
- 1银河麒麟linux系统如何禁用触摸板_麒麟系统 设置触摸板在有鼠标的情况下禁用
- 2CSerialPort教程(1) - CSerialPort项目简介
- 3FRP内网穿透 + Nginx代理 + 获取真实IP_nginx grpc ip穿透
- 4Docker Resources
- 5通过命令iostat,iotop查看Linux系统IO性能,信息指标分析详解_d_await指什么
- 6Visual Studio安装MFC开发组件
- 7GoWeb——Gin框架的使用_fabric-sdk-go与gin框架应用
- 8Web3小白解惑系列:区块链入门(第三弹)_比特币halving
- 9使用c++类模板和迭代器进行List模拟实现
- 10C++领域新星创作者的申请与创作流程分享_csdn创作者认证要上传什么资料
Kafka概念及组件介绍_kagka fentch
赞
踩
Kafka--分布式消息队列系统
1、分布式消息队列系统,先入先出,同时提供数据分布式缓存功能
2、消息持久化:数据读取速度可以达到O(1)——预读,后写(按顺序,ABCDE,正读A,预读B;尾部追加写)对磁盘的顺序访问比内存访问还快)
一、kafka快原因:
1.cache缓存+
2.顺序写入(写数据,磁盘顺序)+
3.零拷贝(1.让操作系统cache中的数据发送到网卡2.网卡传出给下游的消费者)
4.批量发送 +数据压缩
Kafka总结:分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统
二、保证消息的可靠性,至少需要配置一下参数:详细看下边13.
topic级别:replication-factor>=3; 多副本
producer级别:acks=-1;同时发送模式设置producer.type=sync;
ack=-1:producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高
broker级别:关闭不完全的leader选举,即unclean.leader.election.enable=false;
三、kafka作用:消息缓冲 ,flume百万条 ,而sparkstreaming只能处理几万条,中间需要kafka缓冲
1. kafka特性:
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
Kafka应用场景
主要应用场景是:日志收集、消息系统、用户活动跟踪、运营指标、流式处理等
- 消息系统
- 日志系统
- 流处理
2.组件说明
• Kafka内部是分布式的、一个Kafka集群通常包括多个Broker
• zookeeper负载均衡:将Topic分成多个分区,每个Broker存储一个或多个Partition
• 多个Producer和Consumer同时生产和消费消息
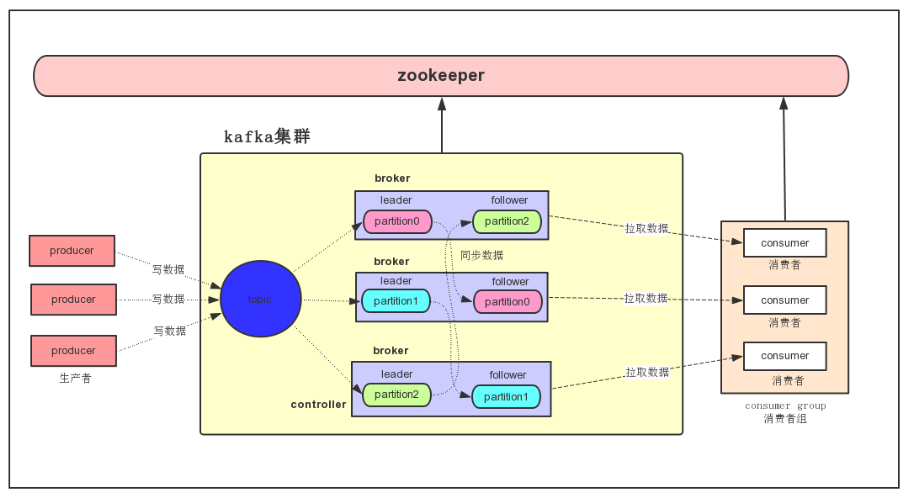
1.Broker:每个kafka实例(server),可以理解为一台机器(节点)
2.Producer:消息生产者,发布消息(写消息)到 kafka 集群的终端或服务。
