
热门标签
热门文章
- 1python:多元线性回归总结_python 多元线性回归
- 2Docker 修改运行中的容器端口映射_docker 启动时忘记映射端口
- 3【SpringBoot框架篇】16.security整合jwt实现对前后端分离的项目进行权限认证_前后端分离权限验证
- 4Tendermint共识算法安全_共识算法安全威胁
- 5挣值管理名词(EV、AC、PV、ETC、SPI、CPI等)及公式(系统集成项目管理工程师挣值管理)
- 6安卓项目:app注册/登录界面设计_安卓注册登录
- 7画出降维后的图片_方法简介 降维法是将一个三维图变成几个二维图.即应选两个合适的平面去观察.当遇到一个空间受力问题时.将物体受到的力分解到两个不同平面上再求解.由于三维问题不好想像.选取适当的角度....
- 8Kafka与RocketMQ区别_kafka和rocketmq的区别
- 9XGBoost的优势与不足:全面解析这个让无数数据科学家疯狂的算法_xgboost 模型优势
- 10谷歌开发者账号关联问题,如何避免Google Play账号关联问题_google account terminated
当前位置: article > 正文
学习笔记Flink(一)—— Flink简介(介绍、基本概念、应用场景)_flink介绍和基本概念
作者:2023面试高手 | 2024-05-07 11:00:06
赞
踩
flink介绍和基本概念
一、Flink介绍
Apache Flink 是一个分布式流批一体化的开源平台。Flink 的核心是一个提供数据分发、通信以及自动容错的流计算引擎。Flink 在流计算之上构建批处理,并且原生的支持迭代计算,内存管理以及程序优化。
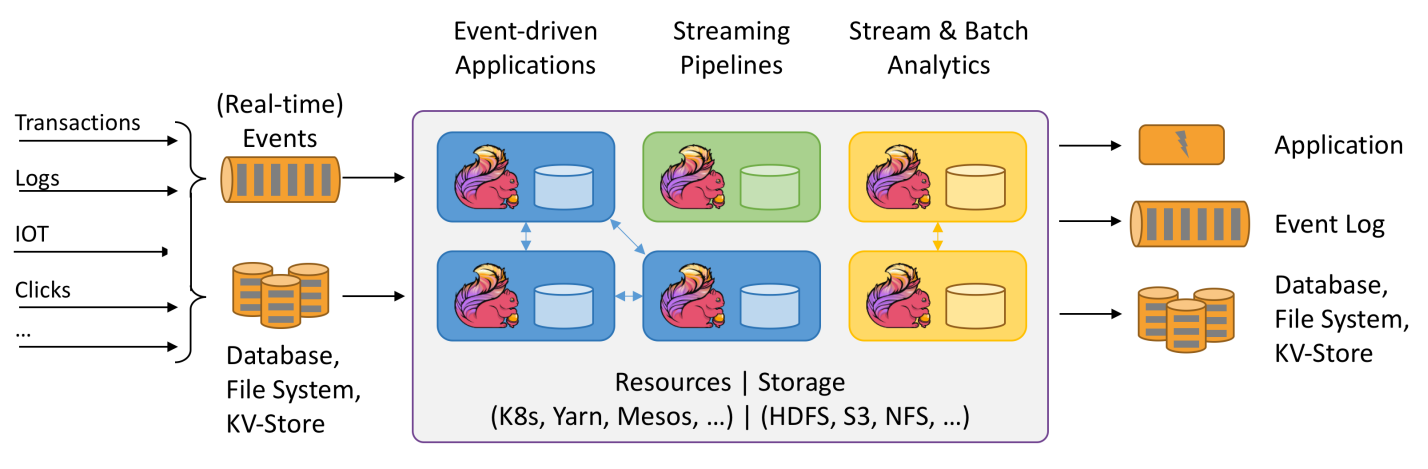
对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个特例而已。也就是说,Flink 会把所有任务当成流来处理,这也是其最大的特点。
Flink 可以支持本地的快速迭代,以及一些环形的迭代任务。
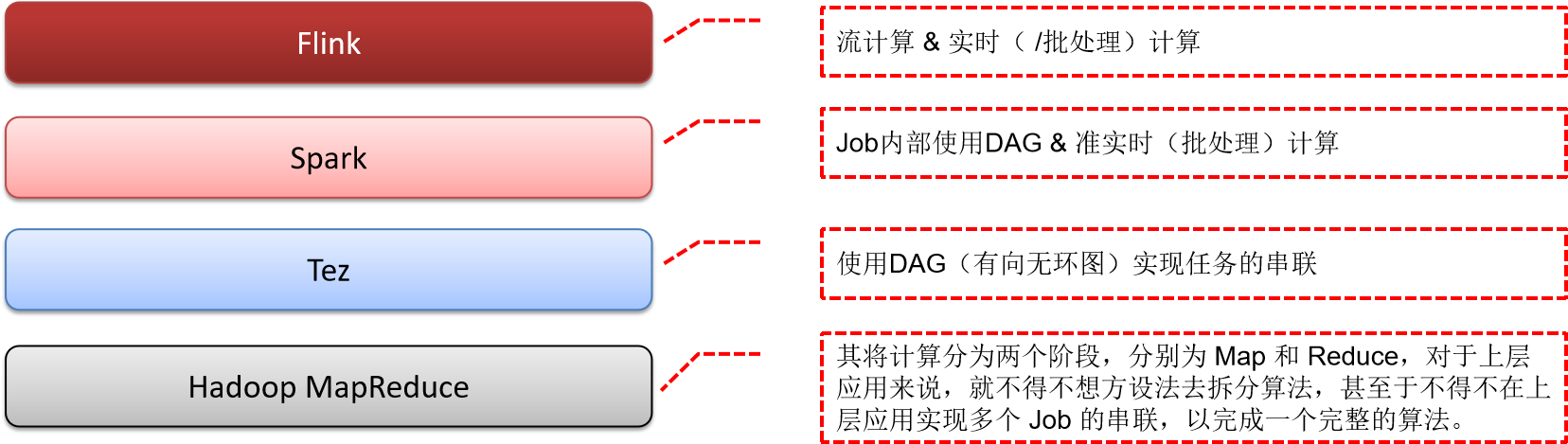
Apache Flink VS Hadoop/Tez/Spark
每个框架都有各自的差异,以及更适合的场景,没有哪一个框架可以完美的支持所有的场景,也就不可能有任何一个框架能完全取代另一个,就像 Spark 没有完全取代 Hadoop。所以我们需要理解不同的其差异,从而更好的使用技术框架来解决实际问题。
二、Flink基本概念
- Flink Cluster
一般情况下,Flink 集群是由一个 Flink Master 和一个或多个 Flink TaskManager 进程组成的分布式系统。 - Flink Master
Flink Master 是 Flink Cluster 的主节点。它包含三个不同的组件:Flink Resource Manager、Flink Dispatcher、运行每个 Flink Job 的 Flink JobManager。 - Flink JobManager
JobManager 是在 Flink Master 运行中的组件之一。JobManager 负责监督单个作业 Task 的执行。以前,整个 Flink Master 都叫做 JobManager。 - Flink TaskManager
TaskManager 是 Flink Cluster 的工作进程。Task 被调度到 TaskManager 上执行。TaskManager 相互通信,只为在后续的 Task 之间交换数据。 - Event
Event 是对应用程序建模的域的状态更改的声明。它可以同时为流或批处理应用程序的 input 和 output,也可以单独是 input 或者 output 中的一种。Event 是特殊类型的 Record。 - Record
