
- 1 高并发架构系列:Kafka、RocketMQ、RabbitMQ的优劣势比较 ...
- 2车载以太网自动化测试套件(SOME/IP)- AETP. TC8 SOME/IP
- 3深度学习-大模型LLM-微调经验分享&总结_大模型llm同时做实体和关系抽取
- 4实时数仓-Flink使用总结_flink实时开发平台
- 5【3DGS】从新视角合成到3D Gaussian Splatting_σ′ = jwσw j
- 6PostgreSQL索引(一)_pgsql 索引
- 7IDEA 连接mysql_driver class 'com.mysql.cj.jdbc.driver' not found
- 8嵌入式之Qt开发_qt嵌入式开发
- 9androidstudio旧版本下载_android studio 旧版本下载
- 10AI大模型探索之路-训练篇21:Llama2微调实战-LoRA技术微调步骤详解
Llama3 中文通用 Agent 微调模型来啦!(附手把手微调实战教程)_llama3微调
赞
踩
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
基于大家的讨论和大模型实践,我们写了:
《大模型面试宝典》(2024版) 发布!
《大模型实战宝典》(2024版) 发布!
Llama3模型在4月18日公布后,国内开发者对Llama3模型进行了很多训练和适配,除了中文纯文本模型外,多模态版本也陆续在发布中。
考虑到国内用户对Agent场景的需求,社区LLM&AIGC模型微调推理框架SWIFT基于Llama3-8b-instruct原始版本训练了通用中文模型,并保留且适配了中文Agent能力,这是开源社区中率先完整适配中文环境的通用Agent Llama3模型,后续会有更完整的评测报告产出。
使用方式
推荐用户直接使用swift进行推理或部署:
# 安装依赖
pip install ms-swift -U
- 1
- 2
# 推理
swift infer --model_type llama3-8b-instruct --model_id_or_path swift/Llama3-Chinese-8B-Instruct-Agent-v1
- 1
- 2
# 部署
swift deploy --model_type llama3-8b-instruct --model_id_or_path swift/Llama3-Chinese-8B-Instruct-Agent-v1
- 1
- 2
下面介绍如何使用SWIFT框架训练Llama3中文Agent模型
环境准备
我们使用框架SWIFT进行模型训练,开发者如果希望训练Llama3中文版本可以参考下面的安装方式:
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
# 安装ms-swift
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e '.[llm]'
# 环境对齐 (通常不需要运行. 如果你运行错误, 可以跑下面的代码, 仓库使用最新环境测试)
pip install -r requirements/framework.txt -U
pip install -r requirements/llm.txt -U
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了大模型面试和技术交流群,相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:来自CSDN + 技术交流
通俗易懂讲解大模型系列
准备

训练使用8卡进行,环境准备完成后,只需要如下命令即可开启训练:
NPROC_PER_NODE=8 \
swift sft \
--model_type llama3-8b-instruct \
--dataset ms-agent-for-agentfabric-default alpaca-en ms-bench ms-agent-for-agentfabric-addition coig-cqia-ruozhiba coig-cqia-zhihu coig-cqia-exam coig-cqia-chinese-traditional coig-cqia-logi-qa coig-cqia-segmentfault coig-cqia-wiki \
--batch_size 2 \
--max_length 2048 \
--use_loss_scale true \
--gradient_accumulation_steps 16 \
--learning_rate 5e-5 \
--use_flash_attn true \
--eval_steps 500 \
--save_steps 500 \
--train_dataset_sample -1 \
--dataset_test_ratio 0.1 \
--val_dataset_sample 10000 \
--num_train_epochs 2 \
--check_dataset_strategy none \
--gradient_checkpointing true \
--weight_decay 0.01 \
--warmup_ratio 0.03 \
--save_total_limit 2 \
--logging_steps 10 \
--sft_type lora \
--lora_target_modules ALL \
--lora_rank 8 \
--lora_alpha 32
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
为了提高ReACT格式的准确率,我们将部分loss字段的权重提高以保留中文训练中的agent能力表现。
推理效果
该模型具备良好的中文问答能力,示例如下:
通用问答:
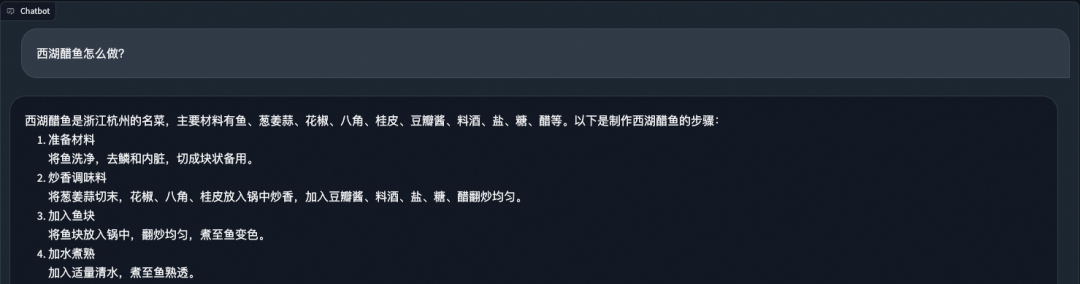

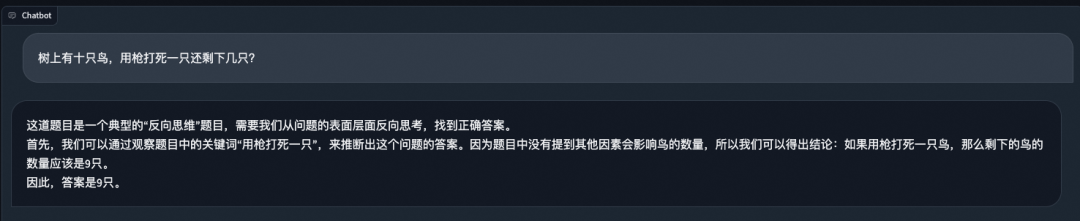
逻辑题:


对联:

藏头诗:

古文翻译:

代码能力:
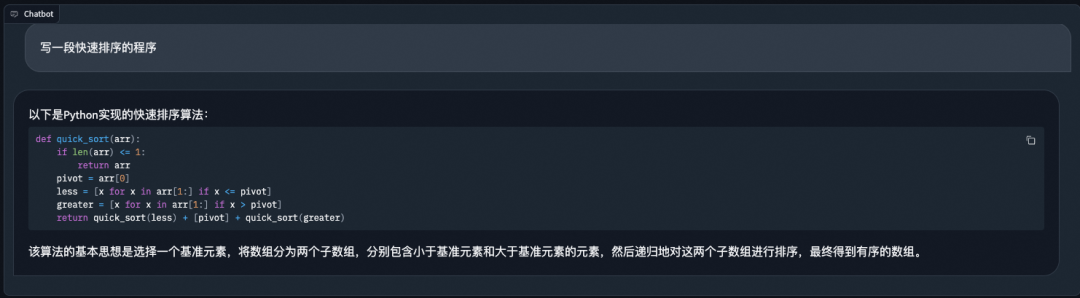
评测
我们使用swift的eval命令对训练模型的前后进行了通用能力评测,结果如下:

英文GSM8K能力下降了8个点左右,经过消融实验我们发现去掉alpaca-en语料会导致GSM8K下降至少十个点以上。
我们在服务部署后,可以在AgentFabric中校验其接口调用效果,以天气查询为例,可以看到:


模型可以按照system要求对查询进行补全。
文生图

图片解释





