
- 1【华为OD机试】手机App防沉迷系统(贪心算法—Java&Python&C++&JS实现)_手机app防沉迷系统华为od
- 2如何保证分布式文件系统的数据一致性
- 3RabbitMQ 笔记_x-delayed-message
- 432单片机 C语言 寄存器(四)_使用c语言判断单片机寄存器数据位
- 5Linux下的CentOS7连接不上外网,yum失败_yum install rpm 无法联网失败
- 6测试用例设计方法_等价类划分法(游戏向)_请简述一下等价类划分法设计测试用例的方法。
- 7当AI遇见现实:数智化时代的人类社会新图景
- 8MySQL安装配置教程-win10_mysql5.6安装
- 9揭秘游戏行业遭遇大规模DDoS攻击后的影响和真相丨阿里云河南_游戏公司被黑客攻击的影响
- 10【人工智能基础】GAN与WGAN实验
方法论系列:数据科学框架入门_数据科学的大框架
赞
踩
目录
- 第一章 - 数据科学家如何战胜困难
- 第二章 - 数据科学框架
- 第三章 - 步骤1:定义问题和步骤2:收集数据
- 第四章 - 步骤3:准备数据
- 第五章 - 数据清洗的4个C:纠正、补全、创建和转换
- 第六章 - 步骤4:使用统计学进行探索性分析
- 第七章 - 步骤5:建立模型
- 第八章 - 评估模型性能
- 第九章 - 使用超参数调整模型
- 第十章 - 使用特征选择调整模型
- 第十一章 - 步骤6:验证和实施
- 第十二章 - 结论和步骤7:优化和战略
数据科学家如何战胜机遇
这是一个经典问题,预测二元事件的结果。通俗地说,这意味着它要么发生了,要么没有发生。例如,你赢了或者没有赢,你通过了考试或者没有通过考试,你被接受或者没有被接受,你懂的。一个常见的商业应用是流失或客户保留。另一个流行的用例是医疗保健的死亡率或生存分析。二元事件创造了一个有趣的动态,因为我们知道,统计上,一个随机猜测应该达到50%的准确率,而不需要创建一个算法或编写一行代码。然而,就像自动纠正拼写技术一样,有时我们人类可以太聪明了,实际上表现不如硬币翻转。在这个内核中,我使用Kaggle的入门竞赛,泰坦尼克号:从灾难中学习机器学习,向读者介绍如何使用数据科学框架来战胜机遇。
当技术太聪明而超出我们的控制时会发生什么?
一个数据科学框架
- 定义问题: 如果数据科学、大数据、机器学习、预测分析、商业智能或其他流行词是解决方案,那么问题是什么?俗话说,不要把马车放在马前面。问题在需求之前,需求在解决方案之前,解决方案在设计之前,设计在技术之前。我们经常在确定要解决的实际问题之前,就急于采用新的闪亮技术、工具或算法。
- 收集数据: 约翰·奈斯比特在他1984年的书《大趋势》中写道,我们“淹没在数据中,却渴望知识。”所以,很有可能数据集已经存在于某个地方,以某种格式存在。它可以是外部的或内部的,结构化的或非结构化的,静态的或流式的,客观的或主观的等等。俗话说,你不必重新发明轮子,你只需要知道在哪里找到它。在下一步中,我们将关注如何将“脏数据”转化为“干净数据”。
- 准备数据以供使用: 这一步通常被称为数据整理,是将“野生”数据转化为“可管理”数据的必要过程。数据整理包括为存储和处理实施数据架构,制定数据治理标准以确保质量和控制,进行数据提取(即ETL和网络抓取),以及进行数据清洗以识别异常、缺失或异常值数据点。
- 进行探索性分析: 任何与数据打过交道的人都知道,垃圾进,垃圾出(GIGO)。因此,部署描述性和图形统计来寻找数据集中的潜在问题、模式、分类、相关性和比较非常重要。此外,数据分类(即定性与定量)对于理解和选择正确的假设检验或数据模型也很重要。
- 建模数据: 像描述性和推断统计一样,数据建模可以总结数据或预测未来结果。您的数据集和预期结果将确定可用的算法。重要的是要记住,算法只是工具,而不是魔术棒或灵丹妙药。您仍然必须是了解如何选择正确工具的技术专家。一个类比是让某人递给你一个十字螺丝刀,然后他们递给你一个平头螺丝刀,或者更糟糕的是一个锤子。最好的情况下,这显示出完全不理解。最坏的情况下,这将使项目无法完成。在数据建模中也是如此。错误的模型最多会导致性能不佳,最坏的情况下会得出错误的结论(作为可操作的情报)。
- 验证和实施数据模型: 在基于数据子集训练模型之后,是时候测试模型了。这有助于确保您没有过度拟合模型,或者使其对所选子集过于特定,以至于不能准确地适应同一数据集的另一个子集。在这一步中,我们确定我们的模型是否过度拟合、泛化或拟合不足我们的数据集。
- 优化和制定策略: 这是“仿生人”步骤,您可以通过迭代整个过程来使其变得更好、更强大、更快。作为数据科学家,您的策略应该是外包开发运营和应用程序管道,以便有更多时间专注于建议和设计。一旦您能够打包您的想法,这就成为您的“货币兑换”比率。
第一步:定义问题
对于这个项目,问题陈述已经给出,我们需要开发一个算法来预测泰坦尼克号上乘客的生存结果。
…
项目概述:
泰坦尼克号的沉没是历史上最臭名昭著的船难之一。1912年4月15日,在她的首航中,泰坦尼克号与冰山相撞后沉没,导致2224名乘客和船员中的1502人死亡。这场轰动的悲剧震惊了国际社会,并促使出台更好的船舶安全规定。
造成如此多人员伤亡的原因之一是乘客和船员的救生艇不够。尽管在沉船中幸存涉及一定的运气成分,但某些人群比其他人更有可能幸存,比如妇女、儿童和上层阶级。
在这个挑战中,我们要求您完成对可能幸存的人群的分析。具体而言,我们要求您应用机器学习的工具来预测哪些乘客在这场悲剧中幸存下来。
实践技能
- 二元分类
- Python和R基础知识
第二步:收集数据
数据集也已经以测试和训练数据的形式给出,可以在Kaggle的泰坦尼克号:来自灾难的机器学习上找到。
步骤3:准备数据以供使用
由于步骤2已经为我们提供了黄金般的服务,所以步骤3也是如此。因此,数据整理中的常规流程,如数据架构、治理和提取,都不在范围内。因此,只有数据清理在范围内。
3.1 导入库
以下代码是用Python 3.x编写的。库提供了预先编写的功能,以执行必要的任务。这个想法是为什么要写十行代码,当你可以写一行呢。
# 加载所需的包 import sys # 访问系统参数的包 print("Python版本:{}". format(sys.version)) import pandas as pd # 数据处理和分析的包,类似于R的数据框架和SQL的功能 print("pandas版本:{}". format(pd.__version__)) import matplotlib # 科学和出版可视化的包 print("matplotlib版本:{}". format(matplotlib.__version__)) import numpy as np # 科学计算的基础包 print("NumPy版本:{}". format(np.__version__)) import scipy as sp # 科学计算和高级数学的包 print("SciPy版本:{}". format(sp.__version__)) import IPython from IPython import display # 在Jupyter notebook中漂亮地打印数据框 print("IPython版本:{}". format(IPython.__version__)) import sklearn # 机器学习算法的集合 print("scikit-learn版本:{}". format(sklearn.__version__)) # 其他库 import random import time # 忽略警告 import warnings warnings.filterwarnings('ignore') print('-'*25) # 输入数据文件在"../input/"目录中可用。 # 例如,运行以下代码(点击运行或按Shift+Enter)将列出输入目录中的文件 from subprocess import check_output print(check_output(["ls", "../input"]).decode("utf8")) # 将任何结果写入当前目录作为输出。

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
Python version: 3.6.3 |Anaconda custom (64-bit)| (default, Nov 20 2017, 20:41:42)
[GCC 7.2.0]
pandas version: 0.20.3
matplotlib version: 2.1.1
NumPy version: 1.13.0
SciPy version: 1.0.0
IPython version: 5.3.0
scikit-learn version: 0.19.1
-------------------------
gender_submission.csv
test.csv
train.csv
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3.11 加载数据建模库
我们将使用流行的scikit-learn库来开发我们的机器学习算法。在sklearn中,算法被称为估计器,并在它们自己的类中实现。为了进行数据可视化,我们将使用matplotlib和seaborn库。以下是常见的加载类。
# 导入所需的库和模块 # 导入常用的模型算法 from sklearn import svm, tree, linear_model, neighbors, naive_bayes, ensemble, discriminant_analysis, gaussian_process from xgboost import XGBClassifier # 导入常用的模型辅助工具 from sklearn.preprocessing import OneHotEncoder, LabelEncoder from sklearn import feature_selection from sklearn import model_selection from sklearn import metrics # 导入可视化相关的库和模块 import matplotlib as mpl import matplotlib.pyplot as plt import matplotlib.pylab as pylab import seaborn as sns from pandas.tools.plotting import scatter_matrix # 配置可视化默认设置 # %matplotlib inline 表示在Jupyter Notebook中显示图形 %matplotlib inline mpl.style.use('ggplot') # 设置图形样式为ggplot风格 sns.set_style('white') # 设置seaborn图形样式为白色背景 pylab.rcParams['figure.figsize'] = 12, 8 # 设置图形大小为12x8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
3.2 相识和问候数据
这是相识和问候的步骤。首先通过名字来了解你的数据,并对其进行一些了解。它是什么样子的(数据类型和值),它是如何运作的(自变量/特征变量),它的目标是什么(因变量/目标变量)。可以把它看作是第一次约会,在你跳进并开始在卧室里戳它之前。
在开始这一步之前,我们首先导入我们的数据。接下来,我们使用info()和sample()函数,以获取变量数据类型(即定性 vs 定量)的快速和粗略的概述。点击这里查看源数据字典。
- Survived变量是我们的结果或因变量。它是一个二元名义数据类型,1表示幸存,0表示未幸存。所有其他变量都是潜在的预测变量或自变量。需要注意的是,更多的预测变量并不意味着更好的模型,而是选择正确的变量。
- PassengerID和Ticket变量被认为是随机唯一标识符,对结果变量没有影响。因此,它们将被排除在分析之外。
- Pclass变量是一个有序数据类型,表示船票等级,是社会经济地位(SES)的代理变量,1表示上层阶级,2表示中层阶级,3表示下层阶级。
- Name变量是一个名义数据类型。可以在特征工程中使用它来从称号中推导出性别,从姓氏中推导出家庭大小,从像医生或硕士这样的称号中推导出SES。由于这些变量已经存在,我们将利用它来看看像硕士这样的称号是否有所不同。
- Sex和Embarked变量是名义数据类型。它们将被转换为虚拟变量进行数学计算。
- Age和Fare变量是连续定量数据类型。
- SibSp表示同行的兄弟姐妹/配偶的数量,Parch表示同行的父母/子女的数量。两者都是离散定量数据类型。这可以用于特征工程,创建一个家庭大小和独自一人的变量。
- Cabin变量是一个名义数据类型,可以在特征工程中用于近似确定事故发生时船上的位置和甲板层次的SES。然而,由于存在许多空值,它并没有增加价值,因此被排除在分析之外。
# 导入数据
data_raw = pd.read_csv('../input/train.csv') # 从文件中导入数据
# 导入验证数据
data_val = pd.read_csv('../input/test.csv') # 从文件中导入验证数据
# 创建数据副本
data1 = data_raw.copy(deep=True) # 使用深拷贝创建数据副本
# 将数据副本放入数据清洗器中
data_cleaner = [data1, data_val] # 将数据副本放入数据清洗器列表中
# 预览数据
print(data_raw.info()) # 打印数据的基本信息
data_raw.sample(10) # 随机抽样并打印10条数据样本
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): PassengerId 891 non-null int64 Survived 891 non-null int64 Pclass 891 non-null int64 Name 891 non-null object Sex 891 non-null object Age 714 non-null float64 SibSp 891 non-null int64 Parch 891 non-null int64 Ticket 891 non-null object Fare 891 non-null float64 Cabin 204 non-null object Embarked 889 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 83.6+ KB None
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 855 | 856 | 1 | 3 | Aks, Mrs. Sam (Leah Rosen) | female | 18.0 | 0 | 1 | 392091 | 9.3500 | NaN | S |
| 701 | 702 | 1 | 1 | Silverthorne, Mr. Spencer Victor | male | 35.0 | 0 | 0 | PC 17475 | 26.2875 | E24 | S |
| 180 | 181 | 0 | 3 | Sage, Miss. Constance Gladys | female | NaN | 8 | 2 | CA. 2343 | 69.5500 | NaN | S |
| 409 | 410 | 0 | 3 | Lefebre, Miss. Ida | female | NaN | 3 | 1 | 4133 | 25.4667 | NaN | S |
| 776 | 777 | 0 | 3 | Tobin, Mr. Roger | male | NaN | 0 | 0 | 383121 | 7.7500 | F38 | Q |
| 404 | 405 | 0 | 3 | Oreskovic, Miss. Marija | female | 20.0 | 0 | 0 | 315096 | 8.6625 | NaN | S |
| 49 | 50 | 0 | 3 | Arnold-Franchi, Mrs. Josef (Josefine Franchi) | female | 18.0 | 1 | 0 | 349237 | 17.8000 | NaN | S |
| 836 | 837 | 0 | 3 | Pasic, Mr. Jakob | male | 21.0 | 0 | 0 | 315097 | 8.6625 | NaN | S |
| 619 | 620 | 0 | 2 | Gavey, Mr. Lawrence | male | 26.0 | 0 | 0 | 31028 | 10.5000 | NaN | S |
| 890 | 891 | 0 | 3 | Dooley, Mr. Patrick | male | 32.0 | 0 | 0 | 370376 | 7.7500 | NaN | Q |
3.21 数据清洗的四个C:修正、补全、创建和转换
在这个阶段,我们将通过以下四个步骤来清洗我们的数据:1)修正异常值和离群值,2)补全缺失信息,3)创建新的特征进行分析,4)将字段转换为正确的格式进行计算和展示。
- 修正: 在审查数据时,我们发现没有异常或不可接受的数据输入。此外,我们发现年龄和票价可能存在离群值。然而,由于它们是合理的值,我们将在完成探索性分析后决定是否应该包含或排除在数据集中。值得注意的是,如果它们是不合理的值,例如年龄为800而不是80,那么现在修正可能是一个安全的决定。然而,当我们修改数据的原始值时,我们需要谨慎,因为这可能需要创建一个准确的模型。
- 补全: 年龄、船舱和登船港口字段中存在空值或缺失数据。缺失值可能是不好的,因为一些算法不知道如何处理空值,会导致失败。而其他算法,如决策树,可以处理空值。因此,在开始建模之前修复这些问题非常重要,因为我们将比较和对比几个模型。有两种常见的方法,要么删除记录,要么使用合理的输入填充缺失值。不推荐删除记录,尤其是大比例的记录,除非它真正代表了一个不完整的记录。相反,最好是填充缺失值。对于定性数据,基本的方法是使用众数进行填充。对于定量数据,基本的方法是使用均值、中位数或均值+随机标准差进行填充。中级方法是根据特定的标准使用基本方法,比如按照等级或登船港口按票价和SES的平均年龄。还有更复杂的方法,但在部署之前,应该与基准模型进行比较,以确定复杂性是否真正增加了价值。对于这个数据集,年龄将使用中位数进行填充,船舱属性将被删除,登船港口将使用众数进行填充。后续的模型迭代可能会修改这个决策,以确定是否提高了模型的准确性。
- 创建: 特征工程是指我们利用现有特征创建新特征,以确定它们是否提供了预测结果的新信号。对于这个数据集,我们将创建一个标题特征,以确定它是否在生存中起到了作用。
- 转换: 最后,但同样重要的是,我们将处理格式。没有日期或货币格式,只有数据类型格式。我们的分类数据被导入为对象,这使得进行数学计算变得困难。对于这个数据集,我们将把对象数据类型转换为分类虚拟变量。
# 打印训练数据中含有空值的列
print('Train columns with null values:\n', data1.isnull().sum())
# 打印分隔线
print("-"*10)
# 打印测试/验证数据中含有空值的列
print('Test/Validation columns with null values:\n', data_val.isnull().sum())
# 打印分隔线
print("-"*10)
# 对原始数据进行描述性统计,包括所有列的统计信息
data_raw.describe(include='all')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Train columns with null values: PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 177 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 687 Embarked 2 dtype: int64 ---------- Test/Validation columns with null values: PassengerId 0 Pclass 0 Name 0 Sex 0 Age 86 SibSp 0 Parch 0 Ticket 0 Fare 1 Cabin 327 Embarked 0 dtype: int64 ----------