Record 是数据集或数据流的组成元素。Operator 和 Function接收 record 作为输入,并将 record 作为输出发出。 - Partition
分区是整个数据流或数据集的独立子集。通过将每个 Record 分配给一个或多个分区,来把数据流或数据集划分为多个分区。在运行期间,Task 会消费数据流或数据集的分区。改变数据流或数据集分区方式的转换通常称为重分区。 - Function
Function 是由用户实现的,并封装了 Flink 程序的应用程序逻辑。大多数 Function 都由相应的 Operator 封装。 - Operator
Logical Graph 的节点。算子执行某种操作,该操作通常由 Function 执行。Source 和 Sink 是数据输入和数据输出的特殊算子。 - Logical Graph
Logical Graph 是一种描述流处理程序的高阶逻辑有向图。节点是Operator,边代表输入/输出关系、数据流和数据集中的之一。 - Instance
Instance 常用于描述运行时的特定类型(通常是 Operator 或者 Function)的一个具体实例。由于 Apache Flink 主要是用 Java 编写的,所以,这与 Java 中的 Instance 或 Object 的定义相对应。在 Apache Flink 的上下文中,parallel instance 也常用于强调同一 Operator 或者 Function 的多个 instance 以并行的方式运行。 - Operator Chain
算子链由两个或多个连续的 Operator 组成,两者之间没有任何的重新分区。同一算子链内的算子可以彼此直接传递 record,而无需通过序列化或 Flink 的网络栈。 - Task
Task 是 Physical Graph 的节点。它是基本的工作单元,由 Flink 的 runtime 来执行。Task 正好封装了一个 Operator 或者 Operator Chain 的 parallel instance。 - Physical Graph
Physical graph 是一个在分布式运行时,把 Logical Graph 转换为可执行的结果。节点是 Task,边表示数据流或数据集的输入/输出关系或 partition。 - Sub Task
Sub-Task 是负责处理数据流 Partition 的 Task。”Sub-Task”强调的是同一个 Operator 或者 Operator Chain 具有多个并行的 Task 。 - Transformation
Transformation 应用于一个或多个数据流或数据集,并产生一个或多个输出数据流或数据集。Transformation 可能会在每个记录的基础上更改数据流或数据集,但也可以只更改其分区或执行聚合。虽然 Operator 和 Function 是 Flink API 的“物理”部分,但 Transformation 只是一个 API 概念。具体来说,大多数(但不是全部)Transformation 是由某些 Operator 实现的。
三、Flink应用场景
1、事件驱动
- 欺诈检测(Fraud detection)
- 异常检测(Anomaly detection)
- 基于规则的告警(Rule-based alerting)
- 业务流程监控(Business process monitoring)
- Web应用程序(社交网络)

2、数据分析应用
6. 双十一销售大屏
7. 在线实时预测
8. 在线实时推荐

3、数据ETL应用
- 数据实时入库
- 数据周期性入库

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/2023面试高手/article/detail/548842
推荐阅读
相关标签

