
- 1js排序的时间复杂度_JavaScript系列--如何快速进行时间复杂度和空间复杂度分析...
- 2智能驾驶的狂想与现实落地_自动驾驶 小马智行 禾多科技
- 3【Python】 Python中的配置文件管理模块:“cfg“ 的安装与应用_python cfg模块
- 4360测绘云Quake网络空间测绘系统双领域上榜“安全牛”_360的quake
- 5python图形界面教程(tkinter)_python图形化界面
- 6Python - 深度学习系列31 - ollama的搭建与使用_ollama安装
- 7c++获取文件信息——_stat函数的使用__stat64i32
- 8共识问题:区块链如何确认记账权?_区块链候选记账权
- 9CCleaner2024win电脑专用系统垃圾清理与优化工具
- 10uniapp 阿里云点播 视频播放
jdk1.8 hashmap
赞
踩
1、HashMap概述
在JDK1.8之前,HashMap采用数组+链表实现,即使用链表处理冲突,同一hash值的节点都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,HashMap采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
下图中代表jdk1.8之前的hashmap结构,左边部分即代表哈希表,也称为哈希数组,数组的每个元素都是一个单链表的头节点,链表是用来解决冲突的,如果不同的key映射到了数组的同一位置处,就将其放入单链表中。
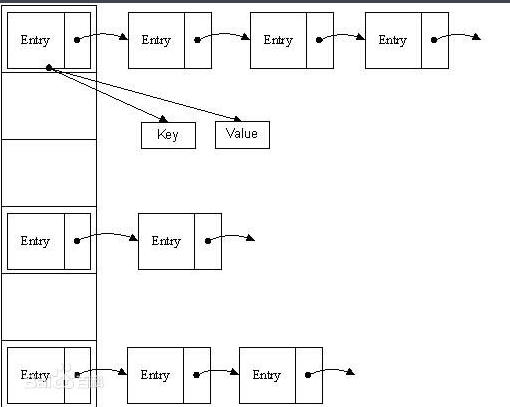
jdk1.8之前hashmap结构图
jdk1.8之前的hashmap都采用上图的结构,都是基于一个数组和多个单链表,hash值冲突的时候,就将对应节点以链表的形式存储。如果在一个链表中查找其中一个节点时,将会花费O(n)的查找时间,会有很大的性能损失。到了jdk1.8,当同一个hash值的节点数不小于8时,不再采用单链表形式存储,而是采用红黑树,如下图所示。
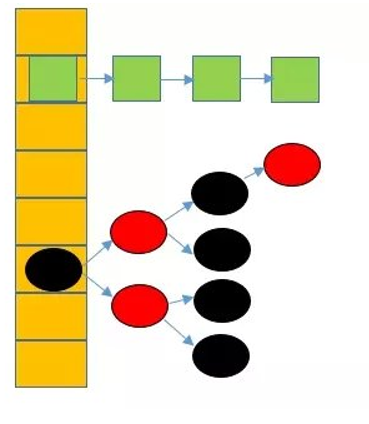
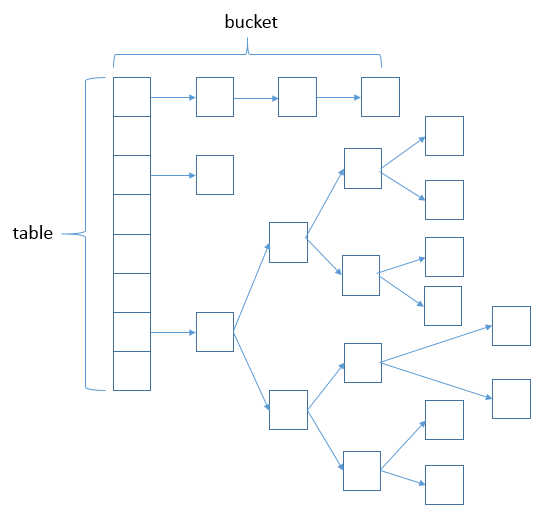
jdk1.8 hashmap结构图
说明:上图很形象的展示了HashMap的数据结构(数组+链表+红黑树),桶中的结构可能是链表,也可能是红黑树,红黑树的引入是为了提高效率。
2、处理hash冲突的链表和红黑树以及位桶(数据结构)
2.1 链表的实现
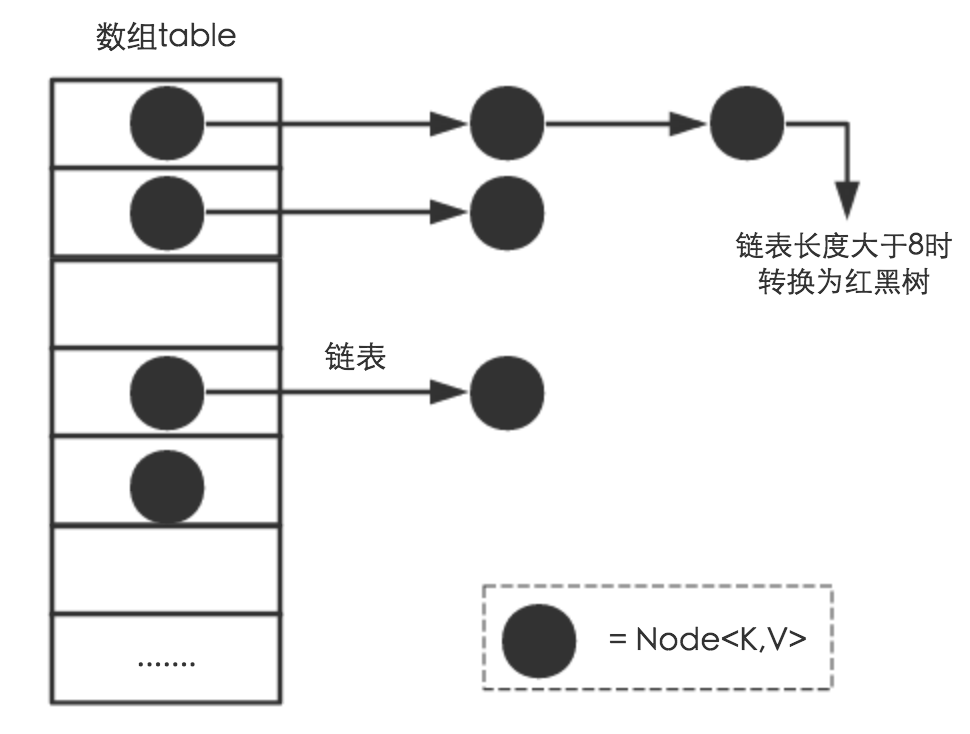
Node是HashMap的一个内部类,实现了Map.Entry接口,本质是就是一个映射(键值对)。上图中的每个黑色圆点就是一个Node对象。来看具体代码:
- //Node是单向链表,它实现了Map.Entry接口
- static class Node<k,v> implements Map.Entry<k,v> {
- final int hash;
- final K key;
- V value;
- Node<k,v> next;
- //构造函数Hash值键值下一个节点
- Node(int hash, K key, V value, Node<k,v> next) {
- this.hash = hash;
- this.key = key;
