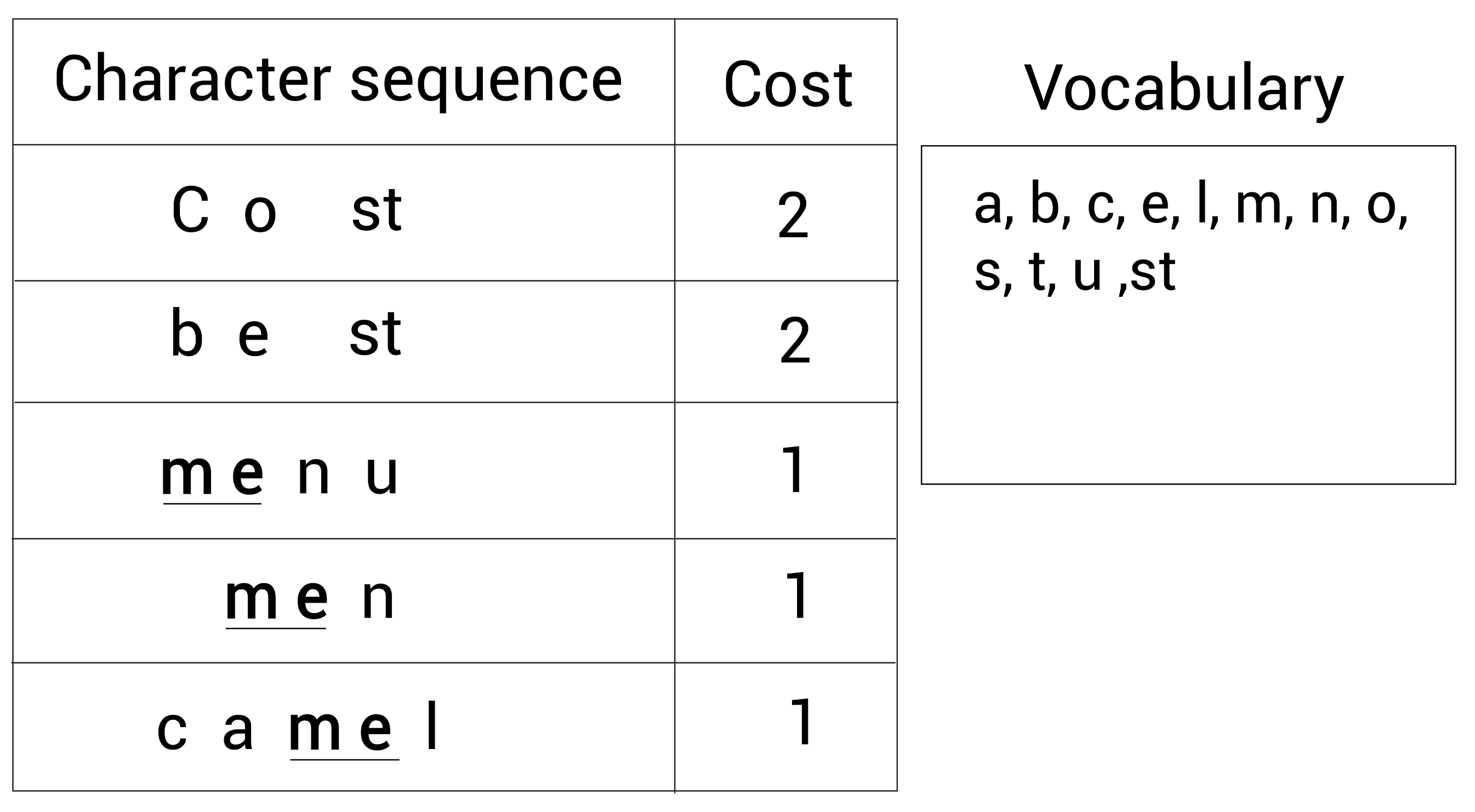
所以我们合并字符m和e为me并加入词表, 现在的词表(右边的Vocabulary)大小为 13,仍然需要添加新的subword到词表中:

再一次,我们继续检查出现最多的字符对。我们此时发现最常见的字符对是me和n,它们一起出现了2次:
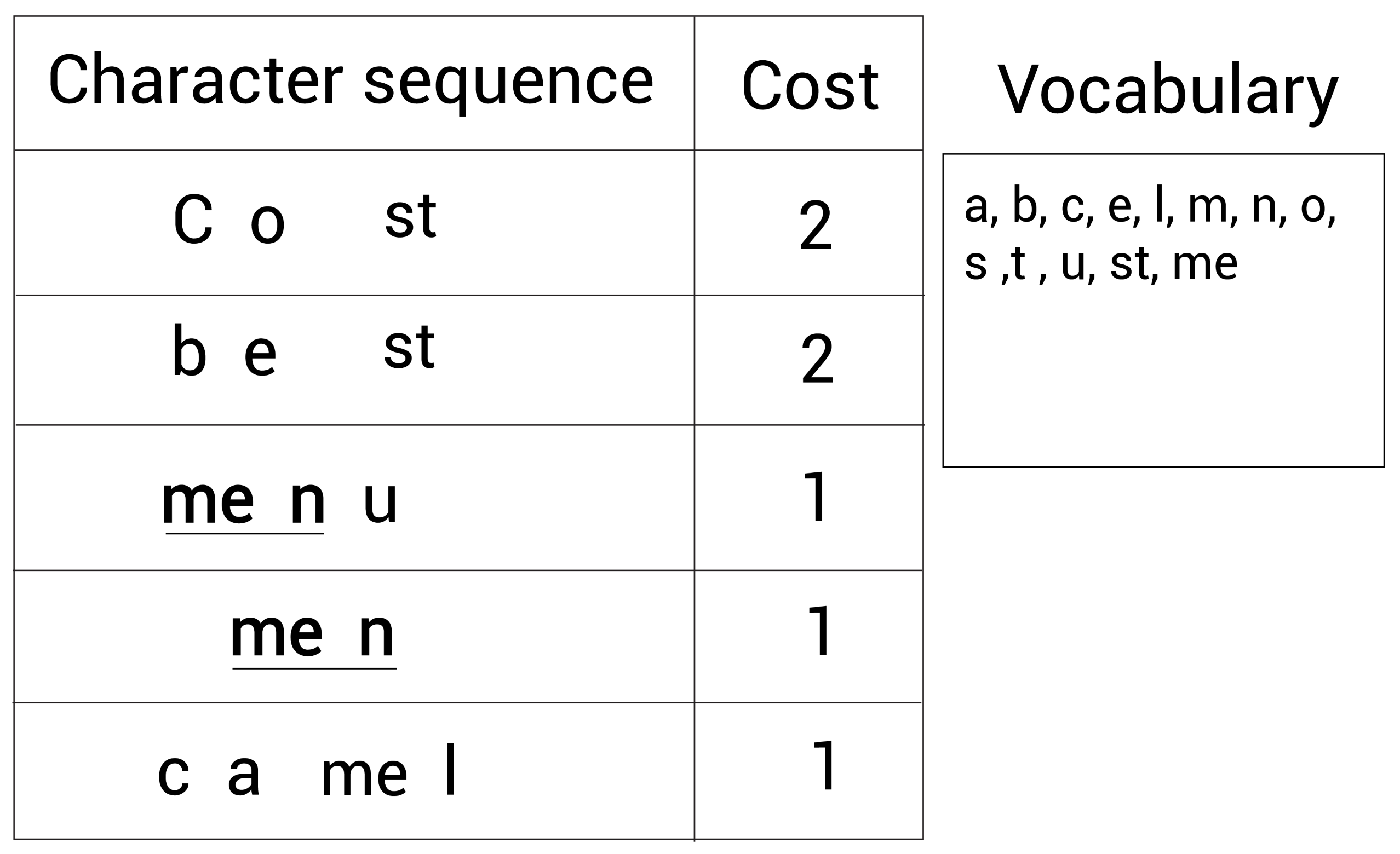
所以,我们继续合并me和n为men,然后加入词表,现在的词表(右边的Vocabulary)大小为 14,词表大小达到了预定义的值,BPE算法停止。

在本例中,使用BPE算法创建了大小为 14的词表:
vocabulary = {a,b,c,e,l,m,n,o,s,t,u,st,me,men}
3-1-3 BPE词表分词实例
假设输入文本只包含一个单词,我们目前有三个文本,分别是mean、star、men,我们使用BPE算法创建的词表进行分词。
1.mean
首先检查单词mean是否出现在词表中,检查后发现此单词并未出现在词表中。所以我们将该单词进行拆分,首先拆分为两个子词[me, an];然后检查这些子词是否出现在词表中;发现me出现在词表中,an则没有;因此,继续拆分子词an,所以现在子词包含[me, a, n]。现在检查字符a和n是否出现在词表中,现在拆分的所有子词都出现在了词表中,因此我们最终得到的标记如下:
tokens = [me,a,n] 2.star
首先检查单词star是否出现在词表中,检查后发现此单词并未出现在词表中。所以我们拆分为子词[st, ar];然后检查子词是否在词表中;发现子词st在词表中,而ar不在;下面继续拆分子词ar,所以现在子词包括[st, a, r]。现在我们检查字符a和r是否在词表中。显然a在而r不在。因为我r只是一个字符,所以我们无法继续拆分,因此只能将它替换为<UNK>标记,这样我们最终的标记为:
tokens = [st,a,<UNK>] 我们知道BPE可以很好的处理稀有词,但是现在我们有一个<UNK>标记。这是因为我们的例子很小,字符r没有出现在词表中。如果我们用一个较大的语料库创建词表,我们的词表肯定会包含所有的字符。
3.men
首先检查单词men是否出现在词表中,检查后发现此单词出现在词表中。最终得到的标记为:
tokens = [men]3-2 字节级字节对编码(Byte-level byte pair encoding,BBPE)
3-2-1 BBPE简介
BBP的分词算法是针对于字符级别的,而BBPE是针对于字节级的,所以就有了字节级的字节对编码存在的意义。BBP不是将单词转换为字符序列,而是转换为字节序列。
3-2-2 实例
假设输入文本仅包含一个单词best。我们知道在BPE中,我们可以将该单词拆分为字符序列,可以得到:
Character sequence: b e s t然而在BBPE中,不是将单词转换为字符序列,而是转换为字节序列。我们该单词转换为如下的字节序列。这样,每个Unicode字符都转换成一个字节。单个字符可以包含1到4个字节。
Byte sequence: 62 65 73 74 假设输入是一个中文词汇:你好。现在,我们将它转换为字节级序列,得到:
Byte sequence: e4 bd a0 e5 a5 bd
通过这种方式,我们先将文本转换为字节级序列,然后应用BPE算法根据字节级符号对构建词表就可以了。
BBPE对于多语言情况下非常有用,它能非常有效地处理未登录词,同时处理多语言词表也非常出色。
3-3 WordPiece
3-3-1 WordPiece 简介
Google的Bert模型在分词的时候使用的是WordPiece算法。 与BPE算法类似,WordPiece算法也是每次从词表中选出两个子词合并成新的子词。与BPE的最大区别在于,如何选择两个子词进行合并:BPE选择频数最高的相邻子词合并,而WordPiece选择能够提升语言模型概率最大(似然概率)的相邻子词加入词表。所以我们合并在给定训练集上训练的语言模型中具有最高概率的字符对。