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 891 | 891 | 714.000000 | 891.000000 | 891.000000 | 891 | 891.000000 | 204 | 889 |
| unique | NaN | NaN | NaN | 891 | 2 | NaN | NaN | NaN | 681 | NaN | 147 | 3 |
| top | NaN | NaN | NaN | Lindahl, Miss. Agda Thorilda Viktoria | male | NaN | NaN | NaN | 1601 | NaN | C23 C25 C27 | S |
| freq | NaN | NaN | NaN | 1 | 577 | NaN | NaN | NaN | 7 | NaN | 4 | 644 |
| mean | 446.000000 | 0.383838 | 2.308642 | NaN | NaN | 29.699118 | 0.523008 | 0.381594 | NaN | 32.204208 | NaN | NaN |
| std | 257.353842 | 0.486592 | 0.836071 | NaN | NaN | 14.526497 | 1.102743 | 0.806057 | NaN | 49.693429 | NaN | NaN |
| min | 1.000000 | 0.000000 | 1.000000 | NaN | NaN | 0.420000 | 0.000000 | 0.000000 | NaN | 0.000000 | NaN | NaN |
| 25% | 223.500000 | 0.000000 | 2.000000 | NaN | NaN | 20.125000 | 0.000000 | 0.000000 | NaN | 7.910400 | NaN | NaN |
| 50% | 446.000000 | 0.000000 | 3.000000 | NaN | NaN | 28.000000 | 0.000000 | 0.000000 | NaN | 14.454200 | NaN | NaN |
| 75% | 668.500000 | 1.000000 | 3.000000 | NaN | NaN | 38.000000 | 1.000000 | 0.000000 | NaN | 31.000000 | NaN | NaN |
| max | 891.000000 | 1.000000 | 3.000000 | NaN | NaN | 80.000000 | 8.000000 | 6.000000 | NaN | 512.329200 | NaN | NaN |
3.22 清洗数据
现在我们知道要清洗什么了,让我们执行我们的代码。
开发者文档:
- pandas.DataFrame
- pandas.DataFrame.info
- pandas.DataFrame.describe
- 索引和选择数据
- pandas.isnull
- pandas.DataFrame.sum
- pandas.DataFrame.mode
- pandas.DataFrame.copy
- pandas.DataFrame.fillna
- pandas.DataFrame.drop
- pandas.Series.value_counts
- pandas.DataFrame.loc
###COMPLETING: complete or delete missing values in train and test/validation dataset # 对训练集和测试/验证集中的缺失值进行填充或删除 for dataset in data_cleaner: # 使用中位数填充缺失的年龄值 dataset['Age'].fillna(dataset['Age'].median(), inplace = True) # 使用众数填充缺失的登船港口值 dataset['Embarked'].fillna(dataset['Embarked'].mode()[0], inplace = True) # 使用中位数填充缺失的票价值 dataset['Fare'].fillna(dataset['Fare'].median(), inplace = True) # 在训练集中删除客舱、乘客ID和票号这些特征/列 drop_column = ['PassengerId','Cabin', 'Ticket'] data1.drop(drop_column, axis=1, inplace = True) # 打印训练集中的缺失值总数 print(data1.isnull().sum()) print("-"*10) # 打印测试/验证集中的缺失值总数 print(data_val.isnull().sum())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
Survived 0 Pclass 0 Name 0 Sex 0 Age 0 SibSp 0 Parch 0 Fare 0 Embarked 0 dtype: int64 ---------- PassengerId 0 Pclass 0 Name 0 Sex 0 Age 0 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 327 Embarked 0 dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
###创建:为训练集和测试/验证集进行特征工程 for dataset in data_cleaner: #离散变量 dataset['FamilySize'] = dataset ['SibSp'] + dataset['Parch'] + 1 #计算家庭成员数量 dataset['IsAlone'] = 1 #初始化为独自一人(是) dataset['IsAlone'].loc[dataset['FamilySize'] > 1] = 0 #如果家庭成员数量大于1,则更新为不是独自一人(否) #快速而简单的代码,从姓名中分离出称号:http://www.pythonforbeginners.com/dictionary/python-split dataset['Title'] = dataset['Name'].str.split(", ", expand=True)[1].str.split(".", expand=True)[0] #从姓名中提取称号 #连续变量分箱;qcut与cut的区别:https://stackoverflow.com/questions/30211923/what-is-the-difference-between-pandas-qcut-and-pandas-cut #使用qcut对票价进行分箱:https://pandas.pydata.org/pandas-docs/stable/generated/pandas.qcut.html dataset['FareBin'] = pd.qcut(dataset['Fare'], 4) #对票价进行分箱 #使用cut对年龄进行分箱:https://pandas.pydata.org/pandas-docs/stable/generated/pandas.cut.html dataset['AgeBin'] = pd.cut(dataset['Age'].astype(int), 5) #对年龄进行分箱 #清理罕见的称号 #print(data1['Title'].value_counts()) stat_min = 10 #虽然小是任意的,但我们将使用统计学中常见的最小值:http://nicholasjjackson.com/2012/03/08/sample-size-is-10-a-magic-number/ title_names = (data1['Title'].value_counts() < stat_min) #这将创建一个以称号为索引的真假序列 #apply和lambda函数是一种快速而简单的代码,可以用较少的行数找到并替换:https://community.modeanalytics.com/python/tutorial/pandas-groupby-and-python-lambda-functions/ data1['Title'] = data1['Title'].apply(lambda x: 'Misc' if title_names.loc[x] == True else x) #如果称号在title_names中为True,则替换为"Misc" print(data1['Title'].value_counts()) print("-"*10) #再次预览数据 data1.info() data_val.info() data1.sample(10)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
Mr 517 Miss 182 Mrs 125 Master 40 Misc 27 Name: Title, dtype: int64 ---------- <class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 14 columns): Survived 891 non-null int64 Pclass 891 non-null int64 Name 891 non-null object Sex 891 non-null object Age 891 non-null float64 SibSp 891 non-null int64 Parch 891 non-null int64 Fare 891 non-null float64 Embarked 891 non-null object FamilySize 891 non-null int64 IsAlone 891 non-null int64 Title 891 non-null object FareBin 891 non-null category AgeBin 891 non-null category dtypes: category(2), float64(2), int64(6), object(4) memory usage: 85.5+ KB <class 'pandas.core.frame.DataFrame'> RangeIndex: 418 entries, 0 to 417 Data columns (total 16 columns): PassengerId 418 non-null int64 Pclass 418 non-null int64 Name 418 non-null object Sex 418 non-null object Age 418 non-null float64 SibSp 418 non-null int64 Parch 418 non-null int64 Ticket 418 non-null object Fare 418 non-null float64 Cabin 91 non-null object Embarked 418 non-null object FamilySize 418 non-null int64 IsAlone 418 non-null int64 Title 418 non-null object FareBin 418 non-null category AgeBin 418 non-null category dtypes: category(2), float64(2), int64(6), object(6) memory usage: 46.8+ KB
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
| Survived | Pclass | Name | Sex | Age | SibSp | Parch | Fare | Embarked | FamilySize | IsAlone | Title | FareBin | AgeBin | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 651 | 1 | 2 | Doling, Miss. Elsie | female | 18.0 | 0 | 1 | 23.0000 | S | 2 | 0 | Miss | (14.454, 31.0] | (16.0, 32.0] |
| 561 | 0 | 3 | Sivic, Mr. Husein | male | 40.0 | 0 | 0 | 7.8958 | S | 1 | 1 | Mr | (-0.001, 7.91] | (32.0, 48.0] |
| 737 | 1 | 1 | Lesurer, Mr. Gustave J | male | 35.0 | 0 | 0 | 512.3292 | C | 1 | 1 | Mr | (31.0, 512.329] | (32.0, 48.0] |
| 368 | 1 | 3 | Jermyn, Miss. Annie | female | 28.0 | 0 | 0 | 7.7500 | Q | 1 | 1 | Miss | (-0.001, 7.91] | (16.0, 32.0] |
| 837 | 0 | 3 | Sirota, Mr. Maurice | male | 28.0 | 0 | 0 | 8.0500 | S | 1 | 1 | Mr | (7.91, 14.454] | (16.0, 32.0] |
| 299 | 1 | 1 | Baxter, Mrs. James (Helene DeLaudeniere Chaput) | female | 50.0 | 0 | 1 | 247.5208 | C | 2 | 0 | Mrs | (31.0, 512.329] | (48.0, 64.0] |
| 273 | 0 | 1 | Natsch, Mr. Charles H | male | 37.0 | 0 | 1 | 29.7000 | C | 2 | 0 | Mr | (14.454, 31.0] | (32.0, 48.0] |
| 117 | 0 | 2 | Turpin, Mr. William John Robert | male | 29.0 | 1 | 0 | 21.0000 | S | 2 | 0 | Mr | (14.454, 31.0] | (16.0, 32.0] |
| 810 | 0 | 3 | Alexander, Mr. William | male | 26.0 | 0 | 0 | 7.8875 | S | 1 | 1 | Mr | (-0.001, 7.91] | (16.0, 32.0] |
| 234 | 0 | 2 | Leyson, Mr. Robert William Norman | male | 24.0 | 0 | 0 | 10.5000 | S | 1 | 1 | Mr | (7.91, 14.454] | (16.0, 32.0] |
3.23 转换格式
我们将把分类数据转换为虚拟变量以进行数学分析。有多种编码分类变量的方法;我们将使用sklearn和pandas函数。
在这一步中,我们还将为数据建模定义我们的x(自变量/特征/解释变量/预测变量等)和y(因变量/目标变量/结果变量等)变量。
开发者文档:
#CONVERT: 使用Label Encoder将对象转换为类别,用于训练集和测试/验证集的数据 #对分类数据进行编码 label = LabelEncoder() for dataset in data_cleaner: dataset['Sex_Code'] = label.fit_transform(dataset['Sex']) #将'Sex'列中的性别数据转换为数字编码 dataset['Embarked_Code'] = label.fit_transform(dataset['Embarked']) #将'Embarked'列中的登船港口数据转换为数字编码 dataset['Title_Code'] = label.fit_transform(dataset['Title']) #将'Title'列中的称号数据转换为数字编码 dataset['AgeBin_Code'] = label.fit_transform(dataset['AgeBin']) #将'AgeBin'列中的年龄段数据转换为数字编码 dataset['FareBin_Code'] = label.fit_transform(dataset['FareBin']) #将'FareBin'列中的票价段数据转换为数字编码 #define y变量,即目标/结果 Target = ['Survived'] #define x变量,即原始特征,用于特征选择 data1_x = ['Sex','Pclass', 'Embarked', 'Title','SibSp', 'Parch', 'Age', 'Fare', 'FamilySize', 'IsAlone'] #用于图表的漂亮名称/值 data1_x_calc = ['Sex_Code','Pclass', 'Embarked_Code', 'Title_Code','SibSp', 'Parch', 'Age', 'Fare'] #用于算法计算的编码 data1_xy = Target + data1_x print('Original X Y: ', data1_xy, '\n') #define x变量,即带有分箱特征的原始特征,以删除连续变量 data1_x_bin = ['Sex_Code','Pclass', 'Embarked_Code', 'Title_Code', 'FamilySize', 'AgeBin_Code', 'FareBin_Code'] data1_xy_bin = Target + data1_x_bin print('Bin X Y: ', data1_xy_bin, '\n') #define x和y变量,即原始虚拟特征 data1_dummy = pd.get_dummies(data1[data1_x]) #对data1中的data1_x进行独热编码 data1_x_dummy = data1_dummy.columns.tolist() #获取独热编码后的列名列表 data1_xy_dummy = Target + data1_x_dummy print('Dummy X Y: ', data1_xy_dummy, '\n') data1_dummy.head() #显示独热编码后的数据的前几行
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
Original X Y: ['Survived', 'Sex', 'Pclass', 'Embarked', 'Title', 'SibSp', 'Parch', 'Age', 'Fare', 'FamilySize', 'IsAlone']
Bin X Y: ['Survived', 'Sex_Code', 'Pclass', 'Embarked_Code', 'Title_Code', 'FamilySize', 'AgeBin_Code', 'FareBin_Code']
