
- 1Stable Diffusion ComfyUI 基础教程(六)图片放大与细节修复_comfyui怎么用放大算法
- 2中国蚁剑免费下载(这里是win版)_中国蚁剑下载
- 3中兴新支点命令篇——任务管理命令_新支点系统查看版本命令在哪
- 4【Unity】通过代码控制编译器的暂停_unity 暂停编辑器
- 5自然语言处理--Keras 实现LSTM循环神经网络分类 IMDB 电影评论数据集_lstm电影评价数据集
- 6计组实验报告(1)_支持veriloghdl的工具及获取方法
- 7维修服务系统,解决家居小问题
- 8Python中os.environ基本介绍及使用方法_os.environ.get
- 9阿里云ECS流量计算_如何查看阿里云流量使用情况csdn
- 10函数调用时长的关键点:揭秘参数位置的秘密
深度学习在人脸识别中的应用综述合集 | Deep Face_人脸识别 csdn
赞
踩
人脸识别的过程
人脸识别的流水线包括四个阶段:检测⇒对齐⇒表达⇒分类。
其中,特征提取与度量,是人脸识别问题中的关键问题,也是相关研究的难点之一。人脸对齐同样是难以解决的问题,特别是在无约束的环境下。
前言
1.传统人脸识别的缺点
传统人脸识别方法,主要利用了手工特征对面部信息进行归纳提取,将人脸图像变换到新的空间进行辨识比对。
而实际场景中人脸的多样性(妆容、光照、角度、配饰、表情、年龄变化等)信息,导致了手工特征无法稳健地获取人脸识别的特征。
对此,传统方法的解决方案多为对图像进行预处理,包括去噪、白平衡、人脸对齐等等,但由于特征的表达能力较弱,因此性能较为受限。
2.人脸识别在深度学习中是一个什么问题?
首先,CNN的经典模型,如Resnet,VGG等,是一个典型的分类模型。
例如,手写数字识别问题中,共60000张训练图像,和10个类别。
用这些图像,将模型训练为一个十分类的问题。
然而,这种模型适合用于人脸识别吗?
3.人脸识别在分类问题中的局限性
在实际场景中,人脸识别往往不能作为一个分类问题看待。
其中主要原因是,我们很难为每个人都采集足够多的训练图像作为训练
而且,即便我们为每个人都采集了大量的训练图像,也很难训练一个大规模的分类模型–因为类别太多了,特征空间太拥挤。
以CelebA为例,该数据集和mnist的对比如下
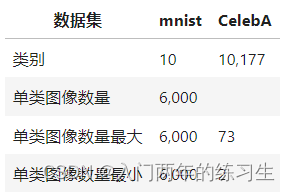
可以看到这里CelebA数据中有10177个类别,且最小的类别图像数据和最大类别图像数据相差过大。
显然,这样的数据集我们不能够用分类模型训练一个分类器。
4.人脸识别过程注重的关键因素
在人脸检测环节中,我们主要关注检测率、漏检率、误检率三个指标,其中:
检测率:存在人脸并且被检测出的图像在所有存在人脸图像中的比例;
漏检率:存在人脸但是没有检测出的图像在所有存在人脸图像中的比例;
误检率:不存在人脸但是检测出存在人脸的图像在所有不存在人脸图像中的比例。
检测速度:如果投入使用但过于耗时他也就失去了原本开发的意义
5.人脸识别过程的应用场景
在人脸识别环节,其应用场景一般分为1:1和1:N。
1:1就是判断两张照片是否为同一个人,通常应用在人证匹配上,例如身份证与实时抓拍照是否为同一个人,常见于各种营业厅以及后面介绍的1:N场景中的注册环节。而1:N应用场景,则是首先执行注册环节,给定N个输入包括人脸照片以及其ID标识,再执行识别环节,给定人脸照片作为输入,输出则是注册环节中的某个ID标识或者不在注册照片中。可见,从概率角度上来看,前者相对简单许多,且由于证件照通常与当下照片年代间隔时间不定,所以通常我们设定的相似度阈值都是比较低的,以此获得比较好的通过率,容忍稍高的误识别率。
而后者1:N,随着N的变大误识别率会升高,识别时间也会增长,所以相似度阈值通常都设定得较高,通过率会下降。这里简单解释下上面的几个名词:误识别率就是照片其实是A的却识别为B的比率;通过率就是照片确实是A的,但可能每5张A的照片才能识别出4张是A其通过率就为80%;相似度阈值是因为对特征值进行分类是概率行为,除非输入的两张照片其实是同一个文件,否则任何两张照片之间都有一个相似度,设定好相似度阈值后唯有两张照片的相似度超过阈值,才认为是同一个人。所以,单纯的评价某个人脸识别算法的准确率没有意义,我们最需要弄清楚的是误识别率小于某个值时(例如0.1%)的通过率。不管1:1还是1:N,其底层技术是相同的,只是难度不同而已。
据此的问题在于:在无法充分训练CNN的前提下,如何利用它得到一个精确的特征提取器?
