
- 1Oracle唯一约束中NULL处理_oracle联合唯一约束对空值有效吗
- 2Neo4j笔记-数据迁移(导出/导入)_neo4j数据导入导出
- 3python数据分析师需要掌握哪些分析技能?数据分析面试题集锦「建议收藏」_python数据分析面试 有哪些
- 4windows下使用ngrok让本地flask服务外网可访问_flask 发布到网上别人可以访问
- 5python面试自我介绍_真实python web面试经历(一)
- 6F450无人机组装与调试
- 7[每日一题]169:找出最大的可达成数字
- 8【SQLServer】JDBC连接SQLServer数据库_sqlserver jdbcurl string
- 9Linux 通用块设备层基础之buffer_head
- 10python 使用 html2image 将 html 转图片_python html2image
多重共线性的处理方法_数据少会导致多重共线性吗
赞
踩
回归分析需要考虑多重共线性问题。多重共线性是指自变量之间存在高度相关性,导致回归模型的系数估计不稳定和假设检验不可靠。在实际应用中,许多自变量之间都可能存在一定程度的相关性,如果没有进行控制,就会导致多重共线性问题的发生。今天来讨论一下,如何解决多元线性回归分析中,多重共线性的问题。
一、多重共线性含义
在多元线性回归模型中,自变量X之间线性相关的现象被称为多重共线性。
数学描述:对于模型
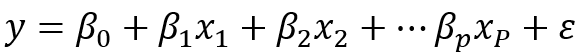
其基本假设之一是自变量X之间是相互独立的,如果某两个或者多个自变量之间出现相关性,则称为多重共线性。即如果存在不全为0的C,使得