Dummy X Y: ['Survived', 'Pclass', 'SibSp', 'Parch', 'Age', 'Fare', 'FamilySize', 'IsAlone', 'Sex_female', 'Sex_male', 'Embarked_C', 'Embarked_Q', 'Embarked_S', 'Title_Master', 'Title_Misc', 'Title_Miss', 'Title_Mr', 'Title_Mrs']
- 1
- 2
- 3
- 4
- 5
| Pclass | SibSp | Parch | Age | Fare | FamilySize | IsAlone | Sex_female | Sex_male | Embarked_C | Embarked_Q | Embarked_S | Title_Master | Title_Misc | Title_Miss | Title_Mr | Title_Mrs | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 1 | 0 | 22.0 | 7.2500 | 2 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 0 | 38.0 | 71.2833 | 2 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 2 | 3 | 0 | 0 | 26.0 | 7.9250 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| 3 | 1 | 1 | 0 | 35.0 | 53.1000 | 2 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 4 | 3 | 0 | 0 | 35.0 | 8.0500 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
3.24 Da-Double Check 清洁数据
既然我们已经清洁了我们的数据,让我们进行一次折扣的双重检查!
# 打印训练数据中含有空值的列 print('Train columns with null values: \n', data1.isnull().sum()) # 打印分隔线 print("-"*10) # 打印训练数据的信息 print (data1.info()) # 打印分隔线 print("-"*10) # 打印测试/验证数据中含有空值的列 print('Test/Validation columns with null values: \n', data_val.isnull().sum()) # 打印分隔线 print("-"*10) # 打印测试/验证数据的信息 print (data_val.info()) # 打印分隔线 print("-"*10) # 打印数据的统计描述信息,包括所有列 data_raw.describe(include = 'all')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
Train columns with null values: Survived 0 Pclass 0 Name 0 Sex 0 Age 0 SibSp 0 Parch 0 Fare 0 Embarked 0 FamilySize 0 IsAlone 0 Title 0 FareBin 0 AgeBin 0 Sex_Code 0 Embarked_Code 0 Title_Code 0 AgeBin_Code 0 FareBin_Code 0 dtype: int64 ---------- <class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 19 columns): Survived 891 non-null int64 Pclass 891 non-null int64 Name 891 non-null object Sex 891 non-null object Age 891 non-null float64 SibSp 891 non-null int64 Parch 891 non-null int64 Fare 891 non-null float64 Embarked 891 non-null object FamilySize 891 non-null int64 IsAlone 891 non-null int64 Title 891 non-null object FareBin 891 non-null category AgeBin 891 non-null category Sex_Code 891 non-null int64 Embarked_Code 891 non-null int64 Title_Code 891 non-null int64 AgeBin_Code 891 non-null int64 FareBin_Code 891 non-null int64 dtypes: category(2), float64(2), int64(11), object(4) memory usage: 120.3+ KB None ---------- Test/Validation columns with null values: PassengerId 0 Pclass 0 Name 0 Sex 0 Age 0 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 327 Embarked 0 FamilySize 0 IsAlone 0 Title 0 FareBin 0 AgeBin 0 Sex_Code 0 Embarked_Code 0 Title_Code 0 AgeBin_Code 0 FareBin_Code 0 dtype: int64 ---------- <class 'pandas.core.frame.DataFrame'> RangeIndex: 418 entries, 0 to 417 Data columns (total 21 columns): PassengerId 418 non-null int64 Pclass 418 non-null int64 Name 418 non-null object Sex 418 non-null object Age 418 non-null float64 SibSp 418 non-null int64 Parch 418 non-null int64 Ticket 418 non-null object Fare 418 non-null float64 Cabin 91 non-null object Embarked 418 non-null object FamilySize 418 non-null int64 IsAlone 418 non-null int64 Title 418 non-null object FareBin 418 non-null category AgeBin 418 non-null category Sex_Code 418 non-null int64 Embarked_Code 418 non-null int64 Title_Code 418 non-null int64 AgeBin_Code 418 non-null int64 FareBin_Code 418 non-null int64 dtypes: category(2), float64(2), int64(11), object(6) memory usage: 63.1+ KB None ----------
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 891 | 891 | 714.000000 | 891.000000 | 891.000000 | 891 | 891.000000 | 204 | 889 |
| unique | NaN | NaN | NaN | 891 | 2 | NaN | NaN | NaN | 681 | NaN | 147 | 3 |
| top | NaN | NaN | NaN | Lindahl, Miss. Agda Thorilda Viktoria | male | NaN | NaN | NaN | 1601 | NaN | C23 C25 C27 | S |
| freq | NaN | NaN | NaN | 1 | 577 | NaN | NaN | NaN | 7 | NaN | 4 | 644 |
| mean | 446.000000 | 0.383838 | 2.308642 | NaN | NaN | 29.699118 | 0.523008 | 0.381594 | NaN | 32.204208 | NaN | NaN |
| std | 257.353842 | 0.486592 | 0.836071 | NaN | NaN | 14.526497 | 1.102743 | 0.806057 | NaN | 49.693429 | NaN | NaN |
| min | 1.000000 | 0.000000 | 1.000000 | NaN | NaN | 0.420000 | 0.000000 | 0.000000 | NaN | 0.000000 | NaN | NaN |
| 25% | 223.500000 | 0.000000 | 2.000000 | NaN | NaN | 20.125000 | 0.000000 | 0.000000 | NaN | 7.910400 | NaN | NaN |
| 50% | 446.000000 | 0.000000 | 3.000000 | NaN | NaN | 28.000000 | 0.000000 | 0.000000 | NaN | 14.454200 | NaN | NaN |
| 75% | 668.500000 | 1.000000 | 3.000000 | NaN | NaN | 38.000000 | 1.000000 | 0.000000 | NaN | 31.000000 | NaN | NaN |
| max | 891.000000 | 1.000000 | 3.000000 | NaN | NaN | 80.000000 | 8.000000 | 6.000000 | NaN | 512.329200 | NaN | NaN |
3.25 分割训练和测试数据
如前所述,提供的测试文件实际上是竞赛提交的验证数据。因此,我们将使用sklearn函数将训练数据分为两个数据集;75/25的比例。这很重要,这样我们就不会过度拟合我们的模型。也就是说,算法对于给定的子集非常特定,不能准确地推广到同一数据集的另一个子集。重要的是,我们的算法没有看到我们将用于测试的子集,这样它就不会通过记忆答案来“作弊”。我们将使用sklearn的 train_test_split函数。在后面的章节中,我们还将使用sklearn的交叉验证函数,将我们的数据集分为训练和测试集,以进行数据建模比较。
# 导入模块 # model_selection是一个模块,用于拆分训练集和测试集 # train_test_split是model_selection模块中的一个函数,用于拆分数据集 # data1是一个数据集,包含特征和目标变量 # data1_x_calc是data1中的特征变量 # Target是data1中的目标变量 # 使用train_test_split函数将data1中的特征变量data1_x_calc和目标变量Target拆分为训练集和测试集 # random_state参数用于控制随机数生成器的种子,保证每次拆分的结果一致 # 拆分后的训练集特征变量赋值给train1_x,测试集特征变量赋值给test1_x # 拆分后的训练集目标变量赋值给train1_y,测试集目标变量赋值给test1_y train1_x, test1_x, train1_y, test1_y = model_selection.train_test_split(data1[data1_x_calc], data1[Target], random_state=0) # 使用train_test_split函数将data1中的特征变量data1_x_bin和目标变量Target拆分为训练集和测试集 # random_state参数用于控制随机数生成器的种子,保证每次拆分的结果一致 # 拆分后的训练集特征变量赋值给train1_x_bin,测试集特征变量赋值给test1_x_bin # 拆分后的训练集目标变量赋值给train1_y_bin,测试集目标变量赋值给test1_y_bin train1_x_bin, test1_x_bin, train1_y_bin, test1_y_bin = model_selection.train_test_split(data1[data1_x_bin], data1[Target], random_state=0) # 使用train_test_split函数将data1_dummy中的特征变量data1_x_dummy和目标变量Target拆分为训练集和测试集 # random_state参数用于控制随机数生成器的种子,保证每次拆分的结果一致 # 拆分后的训练集特征变量赋值给train1_x_dummy,测试集特征变量赋值给test1_x_dummy # 拆分后的训练集目标变量赋值给train1_y_dummy,测试集目标变量赋值给test1_y_dummy train1_x_dummy, test1_x_dummy, train1_y_dummy, test1_y_dummy = model_selection.train_test_split(data1_dummy[data1_x_dummy], data1[Target], random_state=0) # 打印data1的形状,即数据集的行数和列数 print("Data1 Shape: {}".format(data1.shape)) # 打印train1_x的形状,即训练集特征变量的行数和列数 print("Train1 Shape: {}".format(train1_x.shape)) # 打印test1_x的形状,即测试集特征变量的行数和列数 print("Test1 Shape: {}".format(test1_x.shape)) # 打印train1_x_bin的前几行数据 train1_x_bin.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
Data1 Shape: (891, 19)
Train1 Shape: (668, 8)
Test1 Shape: (223, 8)
- 1
- 2
- 3
| Sex_Code | Pclass | Embarked_Code | Title_Code | FamilySize | AgeBin_Code | FareBin_Code | |
|---|---|---|---|---|---|---|---|
| 105 | 1 | 3 | 2 | 3 | 1 | 1 | 0 |
| 68 | 0 | 3 | 2 | 2 | 7 | 1 | 1 |
| 253 | 1 | 3 | 2 | 3 | 2 | 1 | 2 |
| 320 | 1 | 3 | 2 | 3 | 1 | 1 | 0 |
| 706 | 0 | 2 | 2 | 4 | 1 | 2 | 1 |
第四步:使用统计方法进行探索性分析
现在我们的数据已经清洗完毕,我们将使用描述性和图形统计方法来描述和总结我们的变量。在这个阶段,您将发现自己正在对特征进行分类,并确定它们与目标变量以及彼此之间的相关性。
# 离散变量与生存率的相关性 # 使用groupby函数进行分组,类似于透视表操作 for x in data1_x: # 如果变量的数据类型不是float64 if data1[x].dtype != 'float64' : # 打印输出相关性信息 print('Survival Correlation by:', x) # 使用groupby函数按照变量x进行分组,并计算生存率的平均值 print(data1[[x, Target[0]]].groupby(x, as_index=False).mean()) # 打印分隔线 print('-'*10, '\n') # 使用crosstab函数进行交叉表操作 # 交叉表用于统计两个或多个变量之间的频数分布关系 print(pd.crosstab(data1['Title'],data1[Target[0]]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
Survival Correlation by: Sex Sex Survived 0 female 0.742038 1 male 0.188908 ---------- Survival Correlation by: Pclass Pclass Survived 0 1 0.629630 1 2 0.472826 2 3 0.242363 ---------- Survival Correlation by: Embarked Embarked Survived 0 C 0.553571 1 Q 0.389610 2 S 0.339009 ---------- Survival Correlation by: Title Title Survived 0 Master 0.575000 1 Misc 0.444444 2 Miss 0.697802 3 Mr 0.156673 4 Mrs 0.792000 ---------- Survival Correlation by: SibSp SibSp Survived 0 0 0.345395 1 1 0.535885 2 2 0.464286 3 3 0.250000 4 4 0.166667 5 5 0.000000 6 8 0.000000 ---------- Survival Correlation by: Parch Parch Survived 0 0 0.343658 1 1 0.550847 2 2 0.500000 3 3 0.600000 4 4 0.000000 5 5 0.200000 6 6 0.000000 ---------- Survival Correlation by: FamilySize FamilySize Survived 0 1 0.303538 1 2 0.552795 2 3 0.578431 3 4 0.724138 4 5 0.200000 5 6 0.136364 6 7 0.333333 7 8 0.000000 8 11 0.000000 ---------- Survival Correlation by: IsAlone IsAlone Survived 0 0 0.505650 1 1 0.303538 ---------- Survived 0 1 Title Master 17 23 Misc 15 12 Miss 55 127 Mr 436 81 Mrs 26 99
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
