
- 1textarea标签没有左对齐显示数据_layui textarea不对齐
- 22024年你的登录接口真的安全吗?,2024年最新网络安全面试点梳理
- 3一个完整的购物商城系统是一个庞大且复杂的任务,涉及到前端、后端、数据库等多个方面。
- 4ssh-copy-id hadoop2时报错 Permission denied, please try again_root@hadoop02's password: permission denied, pleas
- 5java面试中高频问题----1
- 6阿里云配置ssl证书(阿里云 ssl证书)_阿里云ssl证书
- 7工具 | idea快速生成所有对象set方法的插件_ideal allset插件
- 8chatgpt自己训练模型实现多轮问答对话_transformers>=4.32.0,<4.38.0
- 9前后端入门操作:smart-admin-master_smart-admin 流程
- 10流水账——DS18B20传感器(最详细)_debian系统传感器代码
大模型元年的反思与启示系列-AI Agent
赞
踩
一、写在前面
2023年年末,有机会参加了Qcon上海,庆幸能在大模型出圈元年的最后一周,去见证和学习AI核心玩家们在大模型方面的一些研究和落地。
本次QCon重要主角毫无疑问非大模型莫属,两天关于大模型各方面的分享内容主题和我们当前团队进行的工作基本契合,总结来说主要是三方面,也正好能对应当前大模型架构的经典分层,即:应用层、工具层、模型层&AI Infra:
-
应用层-大模型应用:主要以RAG&AI Agent初代的模式透出,主要的落地场景包括内部数据分析-GBI即生成式BI、研发辅助提效-生成式Code、面向外部用户和小二的知识库问答-如ChatPDF;
-
工具层-应用构建能力:主要介绍如何高效快速去构建自己场景的大模型应用(重点在AI Agent的构建),有应用构建工具-LangChain, Agent开发框架如:MetaGPT,MaaS平台如ModelScop-Agent&Agents for Amazon Bedrock等;
-
模型及基建层-大模型优化加速:核心在模型推理加速上的探索,未来以应对有限算力情况下,大模型应用规模化投产的性能和安全性诉求,目前也是业界争相要探索突破的重点;
