- 1Android 之一 Android Studio 安装、配置等新手入门 + 百度地图定位 + 移动摇杆 的实现_ndk was located by using ndk.dir property. this me
- 2UI 自动化测试框架:PO 模式+数据驱动 【详解版】_po框架
- 3UTAustin最新提出!无相机姿态40秒重建3DGS方法_无需相机参数三维重建
- 4【小程序开发必备】微信小程序常用API全介绍,附示例代码和使用场景_微信小程序代码大全
- 5Mac OS X 10.10 Yosemite 关闭Dashboard和Spotlight_spotlightv100能删除吗
- 6Pycharm报错torch.cuda.OutOfMemoryError: CUDA out of memory.
- 7Drools基础篇-01-规则引擎简单介绍_drools规则引擎
- 8华为云注册登录之图像标签识别_华为云aksk登录
- 9DDoS攻击原理是什么?DDoS攻击原理及防护措施介绍_ddos 不挂科
- 10自动化测试(UI)----PO设计模式_自动化测试模式
Python深度学习——卷积神经网络_python 卷积神经网络
赞
踩
前言
与传统神经网络(NN)相同,卷积神经网络(CNN)的目的是对图片进行特征提取,然后识别。但传统神经网络的参数矩阵特别大,训练时需要花的时间比较多,而且过拟合风险更大,而卷积神经网络可以解决这些问题。
二者还有一个区别在于,以28*28的分辨率为例,传统神经网络中,输入的是784个像素点,而卷积神经网络输入的是原始的图像28*28*1,是三维的。
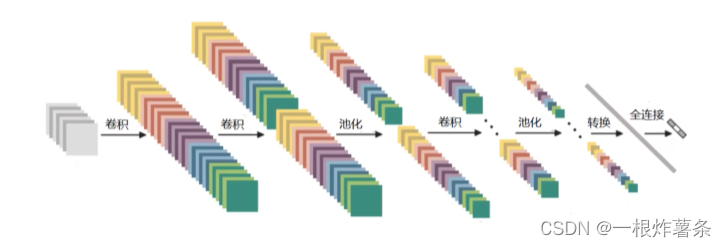
整体架构:输入层+卷积层+池化层+全连接层。
一、卷积层
1、原理
卷积,先把图像分割成很多个小区域,每个小区域由多个像素点组成,提取每个区域的特征。用一组权重参数得到一个特征值 。
卷积核(filter):也叫滤波器,可以看作是一个小的矩阵,用于提取输入数据中的特征。卷积操作通过将卷积核在输入数据上滑动,计算每个位置的内积(原始输入数据*权重参数,累加,再加偏置参数),从而生成输出特征图。权重参数和偏置参数最开始是随机的(一般从高斯分布里选),训练过程中学习并优化。

图像颜色通道:上图只演示了B通道的计算,实际上要将三个颜色通道R、G、B的结果相加,才能得到最终的特征值。
可以用多个卷积核进行特征提取,不同的卷积核对应不同的权重参数,得到的特征图就会不一样,从而实现多尺度多力度的特征提取,得到更丰富的特征。但在每一次卷积中,卷积核的大小规格要一样。
卷积操作要进行很多次,第一次对原始数据做卷积只是得到中阶特征,再一次卷积可以得到高阶特征,不断重复卷积操作,增加卷积核个数,就会得到效果更好的特征。
2、相关参数
滑动窗口步长:步长小的时候,提取到的特征更丰富。图像任务一般步长是1,但是效率慢。
卷积核尺寸:和步长同理,不同尺寸得到不同结果,最小的一般是3x3.
边缘填充:在移动卷积核的时候,前一次位置和下一次位置会有重叠,而重叠部分的数据会被计算两次,对结果的贡献更大。越靠近边界的点被计算的次数越少,而越靠近中间的点被计算的次数越多。但是边界的点并非不重要,所以就用到边缘填充,让原本边界的点不再是边界,一定程度上弥补了边界信息缺失的问题。一般用0填充,计算的时候对结果没影响。比如这样: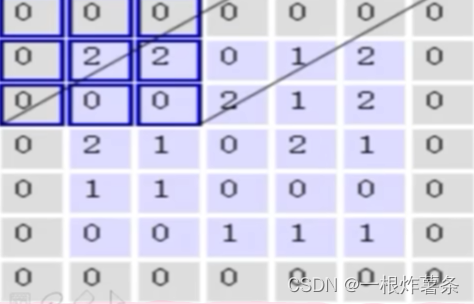
卷积核个数:最终要得到多少个特征图,那就需要多少个卷积核。但每个卷积核里的参数是不一样的,一开始是随机数,后面要进行各自参数更新。
3、特征图尺寸
特征图尺寸也就是卷积的结果,有这样一个计算公式:
其中W1、H1表示输入的宽度、长度;W2、H2表示输出的特征图的宽度、长度;F表示卷积核长和宽的大小;S表示滑动窗口的步长;P表示边界填充(加几圈0)。
4、卷积参数共享
在对每一个小区域卷积时,保证用同一个卷积核,即卷积核参数不变。如果用不同的卷积核,那数据量会非常大,训练时间会很长,过拟合风险也会很大,这些都是传统神经网络的缺点。
每个卷积核还有一个参数叫偏置参数,与结果相关。
二、池化层
经过卷积层的操作后,我们得到非常多的特征,但并不是所有特征都重要,所以需要池化层来压缩,选择性丢弃一些不重要的特征。但它只会改变特征图,不会改变特征图的个数。比如224x224x64的数据经过池化层变成112x112x64.
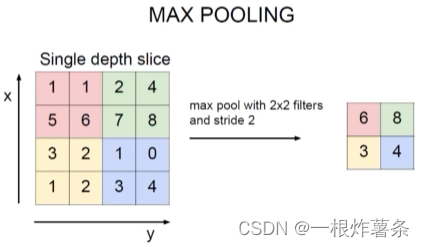
最大池化(Max Pooling):先选择不同区域,每个区域中选最大值,没有计算,只是筛选。而选最大值是因为经过卷积层的计算后,重要特征的值会更大,即只要最好的特征。
三、全连接层
卷积和池化过后,我们得到的还是三维的数据,但三维的数据并不能与我们最终的n个分类做全连接。所以需要把三维的数据拉伸为一维数据,比如32*32*10的数据可以转换为10240个特征,然后我们就可以把这10240个特征转化为我们预测的n个分类的概率值,得出分类结果。
总结
卷积神经网络的过程是先对数据卷积,卷积的过程中往往带有RELU函数,这和传统神经网络一样,随后就进行池化。但并不是完成所有卷积后才池化,而是每进行若干次卷积就进行一次池化,接着再卷积、再池化。
N层卷积神经网络如何定义。在卷积神经网络中,只有带参数的才称之为层。比如卷积层带参数,池化层不带参数,全连接层带参数 ,则最后的N就等于卷积次数+1.