# 导入matplotlib.pyplot库,用于绘制图形 import matplotlib.pyplot as plt # 设置图形的大小为16x12 plt.figure(figsize=[16,12]) # 在第一个子图中绘制箱线图 plt.subplot(231) plt.boxplot(x=data1['Fare'], showmeans = True, meanline = True) plt.title('Fare Boxplot') # 设置子图标题 plt.ylabel('Fare ($)') # 设置y轴标签 # 在第二个子图中绘制箱线图 plt.subplot(232) plt.boxplot(data1['Age'], showmeans = True, meanline = True) plt.title('Age Boxplot') plt.ylabel('Age (Years)') # 在第三个子图中绘制箱线图 plt.subplot(233) plt.boxplot(data1['FamilySize'], showmeans = True, meanline = True) plt.title('Family Size Boxplot') plt.ylabel('Family Size (#)') # 在第四个子图中绘制直方图 plt.subplot(234) plt.hist(x = [data1[data1['Survived']==1]['Fare'], data1[data1['Survived']==0]['Fare']], stacked=True, color = ['g','r'],label = ['Survived','Dead']) plt.title('Fare Histogram by Survival') plt.xlabel('Fare ($)') plt.ylabel('# of Passengers') plt.legend() # 在第五个子图中绘制直方图 plt.subplot(235) plt.hist(x = [data1[data1['Survived']==1]['Age'], data1[data1['Survived']==0]['Age']], stacked=True, color = ['g','r'],label = ['Survived','Dead']) plt.title('Age Histogram by Survival') plt.xlabel('Age (Years)') plt.ylabel('# of Passengers') plt.legend() # 在第六个子图中绘制直方图 plt.subplot(236) plt.hist(x = [data1[data1['Survived']==1]['FamilySize'], data1[data1['Survived']==0]['FamilySize']], stacked=True, color = ['g','r'],label = ['Survived','Dead']) plt.title('Family Size Histogram by Survival') plt.xlabel('Family Size (#)') plt.ylabel('# of Passengers') plt.legend()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
<matplotlib.legend.Legend at 0x7f57f3087860>
- 1

# 使用seaborn图形进行多变量比较:https://seaborn.pydata.org/api.html # 创建一个2行3列的图形,大小为16x12 fig, saxis = plt.subplots(2, 3,figsize=(16,12)) # 绘制柱状图,横轴为'Embarked',纵轴为'Survived',数据来源为data1,绘制在saxis[0,0]位置 sns.barplot(x = 'Embarked', y = 'Survived', data=data1, ax = saxis[0,0]) # 绘制柱状图,横轴为'Pclass',纵轴为'Survived',指定顺序为[1,2,3],数据来源为data1,绘制在saxis[0,1]位置 sns.barplot(x = 'Pclass', y = 'Survived', order=[1,2,3], data=data1, ax = saxis[0,1]) # 绘制柱状图,横轴为'IsAlone',纵轴为'Survived',指定顺序为[1,0],数据来源为data1,绘制在saxis[0,2]位置 sns.barplot(x = 'IsAlone', y = 'Survived', order=[1,0], data=data1, ax = saxis[0,2]) # 绘制点图,横轴为'FareBin',纵轴为'Survived',数据来源为data1,绘制在saxis[1,0]位置 sns.pointplot(x = 'FareBin', y = 'Survived', data=data1, ax = saxis[1,0]) # 绘制点图,横轴为'AgeBin',纵轴为'Survived',数据来源为data1,绘制在saxis[1,1]位置 sns.pointplot(x = 'AgeBin', y = 'Survived', data=data1, ax = saxis[1,1]) # 绘制点图,横轴为'FamilySize',纵轴为'Survived',数据来源为data1,绘制在saxis[1,2]位置 sns.pointplot(x = 'FamilySize', y = 'Survived', data=data1, ax = saxis[1,2])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
<matplotlib.axes._subplots.AxesSubplot at 0x7f57f2f11080>
- 1
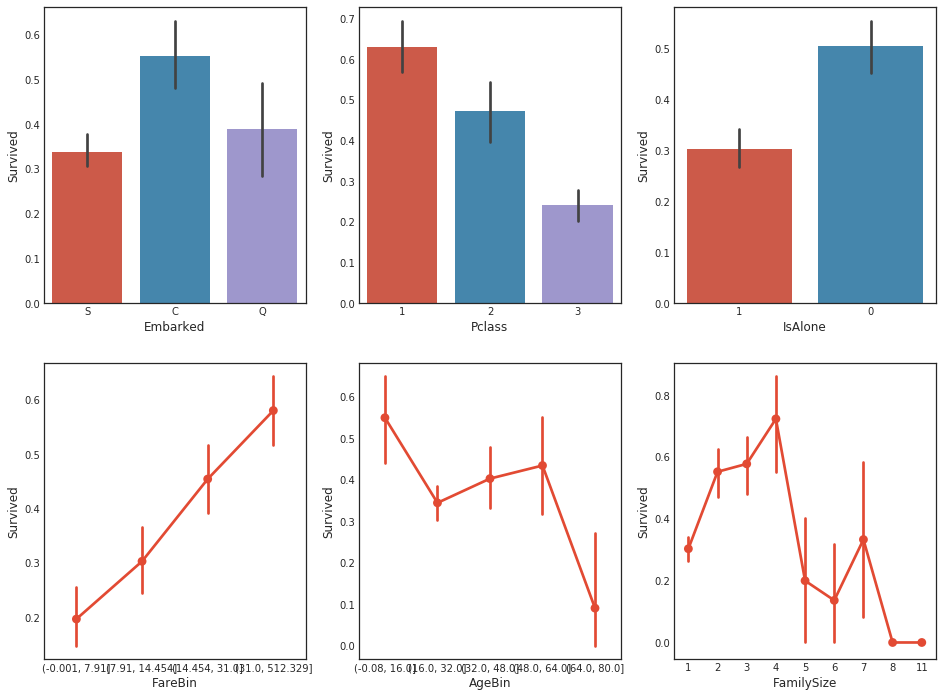
# 导入必要的库 import matplotlib.pyplot as plt import seaborn as sns # 创建一个包含3个子图的图表,大小为14x12 fig, (axis1, axis2, axis3) = plt.subplots(1, 3, figsize=(14, 12)) # 在第一个子图上绘制箱线图,比较Pclass(船舱等级)和Fare(票价)与Survived(是否生存)之间的关系 sns.boxplot(x='Pclass', y='Fare', hue='Survived', data=data1, ax=axis1) axis1.set_title('Pclass vs Fare Survival Comparison') # 设置第一个子图的标题 # 在第二个子图上绘制小提琴图,比较Pclass(船舱等级)和Age(年龄)与Survived(是否生存)之间的关系 sns.violinplot(x='Pclass', y='Age', hue='Survived', data=data1, split=True, ax=axis2) axis2.set_title('Pclass vs Age Survival Comparison') # 设置第二个子图的标题 # 在第三个子图上绘制箱线图,比较Pclass(船舱等级)和FamilySize(家庭大小)与Survived(是否生存)之间的关系 sns.boxplot(x='Pclass', y='FamilySize', hue='Survived', data=data1, ax=axis3) axis3.set_title('Pclass vs Family Size Survival Comparison') # 设置第三个子图的标题
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
Text(0.5,1,'Pclass vs Family Size Survival Comparison')
- 1
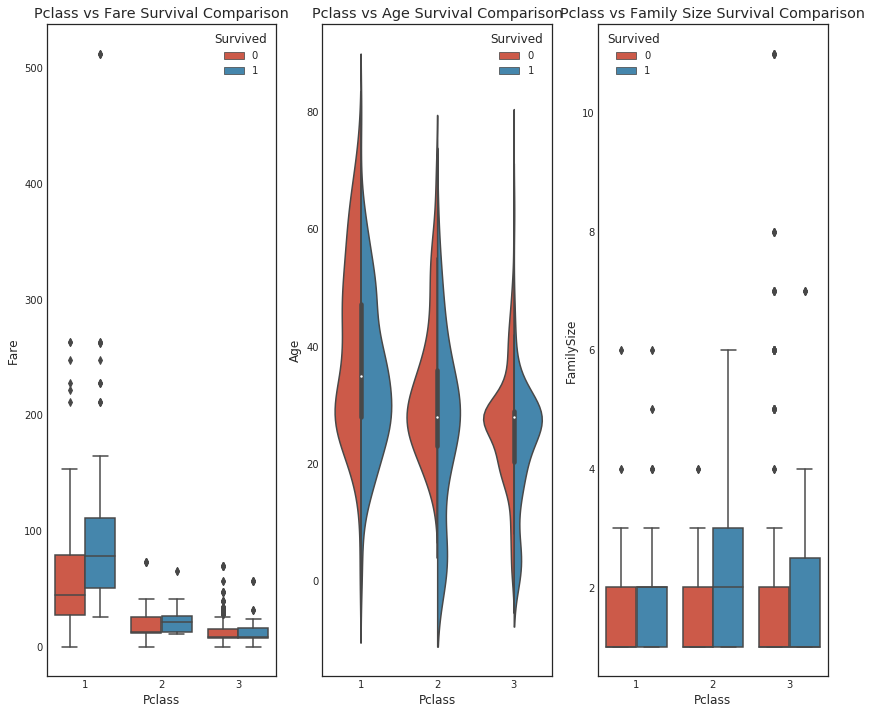
# 导入必要的库 import seaborn as sns import matplotlib.pyplot as plt # 创建一个包含3个子图的图形,大小为14x12 fig, qaxis = plt.subplots(1, 3, figsize=(14, 12)) # 在第一个子图上绘制柱状图,比较性别和登船港口对生存率的影响 sns.barplot(x='Sex', y='Survived', hue='Embarked', data=data1, ax=qaxis[0]) qaxis[0].set_title('Sex vs Embarked Survival Comparison') # 在第二个子图上绘制柱状图,比较性别和客舱等级对生存率的影响 sns.barplot(x='Sex', y='Survived', hue='Pclass', data=data1, ax=qaxis[1]) qaxis[1].set_title('Sex vs Pclass Survival Comparison') # 在第三个子图上绘制柱状图,比较性别和是否独自一人对生存率的影响 sns.barplot(x='Sex', y='Survived', hue='IsAlone', data=data1, ax=qaxis[2]) qaxis[2].set_title('Sex vs IsAlone Survival Comparison')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
Text(0.5,1,'Sex vs IsAlone Survival Comparison')
- 1
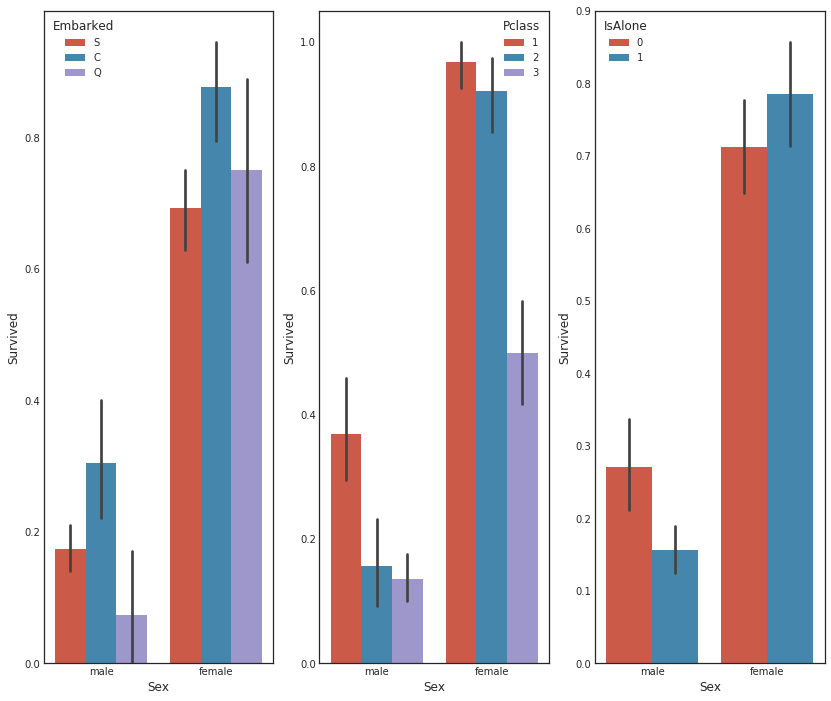
# 导入必要的库已经在代码之外完成了,这里不需要再次导入
# 创建一个1行2列的子图,大小为14x12
fig, (maxis1, maxis2) = plt.subplots(1, 2,figsize=(14,12))
# 绘制一个点图,比较家庭大小与性别、生存率的关系
sns.pointplot(x="FamilySize", y="Survived", hue="Sex", data=data1,
palette={"male": "blue", "female": "pink"}, # 设置男性为蓝色,女性为粉色
markers=["*", "o"], linestyles=["-", "--"], ax = maxis1) # 设置标记和线型,将图绘制在第一个子图上
# 绘制一个点图,比较船舱等级与性别、生存率的关系
sns.pointplot(x="Pclass", y="Survived", hue="Sex", data=data1,
palette={"male": "blue", "female": "pink"}, # 设置男性为蓝色,女性为粉色
markers=["*", "o"], linestyles=["-", "--"], ax = maxis2) # 设置标记和线型,将图绘制在第二个子图上
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
<matplotlib.axes._subplots.AxesSubplot at 0x7f57f2df7978>
- 1
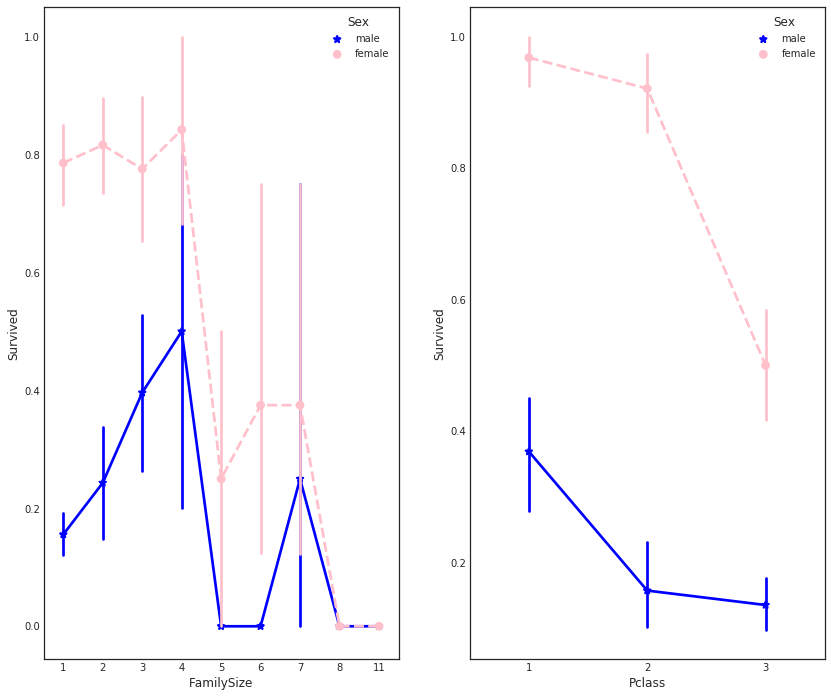
# 导入 seaborn 库
import seaborn as sns
# 创建一个 FacetGrid 对象,用于绘制多个子图
# data1 是数据集,col = 'Embarked' 表示按照 Embarked 列进行分组
e = sns.FacetGrid(data1, col='Embarked')
# 在每个子图中绘制一个 pointplot,表示不同 Pclass、Sex 对应的 Survived 的均值
# 'Pclass' 表示 x 轴,'Survived' 表示 y 轴,'Sex' 表示 hue(颜色),ci=95.0 表示置信区间为 95%
# palette = 'deep' 表示使用深色调色板
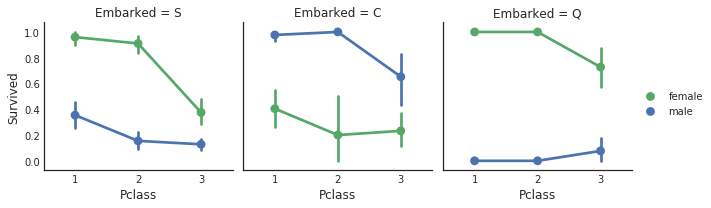
e.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', ci=95.0, palette='deep')
# 添加图例
e.add_legend()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
<seaborn.axisgrid.FacetGrid at 0x7f57f660f2b0>
- 1
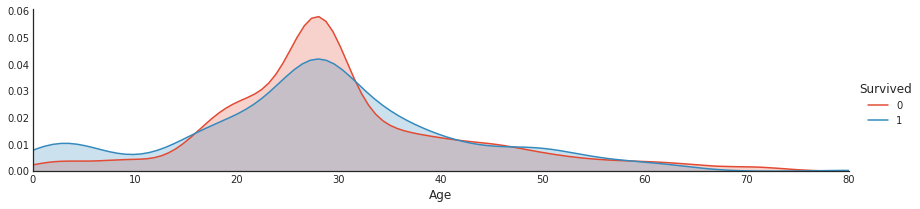
# 导入必要的库 import seaborn as sns # 创建一个FacetGrid对象,用于绘制图表 # data1是数据集,hue参数指定按照'Survived'列的值进行分类 # aspect参数指定图表的宽高比 a = sns.FacetGrid(data1, hue='Survived', aspect=4) # 使用kdeplot函数绘制核密度估计图,并设置阴影效果 # 'Age'参数指定绘制的数据列为'Age' a.map(sns.kdeplot, 'Age', shade=True) # 设置x轴的范围为0到数据集中'Age'列的最大值 a.set(xlim=(0, data1['Age'].max())) # 添加图例 a.add_legend()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
<seaborn.axisgrid.FacetGrid at 0x7f57f254b048>
- 1
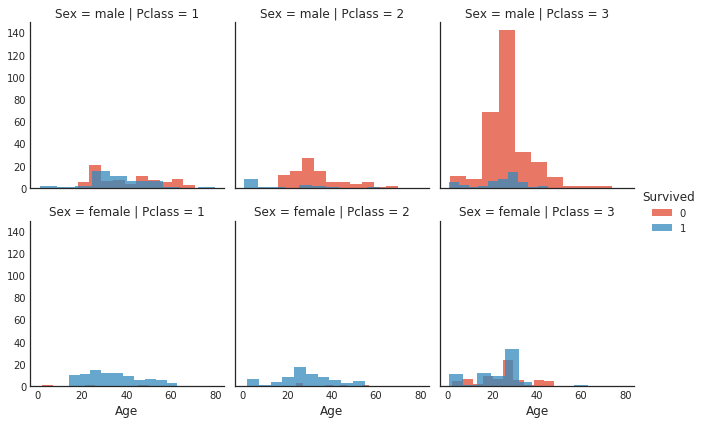
# 导入必要的库
import seaborn as sns
import matplotlib.pyplot as plt
# 创建一个FacetGrid对象,用于绘制多个子图
# data1是数据集,row参数指定按照'Sex'列进行分组,col参数指定按照'Pclass'列进行分组,hue参数指定按照'Survived'列进行着色
h = sns.FacetGrid(data1, row='Sex', col='Pclass', hue='Survived')
# 在每个子图上绘制直方图,x轴为'Age'列,alpha参数指定透明度为0.75
h.map(plt.hist, 'Age', alpha=0.75)
# 添加图例
h.add_legend()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
<seaborn.axisgrid.FacetGrid at 0x7f57f246bdd8>
- 1
# 导入必要的库
import seaborn as sns
# 绘制数据集的配对图
# data1为数据集
# hue参数指定了根据'Survived'列的值对数据进行着色
# palette参数指定了使用'deep'调色板进行着色
# size参数指定了图的大小为1.2
# diag_kind参数指定了对角线上的图形类型为'kde',即核密度估计图
# diag_kws参数指定了对角线上的图形的阴影为True
# plot_kws参数指定了散点图的大小为10
pp = sns.pairplot(data1, hue='Survived', palette='deep', size=1.2, diag_kind='kde', diag_kws=dict(shade=True), plot_kws=dict(s=10))
# 设置x轴标签为空,即不显示x轴标签
pp.set(xticklabels=[])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
<seaborn.axisgrid.PairGrid at 0x7f57f22bd2b0>
- 1

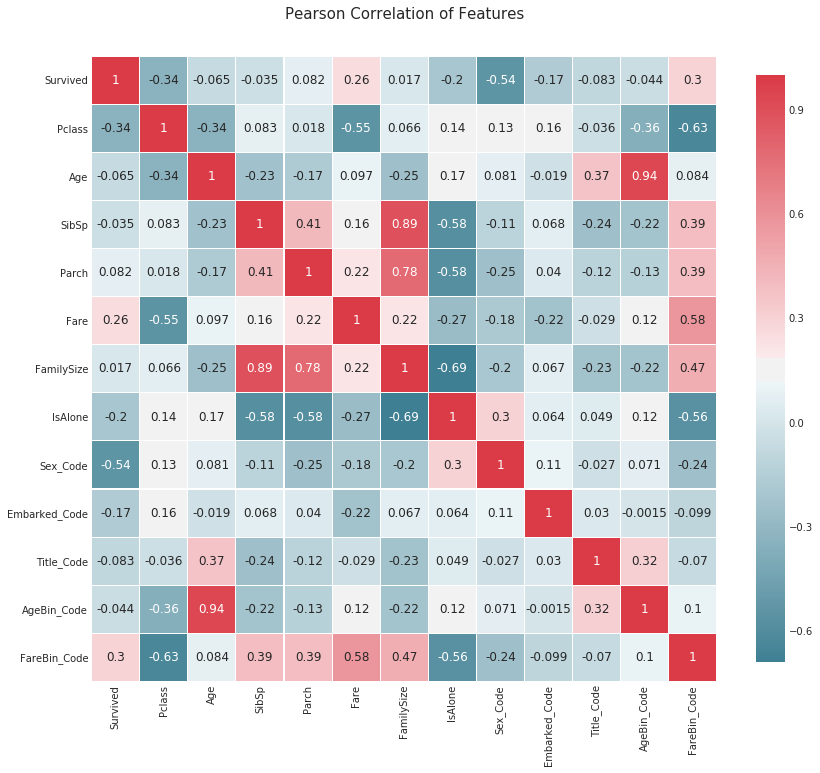
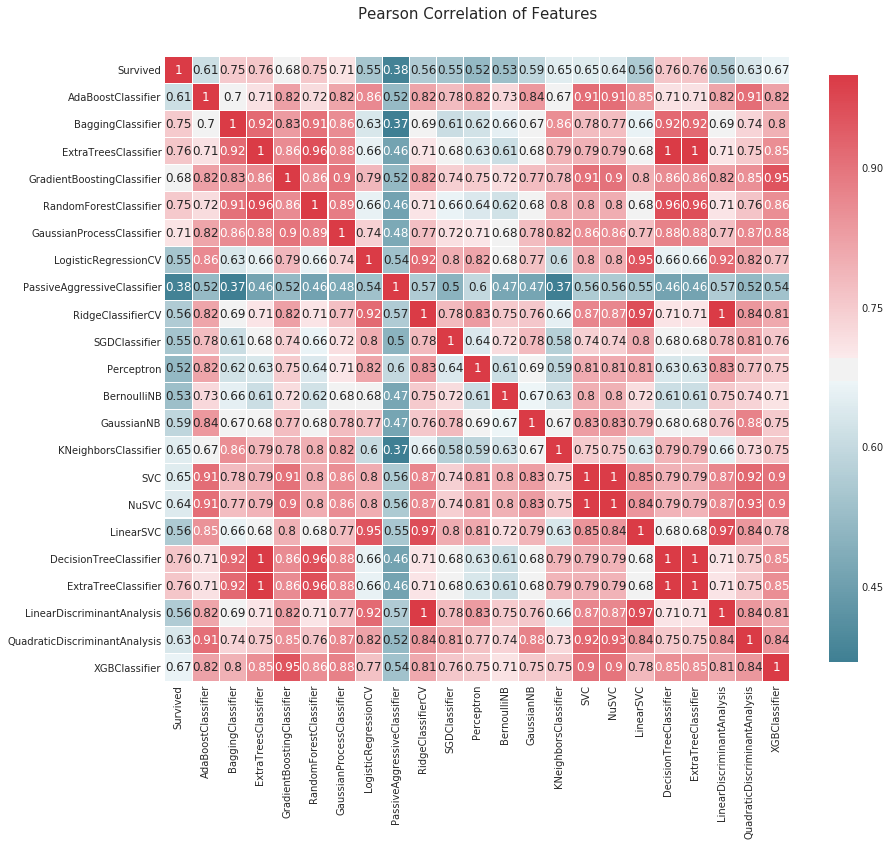
# 导入必要的库 import matplotlib.pyplot as plt import seaborn as sns # 定义一个函数,用于绘制数据集的相关性热力图 def correlation_heatmap(df): # 创建一个图形和一个子图 _ , ax = plt.subplots(figsize =(14, 12)) # 设置调色板,用于表示相关性的颜色 colormap = sns.diverging_palette(220, 10, as_cmap = True) # 绘制热力图 _ = sns.heatmap( df.corr(), # 计算数据集的相关系数矩阵 cmap = colormap, # 使用调色板设置颜色 square=True, # 设置热力图为正方形 cbar_kws={'shrink':.9 }, # 设置颜色条的大小 ax=ax, # 指定子图 annot=True, # 在热力图上显示数值 linewidths=0.1, # 设置热力图中每个单元格的边框宽度 vmax=1.0, # 设置颜色条的最大值 linecolor='white', # 设置热力图中每个单元格的边框颜色 annot_kws={'fontsize':12 } # 设置热力图上数值的字体大小 ) # 设置图标题 plt.title('Pearson Correlation of Features', y=1.05, size=15) # 调用函数绘制数据集data1的相关性热力图 correlation_heatmap(data1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
第五步:建模数据
数据科学是数学(如统计学、线性代数等)、计算机科学(如编程语言、计算机系统等)和商业管理(如沟通、专业知识等)之间的多学科领域。大多数数据科学家来自这三个领域之一,所以他们倾向于偏向于这个学科。然而,数据科学就像一个三条腿的凳子,没有一条腿比其他腿更重要。因此,这一步需要数学方面的高级知识。但是不用担心,我们只需要一个高层次的概述,我们将在本文档中介绍。此外,由于计算机科学的帮助,很多繁重的工作已经为您完成。因此,曾经需要数学或统计学研究生学位的问题,现在只需要几行代码就可以解决。最后,我们需要一些商业头脑来思考问题。毕竟,就像训练一只导盲犬一样,它是从我们这里学习,而不是相反。
机器学习(ML)顾名思义,是教机器如何思考,而不是告诉它们该如何思考。虽然这个主题和大数据已经存在了几十年,但由于进入门槛降低,它比以往任何时候都更受欢迎,无论是对企业还是专业人士来说。这既是好事也是坏事。好处是这些算法现在可以被更多的人使用,可以解决现实世界中更多的问题。坏处是进入门槛降低意味着更多的人不会了解他们正在使用的工具,并可能得出错误的结论。这就是为什么我专注于教给你们的不仅仅是要做什么,还要告诉你们为什么要这样做。之前,我用一个类比来解释,就像让别人递给你一个十字螺丝刀,他们递给你一个平头螺丝刀,或者更糟糕的是一个锤子。最好的情况下,这显示了完全的无知。最坏的情况下,这使得完成项目变得不可能;甚至更糟糕的是,实施了错误的可行性情报。所以现在我已经强调了我的观点,我将告诉你们该怎么做,最重要的是,为什么要这样做。
首先,你必须明白,机器学习的目的是解决人类的问题。机器学习可以分为:监督学习、无监督学习和强化学习。监督学习是通过向模型呈现包含正确答案的训练数据集来训练模型。无监督学习是通过使用不包含正确答案的训练数据集来训练模型。而强化学习是前两者的混合,模型不会立即得到正确答案,而是在一系列事件之后得到正确答案以加强学习。我们正在进行监督机器学习,因为我们通过呈现一组特征及其相应的目标来训练我们的算法。然后,我们希望向它呈现同一数据集的一个新的子集,并在预测准确性方面获得类似的结果。