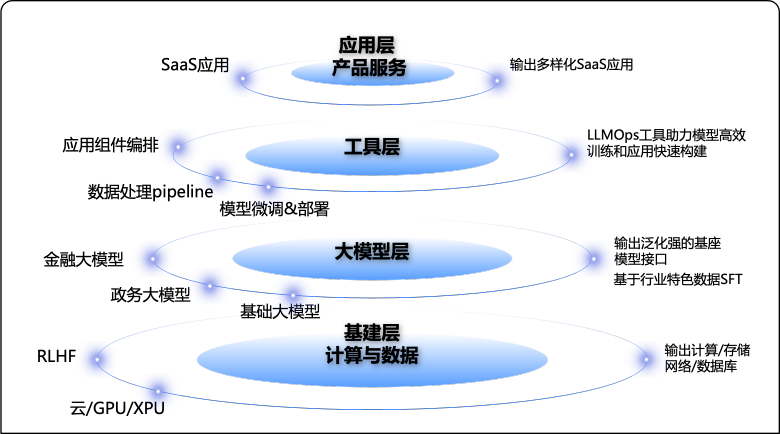
重点根据这三方面我结合在会议中的学习和个人理解来简单做下介绍和回顾,因为内容比较多,打算做个系列的分享,大纲如下:
-
大模型元年的反思与启示系列-AI Agent
-
大模型元年的反思与启示系列-LLM应用构建工具
-
大模型元年的反思与启示系列-LLM训练及微调
注:有些观点纯属个人理解,大家非喜勿喷。同时也希望大家指正,相互交流学习。
二、LLM应用
会议上涉及了很多大模型应用落地场景,出现比较多的关键词是:AI Agent和RAG。先聊聊什么是AI Agent, AI Agent是当前业界在大模型应用方面主要研究的方向,虽然大语言模型的能力足够强大,但它依旧是被动的响应用户的指令,并且生成的效果取决于使用者如何使用它。AI Agent(智能代理)则不同,它是一个自动化的程序,它具备自主规划和执行的能力,它也被视为通往AGI(通用人工智能)的钥匙。
1. AI Agent
1.1. AI Agent的定义
AI Agent是人工智能代理(Artificial Intelligence Agent)的概念,它是一种能够感知环境、进行决策和执行动作的智能实体,通常基于机器学习和人工智能技术,具备自主性和自适应性,在特定任务或领域中能够自主地进行学习和改进。
一个更完整的Agent,一定是与环境充分交互的,它包括两部分——一是Agent的部分,二是环境的部分。此刻的Agent就如同物理世界中的「人类」,物理世界就是人类的「外部环境」。
1.2. AI Agent 的主要组成部分
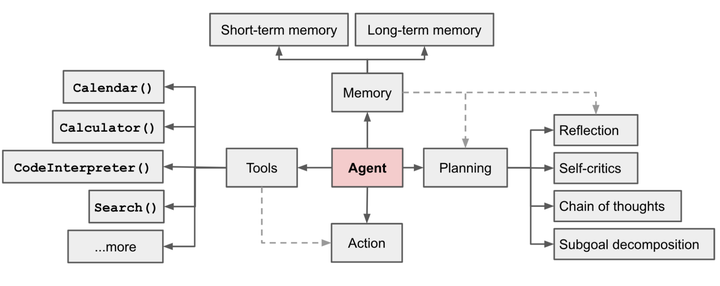
在LLM赋能的自主agent系统中(LLM Agent),LLM充当agent大脑的角色,并与若干关键组件协作 。
-
规划(planning)
-
子目标分解:agent将大任务拆分为更小的可管理的子目标,使得可以有效处理复杂任务。
-
反思与完善:agent对历史动作可以自我批评和自我反思,从错误中学习并在后续步骤里完善,从而改善最终结果的质量。
-
记忆(Memory)
-
短期记忆:上下文学习即是利用模型的短期记忆学习。
-
长期记忆:为agent提供保留和召回长期信息的能力,通常利用外部向量存储和检索实现。