-
生产者可以发布数据到它指定的topic中,并可以指定在topic里哪些消息分配到哪些分区(比如简单的轮流分发各个分区或通过指定分区语义分配key到对应分区)
- 生产者直接把消息发送给对应分区的broker,而不需要任何路由层。
- 批处理发送,当message积累到一定数量或等待一定时间后进行发送。
3.Consumer:从kafka 集群中消费消息(读数据)的终端或服务。
-
一种更抽象的消费方式:消费组(consumer groupid)streaming
- 该方式包含了传统的queue和发布订阅方式
– 首先消费者标记自己一个消费组名。消息将投递到每个消费组中的某一个消费者实例上。
– 如果所有的消费者实例都有相同的消费组,这样就像传统的queue方式。
– 如果所有的消费者实例都有不同的消费组,这样就像传统的发布订阅方式。
– 消费组就好比是个逻辑的订阅者,每个订阅者由许多消费者实例构成(用于扩展或容错)。
- 相对于传统的消息系统,kafka拥有更强壮的顺序保证。
- 由于topic采用了分区,可在多Consumer进程操作时保证顺序性和负载均衡。
- 同一个group的consumer可以并行消费同一个topic的消息,但是同group的consumer,不会重复消费

4.Topic(虚拟概念)队列:每条发布到 kafka 集群的消息属于的类别, kafka 是面向 topic 的
Topic 与offset
• 一个Topic是一个用于发布消息的分类或feed名,kafka集群使用分区的日志,每个分区都是有顺序且不变的消息序列。
• commit的log可以不断追加。消息在每个分区中都分配了一个叫offset的id序列来唯一识别分区中的消息。
1. 无论有没有消费,消息会被清理(如果没有消费,消息会一直持久化,通过以下两配置清理)
(1)配置持久化周期:7天 (2)配置最大的数据量
2.在每个消费者都持久化这个offset在日志中。通常消费者读消息时offset值会线性的增长,但实际上其位置是由消费者
控制,它可以按任意顺序来消费消息。比如复位到老的offset来重新处理。
3.每个分区代表一个并行单元。
5.分区Partition:每个 topic 包含一个或多个 partition。kafka 分配的单位是 partition
-
存储,实现负载均衡(不同partiton可分布在不同机器),保证消息顺序性
-
顺序性保证:局部顺序性(顺序性得到一定保证:订阅消息是从头向后读的,写消息是尾部追加的)
-
Partition以文件夹形式存在
大多数消息系统,同一个topic下的消息,存储在一个队列。分区的概念就是把这个队列划分为若干个小队列,每一个小队列就是一个分区,如下图:
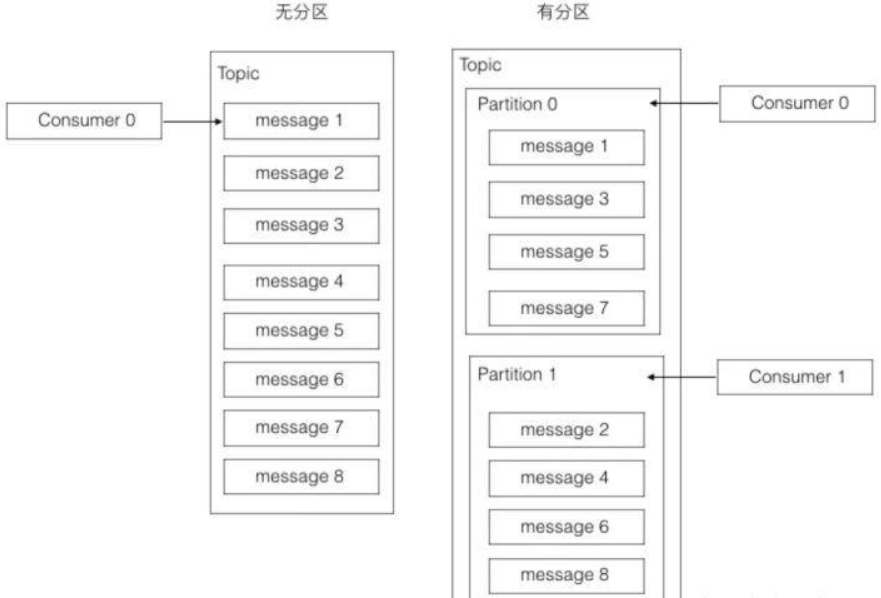
从上图已经可以看出来。无分区时,一个topic只有一个消费者在消费这个消息队列。采用分区后,如果有两个分区,最多两个消费者同时消费,消费的速度肯定会更快。如果觉得不够快,可以加到四个分区,让四个消费者并行消费。
分区的设计大大的提升了kafka的吞吐量!!!