有许多机器学习算法,但它们可以分为四类:分类、回归、聚类或降维,具体取决于目标变量和数据建模目标。我们将把聚类和降维留到另一天,重点关注分类和回归。我们可以概括地说,连续目标变量需要回归算法,而离散目标变量需要分类算法。值得一提的是,逻辑回归虽然在名称中有回归,但实际上是一种分类算法。由于我们的问题是预测乘客是否生存,这是一个离散目标变量。我们将使用sklearn库中的分类算法开始我们的分析。我们将使用交叉验证和评分指标,在后面的部分中讨论,来排名和比较我们算法的性能。
机器学习选择:
现在我们确定了我们的解决方案是一个监督学习分类算法。我们可以缩小选择范围。
机器学习分类算法:
数据科学101:如何选择机器学习算法(MLA)
**重要提示:**当涉及数据建模时,初学者常问的问题是,“什么是最好的机器学习算法?”对此,初学者必须了解机器学习的无免费午餐定理(NFLT)。简而言之,NFLT表明,没有一个超级算法在所有情况下、对于所有数据集都表现最佳。因此,最好的方法是尝试多个MLA,对它们进行调整,并比较它们在特定情况下的表现。尽管如此,已经进行了一些对算法的比较研究,比如Caruana & Niculescu-Mizil 2006的MLA比较,Ogutu et al. 2011的基因组选择研究,Fernandez-Delgado et al. 2014的17个家族的179个分类器比较,Thoma 2016 sklearn比较,还有一种观点认为,“更多的数据胜过更好的算法”(https://www.kdnuggets.com/2015/06/machine-learning-more-data-better-algorithms.html)。
那么对于所有这些信息,初学者应该从哪里开始呢?我建议从树、装袋、随机森林和提升开始。它们基本上是决策树的不同实现方式,决策树是最容易学习和理解的概念。与像SVC这样的算法相比,它们也更容易调整,下一节将讨论这一点。下面,我将概述如何运行和比较几个MLA,但本文档的其余部分将重点介绍通过决策树及其衍生算法学习数据建模。
# 机器学习算法(MLA)选择和初始化 # 导入所需的库 # 这里没有给出import语句,需要根据实际情况导入所需的库 # 定义MLA列表,包含各种机器学习算法 MLA = [ # 集成方法 ensemble.AdaBoostClassifier(), # AdaBoost分类器 ensemble.BaggingClassifier(), # Bagging分类器 ensemble.ExtraTreesClassifier(), # ExtraTrees分类器 ensemble.GradientBoostingClassifier(), # GradientBoosting分类器 ensemble.RandomForestClassifier(), # RandomForest分类器 # 高斯过程 gaussian_process.GaussianProcessClassifier(), # 高斯过程分类器 # 广义线性模型 linear_model.LogisticRegressionCV(), # 带交叉验证的逻辑回归分类器 linear_model.PassiveAggressiveClassifier(), # PassiveAggressive分类器 linear_model.RidgeClassifierCV(), # 带交叉验证的岭回归分类器 linear_model.SGDClassifier(), # 随机梯度下降分类器 linear_model.Perceptron(), # 感知机分类器 # 朴素贝叶斯 naive_bayes.BernoulliNB(), # 伯努利朴素贝叶斯分类器 naive_bayes.GaussianNB(), # 高斯朴素贝叶斯分类器 # 最近邻 neighbors.KNeighborsClassifier(), # K最近邻分类器 # 支持向量机 svm.SVC(probability=True), # 支持向量机分类器 svm.NuSVC(probability=True), # Nu支持向量机分类器 svm.LinearSVC(), # 线性支持向量机分类器 # 决策树 tree.DecisionTreeClassifier(), # 决策树分类器 tree.ExtraTreeClassifier(), # ExtraTree分类器 # 判别分析 discriminant_analysis.LinearDiscriminantAnalysis(), # 线性判别分析分类器 discriminant_analysis.QuadraticDiscriminantAnalysis(), # 二次判别分析分类器 # xgboost XGBClassifier() # XGBoost分类器 ] # 使用ShuffleSplit类进行交叉验证划分数据集 cv_split = model_selection.ShuffleSplit(n_splits=10, test_size=.3, train_size=.6, random_state=0) # 将数据集划分为10份,训练集占60%,测试集占30% # 创建用于比较MLA指标的表格 MLA_columns = ['MLA Name', 'MLA Parameters', 'MLA Train Accuracy Mean', 'MLA Test Accuracy Mean', 'MLA Test Accuracy 3*STD', 'MLA Time'] MLA_compare = pd.DataFrame(columns=MLA_columns) # 创建用于比较MLA预测结果的表格 MLA_predict = data1[Target] # 遍历MLA列表,计算并保存性能指标到表格中 row_index = 0 for alg in MLA: # 获取算法名称和参数 MLA_name = alg.__class__.__name__ MLA_compare.loc[row_index, 'MLA Name'] = MLA_name MLA_compare.loc[row_index, 'MLA Parameters'] = str(alg.get_params()) # 使用交叉验证评估模型性能 cv_results = model_selection.cross_validate(alg, data1[data1_x_bin], data1[Target], cv=cv_split) MLA_compare.loc[row_index, 'MLA Time'] = cv_results['fit_time'].mean() # 计算平均训练时间 MLA_compare.loc[row_index, 'MLA Train Accuracy Mean'] = cv_results['train_score'].mean() # 计算平均训练准确率 MLA_compare.loc[row_index, 'MLA Test Accuracy Mean'] = cv_results['test_score'].mean() # 计算平均测试准确率 MLA_compare.loc[row_index, 'MLA Test Accuracy 3*STD'] = cv_results['test_score'].std() * 3 # 计算测试准确率的3倍标准差,用于评估模型的稳定性 # 保存MLA预测结果 alg.fit(data1[data1_x_bin], data1[Target]) MLA_predict[MLA_name] = alg.predict(data1[data1_x_bin]) row_index += 1 # 打印并按测试准确率排序表格 MLA_compare.sort_values(by=['MLA Test Accuracy Mean'], ascending=False, inplace=True) MLA_compare
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
| MLA Name | MLA Parameters | MLA Train Accuracy Mean | MLA Test Accuracy Mean | MLA Test Accuracy 3*STD | MLA Time | |
|---|---|---|---|---|---|---|
| 21 | XGBClassifier | {'base_score': 0.5, 'booster': 'gbtree', 'cols... | 0.856367 | 0.829478 | 0.0527546 | 0.0338062 |
| 4 | RandomForestClassifier | {'bootstrap': True, 'class_weight': None, 'cri... | 0.892322 | 0.826493 | 0.0679525 | 0.0147755 |
| 14 | SVC | {'C': 1.0, 'cache_size': 200, 'class_weight': ... | 0.837266 | 0.826119 | 0.0453876 | 0.0445107 |
| 3 | GradientBoostingClassifier | {'criterion': 'friedman_mse', 'init': None, 'l... | 0.866667 | 0.822761 | 0.0498731 | 0.0715864 |
| 15 | NuSVC | {'cache_size': 200, 'class_weight': None, 'coe... | 0.835768 | 0.822761 | 0.0493681 | 0.0524707 |
| 2 | ExtraTreesClassifier | {'bootstrap': False, 'class_weight': None, 'cr... | 0.895131 | 0.821269 | 0.0690863 | 0.0144257 |
| 17 | DecisionTreeClassifier | {'class_weight': None, 'criterion': 'gini', 'm... | 0.895131 | 0.81903 | 0.0575704 | 0.00189724 |
| 1 | BaggingClassifier | {'base_estimator': None, 'bootstrap': True, 'b... | 0.890449 | 0.813806 | 0.0614041 | 0.0157245 |
| 13 | KNeighborsClassifier | {'algorithm': 'auto', 'leaf_size': 30, 'metric... | 0.850375 | 0.813806 | 0.0690863 | 0.00233798 |
| 18 | ExtraTreeClassifier | {'class_weight': None, 'criterion': 'gini', 'm... | 0.895131 | 0.812687 | 0.0634811 | 0.00160697 |
| 0 | AdaBoostClassifier | {'algorithm': 'SAMME.R', 'base_estimator': Non... | 0.820412 | 0.81194 | 0.0498606 | 0.072931 |
| 5 | GaussianProcessClassifier | {'copy_X_train': True, 'kernel': None, 'max_it... | 0.871723 | 0.810448 | 0.0492537 | 0.350273 |
| 20 | QuadraticDiscriminantAnalysis | {'priors': None, 'reg_param': 0.0, 'store_cova... | 0.821536 | 0.80709 | 0.0810389 | 0.0176577 |
| 8 | RidgeClassifierCV | {'alphas': (0.1, 1.0, 10.0), 'class_weight': N... | 0.796629 | 0.79403 | 0.0360302 | 0.0105472 |
| 19 | LinearDiscriminantAnalysis | {'n_components': None, 'priors': None, 'shrink... | 0.796816 | 0.79403 | 0.0360302 | 0.00550387 |
| 16 | LinearSVC | {'C': 1.0, 'class_weight': None, 'dual': True,... | 0.79794 | 0.793657 | 0.0400646 | 0.0274618 |
| 6 | LogisticRegressionCV | {'Cs': 10, 'class_weight': None, 'cv': None, '... | 0.797004 | 0.790672 | 0.0653582 | 0.129134 |
| 12 | GaussianNB | {'priors': None} | 0.794757 | 0.781343 | 0.0874568 | 0.00183613 |
| 11 | BernoulliNB | {'alpha': 1.0, 'binarize': 0.0, 'class_prior':... | 0.785768 | 0.775373 | 0.0570347 | 0.00200269 |
| 7 | PassiveAggressiveClassifier | {'C': 1.0, 'average': False, 'class_weight': N... | 0.734457 | 0.730597 | 0.148826 | 0.00238907 |
| 10 | Perceptron | {'alpha': 0.0001, 'class_weight': None, 'eta0'... | 0.740075 | 0.728731 | 0.162221 | 0.00185683 |
| 9 | SGDClassifier | {'alpha': 0.0001, 'average': False, 'class_wei... | 0.737079 | 0.726119 | 0.17372 | 0.00182471 |
# 导入seaborn和matplotlib.pyplot模块
# 使用seaborn的barplot函数绘制条形图
# x轴为'MLA Test Accuracy Mean',y轴为'MLA Name',数据为MLA_compare,颜色为'm'
sns.barplot(x='MLA Test Accuracy Mean', y='MLA Name', data=MLA_compare, color='m')
# 使用pyplot的title函数设置图表标题
plt.title('Machine Learning Algorithm Accuracy Score \n')
# 使用pyplot的xlabel函数设置x轴标签
plt.xlabel('Accuracy Score (%)')
# 使用pyplot的ylabel函数设置y轴标签
plt.ylabel('Algorithm')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Text(0,0.5,'Algorithm')
- 1

5.1 评估模型性能
让我们回顾一下,通过一些基本的数据清洗、分析和机器学习算法(MLA),我们能够以约82%的准确率预测乘客的生存情况。对于几行代码来说,这已经不错了。但是我们总是会问的问题是,我们能做得更好,更重要的是能否获得我们投入时间的回报(ROI)?例如,如果我们只能将准确率提高1/10个百分点,是否值得投入3个月的开发时间?如果你从事研究工作,也许答案是肯定的,但如果你主要从事商业工作,答案通常是否定的。所以,在改进模型时要记住这一点。
数据科学101:确定基准准确率
在决定如何改进我们的模型之前,让我们确定一下我们的模型是否值得保留。为了做到这一点,我们必须回到数据科学101的基础知识。我们知道这是一个二元问题,因为只有两种可能的结果;乘客幸存或死亡。所以,把它看作是一个硬币翻转问题。如果你有一枚公平的硬币,你猜测正面或反面,那么你有50%的几率猜对。所以,让我们将50%作为最差的模型性能;因为低于这个水平,那么当我可以通过抛硬币来预测时,我为什么还需要你呢?
好吧,所以在没有关于数据集的任何信息的情况下,我们总是可以通过二元问题得到50%的准确率。但是我们有关于数据集的信息,所以我们应该能做得更好。我们知道1502/2224或67.5%的人死亡。因此,如果我们只是预测最常见的情况,即100%的人死亡,那么我们将有67.5%的准确率。所以,让我们将68%作为差模型性能的标准,因为低于这个水平,那么当我可以通过预测最常见的情况来预测时,我为什么还需要你呢?
数据科学101:如何创建自己的模型
我们的准确率在提高,但我们能做得更好吗?我们的数据中有任何信号吗?为了说明这一点,我们将构建自己的决策树模型,因为它是最容易理解和需要简单的加法和乘法计算的模型。在创建决策树时,您希望提出问题,将您的目标响应分割成生存/1和死亡/0的同质子组。这既是科学的一部分,也是艺术的一部分,所以让我们玩一下21个问题的游戏,以展示它是如何工作的。如果你想自己跟着做,下载训练数据集并导入Excel。在行中创建一个透视表,列中是生存情况,值是计数和行计数的百分比,行中是下面描述的特征。
记住,游戏的目标是使用决策树模型创建子组,将生存/1放入一个桶中,将死亡/0放入另一个桶中。我们的经验法则是多数人的规则。也就是说,如果多数人或50%以上幸存,那么我们子组中的每个人都幸存/1,但如果幸存的人少于50%,那么我们子组中的每个人都死亡/0。此外,如果子组少于10个和/或我们的模型准确率达到平稳或下降,我们将停止。明白了吗?我们开始吧!
问题1:你在泰坦尼克号上吗? 如果是,那么大多数人(62%)死亡。请注意,我们的样本生存率与我们的总体生存率不同,尽管如此,如果我们假设每个人都死亡,我们的样本准确率为62%。
问题2:你是男性还是女性? 男性,大多数人(81%)死亡。女性,大多数人(74%)幸存。给我们的准确率为79%。
问题3A(沿着女性分支,计数=314):你是1、2还是3等舱? 1等舱,大多数人(97%)幸存,2等舱,大多数人(92%)幸存。由于死亡子组少于10个,我们将停止沿着这个分支继续下去。3等舱,幸存和死亡的比例是50-50。没有新的信息可以改善我们的模型。
问题4A(沿着女性3等舱分支,计数=144):你是从C、Q还是S登船的? 我们获得了一些信息。C和Q,大多数人仍然幸存,所以没有变化。此外,死亡子组少于10个,所以我们将停止。S,大多数人(63%)死亡。所以,我们将女性、3等舱、从S登船的人从假设他们幸存改为假设他们死亡。我们的模型准确率提高到81%。
问题5A(沿着女性3等舱从S登船的分支,计数=88): 到目前为止,看起来我们做出了正确的决策。再增加一层似乎并没有获得更多的信息。这个子组中有55人死亡,33人幸存,由于大多数人死亡,我们需要找到一个信号来识别这33人,或者找到一个子组将他们从死亡改为幸存,以提高我们的模型准确率。我们可以尝试一下我们的特征。我发现的一个是票价0-8,大多数人幸存。这是一个样本量很小的样本11-9,但在统计学中经常使用。我们稍微提高了准确率,但没有足够的提高使我们超过82%。所以,我们就到这里吧。
问题3B(沿着男性分支,计数=577): 回到问题2,我们知道大多数男性死亡。所以,我们正在寻找一个能够识别大多数幸存的子组的特征。令人惊讶的是,舱位或者登船地并不像对女性那样重要,但是头衔是重要的,并且使我们的准确率达到了82%。尝试其他特征,没有一个能将我们的准确率推到82%以上。所以,我们暂时停在这里。
你做到了,在非常少的信息的情况下,我们达到了82%的准确率。在最差、差、好、更好和最好的尺度上,我们将82%设置为好,因为它是一个简单的模型,给我们带来了不错的结果。但问题仍然存在,我们能比我们手工制作的模型做得更好吗?