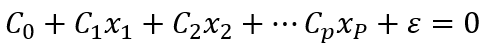
则称自变量X之间存在多重共线性。
二、多重共线性检验方法
多重共线性的检验可以使用相关分析查看两两自变量之间的相关系数,或者计算VIF值进行诊断。下文将围绕一个案例进行演示讲解。
案例:从中国知网截取一篇案例,相关说明及数据如下:

范圣岗,奚书静. 多元线性回归模型中处理多重共线性方法对比——以人口迁移冲击教育资源模型为例[J].
将数据整理好上传至SPSSSAU系统,进行后续分析。
1、相关系数检验法
如果两个自变量之间相关系数较大且接近1,则可认为回归模型中存在多重共线性问题。相关系数检验法可作为初步判断共线性的一种方法。
以SPSSAU为例,进行自变量之间的相关分析,操作如下图:
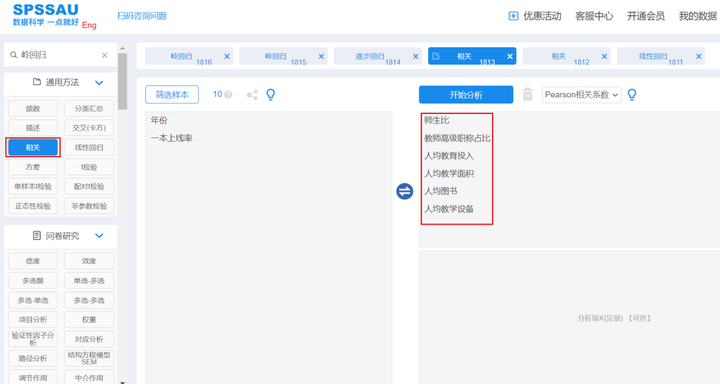
SPSSAU输出相关分析结果如下:

从相关分析结果来看,各自变量之间相关系数都较大且接近于1(均在0.7以上且显著),说明各自变量之间相关性很强,可以初步认为自变量之间存在多重共线性问题。
2、VIF检验法
VIF值是方差膨胀因子,可以衡量多重共线性的严重程度。一般认为VIF值大于10,则存在多重共线性问题(严格大于5)。
第i个回归系数的方差膨胀因子可表示为:
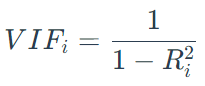
其中Ri方表示将第i个变量作为因变量与其余自变量拟合回归方程所得到的决定系数,VIF值越大说明该变量与其余自变量具有较强的相关关系。
另外,有些文献也以容忍度作为判断共线性的指标,容忍度为VIF值的倒数,容忍度大于0.1则说明没有共线性(严格是大于0.2)。研究时二者选其一即可,一般描述VIF值。
