
- 1Cesium介绍及3DTiles数据加载时添加光照效果对比_cesium光照
- 2RabbitMQ的死信队列详解及实现_获取死信队列中的信息
- 3PeLK:通过周边卷积的参数高效大型卷积神经网络
- 4react 暂存数据持久化_react store 数据持久化
- 5Map集合和Collections(集合工具类)_collections工具类中的binarysearch()方法中的key是map中的键吗
- 6如何解决Git合并分支造成的冲突_git合并出现冲突是如何解决的
- 7jmeter 性能测试结果分析_jmeter结果分析
- 8在Git上放一个静态页面并且可以访问_gitlab 怎么发布静态页面
- 9机械臂视觉抓取总结_机械臂目标定位与抓取
- 10Jupyter 进阶教程
sentencepiece原理与实践_sentencepieces
赞
踩
1 前言
前段时间在看到XLNET,Transformer-XL等预训练模式时,看到源代码都用到sentencepiece模型,当时不清楚。经过这段时间实践和应用,觉得这个方法和工具值得NLP领域推广和应用。今天就分享下sentencepiece原理以及实践效果。
2 原理
sentencepiece由谷歌将一些词-语言模型相关的论文进行复现,开发了一个开源工具——训练自己领域的sentencepiece模型,该模型可以代替预训练模型(BERT,XLNET)中词表的作用。开源代码地址为:https://github.com/google/sentencepiece。其原理就相当于:提供四种关于词的切分方法。这里跟中文的分词作用是一样的,但从思路上还是有区分的。通过使用我感觉:在中文上,就是把经常在一起出现的字组合成一个词语;在英文上,它会把英语单词切分更小的语义单元,减少词表的数量。
例如“机器学习领域“这个文本,按jieba会分“机器/学习/领域”,但你想要粒度更大的切分效果,如“机器学习/领域”或者不切分,这样更有利于模型捕捉更多N-gram特征。为实现这个,你可能想到把对应的大粒度词加到词表中就可以解决,但是添加这类词是很消耗人力。然而对于该问题,sentencepiece可以得到一定程度解决,甚至完美解决你的需求。
模型在训练中主要使用统计指标,比如出现的频率,左右连接度等,还有困惑度来训练最终的结果。了解算法细节可以去githup上查看相关论文。
3 安装
GitHub官网提供了二种安装方式,第一种是通过vcpkg:
- git clone https://github.com/Microsoft/vcpkg.git
- cd vcpkg
- ./bootstrap-vcpkg.sh
- ./vcpkg integrate install
- ./vcpkg install sentencepiece
第二种方式通过C++方式安装:
需要依赖的包有:
- cmake
- C++11 compiler
- gperftools library (optional, 10-40% performance improvement can be obtained.)
安装步骤先从githup把源码download下来,然后
- % cd /path/to/sentencepiece
- % mkdir build
- % cd build
- % cmake ..
- % make -j $(nproc)
- % sudo make install
- % sudo ldconfig -v
4 训练
安装成功,就可以用自己的领域文本数据进行训练,训练的代码指令为:
spm_train --input='/home/deploy/sentencepiece/news_corpus.txt' -- model_prefix='/home/deploy/sentencepiece/mypiece' --vocab_size=320000 --character_coverage=1 --model_type='bpe'
参数说明:
input 训练语料,形式为一行一段文本
model_prefix 模型输出的路径
vocab_size 训练后词表的大小,数量越大训练越慢,太小(<4000)可能训练不了
character_coverage 模型中覆盖的字符数,默认是0.995,中文语料设置为1
model_type 训练时模型的类别:
max_sentence_length 最大句子长度,默认是4192,长度貌似按字节来算,意味一个中文字代表长度为2
max_sentencepiece_length 最大的句子块长度,默认是16
seed_sentencepiece_size 控制句子数量,默认是100w
num_threads 线程数,默认是开16个
use_all_vocab 使用所有的tokens作为词库,不过只对word/char 模型管用
input_sentence_size 训练器最大加载数量,默认为0
5 测试
训练完模型后,可以调用模型进行效果测试。在调用模型前,先安装对应的python包:
pip install sentencepiece
具体是,我使用大小约1G的NLP相关的语料库,分别训练unigram和bpe两种模型。另外,我还对比了XLNET开源的中文sentencepiece模型,以及jieba分词效果。
- def sentence_piece():
- import sentencepiece as spm
- sp = spm.SentencePieceProcessor()
- text="讲解了一下机器学习领域中常见的深度学习LSTM+CRF的网络拓扑 17:了解CRF层添加的好处 18:
- EmissionScore TransitionScore 19:CRF的目标函数 20:计算CRF真实路径的分数"
- print("*****************text****************")
- print(text)
- print("*****************jieba****************")
- print(' '.join(jieba.cut(text)))
- print("*****************XLNET sentencepiece****************")
- sp.Load("/home/deploy/pre_training/spiece.model")
- print(sp.EncodeAsPieces(text))
- print("***************** unigram_sentencepiece****************")
- sp.Load("/home/deploy/pre_training/sentencepiece/mypiece_unigram.model")
- print(sp.EncodeAsPieces(text))
- print("***************** bpe_sentencepiece****************")
- sp.Load("/home/deploy/pre_training/sentencepiece/mypiece_pbe.model")
- print(sp.EncodeAsPieces(text))

测试结果如下:
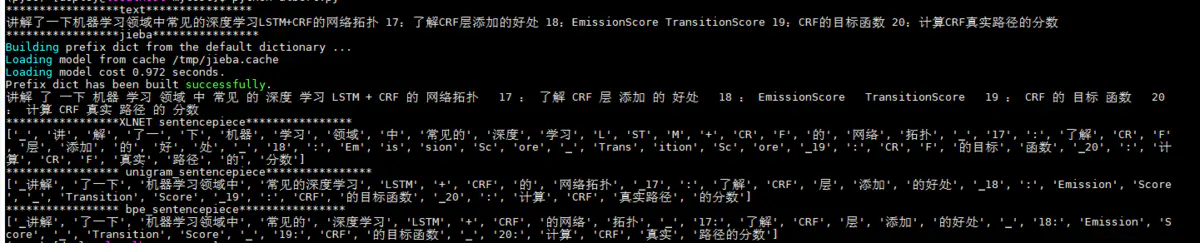
6 结语
从测试结果可以看出:sentencpiece更倾向输出更大粒度的词,像把“机器学习领域中”放在一起,说明这个词语在语料库中出现的频率很高。XLNET中别人开源的模型跨领域表现的并不好,在面向自己应用场景时,需自己训练。此外,与jieba对比,会发现后者切分的可能并不是一个语言词,例如“的网络”,但这个N-gram特征对模型来说影响并不是很大。
就个人来说,我觉得sentencpiece给我带来了一定的惊喜,后续我会用它在下游任务上进行测试,再进一步验证它的效果,比如text-cnn文本分类。不过,我觉得它还是有改进空间的,像切分如“的网络”这样的结果,加一个停用词处理流程,可能会更好。
作者:烛之文
链接:https://www.jianshu.com/p/d36c3e06fb98
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