在我们继续之前,让我们编写上面所写的代码。请注意,这是一个由“手工”创建的手动过程。你不必这样做,但在开始使用MLA之前了解它是很重要的。把MLA想象成一台TI-89计算器,在微积分考试中使用它非常强大,可以帮助你完成很多繁重的工作。但是如果你在考试中不知道你在做什么,即使是TI-89,也无法帮助你通过。所以,明智地学习下一节的内容。
参考资料:交叉验证和决策树教程
#IMPORTANT: 这是一个手工制作的模型,仅用于学习目的。 #然而,你也可以创建自己的预测模型,而不需要使用复杂的算法 :) #硬币翻转模型,使用随机数生成器生成1/幸存 0/死亡的预测结果 #遍历DataFrame的行,返回(index, Series)对:https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.iterrows.html for index, row in data1.iterrows(): #随机数生成器:https://docs.python.org/2/library/random.html if random.random() > .5: # 随机生成一个0.0到1.0之间的浮点数 data1.set_value(index, 'Random_Predict', 1) #预测为幸存/1 else: data1.set_value(index, 'Random_Predict', 0) #预测为死亡/0 #计算随机猜测幸存的准确率。使用快捷方式 1 = 正确猜测,0 = 错误猜测 #该列的平均值将等于准确率 data1['Random_Score'] = 0 #假设预测错误 data1.loc[(data1['Survived'] == data1['Random_Predict']), 'Random_Score'] = 1 #对于正确的预测,将其设置为1 print('Coin Flip Model Accuracy: {:.2f}%'.format(data1['Random_Score'].mean()*100)) #我们也可以使用scikit的accuracy_score函数来节省几行代码 #http://scikit-learn.org/stable/modules/generated/sklearn.metrics.accuracy_score.html#sklearn.metrics.accuracy_score print('Coin Flip Model Accuracy w/SciKit: {:.2f}%'.format(metrics.accuracy_score(data1['Survived'], data1['Random_Predict'])*100))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
Coin Flip Model Accuracy: 47.81%
Coin Flip Model Accuracy w/SciKit: 47.81%
- 1
- 2
# 通过性别、舱位等因素对数据进行分组,并计算存活率
pivot_female = data1[data1.Sex=='female'].groupby(['Sex','Pclass', 'Embarked','FareBin'])['Survived'].mean()
print('Survival Decision Tree w/Female Node: \n',pivot_female)
# 通过性别、头衔等因素对数据进行分组,并计算存活率
pivot_male = data1[data1.Sex=='male'].groupby(['Sex','Title'])['Survived'].mean()
print('\n\nSurvival Decision Tree w/Male Node: \n',pivot_male)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Survival Decision Tree w/Female Node: Sex Pclass Embarked FareBin female 1 C (14.454, 31.0] 0.666667 (31.0, 512.329] 1.000000 Q (31.0, 512.329] 1.000000 S (14.454, 31.0] 1.000000 (31.0, 512.329] 0.955556 2 C (7.91, 14.454] 1.000000 (14.454, 31.0] 1.000000 (31.0, 512.329] 1.000000 Q (7.91, 14.454] 1.000000 S (7.91, 14.454] 0.875000 (14.454, 31.0] 0.916667 (31.0, 512.329] 1.000000 3 C (-0.001, 7.91] 1.000000 (7.91, 14.454] 0.428571 (14.454, 31.0] 0.666667 Q (-0.001, 7.91] 0.750000 (7.91, 14.454] 0.500000 (14.454, 31.0] 0.714286 S (-0.001, 7.91] 0.533333 (7.91, 14.454] 0.448276 (14.454, 31.0] 0.357143 (31.0, 512.329] 0.125000 Name: Survived, dtype: float64 Survival Decision Tree w/Male Node: Sex Title male Master 0.575000 Misc 0.250000 Mr 0.156673 Name: Survived, dtype: float64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
#handmade data model using brain power (and Microsoft Excel Pivot Tables for quick calculations) #手工制作的数据模型,使用大脑计算(以及Microsoft Excel数据透视表进行快速计算) def mytree(df): #初始化表格以存储预测结果 Model = pd.DataFrame(data = {'Predict':[]}) male_title = ['Master'] #幸存的称号 for index, row in df.iterrows(): #问题1:你是否在泰坦尼克号上;大多数人都死了 Model.loc[index, 'Predict'] = 0 #问题2:你是女性吗;大多数女性幸存 if (df.loc[index, 'Sex'] == 'female'): Model.loc[index, 'Predict'] = 1 #问题3A 女性 - 班级和问题4 登船地点提供最少的信息 #问题5B 女性 - 票价范围;将女性节点决策树中小于0.5的值设为0 if ((df.loc[index, 'Sex'] == 'female') & (df.loc[index, 'Pclass'] == 3) & (df.loc[index, 'Embarked'] == 'S') & (df.loc[index, 'Fare'] > 8) ): Model.loc[index, 'Predict'] = 0 #问题3B 男性:称号;将大于0.5的值设为1,表示大多数幸存 if ((df.loc[index, 'Sex'] == 'male') & (df.loc[index, 'Title'] in male_title) ): Model.loc[index, 'Predict'] = 1 return Model #对数据进行建模 Tree_Predict = mytree(data1) print('Decision Tree Model Accuracy/Precision Score: {:.2f}%\n'.format(metrics.accuracy_score(data1['Survived'], Tree_Predict)*100)) #使用http://scikit-learn.org/stable/modules/generated/sklearn.metrics.classification_report.html#sklearn.metrics.classification_report生成准确率摘要报告 #其中召回率得分=(真正例)/(真正例+假反例),1为最佳:http://scikit-learn.org/stable/modules/generated/sklearn.metrics.recall_score.html#sklearn.metrics.recall_score #F1得分=精确率和召回率的加权平均值,1为最佳:http://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html#sklearn.metrics.f1_score print(metrics.classification_report(data1['Survived'], Tree_Predict))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
Decision Tree Model Accuracy/Precision Score: 82.04%
precision recall f1-score support
0 0.82 0.91 0.86 549
1 0.82 0.68 0.75 342
avg / total 0.82 0.82 0.82 891
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
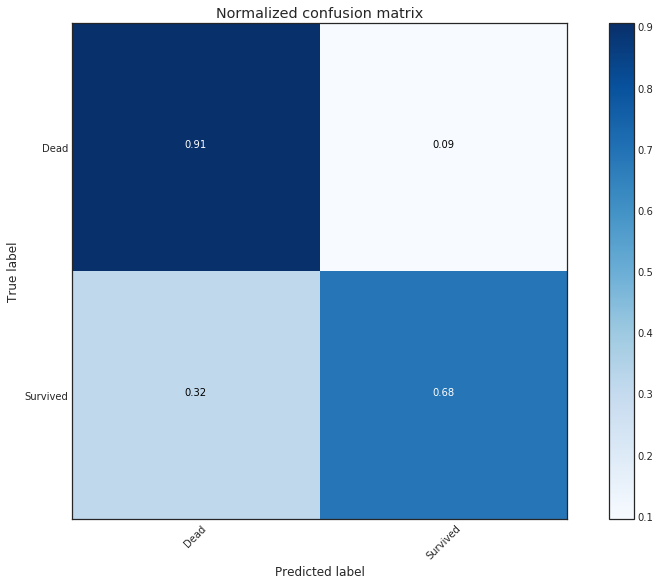
# 绘制混淆矩阵的函数 import itertools def plot_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cmap=plt.cm.Blues): """ 这个函数打印并绘制混淆矩阵。 可以通过设置`normalize=True`来进行归一化。 """ if normalize: # 如果需要归一化,则将混淆矩阵的每个元素除以该行的总和,以得到归一化的混淆矩阵 cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis] print("Normalized confusion matrix") else: print('Confusion matrix, without normalization') # 打印混淆矩阵 print(cm) # 绘制混淆矩阵图像 plt.imshow(cm, interpolation='nearest', cmap=cmap) plt.title(title) plt.colorbar() tick_marks = np.arange(len(classes)) plt.xticks(tick_marks, classes, rotation=45) plt.yticks(tick_marks, classes) fmt = '.2f' if normalize else 'd' thresh = cm.max() / 2. # 在每个混淆矩阵元素的中心位置添加文本,显示该元素的值 for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])): plt.text(j, i, format(cm[i, j], fmt), horizontalalignment="center", color="white" if cm[i, j] > thresh else "black") plt.tight_layout() plt.ylabel('True label') plt.xlabel('Predicted label') # 计算混淆矩阵 cnf_matrix = metrics.confusion_matrix(data1['Survived'], Tree_Predict) np.set_printoptions(precision=2) class_names = ['Dead', 'Survived'] # 绘制未归一化的混淆矩阵图像 plt.figure() plot_confusion_matrix(cnf_matrix, classes=class_names, title='Confusion matrix, without normalization') # 绘制归一化的混淆矩阵图像 plt.figure() plot_confusion_matrix(cnf_matrix, classes=class_names, normalize=True, title='Normalized confusion matrix')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
Confusion matrix, without normalization
[[497 52]
[108 234]]
Normalized confusion matrix
[[ 0.91 0.09]
[ 0.32 0.68]]
- 1
- 2
- 3
- 4
- 5
- 6

5.11 使用交叉验证(CV)评估模型性能
在第5.0步骤中,我们使用了sklearn cross_validate函数来训练、测试和评估我们的模型性能。
记住,我们需要使用不同的子集来构建模型的训练数据和评估模型的测试数据。否则,我们的模型将会过拟合。这意味着它在已经见过的数据上的“预测”非常好,但在未见过的数据上的预测非常糟糕;这根本就不是预测。这就像在学校测验中作弊得到满分,但当你参加考试时,你会失败,因为你从未真正学到任何东西。机器学习也是如此。
CV基本上是一个快捷方式,可以多次拆分和评分我们的模型,这样我们就可以了解它在未见数据上的表现如何。这在Kaggle竞赛或任何一种一致性很重要且应避免出现意外的情况下非常有帮助。
除了CV之外,我们还使用了一个定制的sklearn train test splitter,以在测试评分中引入一些随机性。下面是默认CV拆分的图片。
5.12 使用超参数调整模型
当我们使用sklearn决策树分类器时,我们接受了所有函数的默认值。这给了我们机会看看不同的超参数设置如何改变模型的准确性。(点击这里了解更多关于参数和超参数的信息。)
然而,为了调整模型,我们需要真正理解它。这就是为什么我在前面的部分花时间向你展示预测如何工作的原因。现在让我们更多地了解一下我们的决策树算法。
来源:sklearn
决策树的一些优点包括:
- 简单易懂,易于解释。可以将树可视化。
- 需要很少的数据准备。其他技术通常需要数据归一化,需要创建虚拟变量和删除空值。但请注意,该模块不支持缺失值。
- 使用树进行预测的成本(即预测数据)与用于训练树的数据点数量的对数成正比。
- 能够处理数值和分类数据。其他技术通常专门用于分析只有一种类型变量的数据集。有关更多信息,请参阅算法。
- 能够处理多输出问题。
- 使用白盒模型。如果在模型中观察到某种情况,那么对于该条件的解释很容易通过布尔逻辑来解释。相比之下,在黑盒模型(例如人工神经网络)中,结果可能更难解释。
- 可以使用统计测试验证模型。这使得可以考虑模型的可靠性。
- 即使其假设与生成数据的真实模型略有违背,也能表现良好。
决策树的缺点包括:
- 决策树学习器可能创建过于复杂的树,无法很好地推广数据。这被称为过拟合。为了避免这个问题,需要使用修剪(目前不支持),设置叶节点所需的最小样本数或设置树的最大深度等机制。
- 决策树可能不稳定,因为数据的微小变化可能导致生成完全不同的树。通过在集成中使用决策树可以缓解这个问题。
- 学习最优决策树的问题在多个方面上被认为是NP完全的,甚至对于简单的概念也是如此。因此,实际的决策树学习算法基于启发式算法,如贪婪算法,在每个节点上做出局部最优决策。这样的算法不能保证返回全局最优决策树。通过在集成学习器中训练多个树,可以缓解这个问题,其中特征和样本是随机抽样并替换的。
- 有些概念很难学习,因为决策树不容易表达它们,例如XOR、奇偶校验或多路复用器问题。
- 如果某些类别占主导地位,决策树学习器会创建有偏差的树。因此,建议在拟合决策树之前平衡数据集。
下面是可用的超参数和定义:
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False)
我们将使用ParameterGrid、GridSearchCV和自定义的sklearn评分来调整我们的模型;点击这里了解更多关于ROC_AUC得分的信息。然后我们将使用graphviz可视化我们的树。点击这里了解更多关于ROC_AUC得分的信息。
# 导入需要的库 from sklearn import tree from sklearn import model_selection # 创建决策树分类器对象 dtree = tree.DecisionTreeClassifier(random_state = 0) # 使用交叉验证评估基础模型 base_results = model_selection.cross_validate(dtree, data1[data1_x_bin], data1[Target], cv = cv_split) # 使用训练数据拟合决策树模型 dtree.fit(data1[data1_x_bin], data1[Target]) # 输出决策树模型的参数 print('BEFORE DT Parameters: ', dtree.get_params()) # 输出基础模型的训练得分和测试得分 print("BEFORE DT Training w/bin score mean: {:.2f}". format(base_results['train_score'].mean()*100)) print("BEFORE DT Test w/bin score mean: {:.2f}". format(base_results['test_score'].mean()*100)) print("BEFORE DT Test w/bin score 3*std: +/- {:.2f}". format(base_results['test_score'].std()*100*3)) #print("BEFORE DT Test w/bin set score min: {:.2f}". format(base_results['test_score'].min()*100)) print('-'*10) # 设置超参数的取值范围 param_grid = {'criterion': ['gini', 'entropy'], # 评估标准,两种计算信息增益的公式,gini和entropy,默认为gini #'splitter': ['best', 'random'], # 分割策略,两种策略,best和random,默认为best 'max_depth': [2,4,6,8,10,None], # 决策树的最大深度,默认为None #'min_samples_split': [2,5,10,.03,.05], # 最小分割样本数(占总样本数的比例),默认为2 #'min_samples_leaf': [1,5,10,.03,.05], # 最小叶子节点样本数(占总样本数的比例),默认为1 #'max_features': [None, 'auto'], # 在进行分割时考虑的最大特征数,默认为None或全部特征 'random_state': [0] # 随机数种子,用于控制随机数生成器 } # 使用网格搜索选择最佳模型 tune_model = model_selection.GridSearchCV(tree.DecisionTreeClassifier(), param_grid=param_grid, scoring = 'roc_auc', cv = cv_split) tune_model.fit(data1[data1_x_bin], data1[Target]) # 输出最佳模型的参数 print('AFTER DT Parameters: ', tune_model.best_params_) # 输出最佳模型的训练得分和测试得分 print("AFTER DT Training w/bin score mean: {:.2f}". format(tune_model.cv_results_['mean_train_score'][tune_model.best_index_]*100)) print("AFTER DT Test w/bin score mean: {:.2f}". format(tune_model.cv_results_['mean_test_score'][tune_model.best_index_]*100)) print("AFTER DT Test w/bin score 3*std: +/- {:.2f}". format(tune_model.cv_results_['std_test_score'][tune_model.best_index_]*100*3)) print('-'*10) # 使用最佳模型进行交叉验证 #tune_results = model_selection.cross_validate(tune_model, data1[data1_x_bin], data1[Target], cv = cv_split) # 输出最佳模型的参数和训练得分、测试得分 #print('AFTER DT Parameters: ', tune_model.best_params_) #print("AFTER DT Training w/bin set score mean: {:.2f}". format(tune_results['train_score'].mean()*100)) #print("AFTER DT Test w/bin set score mean: {:.2f}". format(tune_results['test_score'].mean()*100)) #print("AFTER DT Test w/bin set score min: {:.2f}". format(tune_results['test_score'].min()*100)) #print('-'*10)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
BEFORE DT Parameters: {'class_weight': None, 'criterion': 'gini', 'max_depth': None, 'max_features': None, 'max_leaf_nodes': None, 'min_impurity_decrease': 0.0, 'min_impurity_split': None, 'min_samples_leaf': 1, 'min_samples_split': 2, 'min_weight_fraction_leaf': 0.0, 'presort': False, 'random_state': 0, 'splitter': 'best'}
BEFORE DT Training w/bin score mean: 89.51
BEFORE DT Test w/bin score mean: 82.09
BEFORE DT Test w/bin score 3*std: +/- 5.57
----------
AFTER DT Parameters: {'criterion': 'gini', 'max_depth': 4, 'random_state': 0}
AFTER DT Training w/bin score mean: 89.35
AFTER DT Test w/bin score mean: 87.40
AFTER DT Test w/bin score 3*std: +/- 5.00
----------
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
5.13 使用特征选择调整模型
正如之前所述,更多的预测变量并不意味着模型更好,而是选择正确的预测变量才能得到更好的模型。因此,在数据建模中,另一步是进行特征选择。Sklearn提供了几种选择,我们将使用递归特征消除(RFE)与交叉验证(CV)。
#base model #输出数据集data1[data1_x_bin]的形状和列名 print('BEFORE DT RFE Training Shape Old: ', data1[data1_x_bin].shape) print('BEFORE DT RFE Training Columns Old: ', data1[data1_x_bin].columns.values) #输出基础模型的训练得分和测试得分的平均值和标准差 print("BEFORE DT RFE Training w/bin score mean: {:.2f}". format(base_results['train_score'].mean()*100)) print("BEFORE DT RFE Test w/bin score mean: {:.2f}". format(base_results['test_score'].mean()*100)) print("BEFORE DT RFE Test w/bin score 3*std: +/- {:.2f}". format(base_results['test_score'].std()*100*3)) print('-'*10) #feature selection #使用RFECV进行特征选择 dtree_rfe = feature_selection.RFECV(dtree, step = 1, scoring = 'accuracy', cv = cv_split) dtree_rfe.fit(data1[data1_x_bin], data1[Target]) #将x和y转换为减少的特征并拟合新模型 #另一种方法:可以使用管道来减少拟合和转换步骤:http://scikit-learn.org/stable/modules/generated/sklearn.pipeline.Pipeline.html X_rfe = data1[data1_x_bin].columns.values[dtree_rfe.get_support()] rfe_results = model_selection.cross_validate(dtree, data1[X_rfe], data1[Target], cv = cv_split) #print(dtree_rfe.grid_scores_) #输出数据集data1[X_rfe]的形状和列名 print('AFTER DT RFE Training Shape New: ', data1[X_rfe].shape) print('AFTER DT RFE Training Columns New: ', X_rfe) #输出特征选择后的模型的训练得分和测试得分的平均值和标准差 print("AFTER DT RFE Training w/bin score mean: {:.2f}". format(rfe_results['train_score'].mean()*100)) print("AFTER DT RFE Test w/bin score mean: {:.2f}". format(rfe_results['test_score'].mean()*100)) print("AFTER DT RFE Test w/bin score 3*std: +/- {:.2f}". format(rfe_results['test_score'].std()*100*3)) print('-'*10) #tune rfe model #使用GridSearchCV对特征选择后的模型进行调参 rfe_tune_model = model_selection.GridSearchCV(tree.DecisionTreeClassifier(), param_grid=param_grid, scoring = 'roc_auc', cv = cv_split) rfe_tune_model.fit(data1[X_rfe], data1[Target]) #print(rfe_tune_model.cv_results_.keys()) #print(rfe_tune_model.cv_results_['params']) #输出调参后的模型的最佳参数 print('AFTER DT RFE Tuned Parameters: ', rfe_tune_model.best_params_) #print(rfe_tune_model.cv_results_['mean_train_score']) #输出调参后的模型的训练得分和测试得分的平均值和标准差 print("AFTER DT RFE Tuned Training w/bin score mean: {:.2f}". format(rfe_tune_model.cv_results_['mean_train_score'][tune_model.best_index_]*100)) #print(rfe_tune_model.cv_results_['mean_test_score']) print("AFTER DT RFE Tuned Test w/bin score mean: {:.2f}". format(rfe_tune_model.cv_results_['mean_test_score'][tune_model.best_index_]*100)) print("AFTER DT RFE Tuned Test w/bin score 3*std: +/- {:.2f}". format(rfe_tune_model.cv_results_['std_test_score'][tune_model.best_index_]*100*3)) print('-'*10)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
BEFORE DT RFE Training Shape Old: (891, 7) BEFORE DT RFE Training Columns Old: ['Sex_Code' 'Pclass' 'Embarked_Code' 'Title_Code' 'FamilySize' 'AgeBin_Code' 'FareBin_Code'] BEFORE DT RFE Training w/bin score mean: 89.51 BEFORE DT RFE Test w/bin score mean: 82.09 BEFORE DT RFE Test w/bin score 3*std: +/- 5.57 ---------- AFTER DT RFE Training Shape New: (891, 6) AFTER DT RFE Training Columns New: ['Sex_Code' 'Pclass' 'Title_Code' 'FamilySize' 'AgeBin_Code' 'FareBin_Code'] AFTER DT RFE Training w/bin score mean: 88.16 AFTER DT RFE Test w/bin score mean: 83.06 AFTER DT RFE Test w/bin score 3*std: +/- 6.22 ---------- AFTER DT RFE Tuned Parameters: {'criterion': 'gini', 'max_depth': 4, 'random_state': 0} AFTER DT RFE Tuned Training w/bin score mean: 89.39 AFTER DT RFE Tuned Test w/bin score mean: 87.34 AFTER DT RFE Tuned Test w/bin score 3*std: +/- 6.21 ----------
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
# 导入graphviz库 import graphviz # 使用tree.export_graphviz函数生成决策树的MLA版本的图形化表示 # 参数dtree为决策树模型 # 参数out_file为输出文件,默认为None,表示不输出到文件,而是返回生成的图形化表示的字符串 # 参数feature_names为特征的名称列表,用于标识决策树中的特征 # 参数class_names为类别的名称列表,用于标识决策树中的类别 # 参数filled为布尔值,表示是否给决策树的节点填充颜色,默认为False # 参数rounded为布尔值,表示是否给决策树的节点绘制圆角矩形,默认为False dot_data = tree.export_graphviz(dtree, out_file=None, feature_names = data1_x_bin, class_names = True, filled = True, rounded = True) # 使用graphviz库的Source函数将生成的图形化表示字符串转换为图形对象 graph = graphviz.Source(dot_data) # 输出图形对象 graph
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
语料:
<a id="ch11"></a>
- 1
- 2
Step 6: Validate and Implement
The next step is to prepare for submission using the validation data.