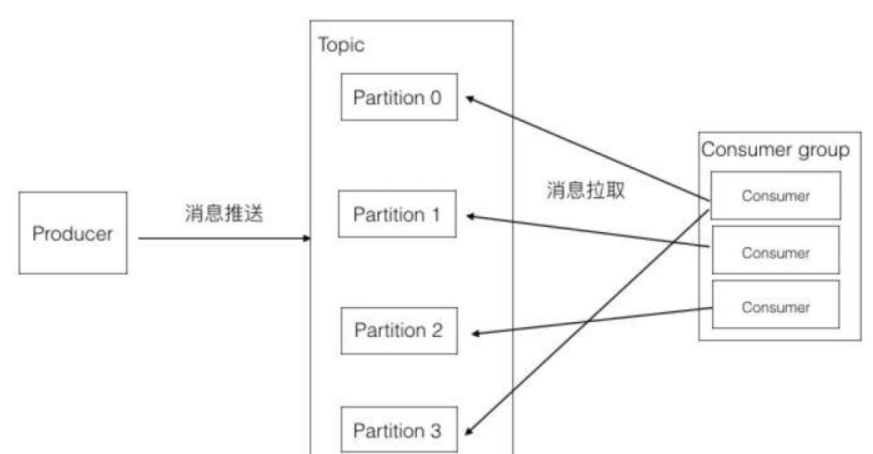
此图包含如下几个知识点:
1、一个partition只能被同组的一个consumer消费(图中只会有一个箭头指向一个partition)
2、同一个组里的一个consumer可以消费多个partition(图中第一个consumer消费Partition 0和3)
3、消费效率最高的情况是partition和consumer数量相同。这样确保每个consumer专职负责一个partition。
4、consumer数量不能大于partition数量。由于第一点的限制,当consumer多于partition时,就会有consumer闲置。
5、consumer group可以认为是一个订阅者的集群,其中的每个consumer负责自己所消费的分区
Topic和Partition关系:
每个partition都是有序的不可变的。
Kafka可以保证partition的消费顺序,但不能保证topic消费顺序。

(1)topic是逻辑概念,Partition是物理概念,一个或多个Partition组成了一个Topic。
(2)topic中的多个partition以文件夹的式保存到broker(每个文件夹保存内容不一样),每个分区序号从0递增,且消息有序
注:一般多少表就有多少topoc,但有一些同类表可能会预聚合存放在一个topic里
Partition有2个部分组成:(1)index log(定位索引信息) (2)message log(存储真实数据)
查找:二分法+顺序遍历(解决给定一个顺序数字队列,如何快速找到其中某个值的位置?)
6. Segment:partition物理上由多个segment组成。
7. offset : 每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续递增的序列号叫做offset,偏移量offset在每个分区中是唯一的。
偏移量offset(在topic中存在offset),定位数据读取的位置(不仅要确定读offset的位置,更要是哪个partition中读)

offset 位置:消费者在对应分区上已经消费的消息数(位置) offset保存的地方跟kafka版本有一定的关系。
kafka0.8 版本之前offset保存在zookeeper上。
kafka0.8 版本之后offset保存在kafka集群上。
-
LEO:每个副本的最后一条消息的offset
-
HW:一个分区中所有副本最小的offset
Offset命名:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然thefirst offset就是00000000000.kafka。
Kafka的消息是无状态,降低Kafka实现的难度,消费者必须自己维护已消费的状态信息
8.replica副本:partition 的副本,保障 partition 的高可用(多副本实现)。
Kafka分区多副本是Kafka可靠性的核心保证,把消息写入到多个副本可以使Kafka在崩溃时保证消息的持久性及可靠性。
topic下会划分多个partition,每个partition都有自己的replica,其中只有一个是leader replica,其余的是follower replica。
Topic、partition、replica的关系如下图:

-