VIF值和容忍度可以通过SPSSAU线性回归分析得到,如下图:
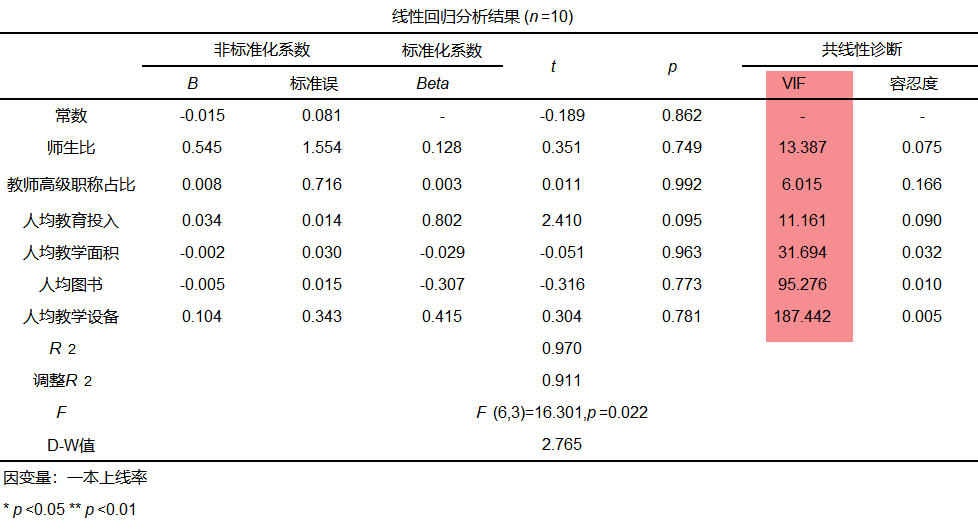
从分析结果可以看出,除变量2教师高级职称占比外,其余变量的VIF值均大于0,可以认为存在严重的多重共线性问题。
三、多重共线性处理方法
当模型中出现多重共线性问题时,常用的解决办法有以下4种:
(1)手动剔除变量
(2)逐步回归
(3)岭回归
(4)增大样本量
接下来,基于本案例分别进行演示说明。
1、手动剔除变量
手动剔除变量,最简单的方法就是对存在共线性的自变量进行一定的筛选。
首先将VIF值最大的两个自变量“人均图书”和“人均教学设备”进行剔除,再次分析,得到结果如下:
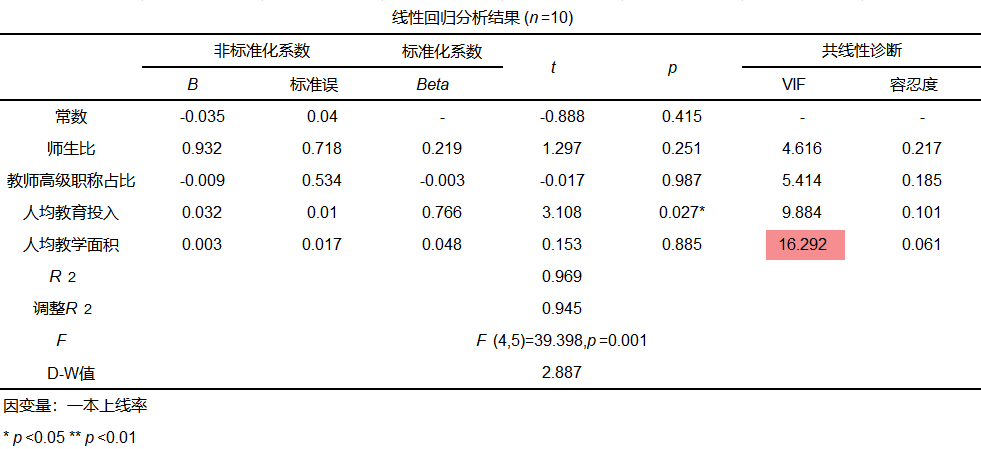
从上表可以看出,在手动剔除了VIF值最大的两个变量后,剩下四个变量的VIF值均呈现下降趋势。但此时“人均教学面积”的VIF值仍大于10,进一步进行剔除后,得到结果如下:
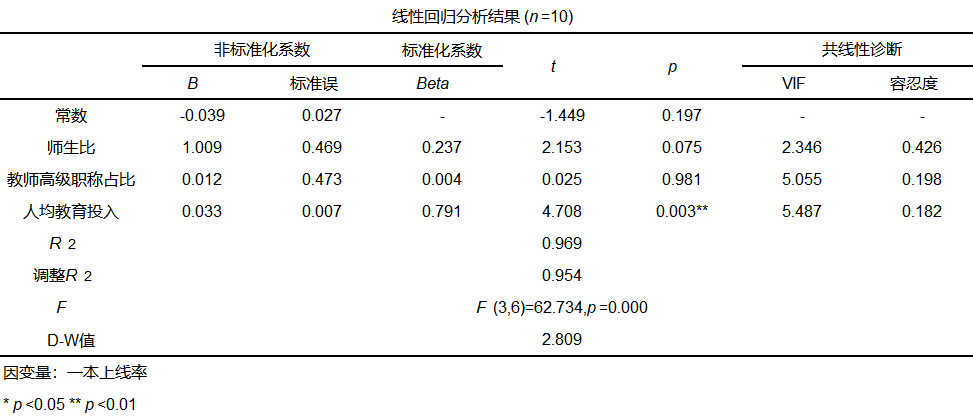
此时可以看到,剩余3个变量的VIF值均小于10,此时多元回归模型公式为:一本上线率=-0.039 + 1.009*师生比 + 0.012*教师高级职称占比 + 0.033*人均教育投入,各系数均与正常逻辑相符。且模型R方值为0.969,表明方程有较好的显著性及对模型很好的解释性。
2、逐步回归
逐步回归法是在模型中逐个引入自变量,自动筛选出有影响的变量。逐步回归根据模型统计意义的检验以及调整后R方的变化情况来判断新引入的变量是否引起共线性。如果新引入的变量使得模型统计意义检验能通过,且又能提高模型的调整后R方,则应该引入,否则不引入。