这里有2014年的deepface深度学习来做出了一个新的突破
人脸识别在深度学习中的第一个里程碑DeepFace
DeepFace是Facebook CVPR2014年发表,主要用于人脸验证,是深度学习人脸识别的奠基之作,超过了非深度学习方法Tom-vs-Pete classifiers、high-dim LBP、TL Joint Bayesian等
1.DeepFace主要思想
3D人脸对齐:采用显式的3D人脸建模并应用分段仿射变换,并实现人脸正面化。
人脸表示(人脸识别):利用9层深度神经网络导出人脸表示,还使用了3个无权重共享的局部连接层。人脸表示特征向量是4096维,Softmax分类。开了先例,后面再也不用LBP了。
人脸验证:无监督(两个向量的内积);有监督(卡方相似度或孪生网络)。
将基于模型的精确对齐与大型人脸数据库相结合的学习表示方法可以很好地推广到无约束环境下的人脸。在人脸数据集Facebook的SFC 上训练网络模型。LFW达到97.35%的准确度,YTF上91.4%,将当前技术水平的误差减少了27%以上,接近人类水平的表现。
2.人脸对齐
人脸对齐仍然被认为是难以解决的问题,特别是在无约束的环境下
DeepFace是将检测的人脸投射到3维模型上,再对齐到正脸。这个方法比较复杂,后面不用它也能取得很好的效果。

对齐的步骤是:找6个landmarks–>进行2D对齐–>重新找6个landmarks–>重新进行2D对齐……直到收敛–>找67个landmarks–>3D-2D映射建模–>逐段仿射变换变成正脸。
- (a)检测人脸及检测6个初始基准点:由训练有素支持向量回归器(Support Vector Regressor)+LBP 来检测剪切块内的6个基准点,其中眼睛中心2个,鼻尖1个和嘴部位置 3个。
- (b)2D对齐的剪切块:6个基准点用于通过缩放、旋转和平移将图像转换成6个锚点位置,然后在新的warped图像上迭代直到没有显著变化,最终构成2D相似性变换,生成了2D对齐的剪切块。然而,相似变换不能补偿平面外旋转,这在无约束条件下尤为重要。
- ©在2D剪切块上定位67个基准点并做相应的Delaunay三角剖分:为了对齐经平面外旋转的人脸,使用通用的3D形状模型并注册3D仿射相机,相机用于将2D剪切曲线扭曲到3D形状的图像平面。使用第二个SVR在2D对齐的剪切块中定位另外的67个基准点。在轮廓上添加了三角形以避免不连续。
- (d)将三角化后的人脸转换成3D形状:手动在3D参考形状(USF Human-ID数据库的3D扫描的平均值)上放置67个锚点,并且以这种方式实现基准点与3D参考点之间的完全对应。
- (e)相对于拟合的3D-2D相机的三角形可视图:然后使用广义最小二乘解和一个已知协方差矩阵Σ来拟合一个仿射3D到2D的相机P,大小为2×4的仿射相机P由8个未知数的向量P->表示。较暗的三角形能见度低。
- (f)分段仿射变换:最后的正面化是通过由67个基准点衍生的Delaunay三角剖分引导的分段仿射变换(piece-wise affinewarping)实现的
- (g)最终的正面化的剪切块
3.模型结构
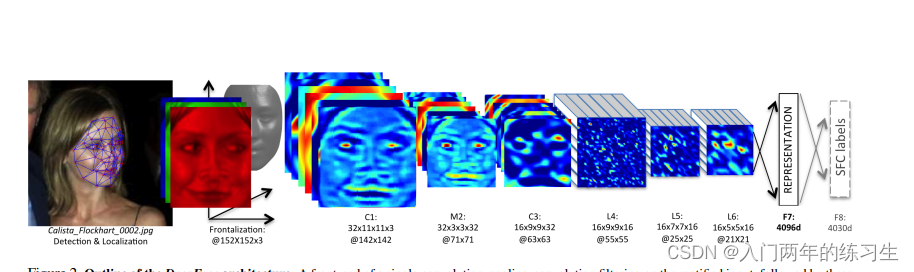
该工作具有典型的早期CNN的研究风格,采用分类的思路来训练模型 使用的数据集为SFC(social face
classification),共440万张图像,4030个类别,每个人都有800至1200张图像。
这样的数据集足够训练一个CNN模型(一百万级参数)
通过一个大型的深层网络学习面部图像的一般表示(Representation)。将DNN训练成一个多分类的人脸识别任务,即对人脸图像的身份进行分类。