副本可以在设置主题的时候可以通过replication-factor参数来设置,也可以在broker级别中设置defalut.replication-factor来指定,一般我们都设置为3;
-
三个副本中有一个副本是leader,两个副本是follower,leader负责消息的读写,follower负责定期从leader中复制最新的消息,保证follower和leader的消息一致性,当leader宕机后,会从follower中选举出新的leader负责读写消息,通过分区副本的架构,虽然引入了数据冗余,但是保证了kafka的高可靠。
• follower: replica 中的一个角色,从 leader 中复制(fentch)数据。
• leader: replica 中的一个角色, producer 和 consumer 只跟 leader 交互。
• controller:kafka 集群中的其中一个服务器,用来进行 leader election 以及各种 failover。
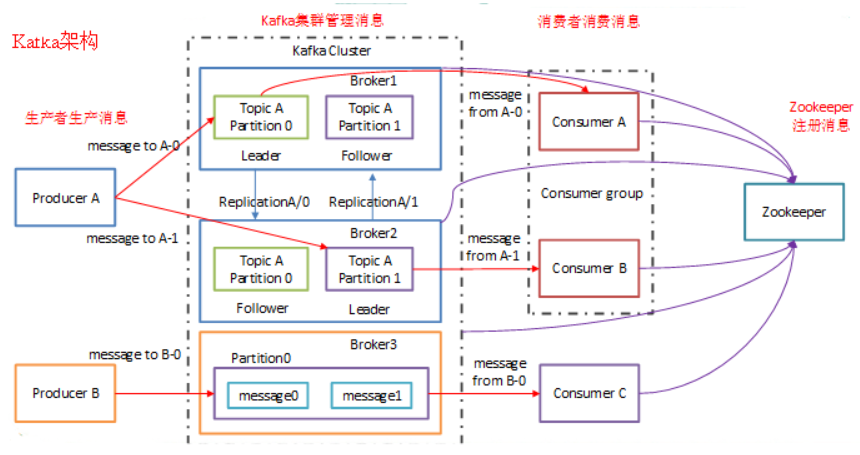
9.zookeeper:
kafka 通过 zookeeper 来存储集群的 meta 信息和偏移量(offset)。
Kafka需要和zookeeper联合部署,Zookeeper保证了Kafka系统可用性,Topic中的一些信息也要保存Zookeeper中。
(1) Kafka 通过 zookeeper 来存储集群的 meta 信息。
(2) 一旦controller所在broker宕机了,此时临时节点消失,集群里其他broker会一直监听这个临时节点,发现临时节点消失了,就争抢再次创建临时节点,保证有一台新的broker会成为controller角色。
broker依然依赖于ZK,zookeeper 在kafka中还用来选举controller和检测broker是否存活等等。
zk维护offset一致:
10.Consumer group:
同一个group的consumer可以并行消费同一个topic的消息,但是同group的consumer,不会重复消费。
如果同一个topic需要被多次消费,可以通过设立多个consumer group来实现。每个group分别消费,互不影响。
-
high-level consumer API 中,每个 consumer 都属于一个 consumer group。
- 每条消息和partition只能被 consumer group 中一个 Consumer 消费,但可被多个 consumer group 消费
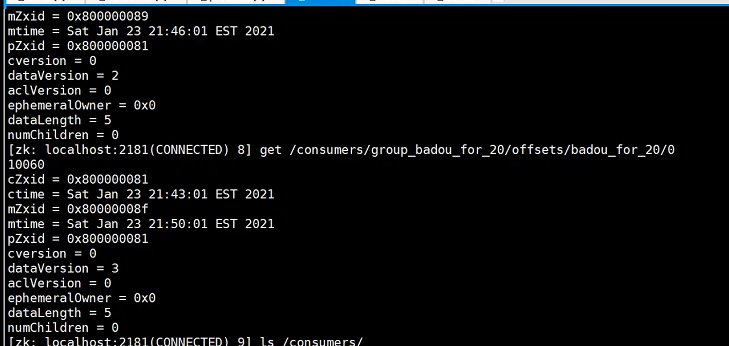
查看命令:
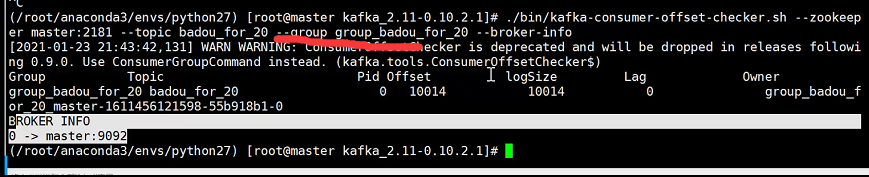
11.Message消息--kafka数据单位:(Flume -event、hdfs-block、Kafka--message )
kafka的最基本的数据单元——message,最大的消费message不能超过1M,可通过配置控制
• 每个producer可以向一个topic(主题)发布一些消息。如果consumer订阅这个主题,新发布消息会广播给这consumer。
• message format:– message length : 4 bytes -1 空 – "magic" value : 1 byte (kafka服务协议版本号,做兼容)