第六步:验证和实施
下一步是使用验证数据准备提交。
# 对比算法的预测结果,其中1表示完全相似,0表示完全相反
# 在这些预测结果中有一些1,但也有足够多的蓝色和浅红色,可以通过将它们结合起来创建一个“超级算法”
# 使用correlation_heatmap函数绘制相关性热力图,传入MLA_predict作为参数
- 1
- 2
- 3
# 导入所需的库和模块 # 导入ensemble模块中的VotingClassifier类,用于实现投票分类器 from sklearn import ensemble # 导入gaussian_process模块中的GaussianProcessClassifier类,用于实现高斯过程分类器 from sklearn import gaussian_process # 导入linear_model模块中的LogisticRegressionCV类,用于实现逻辑回归分类器 from sklearn import linear_model # 导入naive_bayes模块中的BernoulliNB和GaussianNB类,用于实现朴素贝叶斯分类器 from sklearn import naive_bayes # 导入neighbors模块中的KNeighborsClassifier类,用于实现K近邻分类器 from sklearn import neighbors # 导入svm模块中的SVC类,用于实现支持向量机分类器 from sklearn import svm # 导入xgboost模块中的XGBClassifier类,用于实现XGBoost分类器 from xgboost import XGBClassifier # 定义投票分类器的模型列表 vote_est = [ # 集成方法 ('ada', ensemble.AdaBoostClassifier()), # AdaBoost分类器 ('bc', ensemble.BaggingClassifier()), # Bagging分类器 ('etc',ensemble.ExtraTreesClassifier()), # ExtraTrees分类器 ('gbc', ensemble.GradientBoostingClassifier()), # GradientBoosting分类器 ('rfc', ensemble.RandomForestClassifier()), # RandomForest分类器 # 高斯过程分类器 ('gpc', gaussian_process.GaussianProcessClassifier()), # 逻辑回归分类器 ('lr', linear_model.LogisticRegressionCV()), # 朴素贝叶斯分类器 ('bnb', naive_bayes.BernoulliNB()), # 伯努利朴素贝叶斯分类器 ('gnb', naive_bayes.GaussianNB()), # 高斯朴素贝叶斯分类器 # K近邻分类器 ('knn', neighbors.KNeighborsClassifier()), # 支持向量机分类器 ('svc', svm.SVC(probability=True)), # XGBoost分类器 ('xgb', XGBClassifier()) ] # 创建硬投票分类器 vote_hard = ensemble.VotingClassifier(estimators=vote_est, voting='hard') # 使用交叉验证对硬投票分类器进行评估 vote_hard_cv = model_selection.cross_validate(vote_hard, data1[data1_x_bin], data1[Target], cv=cv_split) # 使用训练数据对硬投票分类器进行训练 vote_hard.fit(data1[data1_x_bin], data1[Target]) # 输出硬投票分类器的训练得分均值 print("Hard Voting Training w/bin score mean: {:.2f}".format(vote_hard_cv['train_score'].mean() * 100)) # 输出硬投票分类器的测试得分均值 print("Hard Voting Test w/bin score mean: {:.2f}".format(vote_hard_cv['test_score'].mean() * 100)) # 输出硬投票分类器的测试得分3倍标准差 print("Hard Voting Test w/bin score 3*std: +/- {:.2f}".format(vote_hard_cv['test_score'].std() * 100 * 3)) print('-' * 10) # 创建软投票分类器 vote_soft = ensemble.VotingClassifier(estimators=vote_est, voting='soft') # 使用交叉验证对软投票分类器进行评估 vote_soft_cv = model_selection.cross_validate(vote_soft, data1[data1_x_bin], data1[Target], cv=cv_split) # 使用训练数据对软投票分类器进行训练 vote_soft.fit(data1[data1_x_bin], data1[Target]) # 输出软投票分类器的训练得分均值 print("Soft Voting Training w/bin score mean: {:.2f}".format(vote_soft_cv['train_score'].mean() * 100)) # 输出软投票分类器的测试得分均值 print("Soft Voting Test w/bin score mean: {:.2f}".format(vote_soft_cv['test_score'].mean() * 100)) # 输出软投票分类器的测试得分3倍标准差 print("Soft Voting Test w/bin score 3*std: +/- {:.2f}".format(vote_soft_cv['test_score'].std() * 100 * 3)) print('-' * 10)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
Hard Voting Training w/bin score mean: 86.59
Hard Voting Test w/bin score mean: 82.39
Hard Voting Test w/bin score 3*std: +/- 4.95
----------
Soft Voting Training w/bin score mean: 87.15
Soft Voting Test w/bin score mean: 82.35
Soft Voting Test w/bin score 3*std: +/- 4.85
----------
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
#IMPORTANT: THIS SECTION IS UNDER CONSTRUCTION!!!! 12.24.17 #UPDATE: This section was scrapped for the next section; as it's more computational friendly. #WARNING: Running is very computational intensive and time expensive #code is written for experimental/developmental purposes and not production ready #tune each estimator before creating a super model #http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html grid_n_estimator = [50,100,300] # 定义n_estimators的取值范围 grid_ratio = [.1,.25,.5,.75,1.0] # 定义learning_rate和max_samples的取值范围 grid_learn = [.01,.03,.05,.1,.25] # 定义learning_rate的取值范围 grid_max_depth = [2,4,6,None] # 定义max_depth的取值范围 grid_min_samples = [5,10,.03,.05,.10] # 定义min_samples_split和min_samples_leaf的取值范围 grid_criterion = ['gini', 'entropy'] # 定义criterion的取值范围 grid_bool = [True, False] # 定义bool类型的取值范围 grid_seed = [0] # 定义random_state的取值范围 vote_param = [{ # #http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.AdaBoostClassifier.html 'ada__n_estimators': grid_n_estimator, # AdaBoostClassifier的n_estimators参数取值范围 'ada__learning_rate': grid_ratio, # AdaBoostClassifier的learning_rate参数取值范围 'ada__algorithm': ['SAMME', 'SAMME.R'], # AdaBoostClassifier的algorithm参数取值范围 'ada__random_state': grid_seed, # AdaBoostClassifier的random_state参数取值范围 #http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.BaggingClassifier.html#sklearn.ensemble.BaggingClassifier 'bc__n_estimators': grid_n_estimator, # BaggingClassifier的n_estimators参数取值范围 'bc__max_samples': grid_ratio, # BaggingClassifier的max_samples参数取值范围 'bc__oob_score': grid_bool, # BaggingClassifier的oob_score参数取值范围 'bc__random_state': grid_seed, # BaggingClassifier的random_state参数取值范围 #http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.ExtraTreesClassifier.html#sklearn.ensemble.ExtraTreesClassifier 'etc__n_estimators': grid_n_estimator, # ExtraTreesClassifier的n_estimators参数取值范围 'etc__criterion': grid_criterion, # ExtraTreesClassifier的criterion参数取值范围 'etc__max_depth': grid_max_depth, # ExtraTreesClassifier的max_depth参数取值范围 'etc__random_state': grid_seed, # ExtraTreesClassifier的random_state参数取值范围 #http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html#sklearn.ensemble.GradientBoostingClassifier 'gbc__loss': ['deviance', 'exponential'], # GradientBoostingClassifier的loss参数取值范围 'gbc__learning_rate': grid_ratio, # GradientBoostingClassifier的learning_rate参数取值范围 'gbc__n_estimators': grid_n_estimator, # GradientBoostingClassifier的n_estimators参数取值范围 'gbc__criterion': ['friedman_mse', 'mse', 'mae'], # GradientBoostingClassifier的criterion参数取值范围 'gbc__max_depth': grid_max_depth, # GradientBoostingClassifier的max_depth参数取值范围 'gbc__min_samples_split': grid_min_samples, # GradientBoostingClassifier的min_samples_split参数取值范围 'gbc__min_samples_leaf': grid_min_samples, # GradientBoostingClassifier的min_samples_leaf参数取值范围 'gbc__random_state': grid_seed, # GradientBoostingClassifier的random_state参数取值范围 #http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html#sklearn.ensemble.RandomForestClassifier 'rfc__n_estimators': grid_n_estimator, # RandomForestClassifier的n_estimators参数取值范围 'rfc__criterion': grid_criterion, # RandomForestClassifier的criterion参数取值范围 'rfc__max_depth': grid_max_depth, # RandomForestClassifier的max_depth参数取值范围 'rfc__min_samples_split': grid_min_samples, # RandomForestClassifier的min_samples_split参数取值范围 'rfc__min_samples_leaf': grid_min_samples, # RandomForestClassifier的min_samples_leaf参数取值范围 'rfc__bootstrap': grid_bool, # RandomForestClassifier的bootstrap参数取值范围 'rfc__oob_score': grid_bool, # RandomForestClassifier的oob_score参数取值范围 'rfc__random_state': grid_seed, # RandomForestClassifier的random_state参数取值范围 #http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegressionCV.html#sklearn.linear_model.LogisticRegressionCV 'lr__fit_intercept': grid_bool, # LogisticRegressionCV的fit_intercept参数取值范围 'lr__penalty': ['l1','l2'], # LogisticRegressionCV的penalty参数取值范围 'lr__solver': ['newton-cg', 'lbfgs', 'liblinear', 'sag', 'saga'], # LogisticRegressionCV的solver参数取值范围 'lr__random_state': grid_seed, # LogisticRegressionCV的random_state参数取值范围 #http://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.BernoulliNB.html#sklearn.naive_bayes.BernoulliNB 'bnb__alpha': grid_ratio, # BernoulliNB的alpha参数取值范围 'bnb__prior': grid_bool, # BernoulliNB的prior参数取值范围 'bnb__random_state': grid_seed, # BernoulliNB的random_state参数取值范围 #http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html#sklearn.neighbors.KNeighborsClassifier 'knn__n_neighbors': [1,2,3,4,5,6,7], # KNeighborsClassifier的n_neighbors参数取值范围 'knn__weights': ['uniform', 'distance'], # KNeighborsClassifier的weights参数取值范围 'knn__algorithm': ['auto', 'ball_tree', 'kd_tree', 'brute'], # KNeighborsClassifier的algorithm参数取值范围 'knn__random_state': grid_seed, # KNeighborsClassifier的random_state参数取值范围 #http://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html#sklearn.svm.SVC #http://blog.hackerearth.com/simple-tutorial-svm-parameter-tuning-python-r 'svc__kernel': ['linear', 'poly', 'rbf', 'sigmoid'], # SVC的kernel参数取值范围 'svc__C': grid_max_depth, # SVC的C参数取值范围 'svc__gamma': grid_ratio, # SVC的gamma参数取值范围 'svc__decision_function_shape': ['ovo', 'ovr'], # SVC的decision_function_shape参数取值范围 'svc__probability': [True], # SVC的probability参数取值范围 'svc__random_state': grid_seed, # SVC的random_state参数取值范围 #http://xgboost.readthedocs.io/en/latest/parameter.html 'xgb__learning_rate': grid_ratio, # XGBClassifier的learning_rate参数取值范围 'xgb__max_depth': [2,4,6,8,10], # XGBClassifier的max_depth参数取值范围 'xgb__tree_method': ['exact', 'approx', 'hist'], # XGBClassifier的tree_method参数取值范围 'xgb__objective': ['reg:linear', 'reg:logistic', 'binary:logistic'], # XGBClassifier的objective参数取值范围 'xgb__seed': grid_seed # XGBClassifier的seed参数取值范围 }] #Soft Vote with tuned models #grid_soft = model_selection.GridSearchCV(estimator = vote_soft, param_grid = vote_param, cv = 2, scoring = 'roc_auc') #grid_soft.fit(data1[data1_x_bin], data1[Target]) #print(grid_soft.cv_results_.keys()) #print(grid_soft.cv_results_['params']) #print('Soft Vote Tuned Parameters: ', grid_soft.best_params_) #print(grid_soft.cv_results_['mean_train_score']) #print("Soft Vote Tuned Training w/bin set score mean: {:.2f}". format(grid_soft.cv_results_['mean_train_score'][tune_model.best_index_]*100)) #print(grid_soft.cv_results_['mean_test_score']) #print("Soft Vote Tuned Test w/bin set score mean: {:.2f}". format(grid_soft.cv_results_['mean_test_score'][tune_model.best_index_]*100)) #print("Soft Vote Tuned Test w/bin score 3*std: +/- {:.2f}". format(grid_soft.cv_results_['std_test_score'][tune_model.best_index_]*100*3)) #print('-'*10) #credit: https://rasbt.github.io/mlxtend/user_guide/classifier/EnsembleVoteClassifier/ #cv_keys = ('mean_test_score', 'std_test_score', 'params') #for r, _ in enumerate(grid_soft.cv_results_['mean_test_score']): # print("%0.3f +/- %0.2f %r" # % (grid_soft.cv_results_[cv_keys[0]][r], # grid_soft.cv_results_[cv_keys[1]][r] / 2.0, # grid_soft.cv_results_[cv_keys[2]][r])) #print('-'*10)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
#WARNING: Running is very computational intensive and time expensive. #Code is written for experimental/developmental purposes and not production ready! #定义一些超参数的取值范围 grid_n_estimator = [10, 50, 100, 300] #AdaBoostClassifier和BaggingClassifier的n_estimators参数的取值范围 grid_ratio = [.1, .25, .5, .75, 1.0] #BaggingClassifier的max_samples参数的取值范围和SVC的gamma参数的取值范围 grid_learn = [.01, .03, .05, .1, .25] #AdaBoostClassifier和GradientBoostingClassifier的learning_rate参数的取值范围 grid_max_depth = [2, 4, 6, 8, 10, None] #ExtraTreesClassifier和GradientBoostingClassifier的max_depth参数的取值范围 grid_min_samples = [5, 10, .03, .05, .10] #暂时没有使用到 grid_criterion = ['gini', 'entropy'] #ExtraTreesClassifier和RandomForestClassifier的criterion参数的取值范围 grid_bool = [True, False] #LogisticRegressionCV的fit_intercept参数的取值范围 grid_seed = [0] #随机种子 #定义一些模型的参数组合 grid_param = [ [{ #AdaBoostClassifier - http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.AdaBoostClassifier.html 'n_estimators': grid_n_estimator, #default=50 'learning_rate': grid_learn, #default=1 #'algorithm': ['SAMME', 'SAMME.R'], #default=’SAMME.R 'random_state': grid_seed }], [{ #BaggingClassifier - http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.BaggingClassifier.html#sklearn.ensemble.BaggingClassifier 'n_estimators': grid_n_estimator, #default=10 'max_samples': grid_ratio, #default=1.0 'random_state': grid_seed }], [{ #ExtraTreesClassifier - http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.ExtraTreesClassifier.html#sklearn.ensemble.ExtraTreesClassifier 'n_estimators': grid_n_estimator, #default=10 'criterion': grid_criterion, #default=”gini” 'max_depth': grid_max_depth, #default=None 'random_state': grid_seed }], [{ #GradientBoostingClassifier - http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html#sklearn.ensemble.GradientBoostingClassifier #'loss': ['deviance', 'exponential'], #default=’deviance’ 'learning_rate': [.05], #default=0.1 -- 12/31/17 set to reduce runtime -- The best parameter for GradientBoostingClassifier is {'learning_rate': 0.05, 'max_depth': 2, 'n_estimators': 300, 'random_state': 0} with a runtime of 264.45 seconds. 'n_estimators': [300], #default=100 -- 12/31/17 set to reduce runtime -- The best parameter for GradientBoostingClassifier is {'learning_rate': 0.05, 'max_depth': 2, 'n_estimators': 300, 'random_state': 0} with a runtime of 264.45 seconds. #'criterion': ['friedman_mse', 'mse', 'mae'], #default=”friedman_mse” 'max_depth': grid_max_depth, #default=3 'random_state': grid_seed }], [{ #RandomForestClassifier - http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html#sklearn.ensemble.RandomForestClassifier 'n_estimators': grid_n_estimator, #default=10 'criterion': grid_criterion, #default=”gini” 'max_depth': grid_max_depth, #default=None 'oob_score': [True], #default=False -- 12/31/17 set to reduce runtime -- The best parameter for RandomForestClassifier is {'criterion': 'entropy', 'max_depth': 6, 'n_estimators': 100, 'oob_score': True, 'random_state': 0} with a runtime of 146.35 seconds. 'random_state': grid_seed }], [{ #GaussianProcessClassifier 'max_iter_predict': grid_n_estimator, #default: 100 'random_state': grid_seed }], [{ #LogisticRegressionCV - http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegressionCV.html#sklearn.linear_model.LogisticRegressionCV 'fit_intercept': grid_bool, #default: True #'penalty': ['l1','l2'], 'solver': ['newton-cg', 'lbfgs', 'liblinear', 'sag', 'saga'], #default: lbfgs 'random_state': grid_seed }], [{ #BernoulliNB - http://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.BernoulliNB.html#sklearn.naive_bayes.BernoulliNB 'alpha': grid_ratio, #default: 1.0 }], #GaussianNB - [{}], [{ #KNeighborsClassifier - http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html#sklearn.neighbors.KNeighborsClassifier 'n_neighbors': [1,2,3,4,5,6,7], #default: 5 'weights': ['uniform', 'distance'], #default = ‘uniform’ 'algorithm': ['auto', 'ball_tree', 'kd_tree', 'brute'] }], [{ #SVC - http://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html#sklearn.svm.SVC #http://blog.hackerearth.com/simple-tutorial-svm-parameter-tuning-python-r #'kernel': ['linear', 'poly', 'rbf', 'sigmoid'], 'C': [1,2,3,4,5], #default=1.0 'gamma': grid_ratio, #edfault: auto 'decision_function_shape': ['ovo', 'ovr'], #default:ovr 'probability': [True], 'random_state': grid_seed }], [{ #XGBClassifier - http://xgboost.readthedocs.io/en/latest/parameter.html 'learning_rate': grid_learn, #default: .3 'max_depth': [1,2,4,6,8,10], #default 2 'n_estimators': grid_n_estimator, 'seed': grid_seed }] ] start_total = time.perf_counter() #记录总的运行时间 for clf, param in zip (vote_est, grid_param): #对于每个模型和其对应的参数组合进行遍历 start = time.perf_counter() best_search = model_selection.GridSearchCV(estimator = clf[1], param_grid = param, cv = cv_split, scoring = 'roc_auc') #使用GridSearchCV进行参数搜索 best_search.fit(data1[data1_x_bin], data1[Target]) #在训练集上进行参数搜索 run = time.perf_counter() - start #记录每个模型的运行时间 best_param = best_search.best_params_ #获取最佳参数 print('The best parameter for {} is {} with a runtime of {:.2f} seconds.'.format(clf[1].__class__.__name__, best_param, run)) clf[1].set_params(**best_param) #将最佳参数设置给模型 run_total = time.perf_counter() - start_total #记录总的运行时间 print('Total optimization time was {:.2f} minutes.'.format(run_total/60)) print('-'*10)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
The best parameter for AdaBoostClassifier is {'learning_rate': 0.1, 'n_estimators': 300, 'random_state': 0} with a runtime of 37.28 seconds.