- this.value = value;
- this.next = next;
- }
-
- public final K getKey() { return key; }
- public final V getValue() { return value; }
- public final String toString() { return key + = + value; }
-
- public final int hashCode() {
- return Objects.hashCode(key) ^ Objects.hashCode(value);
- }
-
- public final V setValue(V newValue) {
- V oldValue = value;
- value = newValue;
- return oldValue;
- }
- //判断两个node是否相等,若key和value都相等,返回true。可以与自身比较为true
- public final boolean equals(Object o) {
- if (o == this)
- return true;
- if (o instanceof Map.Entry) {
- Map.Entry<!--?,?--> e = (Map.Entry<!--?,?-->)o;
- if (Objects.equals(key, e.getKey()) &&
- Objects.equals(value, e.getValue()))
- return true;
- }
- return false;
- }
- }

可以看到,node中包含一个next变量,这个就是链表的关键点,hash结果相同的元素就是通过这个next进行关联的。
2.2 红黑树
红黑树比链表多了四个变量,parent父节点、left左节点、right右节点、prev上一个同级节点,红黑树内容较多,不在赘述。
2.3 位桶
transient Node<k,v>[] table;//存储(位桶)的数组HashMap类中有一个非常重要的字段,就是 Node[] table,即哈希桶数组,明显它是一个Node的数组。
有了以上3个数据结构,只要有一点数据结构基础的人,都可以大致联想到HashMap的实现了。首先有一个每个元素都是链表(可能表述不准确)的数组,当添加一个元素(key-value)时,就首先计算元素key的hash值,以此确定插入数组中的位置,但是可能存在同一hash值的元素已经被放在数组同一位置了,这时就添加到同一hash值的元素的后面,他们在数组的同一位置,但是形成了链表,所以说数组存放的是链表。而当链表长度太长时,链表就转换为红黑树,这样大大提高了查找的效率。
3、HashMap源码分析
3.1 类的继承关系
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable可以看到HashMap继承自父类(AbstractMap),实现了Map、Cloneable、Serializable接口。其中,Map接口定义了一组通用的操作;Cloneable接口则表示可以进行拷贝,在HashMap中,实现的是浅层次拷贝,即对拷贝对象的改变会影响被拷贝的对象;Serializable接口表示HashMap实现了序列化,即可以将HashMap对象保存至本地,之后可