SPSSAU共提供3种自变量进入回归模型的方法,分别是forward向前法、backward向后法、逐步stepwise法。
① 向前法
向前法是指回归模型中的变量从无到有,从少到多逐个引入的变量构建回归模型的一种方法。
② 向后法
向后法是指回归模型的变量从有到无,由多到少的逐个剔除变量构建回归模型的一种方法。
③ 逐步法
逐步法是向前法和向后法两种方法的结合,一边选择,一边剔除,二者交叉进行。逐步法逐个引入新变量,每引入一个新变量同时又考虑是否剔除已选变量,这种方法即保留了有显著影响的变量,又剔除了不显著的变量,使用最为广泛。故通常使用逐步法进行分析。
SPSSAU使用逐步法进行逐步回归得到分析结果如下:
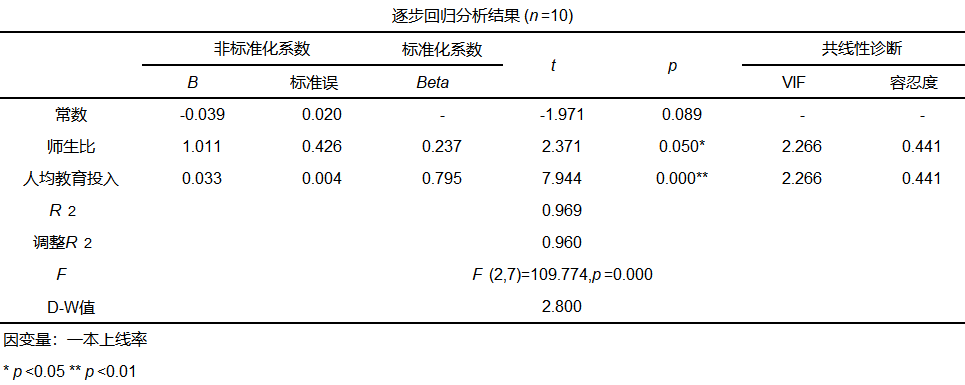
从上表可以看出,使用逐步回归进行分析,最终只保留了“师生比”和“人均教育投入”两个变量在模型中,VIF值均小于5。
【特别说明】:值得注意的一点是,手动剔除变量和使用逐步回归法进行分析时,虽然能够降低模型的共线性问题,但是可能会剔除本来希望保留在模型中的变量;可能会导致模型的原本意义发生变化,使用的时候需要注意。
3、岭回归
岭回归是利用岭估计来代替普通最小二乘估计,以损失部分信息为代价来寻找效果稍差但回归系数更符合实际情况的模型方程。当自变量之间存在多重共线性,岭回归是相对比较稳定的方法,且岭回归估计的回归系数的标准差也较小。
岭回归其研究步骤共分为两步:①结合岭迹图寻找最佳K值;②输入K值进行回归建模。
step1:结合岭迹图寻找最佳K值
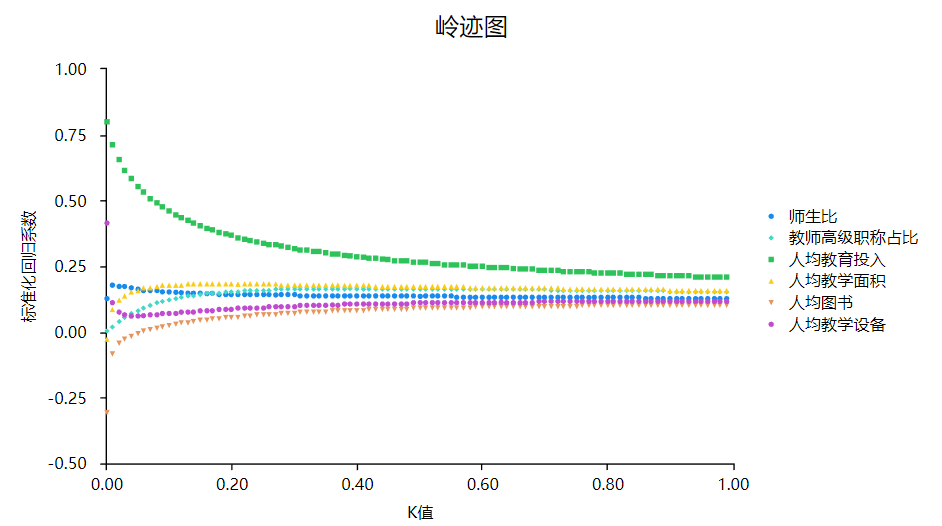