假设句子S=(t1,t2,...,tn)由n个子词组成,ti表示子词,且假设各个子词之间是独立存在的,则句子S的语言模型似然值等价于所有子词概率的乘积:
![]()
假设把相邻位置的x和y两个子词进行合并,合并后产生的子词记为z,此时句子S似然值的变化可表示为:
![]()
似然值的变化就是两个子词之间的互信息。简而言之,WordPiece每次选择合并的两个子词,他们具有最大的互信息值,也就是两子词在语言模型上具有较强的关联性,它们经常在语料中以相邻方式同时出现。
3-3-2 实例
在BPE中,合并的是最高频次的字符对。在BPE中,我们会合并s和t,因为它们一起出现的频次最高。
但是现在,在WordPiece中,会根据似然来合并单词。首先,会检查语言模型(通过给定数据集训练的语言模型)输出的每个字符对出现的概率。然后选取概率最高的那一对。字符对s和t出现的概率可以计算为:
![]()
如果它们的概率是最高的,那么我们就合并它们并加入到词表中。这样,我们就计算了每个字符对出现的概率并合并概率最高的那一对到词表中。
3-3-3 WordPiece词表分词实例
假设根据WordPiece构建的词表如下:
vocabulary = {a,b,c,e,l,m,n,o,s,t,u,st,me}
假设输入文本只包含一个单词:stem,我们使用WordPiece算法创建的词表进行分词。 首先检查单词stem是否出现在词表中,检查后发现此单词并未出现在词表中;下面所以我们拆分为子词[st, ##em],接下来我们检查是否这些子词出现在词表中;发现子词st在词表中,而em不在。我们继续拆分子词em,现在我们得到的子词为:[be, ##e, ##m]。现在我们继续检查是否字符e和m出现在词表中。因为它们都在词表中,所以我们最终得到的标记为:
tokens = [st, ##e, ##m] 3-4 Unigram Language Model (ULM)