- 3D对齐后的152x152像素的3通道RGB人脸图像被送入具有32个11×11×3的滤波器的卷积层(C1)。
- 然后将得到的32个特征图馈送到最大池化层(M2),对3×3空间邻域最大池化,步幅为2, 每个通道分别执行。
- M2之后是具有16个9×9×32的滤波器卷积层(C3)。
- 局部连接层(locally connected layers)(L4, L5和L6)应用类似卷积层的滤波器组,但是特征图中的每个位置都学习不同的滤波器组,Local的意思是卷积核的参数不共享。LCN不同于卷积层,LCN每个点的卷积核都不一样。
这是因为对齐图像的不同区域具有不同的局部统计特征,卷积的局部稳定性假设并不存在,所以使用相同的卷积核会导致信息的丢失。局部连接层的使用不会影响特征提取的计算负担,但会影响需要训练的参数数量。 - F7和F8是全连接,能够捕获在人脸图像特征之间的较远部分的相关性,例如,眼睛的位置和形状以及嘴的位置和形状。
- F7的输出将用作原始人脸表示特征向量,4096维。
这与基于lbp的表示形成了对比,它通常汇集非常局部的描述符(通过计算直方图),并将其用作分类器的输入。
7.F8上人脸表示被送到了 K-way Softmax 来产生在类别标签上的概率分布,用于分类。4030维,是因为SFC训练数据集有4030个人,每个人具有800到1200张人脸图片.
训练的目标是最大限度地提高正确类别(人脸id)的概率。最小化每个训练样本的交叉熵损失来实现,并使用随机梯度下降(SGD)更新参数,使各参数的损失最小化。使用了ReLU激活。
只对第一个全连接层应用了dropout,由于训练集较大,我们在训练过程中没有观察到明显的过拟合。
7. 人脸表示归一化:将人脸表示特征归一化为0到1之间,以降低对光照变化的敏感度。对于F7输出的4096-d向量先每一维进行归一化,即对于结果向量中的每一维,都要除以该维度在整个训练集上的最大值;再对每个向量进行L2归一化。
归一化后的DeepFace特征向量与传统的基于直方图的特征(如LBP)有相同之处:所有值均非负;非常稀疏;特征元素的值都在区间[0,1]之间。
4.人脸验证
人脸验证的目标是判断两个人脸图像是否属于同一个人的,1:1
其中:
- 无监督相似性指标:直接对两个归一化的特征向量做内积。
DeepFace的目标是学习一种无监督的指标,它可以很好地泛化到几个数据集。 - 有监督度量指标: 卡方相似度或孪生网络。
有监督的方法相对于无监督的方法表现出明显的性能优势。通过对目标域的训练集进行训练,可以对特征向量(或分类器)进行微调,从而更好地在数据集的特定分布范围内执行。但训练数据和测试数据的不一致会导致很差的泛化能力,如果将模型拟合在小的数据集则会大大减小它泛化到其它数据集的能力。
- 卡方相似度:
χ 2 ( f 1 , f 2 ) = ∑ i w i ( f 1 [ i ] − f 2 [ i ] ) 2 f 1 [ i ] + f 2 [ i ] \chi^{2}\left(f_{1}, f_{2}\right)=\sum_{i} w_{i} \frac{\left(f_{1}[i]-f_{2}[i]\right)^{2}}{f_{1}[i]+f_{2}[i]} χ2(f1,f2)=i∑wif1[i]+f2[i](f1[i]−f2[i])2
f 1 , f 2 是 D e e p F a c e 的表示 , 权重参数 w 使用 S V M 学习 f_{1},f_{2}是DeepFace的表示,权重参数w使用SVM学习 f1,f2是DeepFace的表示,权重参数w使用SVM学习
-Siamese network (并使用加权L1距离)