-
工具使用(tool use)
-
对模型权重丢失的信息,agent学习调用外部API获取额外信息,包括当前信息、代码执行能力、专有信息源的访问等。
-
行动(Action)
-
行动模块是智能体实际执行决定或响应的部分。面对不同的任务,智能体系统有一个完整的行动策略集,在决策时可以选择需要执行的行动,比如广为熟知的记忆检索、推理、学习、编程等。
1.3. 人机协同模式
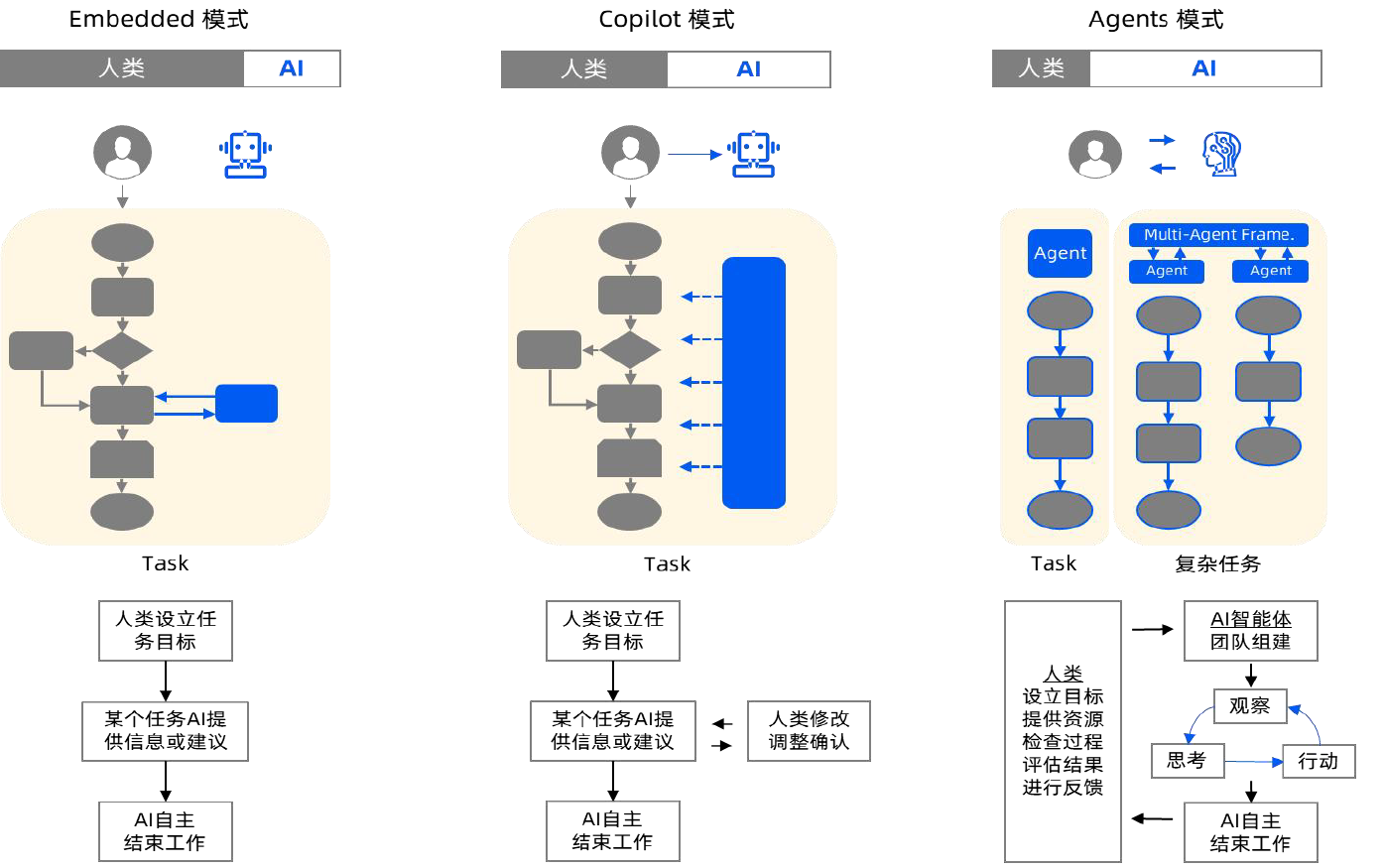
基于大模型的Agent不仅可以让每个人都有增强能力的专属智能助理,还将改变人机协同的模式,带来更为广泛的人机融合。生成式AI的智能革命演化至今,从人机协同呈现了三种模式:
-
嵌入模式:用户通过语言交流与AI合作,使用提示词设定目标,AI协助完成任务,比如用户使用生成式AI创作小说、音乐作品、3D内容等。在这种模式下,AI执行命令,人类是决策者和指挥者。
-
副驾驶模式:人类和AI是合作伙伴,共同参与工作流程。AI提供建议、协助完成工作,比如在软件开发中为程序员编写代码、检测错误或优化性能。AI是知识丰富的合作伙伴,而非简单的工具。
-
智能体模式:人类设定目标和提供资源,AI独立承担大部分工作,人类监督进程和评估结果。AI体现了自主性和适应性,接近独立行动者,人类扮演监督者和评估者的角色。
智能体模式比嵌入模式和副驾驶模式更高效,可能成为未来人机协同的主要模式。在智能体的人机协同模式下,每个普通个体都有可能成为超级个体,拥有自己的AI团队和自动化任务工作流。他们可以与其他超级个体建立更智能化、自动化的协作关系。现在业内已经有一些一人公司和超级个体在积极探索这一模式。
2. AI Agent应用
当前,AI Agent 已是公认大语言模型落地的有效方式之一,它让更多人看清了大语言模型创业的方向,以及 LLM、Agent 与已有的行业技术融合应用的前景。目前大语言模型的Agent,在代码生成、数据分析、通用问题解答、科学研究等多个领域内,都有一众开源或闭源项目,可见其火爆程度。
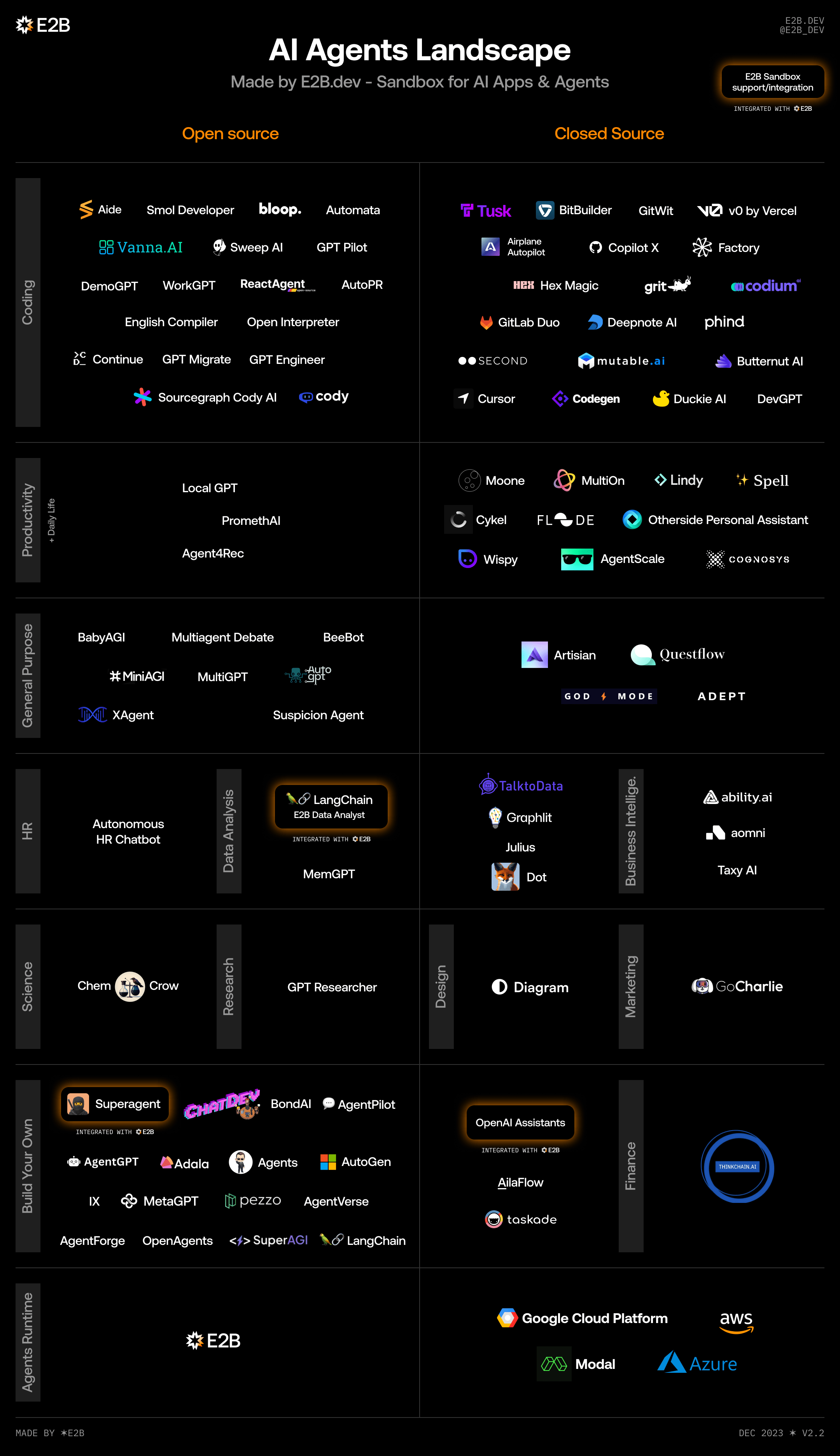
2.1. 业界相关AI Agent举例
| 应用名 | 应用地址 | 应用描述 | 是否开源 |
| AgentGPT | 基于浏览器的 AutoGPT 实现,可通过无代码平台访问。 | 是 | |
| AI Legion | 一个让智能体协同工作的平台,用 TypeScript 编写。 | 是 | |
| AutoGPT | 使 GPT-4 完全自动化的实验性开源尝试,在 GitHub 上拥有超过 14k星标。 | 是 | |
| Automata | 根据项目的上下文自动生成自己的代码。 | 是 | |
| AutoPR | AI 生成的拉取请求来解决问题,由 ChatGPT 提供支持。 | 是 | |
| Autonomous HR Chatbot | 由 GPT-3.5 提供支持的自主 HR 助理。 | 是 | |
| BabyAGI | 使用人工智能管理任务的简单框架。 | 是 | |
| BabyBeeAGI | 任务管理和功能扩展。 | 是 | |
| Loop GPT | 用于创建自主人工智能代理的开源工具。 | 是 | |
| LocalGPT | 用于构建自主人工智能代理的开源工具。 | 是 | |
| Mentat | 自主人工智能代理的开源项目。 | 是 | |
| MetaGPT | 用于创建自主人工智能代理的开源工具。 | 是 | |
| Mini AGI | 自主人工智能代理的开源项目。 | 是 | |
| Multi GPT | 用于创建自主人工智能代理的开源工具。 | 是 | |
| OpenAGI | 用于创建自主人工智能代理的开源工具。 | 是 | |
| Open Interpreter | 用于创建自主人工智能代理的开源工具。 | 是 | |
| Pezzo | 旨在简化提示设计、版本管理、发布、协作、故障排除等的开发工具包。 | 是 | |
| Private GPT | 无需互联网连接即可与文档进行私人交互的工具。 | 是 | |
| PromethAI | 个性化人工智能助手,帮助实现营养和其他目标。 | 是 | |
| React Agent | 开源 React.js 自治 LLM 代理。 | 是 | |
| Smol developer | - | 您自己的初级开发人员,通过 e2b 在几秒钟内完成部署。 | - |
| Superagent | 不是单个代理,而是一个无需编码即可创建代理的工具。 | 是 | |
| SuperAGI | 一个开源自主人工智能框架,支持开发和部署自主代理。 | 是 | |
| Sweep | Github 助手可帮助修复小错误并实现小功能。 | 是 | |
| Teenage AGI | 一款受BabyAGI启发的智能体,可以回忆无限的记忆,在采取行动之前“思考”,并且在关闭后不会丢失记忆。 | 是 | |
| “Westworld” simulation | 《西部世界》的多智能体模拟库,旨在模拟和优化多个智能体交互的系统和环境。 | 是 | |
| Voyager | Minecraft 中由大语言模型驱动的终身学习代理。 | 是 | |
| Butternut AI | 一款可在 20 秒内创建功能齐全、可随时启动的网站的工具。 | 是 | |
| Codium AI | 由人工智能驱动的交互式代码完整性开发工具使开发人员能够更快地交付软件并减少错误。 | 是 | |
| Commit | 软件开发人员的职业副驾 |
下面,我们结合QCon 上海来讲讲AI Agent的应用有哪些。
2.2. QCon上的AI Agent应用
整个分享应用上来看,核心聚焦在三类应用或场景:ABI/GBI 生成式BI或是数据分析;Code Agent 代码助手; 基于RAG技术的知识问答。
2.2.1. BI(Data Analysis) Agent - 生成式BI
2.2.1.1. LLM在金融智能应用研发实战与探索
在生成式BI(Data Agent)方面,白天专题演讲听了由腾讯云的技术总监分享的主题,他分享了txt2SQL的智能问答系统方案设计,整体准确度能达到惊人的99%(纯大模型生成且复杂度不高的SQL准确率大概在80%+)。但其实质上他们的方案主要还是依靠工程能力,并未完全使用大模型的NL2SQL的生成能力,而是结合RAG,通过Query去匹配RAG里的常见的查询问题及对应的SQL示例,然后再基于检索到的SQL去与数据源联通。

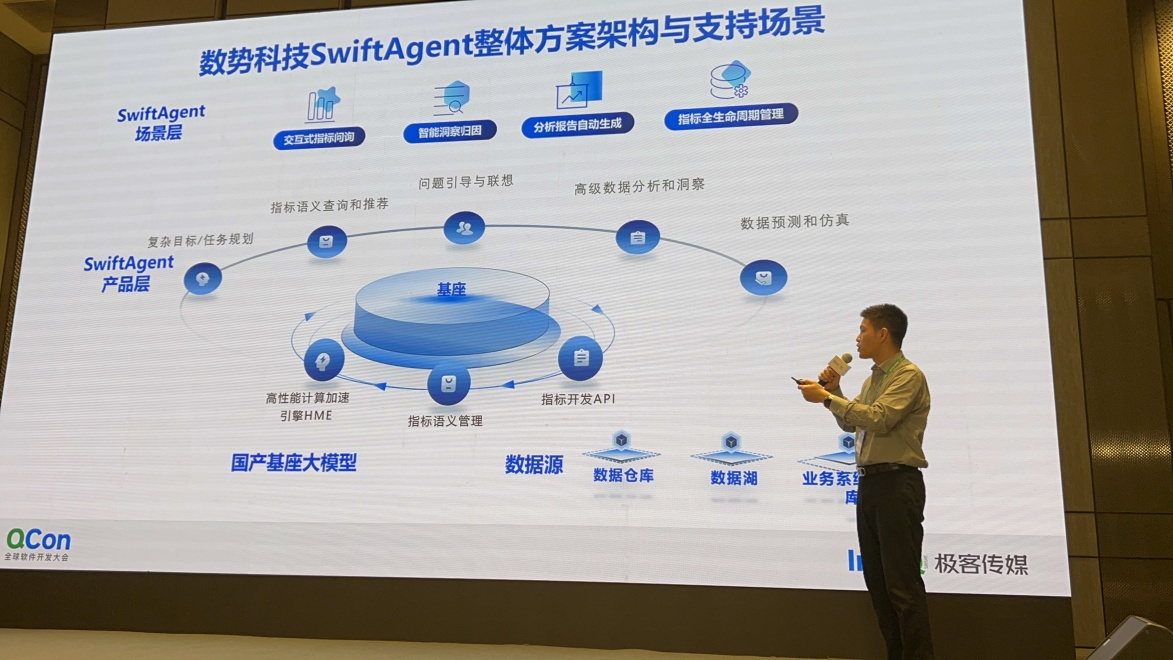
2.2.1.2. 数势大模型SwiftAgent在企业经营分析领域的应用
由数势科技/金融数字化产品总经理,分享的同类DataAgent产品-swiftAgent,将传统的BI手动全流程产品(GUI)通过大模型进行基于语言的(LUI)模式重构,包括交互的指标问询、智能的洞察归因、分析报告自动生成、指标的全生命周期管理等能力。