The best parameter for BaggingClassifier is {'max_samples': 0.25, 'n_estimators': 300, 'random_state': 0} with a runtime of 33.04 seconds.
The best parameter for ExtraTreesClassifier is {'criterion': 'entropy', 'max_depth': 6, 'n_estimators': 100, 'random_state': 0} with a runtime of 68.93 seconds.
The best parameter for GradientBoostingClassifier is {'learning_rate': 0.05, 'max_depth': 2, 'n_estimators': 300, 'random_state': 0} with a runtime of 38.77 seconds.
The best parameter for RandomForestClassifier is {'criterion': 'entropy', 'max_depth': 6, 'n_estimators': 100, 'oob_score': True, 'random_state': 0} with a runtime of 84.14 seconds.
The best parameter for GaussianProcessClassifier is {'max_iter_predict': 10, 'random_state': 0} with a runtime of 6.19 seconds.
The best parameter for LogisticRegressionCV is {'fit_intercept': True, 'random_state': 0, 'solver': 'liblinear'} with a runtime of 9.40 seconds.
The best parameter for BernoulliNB is {'alpha': 0.1} with a runtime of 0.24 seconds.
The best parameter for GaussianNB is {} with a runtime of 0.05 seconds.
The best parameter for KNeighborsClassifier is {'algorithm': 'brute', 'n_neighbors': 7, 'weights': 'uniform'} with a runtime of 5.56 seconds.
The best parameter for SVC is {'C': 2, 'decision_function_shape': 'ovo', 'gamma': 0.1, 'probability': True, 'random_state': 0} with a runtime of 30.49 seconds.
The best parameter for XGBClassifier is {'learning_rate': 0.01, 'max_depth': 4, 'n_estimators': 300, 'seed': 0} with a runtime of 43.57 seconds.
Total optimization time was 5.96 minutes.
----------
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
# 导入所需的库 # 创建一个Hard Voting分类器,使用之前定义的vote_est模型列表,voting方式为'hard' grid_hard = ensemble.VotingClassifier(estimators = vote_est , voting = 'hard') # 使用交叉验证对Hard Voting分类器进行评估,使用data1[data1_x_bin]作为特征数据,data1[Target]作为目标数据,cv参数为cv_split grid_hard_cv = model_selection.cross_validate(grid_hard, data1[data1_x_bin], data1[Target], cv = cv_split) # 使用data1[data1_x_bin]和data1[Target]对Hard Voting分类器进行训练 grid_hard.fit(data1[data1_x_bin], data1[Target]) # 打印Hard Voting分类器在训练集上的平均得分 print("Hard Voting w/Tuned Hyperparameters Training w/bin score mean: {:.2f}". format(grid_hard_cv['train_score'].mean()*100)) # 打印Hard Voting分类器在测试集上的平均得分 print("Hard Voting w/Tuned Hyperparameters Test w/bin score mean: {:.2f}". format(grid_hard_cv['test_score'].mean()*100)) # 打印Hard Voting分类器在测试集上的得分的3倍标准差 print("Hard Voting w/Tuned Hyperparameters Test w/bin score 3*std: +/- {:.2f}". format(grid_hard_cv['test_score'].std()*100*3)) print('-'*10) # 创建一个Soft Voting分类器,使用之前定义的vote_est模型列表,voting方式为'soft' grid_soft = ensemble.VotingClassifier(estimators = vote_est , voting = 'soft') # 使用交叉验证对Soft Voting分类器进行评估,使用data1[data1_x_bin]作为特征数据,data1[Target]作为目标数据,cv参数为cv_split grid_soft_cv = model_selection.cross_validate(grid_soft, data1[data1_x_bin], data1[Target], cv = cv_split) # 使用data1[data1_x_bin]和data1[Target]对Soft Voting分类器进行训练 grid_soft.fit(data1[data1_x_bin], data1[Target]) # 打印Soft Voting分类器在训练集上的平均得分 print("Soft Voting w/Tuned Hyperparameters Training w/bin score mean: {:.2f}". format(grid_soft_cv['train_score'].mean()*100)) # 打印Soft Voting分类器在测试集上的平均得分 print("Soft Voting w/Tuned Hyperparameters Test w/bin score mean: {:.2f}". format(grid_soft_cv['test_score'].mean()*100)) # 打印Soft Voting分类器在测试集上的得分的3倍标准差 print("Soft Voting w/Tuned Hyperparameters Test w/bin score 3*std: +/- {:.2f}". format(grid_soft_cv['test_score'].std()*100*3)) print('-'*10) # 输出各个分类器的最佳参数和运行时间 # AdaBoostClassifier的最佳参数是{'learning_rate': 0.1, 'n_estimators': 300, 'random_state': 0},运行时间为33.39秒 # BaggingClassifier的最佳参数是{'max_samples': 0.25, 'n_estimators': 300, 'random_state': 0},运行时间为30.28秒 # ExtraTreesClassifier的最佳参数是{'criterion': 'entropy', 'max_depth': 6, 'n_estimators': 100, 'random_state': 0},运行时间为64.76秒 # GradientBoostingClassifier的最佳参数是{'learning_rate': 0.05, 'max_depth': 2, 'n_estimators': 300, 'random_state': 0},运行时间为34.35秒 # RandomForestClassifier的最佳参数是{'criterion': 'entropy', 'max_depth': 6, 'n_estimators': 100, 'oob_score': True, 'random_state': 0},运行时间为76.32秒 # GaussianProcessClassifier的最佳参数是{'max_iter_predict': 10, 'random_state': 0},运行时间为6.01秒 # LogisticRegressionCV的最佳参数是{'fit_intercept': True, 'random_state': 0, 'solver': 'liblinear'},运行时间为8.04秒 # BernoulliNB的最佳参数是{'alpha': 0.1},运行时间为0.19秒 # GaussianNB的最佳参数是{},运行时间为0.04秒 # KNeighborsClassifier的最佳参数是{'algorithm': 'brute', 'n_neighbors': 7, 'weights': 'uniform'},运行时间为4.84秒 # SVC的最佳参数是{'C': 2, 'decision_function_shape': 'ovo', 'gamma': 0.1, 'probability': True, 'random_state': 0},运行时间为29.39秒 # XGBClassifier的最佳参数是{'learning_rate': 0.01, 'max_depth': 4, 'n_estimators': 300, 'seed': 0},运行时间为46.23秒 # 总优化时间为5.56分钟。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
Hard Voting w/Tuned Hyperparameters Training w/bin score mean: 85.22
Hard Voting w/Tuned Hyperparameters Test w/bin score mean: 82.31
Hard Voting w/Tuned Hyperparameters Test w/bin score 3*std: +/- 5.26
----------
Soft Voting w/Tuned Hyperparameters Training w/bin score mean: 84.76
Soft Voting w/Tuned Hyperparameters Test w/bin score mean: 82.28
Soft Voting w/Tuned Hyperparameters Test w/bin score 3*std: +/- 5.42
----------
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
# 准备数据进行建模 # 打印数据信息 print(data_val.info()) print("-"*10) # 手工决策树 - 提交得分 = 0.77990 # 将Survived列设置为mytree函数的返回值,并转换为整数类型 data_val['Survived'] = mytree(data_val).astype(int) # 决策树建模 - 使用完整数据集进行建模,提交得分:默认=0.76555,调整后=0.77990 # 使用决策树分类器进行建模 # submit_dt = tree.DecisionTreeClassifier() # submit_dt = model_selection.GridSearchCV(tree.DecisionTreeClassifier(), param_grid=param_grid, scoring='roc_auc', cv=cv_split) # submit_dt.fit(data1[data1_x_bin], data1[Target]) # print('Best Parameters: ', submit_dt.best_params_) # 最佳参数: {'criterion': 'gini', 'max_depth': 4, 'random_state': 0} # 将Survived列设置为submit_dt.predict函数的返回值 # data_val['Survived'] = submit_dt.predict(data_val[data1_x_bin]) # Bagging建模 - 使用完整数据集进行建模,提交得分:默认=0.75119,调整后=0.77990 # 使用Bagging分类器进行建模 # submit_bc = ensemble.BaggingClassifier() # submit_bc = model_selection.GridSearchCV(ensemble.BaggingClassifier(), param_grid={'n_estimators':grid_n_estimator, 'max_samples': grid_ratio, 'oob_score': grid_bool, 'random_state': grid_seed}, scoring='roc_auc', cv=cv_split) # submit_bc.fit(data1[data1_x_bin], data1[Target]) # print('Best Parameters: ', submit_bc.best_params_) # 最佳参数: {'max_samples': 0.25, 'n_estimators': 500, 'oob_score': True, 'random_state': 0} # 将Survived列设置为submit_bc.predict函数的返回值 # data_val['Survived'] = submit_bc.predict(data_val[data1_x_bin]) # Extra Tree建模 - 使用完整数据集进行建模,提交得分:默认=0.76555,调整后=0.77990 # 使用Extra Trees分类器进行建模 # submit_etc = ensemble.ExtraTreesClassifier() # submit_etc = model_selection.GridSearchCV(ensemble.ExtraTreesClassifier(), param_grid={'n_estimators': grid_n_estimator, 'criterion': grid_criterion, 'max_depth': grid_max_depth, 'random_state': grid_seed}, scoring='roc_auc', cv=cv_split) # submit_etc.fit(data1[data1_x_bin], data1[Target]) # print('Best Parameters: ', submit_etc.best_params_) # 最佳参数: {'criterion': 'entropy', 'max_depth': 6, 'n_estimators': 100, 'random_state': 0} # 将Survived列设置为submit_etc.predict函数的返回值 # data_val['Survived'] = submit_etc.predict(data_val[data1_x_bin]) # Random Forest建模 - 使用完整数据集进行建模,提交得分:默认=0.71291,调整后=0.73205 # 使用Random Forest分类器进行建模 # submit_rfc = ensemble.RandomForestClassifier() # submit_rfc = model_selection.GridSearchCV(ensemble.RandomForestClassifier(), param_grid={'n_estimators': grid_n_estimator, 'criterion': grid_criterion, 'max_depth': grid_max_depth, 'random_state': grid_seed}, scoring='roc_auc', cv=cv_split) # submit_rfc.fit(data1[data1_x_bin], data1[Target]) # print('Best Parameters: ', submit_rfc.best_params_) # 最佳参数: {'criterion': 'entropy', 'max_depth': 6, 'n_estimators': 100, 'random_state': 0} # 将Survived列设置为submit_rfc.predict函数的返回值 # data_val['Survived'] = submit_rfc.predict(data_val[data1_x_bin]) # Ada Boosting建模 - 使用完整数据集进行建模,提交得分:默认=0.74162,调整后=0.75119 # 使用Ada Boosting分类器进行建模 # submit_abc = ensemble.AdaBoostClassifier() # submit_abc = model_selection.GridSearchCV(ensemble.AdaBoostClassifier(), param_grid={'n_estimators': grid_n_estimator, 'learning_rate': grid_ratio, 'algorithm': ['SAMME', 'SAMME.R'], 'random_state': grid_seed}, scoring='roc_auc', cv=cv_split) # submit_abc.fit(data1[data1_x_bin], data1[Target]) # print('Best Parameters: ', submit_abc.best_params_) # 最佳参数: {'algorithm': 'SAMME.R', 'learning_rate': 0.1, 'n_estimators': 300, 'random_state': 0} # 将Survived列设置为submit_abc.predict函数的返回值 # data_val['Survived'] = submit_abc.predict(data_val[data1_x_bin]) # Gradient Boosting建模 - 使用完整数据集进行建模,提交得分:默认=0.75119,调整后=0.77033 # 使用Gradient Boosting分类器进行建模 # submit_gbc = ensemble.GradientBoostingClassifier() # submit_gbc = model_selection.GridSearchCV(ensemble.GradientBoostingClassifier(), param_grid={'learning_rate': grid_ratio, 'n_estimators': grid_n_estimator, 'max_depth': grid_max_depth, 'random_state':grid_seed}, scoring='roc_auc', cv=cv_split) # submit_gbc.fit(data1[data1_x_bin], data1[Target]) # print('Best Parameters: ', submit_gbc.best_params_) # 最佳参数: {'learning_rate': 0.25, 'max_depth': 2, 'n_estimators': 50, 'random_state': 0} # 将Survived列设置为submit_gbc.predict函数的返回值 # data_val['Survived'] = submit_gbc.predict(data_val[data1_x_bin]) # Extreme Boosting建模 - 使用完整数据集进行建模,提交得分:默认=0.73684,调整后=0.77990 # 使用Extreme Boosting分类器进行建模 # submit_xgb = XGBClassifier() # submit_xgb = model_selection.GridSearchCV(XGBClassifier(), param_grid={'learning_rate': grid_learn, 'max_depth': [0,2,4,6,8,10], 'n_estimators': grid_n_estimator, 'seed': grid_seed}, scoring='roc_auc', cv=cv_split) # submit_xgb.fit(data1[data1_x_bin], data1[Target]) # print('Best Parameters: ', submit_xgb.best_params_) # 最佳参数: {'learning_rate': 0.01, 'max_depth': 4, 'n_estimators': 300, 'seed': 0} # 将Survived列设置为submit_xgb.predict函数的返回值 # data_val['Survived'] = submit_xgb.predict(data_val[data1_x_bin]) # Hard Voting分类器 - 使用完整数据集进行建模,提交得分:默认=0.75598,调整后=0.77990 # 将Survived列设置为grid_hard.predict函数的返回值 data_val['Survived'] = grid_hard.predict(data_val[data1_x_bin]) # Soft Voting分类器 - 使用完整数据集进行建模,提交得分:默认=0.73684,调整后=0.74162 # 将Survived列设置为vote_soft.predict函数的返回值 # data_val['Survived'] = vote_soft.predict(data_val[data1_x_bin]) # data_val['Survived'] = grid_soft.predict(data_val[data1_x_bin]) # 提交文件 submit = data_val[['PassengerId','Survived']] submit.to_csv("../working/submit.csv", index=False) # 打印验证数据分布 print('Validation Data Distribution: \n', data_val['Survived'].value_counts(normalize=True)) # 随机抽取10个样本 submit.sample(10)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
<class 'pandas.core.frame.DataFrame'> RangeIndex: 418 entries, 0 to 417 Data columns (total 21 columns): PassengerId 418 non-null int64 Pclass 418 non-null int64 Name 418 non-null object Sex 418 non-null object Age 418 non-null float64 SibSp 418 non-null int64 Parch 418 non-null int64 Ticket 418 non-null object Fare 418 non-null float64 Cabin 91 non-null object Embarked 418 non-null object FamilySize 418 non-null int64 IsAlone 418 non-null int64 Title 418 non-null object FareBin 418 non-null category AgeBin 418 non-null category Sex_Code 418 non-null int64 Embarked_Code 418 non-null int64 Title_Code 418 non-null int64 AgeBin_Code 418 non-null int64 FareBin_Code 418 non-null int64 dtypes: category(2), float64(2), int64(11), object(6) memory usage: 63.1+ KB None ---------- Validation Data Distribution: 0 0.633971 1 0.366029 Name: Survived, dtype: float64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
| PassengerId | Survived | |
|---|---|---|
| 113 | 1005 | 1 |
| 69 | 961 | 1 |
| 70 | 962 | 1 |
| 191 | 1083 | 0 |
| 376 | 1268 | 1 |
| 37 | 929 | 1 |
| 46 | 938 | 1 |
| 236 | 1128 | 0 |
| 294 | 1186 | 0 |
| 366 | 1258 | 0 |
第七步:优化和策略
结论
数据科学框架的第一次迭代似乎收敛于0.77990的提交准确率。使用相同的数据集和不同的决策树实现(adaboost、随机森林、梯度提升、xgboost等)进行调优,都无法超过0.77990的提交准确率。有趣的是,在这个数据集中,简单的决策树算法具有最佳的默认提交分数,并且通过调优实现了相同的最佳准确率。
虽然在单个数据集上测试少数算法无法得出一般性结论,但对于提到的数据集有几点观察结果:
- 训练数据集与测试/验证数据集和总体人口的分布不同。这导致交叉验证(CV)准确率和Kaggle提交准确率之间存在较大差距。
- 在相同的数据集下,基于决策树的算法在适当的调优后似乎收敛于相同的准确率。
- 尽管经过调优,没有机器学习算法能够超过自制算法。作者认为,对于小数据集来说,人工算法是要超越的标杆。
基于这些观察结果,对于第二次迭代,我将花更多时间在预处理和特征工程上,以更好地对齐CV分数和Kaggle分数,并提高整体准确率。