3-4-1 ULM简介
与WordPiece一样,Unigram Language Model(ULM)同样使用语言模型来挑选子词。不同之处在于,BPE和WordPiece算法的词表大小都是从小到大变化,属于增量法。而Unigram Language Model则是减量法,即先初始化一个大词表,根据评估准则不断丢弃词表,直到满足限定条件。ULM算法考虑了句子的不同分词可能,因而能够输出带概率的多个子词分段。
对于句子S=(x1,x2,...,xm)为句子的一个分词结果,由m个子词组成。所以,当前分词下句子S的似然值可以表示为:
![]()
对于句子S,挑选似然值最大的作为分词结果,则可以表示为:
![]()
这里U(x)包含了句子的所有分词结果。在实际应用中,词表大小有上万个,直接罗列所有可能的分词组合不具有操作性。针对这个问题,可通过维特比算法得到来解决。
ULM通过EM算法(期望最大算法)来估计每个子词的概率P(xi)。假设当前词表V, 则M步最大化的对象是如下似然函数:

其中,|D|是语料库中语料数量。上述公式的一个直观理解是,将语料库中所有句子的所有分词组合形成的概率相加。
初始时,词表V并不存在。因而,ULM算法采用不断迭代的方法来构造词表以及求解分词概率:
1.初始时,建立一个足够大的词表。一般,可用语料中的所有字符加上常见的子字符串初始化词表,也可以通过BPE算法初始化。
2.针对当前词表,用EM算法求解每个子词在语料上的概率。
3.对于每个子词,计算当该子词被从词表中移除时,总的loss降低了多少,记为该子词的loss。
4.将子词按照loss大小进行排序,丢弃一定比例loss最小的子词(比如20%),保留下来的子词生成新的词表。这里需要注意的是,单字符不能被丢弃,这是为了避免OOV情况。
5.重复步骤2到4,直到词表大小减少到设定范围。
ULM会保留那些以较高频率出现在很多句子的分词结果中的子词,因为这些子词如果被丢弃,其损失会很大。
Reference:

