
- 1[图解]SysML和EA建模住宅安全系统-04_sysml案例 ea
- 2idea 换maven项目jdk版本_idea maven 更换项目的jdk
- 3fpga快速入门书籍推荐_fpga入门书推进
- 4实验 5 Spark SQL 编程初级实践
- 5Git忽略已经上传的文件和文件夹_git 忽略文件以及忽略已上传文件
- 6解决哈希碰撞:选择合适的方法优化哈希表性能
- 7idea java 插件开发_IDEA插件开发之环境搭建过程图文详解
- 8《五》Word文件编辑软件调试及测试
- 9ubuntu下faster-whisper安装、基于faster-whisper的语音识别示例、同步生成srt字幕文件_装faster whisper需要卸载whisper吗
- 10大疆 植保无人机T60 评测_大疆t60无人机参数
【PGGAN】1、Progressive Growing of GANs for Improved Quality, Stability, and Variation 论文阅读_pggan论文
赞
踩
使用渐进式增长GAN提升质量、稳定性、变化性
paper:https://arxiv.org/abs/1710.10196
code :https://github.com/facebookresearch/pytorch_GAN_zoo
PGGAN基本思路:
如果现在我们想生成超高分辨率的图像,譬如 1024×1024 图片,假设我们采用 StackGAN 或者是 LapGAN 的话,我们需要用到的 GANs 结构会非常多,这样会导致网络 深度巨大,训练起来非常慢。为了解决这一问题,PGGAN(渐进式增长 GAN)提出的想法是,我们只需要一个 GANs 就能产生 1024×1024 图片。但是一开始的时候 GANs 的网络非常浅,只能学习低分辨率(4×4)的图片生成,随着训练进行,我们会把 GANs 的网络层数逐渐加深,进而去学习更高分辨率的图片生成,最终不断的更新 GANs 从而能学习到 1024×1024 分辨率的图片生成。
也就是说,PGGAN 与 StackGAN 和 LapGAN 的最大不同在于,后两者的网络结构是固定的,但是 PGGAN 随着训练进行网络会不断加深,网络结构是在不断改变的。这样做最大的好处就是,PGGAN 大部分的迭代都在较低分辨率下完成,训练速度比传统 GANs提升了 2-6 倍。
一、训练方法:
1、原文中
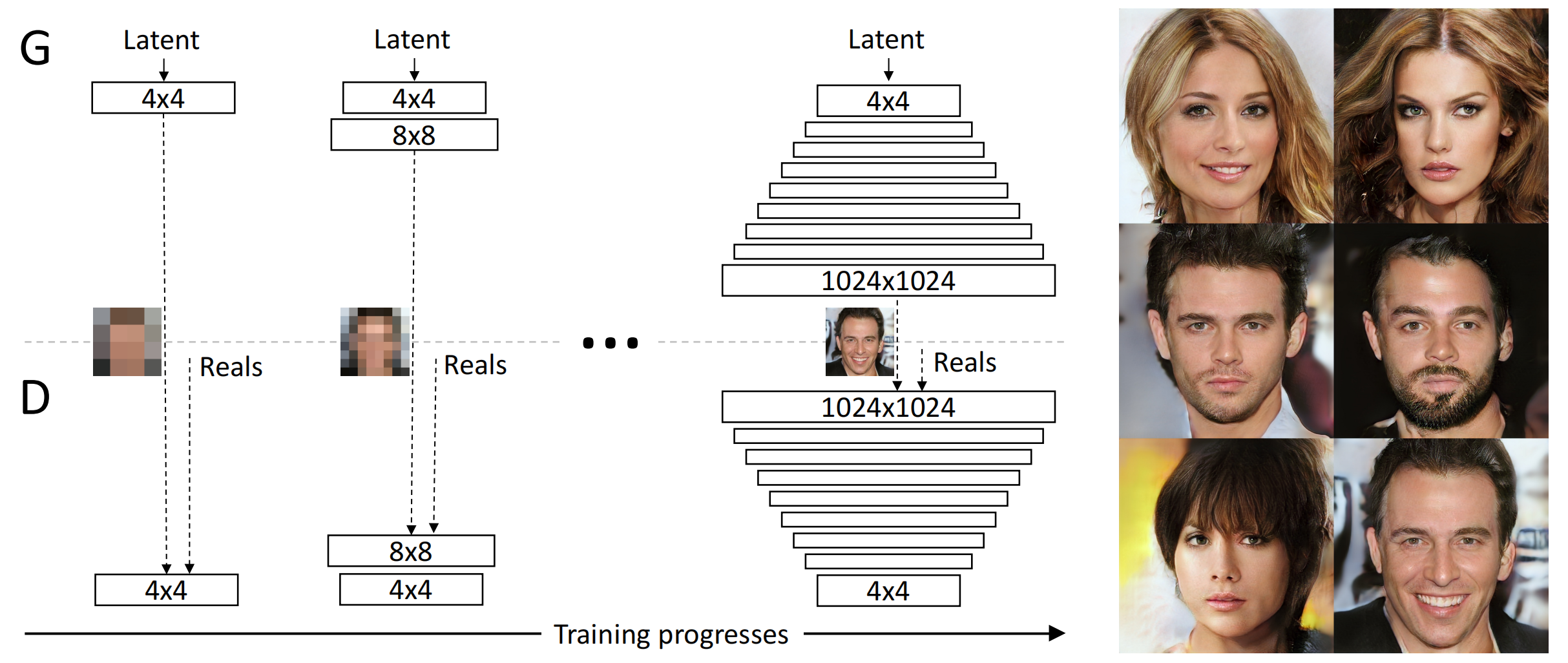
训练开始于有着一个4×4像素的低空间分辨率的生成器和判别器。随着训练,我们逐渐向生成器和判别器网络中添加层,进而增加生成图片的空间分辨率。所有现存的层在过程中保持可训练性。这里N×N是指卷积层在N×N的空间分辨率上进行操作。这个方法使得在高分辨率上也能稳定合成并且加快了训练速度。右图我们展示了六张通过使用在1024 × 1024空间分辨率上渐进增长的方法生成的样例图片。
Figure 1: Our training starts with both the generator (G) and discriminator (D) having a low spatial resolution of 4×4 pixels. As the training advances, we incrementally add layers to G and D, thus increasing the spatial resolution of the generated images. All existing layers remain trainable throughout the process. Here N × N refers to convolutional layers operating on N × N spatial resolution. This allows stable synthesis in high resolutions and also speeds up training considerably. One the right we show six example images generated using progressive growing at 1024 × 1024.
但是上述这样的做法会有一个问题,就是从4×4的输出变为8×8的输出的过程中,网络层数的突变会造成GANs的急剧不稳定,使得GANs需要花费额外的时间从动荡状态收敛回平稳状态,这会影响模型训练的效率。为了解决这一问题,PGGAN提出了平滑过渡技术。
Figure 2: When doubling the resolution of the generator (G) and discriminator (D) we fade in the new layers smoothly.
This example illustrates the transition from 16 × 16 images(a) to 32 × 32 images (c).
During the transition (b) we treat the layers that operate on the higher resolution like a residual block, whose weight α increases linearly from 0 to 1. Here 2× and 0.5× refer to doubling and halving the image resolution using nearest neighbor filtering and average pooling, respectively. The toRGB represents a layer that projects feature vectors to RGB colors and fromRGB does the reverse; both use 1 × 1 convolutions. When training the discriminator, we feed in real images that are downscaled to match the current resolution of the network. During a resolution transition, we interpolate between two resolutions of the real images, similarly to how the generator output combines two resolutions.
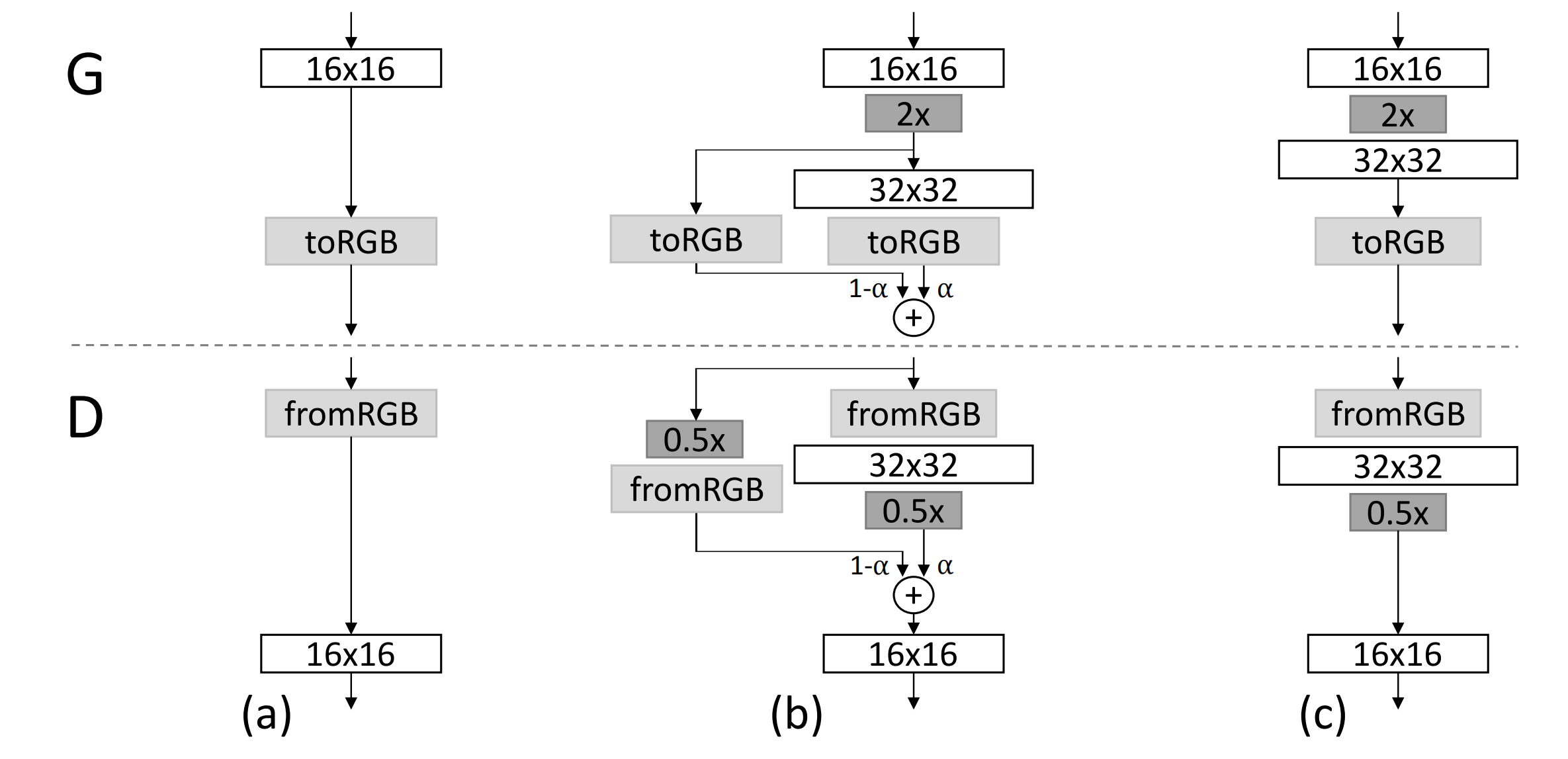
如上图所示,当把生成器和判别器的分辨率加倍时,会平滑的增强新的层。我们以从16 × 16像素的图片转换到32 × 32像素的图片为例。在转换(b)过程中,把在更高分辨率上操作的层视为一个残缺块,权重α从0到1线性增长。当α为0的时候,相当于图 (a),当α为1的时候,相当于图(c)。所以,在转换过程中,生成样本的像素,是从 16x16到 32x32转换的。同理,对真实样本也做了类似的平滑过渡,也就是,在这个阶段的某个训练batch,真实样本是: X = ∗ (1−α) +
∗ α。
上图中的2× 和 0.5× 指利用最近邻卷积和平均池化分别对图片分辨率加倍和折半。toRGB表示将一个层中的特征向量投射到RGB颜色空间中,fromRGB正好是相反的过程;这两个过程都是利用1 × 1卷积。当训练判别器时,插入下采样后的真实图片去匹配网络中的当前分辨率。在分辨率转换过程中,会在两张真实图片的分辨率之间插值,类似于将两个分辨率结合到一起用生成器输出。
2、知乎中
作者采用progressive growing的训练方式,先训一个小分辨率的图像生成,训好了之后再逐步过渡到更高分辨率的图像。然后稳定训练当前分辨率【通过加权】,再逐步过渡到下一个更高的分辨率。

如上图所示。更具体点来说,当处于fade in(或者说progressive growing)阶段的时候,上一分辨率(4*4)会通过resize+conv操作得到跟下一分辨率(8*8)同样大小的输出,然后两部分做加权,再通过to_rgb操作得到最终的输出。这样做的一个好处是它可以充分利用上个分辨率训练的结果,通过缓慢的过渡(w逐渐增大),使得训练生成下一分辨率的网络更加稳定。
上面展示的是Generator的growing阶段。下图是Discriminator的growing,它跟Generator的类似,差别在于一个是上采样,一个是下采样。这里就不再赘述。
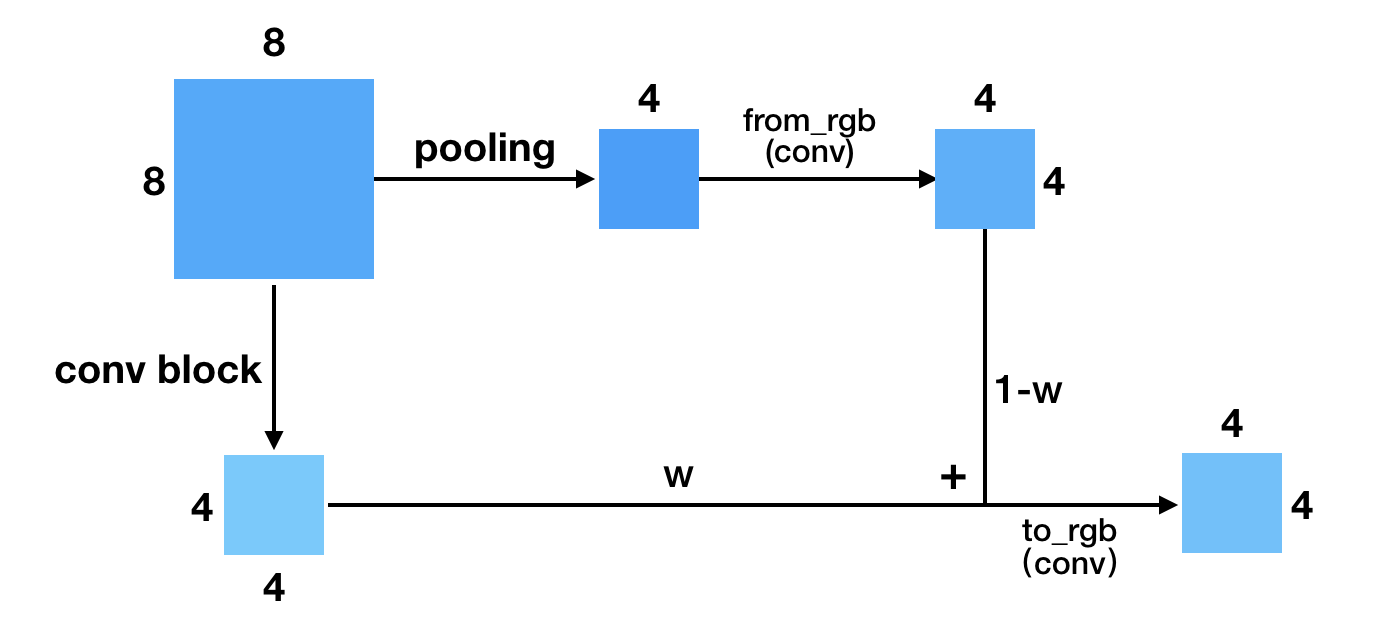
不难想象,网络在growing的时候,如果不引入progressive(fade in),那么有可能因为比较差的初始化,导致原来训练的进度功亏一篑,模型不得不从新开始学习,如此一来就没有充分利用以前学习的成果,甚至还可能误导。我们知道GAN的训练不稳定,这样的突变有时候是致命的。所以为了稳定突变的分辨率,fade in(渐进)对训练的稳定性来说至关重要。
借助这种growing的方式,PG-GAN的效果超级好。另外,我认为这种progressive growing的方法比较适合GAN的训练,GAN训练不稳定可以通过growing的方式可以缓解。不只是在噪声生成图像的任务中可以这么做,在其他用到GAN的任务中都可以引入这种训练方式。我打算将progressive growing引入到CycleGAN中,希望能够得到更好的结果。
二、增加多样性,防止模型崩塌:
P-GAN通过设计判别多样性的特征人为引导增加多样性,从而解决模型崩塌问题。
作者沿用improved GAN的思路,通过人为地给Discriminator构造判别多样性的特征来引导Generator生成更多样的样本。Discriminator能探测到mode collapse是否产生了,一旦产生,Generator的loss就会增大,通过优化Generator就会往远离mode collapse的方向走,而不是一头栽进坑里。Improved GAN引入了minibatch discrimination层,构造一个minibatch内的多样性衡量指标,它引入了新的参数。
为简化计算,文中直接计算minibatch 中feature 的标准差的均值,该scalar经扩展为feature map大小后直接作为新feature map的一个通道。我们把这层叫做Minibatch stddev层。该层可以加到D中的任意位置,但是作者只加到了D的末端。下图是网络的最终结构(D与G对称):
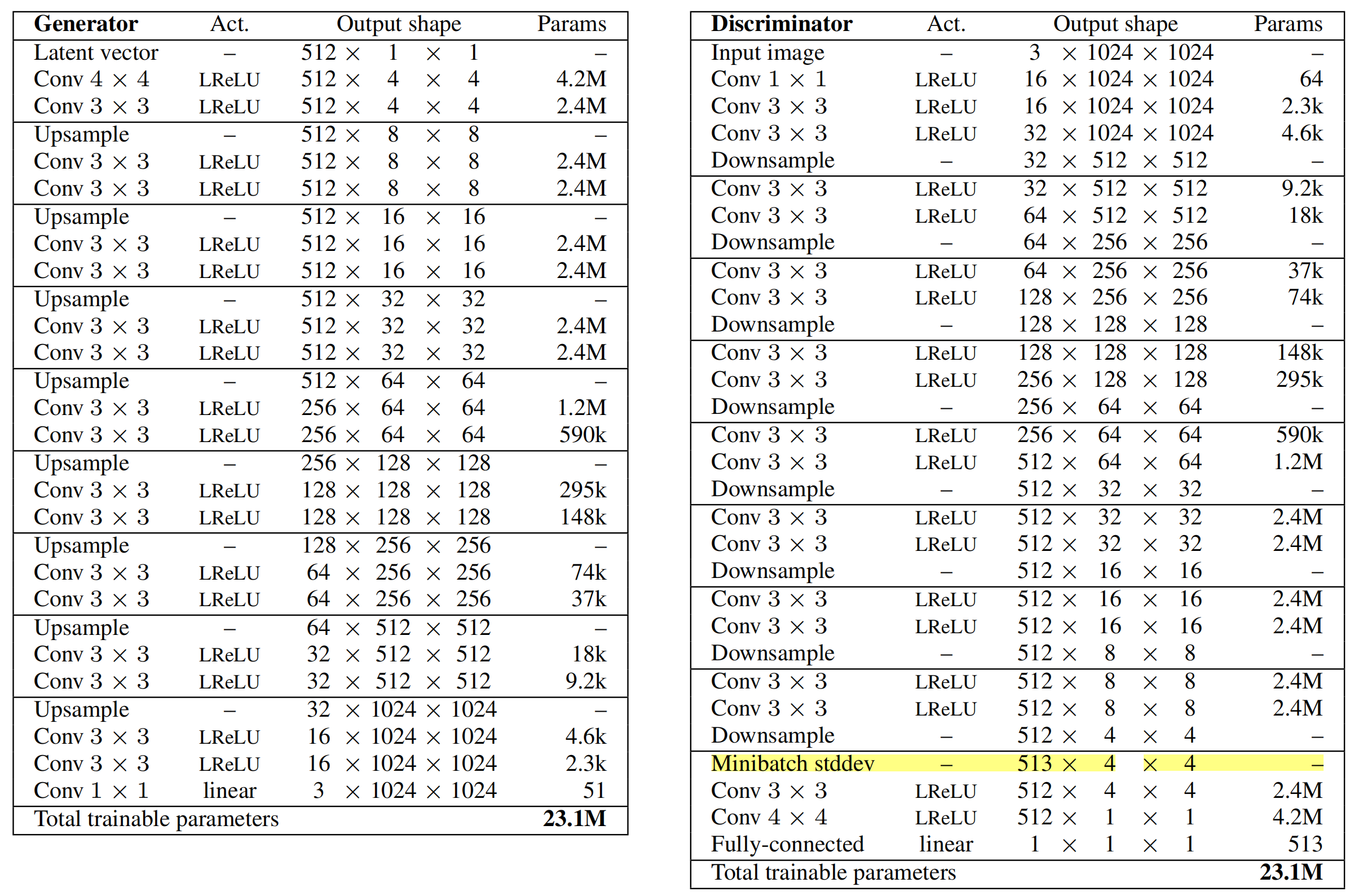
生成对抗网络总有一种捕获训练数据中部分数据分布的倾向,学术界称之为 mode collapse,情况严重的话,称之为 mode dropping。这与我们 GAN 生成对抗网络的原本思想背道而驰,我们希望 GAN能够捕捉出所有数据的分布,进而生成器可以产生尽可能真实、多样的图片。为了应对这种情况,作者提出了一种方法 minibatch standard deviation。
该方法的前身是 Minibatch discrimination。是生成对抗网络之父 Ian Goodfellow 在 2016 年 Improved Techniques for Training GANs 中提出,具体的步骤如下图所示:
Ian Goodfellow 在论文中曾经说道 Minibatch Discriminator 的中心思想在于让 discriminator 每一次看多个 instance 的组合,而不是单独的看一个 instance。(这样可以增加 mode collapse 的惩罚)。每次看多个样本的方法,有一点和 Batch Normalization 类似。然而,考虑到 Minibatch Disrminator 只是作为防止 mode collapse 的工具,因此,我们对他进一步限制,查看我们生成的图像距离是否足够的 '接近'。 查看样本之间距离的方法很多,作者进行大量的实验,介绍的 Minibatch Disrminator 就是一个较好的衡量距离的方法。
实在看不下去了..... 具体的看:PGGAN(ProGAN) 介绍 2022/05/06 - lucky_light - 博客园