岭回归时k值的判断非常重要,通常可查看岭迹图和VIF指标进行判断。岭迹图出现平稳那一刻的k值即为最佳值,岭迹图的判断带有较强主观性。与此同时可使用VIF指标进行判断,SPSSAU默认输出该指标值,如果出现各个X的VIF均小于10时对应的最小K值,此时则为最优K值。
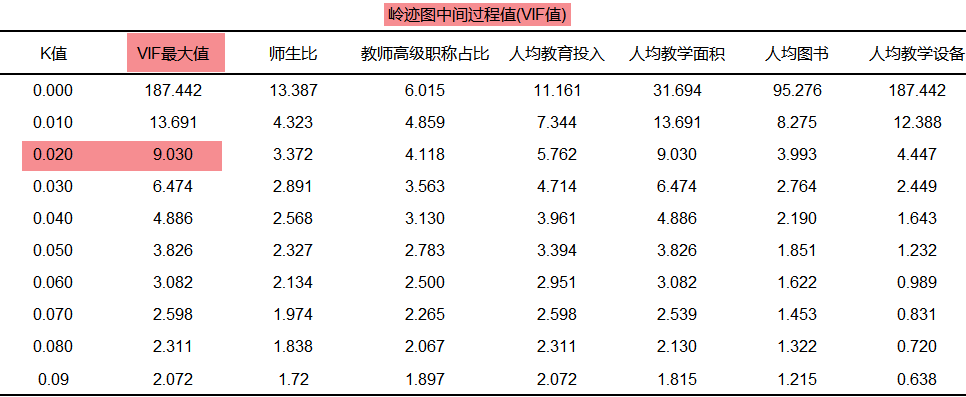
SPSSAU结合VIF<=10和K值越小越好这两个标准进行评判,建议可取K值为0.02。
step2:输入K=0,02,再次进行分析,得到岭回归分析结果如下:
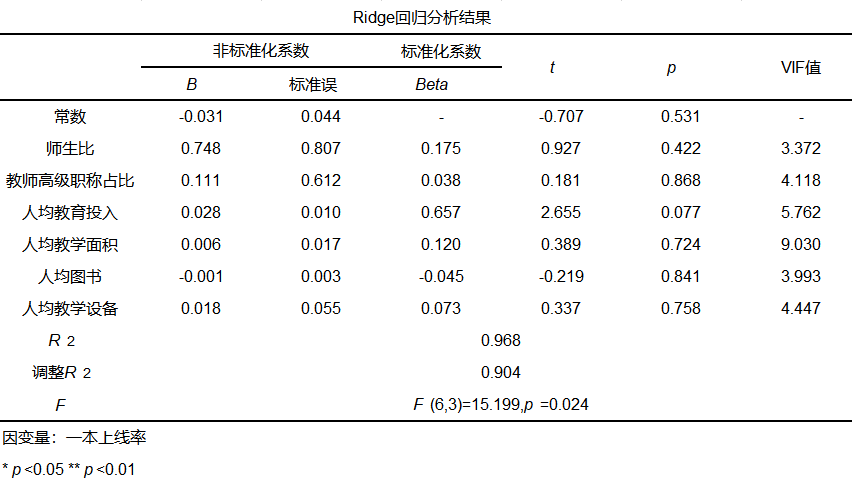
从岭回归分析结果可以看出,VIF值均小于10,解决了多重共线性问题。
4、增大样本量
在建立回归模型时,如果变量的样本数据太少,很容易产生多重共线性问题。所以可以通过增大样本量的方法,克服多重共线性。但是在实际研究中是不现实的,因为我们没有办法确定增加什么多少样本才能克服多重共线性,也有可能在增加了样本量的同时,产生了一些新的问题,导致模型的拟合变差,没有达到我们所期望的效果。
除以上方法外,还可以使用主成分回归、lasso回归、改变参数的约束形式、变换模型的形式、综合使用时序数据和截面数据等多种方法处理数据的多重共线性问题。
参考文献:
[1]刘芳,董奋义. 计量经济学中多重共线性的诊断及处理方法研究[J]. 中原工学院学报,2020,31(01):44-48+55.
[2]范圣岗,奚书静. 多元线性回归模型中处理多重共线性方法对比——以人口迁移冲击教育资源模型为例[J]. 科技风,2020,No.427(23):157+159.