2.2.1.3. AIGC与数据分析融合打造数据消费新模式
网易数帆的大数据解决方案专家分享了网易在Data Agent方面的工作。面对大模型出错的情况,他们核心瞄可信方向,做了很多产品交互上的工作,去保障NL2SQL查询出的数据可信:
-
需求可理解:通过自研NL2SQL专属大模型,针对相关数据相关函数如同比/环比/分组排序等函数进行增强。
-
过程可验证:通过交互界面上以自然语言的方式生成查询的解释,让用户容易去识别模型生成过程的对错,去保障生成过程的可信。
-
用户可干预:基于查询解释,用户可手动在查询结果的查询条件上进行调整查询条件,用确定性的手段获取正确性的结果。
-
结果可运营:通过实时针对结果,进行正误标记反馈持续优化大模型的生成正确性。

另外还有一些企业进行了有关NL2SQL的场景尝试,这里不做一一列举:
2.2.2. Coding Agent
因为前期对Github Copilot、codeGeex、CodeFuse等做过深入的使用体验,核心功能是帮助程序员进行代码生成、代码优化、代码检测等研发辅助提效,场景上核心关注的更多是代码安全性的问题。这里就不做赘述,相关的分享PPT可自取:大会演讲PPT合集
2.2.3. 基于RAG的知识问答
由于篇幅的关系,RAG相关的大模型应用,将在下篇进行详细阐述和分解:《QCon上海见闻:大模型元年的反思与启示系列-RAG》。
三、挑战
从技术上看,AI Agent的发展仍然缓慢,大多数应用仍处于POC或理论实验阶段。目前几乎很少能看到能够在复杂领域场景中完全自主的规模化AI Agent应用。主要原因还是充当AI Agent大脑的LLM模型仍不够强大。即使是最强大的GPT4,在应用时仍面临一些问题:
-
上下文长度有限,限制了历史信息、详细说明、API调用上下文和响应的包含。
-
长期规划和任务分解仍然具有挑战性。
-
当前Agent系统依赖自然语言作为与外部组件之间的接口,但模型输出的可靠性值得怀疑。
此外,AI Agent的成本较高,特别是多智能体系统。在很多场景中,使用AI Agent与Copilot模式相比,效果提升不明显,或者无法覆盖增加的成本。大部分AI Agent技术仍处于研究阶段。最后,AI Agent可能面临诸如安全性与隐私性、伦理与责任、经济和社会就业影响等多方面的挑战。