– crc32 : 4 bytes – timestamp 8 bytes – payload : n bytes
kafka持久化:
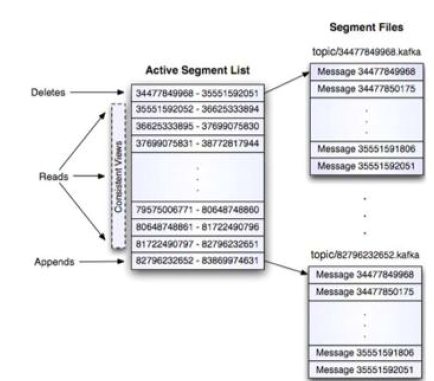
• Kafka存储布局简单:Topic的每个Partition对应一个逻辑日志(一个日志为相同大小的一组分段文件)
• 每次生产者发布消息到一个分区,代理就将消息追加到最后一个段文件segment中。当发布的消息数量达到设定值或者经过一定的 时间后,一段文件真正flush磁盘中。 写入完成后,消息公开给消费者。
• 与传统的消息系统不同,Kafka系统中存储的消息没有明确的消息Id。
• 消息通过日志中的逻辑偏移量来公开。
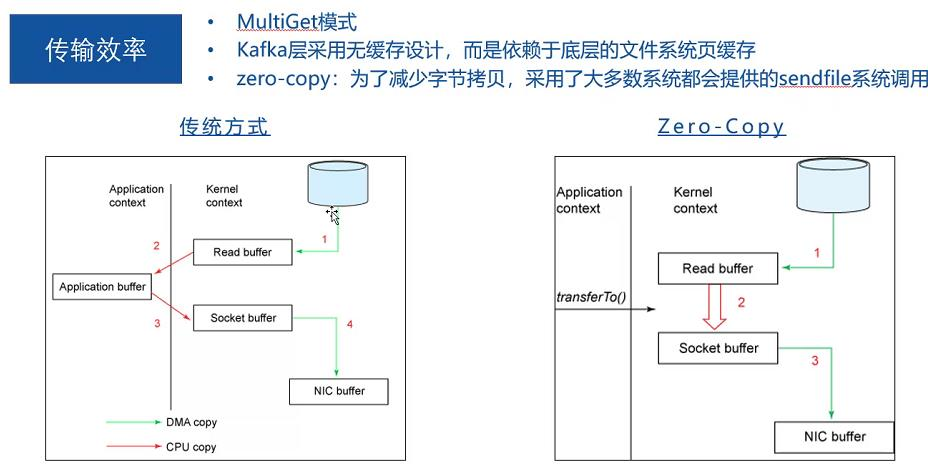
12.传输效率高:zero-copy,内核调用,直接将磁盘上的数据拷贝到socket,而不用通过应用程序传输。
zero-copy:kafka为了减少字节拷贝,采用了大多数系统都会提供的sendfile系统调用
Kafka的消息是无状态,降低Kafka实现难度,消费者必须自己维护已消费的状态信息,代理完全不管
这种设计非常微妙,它本身包含了创新
– 从代理删除消息变得很棘手,因为代理并不知道消费者是否已经使用了该消息。Kafka创新性地解决了这个问题,它将一个简单的基于时间的SLA应用于保留策略。当消息在代理中超过一定时间后,将会被自动删除。
– 好处:消费者可以故意倒回到老的偏移量再次消费数据。这违反了队列常见约定,但被证明是许多消费者的基本特征。
13.可靠性交付保证
• Kafka默认采用at least once的消息投递策略。即在消费者端的处理顺序是获得消息->处理消息->保存位置。这可能导致一旦客户端挂掉,新的客户端接管时处理前面客户端已处理过的消息。
• 三种保证策略:
– At most once 消息可能会丢,但绝不会重复传输 (很少用)
– At least one 消息绝不会丢,但可能会重复传输 (常用)
– Exactly once 每条消息肯定会被传输一次且仅传输一次
副本管理
• kafka将日志复制到指定多个服务器上。
• 复本的单元是partition。在正常情况下,每个分区有一个leader和0到多个follower。
• leader处理对应分区上所有的读写请求。分区可以多于broker数,leader也是分布式的。
• follower的日志和leader日志相同的, follower被动复制leader。如果leader挂,其中一个follower会自动变成新的leader.
14、ISR集合(同步副本)in-sync replica:leader partition保持同步的follower partition的数量
Kafka集群内部topic有多个partition,为了达到高可用目的,采用日志副本策略:
---当出现某些机器挂了情况,如果leader挂了,必须在ISR集合里面的follower,才有机会成为leader。因为在这个ISR列表里代表他的数据跟leader是同步的。
ISR集合,只要在该集合中的follower才有机会成为leader。
如何让leader知道follower是否成功接收数据(心跳、ack)
15、如何判断活着:
(1)心跳
(2)如何slave能够紧随leader的更新不至于落的太远,就认为有效,否则认为slave挂掉,需要从ISR中剔除掉slave