把上面那个网络,复制两份,两个人脸分别输入两个小网络,两个小网络共享参数,最后计算两个输出的特征向量的距离,用一个全连接层映射为一个逻辑单元(相同还是不相同)。网络的参数和上面人脸表示网络的一致,为了防止过拟合,训练的时候只训练最高两层。
在Siamese网络中,以人脸验证为目标,特征提取和人脸识别来联合学习。

5.数据集
本文提出的人脸表示是从SFC数据集训练,常用的数据集有以下几个:
社交人脸分类(Social Face Classification , SFC)数据集: SFC数据集来自Facebook的大量照片,包括4030个人的440万张标记人脸,每个人具有800到1200张人脸图片。
LFW数据集:由5,749个名人的13,323张网络照片组成,这些照片在10个分组中分为6,000个人脸对。这是在无约束环境中进行人脸验证的基准数据集。
CelebA数据集:是CelebFaces Attribute的缩写,意即名人人脸属性数据集,其包含10,177个名人身份的202,599张人脸图片,每张图片都做好了特征标记,包含人脸bbox标注框、5个人脸特征点坐标以及40个属性标记
LFW data set
CelebA data set
6.实验结果
与其他几种方法的对比
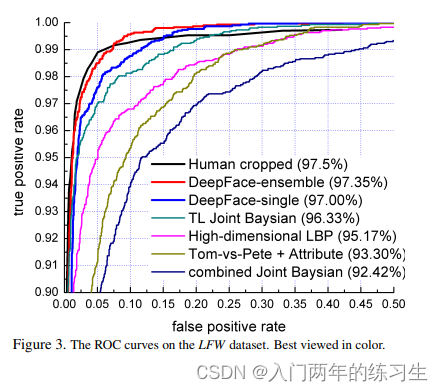
LFW数据集的结果:
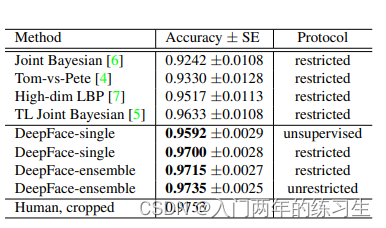
YTF数据集结果
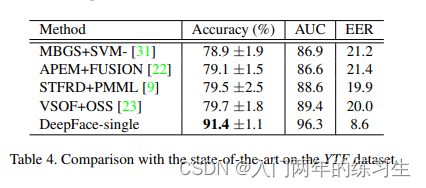
TYF视频级人脸验证数据集上性能也好很多,ROC曲线上DeepFace在左上角,性能最好。我们通过为每对训练视频创建50对帧(每个视频一个帧)来直接使用DeepFace-Single表示,并根据视频训练对将这些帧标记为相同或不相同,然后训练网络。测试时,给出一个测试视频对后,从每段视频中随机选出100个视频帧对,将输出的结果取均值作为判断的依据。使用有监督weighted χ2验证。在YTF上91.4%,由于YTF库中有100个标注错误的视频对,经过改正后,达到了92.5%。这也证明我们的DeepFace方法,在其他领域也具有很好的泛化性能(视频人脸验证)。
现代人脸识别研究的主要趋势
现代人脸识别问题,主要的核心在于如何将不同的人脸,在特征空间中有效区分开来。
例如,利用siamese network,就是一种典型的度量学习策略。
这种度量学习,通常采用对比损失作为损失函数,其目标是判断输入的两个实例,是/不是 一类。
虽然这种方式能够将类间距离加大,但对于类内距离的减小,作用有限。
对此,人们又提出了三元组损失。

这里二元组的的应用通俗的来讲
如果
d
趋于
0
,则
c
o
n
s
t
r
a
s
t
为
1
如果
d
很大,则
c
o
n
s
t
r
a
s
t
为
0
使得他们综合还是
1
如果d趋于0,则constrast为1 如果d很大,则constrast为0 使得他们综合还是1
如果d趋于0,则constrast为1如果d很大,则constrast为0使得他们综合还是1
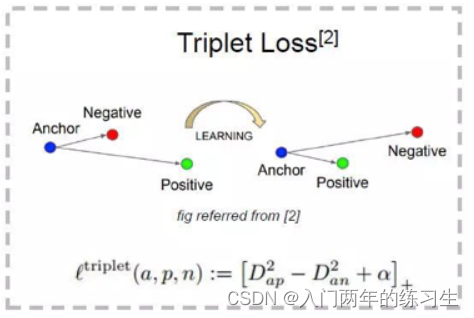
加入三原组给三个例子
P
1
P
2
N
1
送入网络,使得
d
(
f
p
1
,
f
p
2
)
距离尽可能为
0
d
(
f
p
1
,
f
n
1
)
距离尽可能大缺点:难训练,选取正例负例困难
加入三原组 给三个例子 P1 P2 N1 送入网络,使得d(fp1,fp2)距离尽可能为0 d(fp1,fn1)距离尽可能大 缺点:难训练,选取正例负例困难
加入三原组给三个例子P1P2N1送入网络,使得d(fp1,fp2)距离尽可能为0d(fp1,fn1)距离尽可能大缺点:难训练,选取正例负例困难
三元组损失函数可以在加大类间距离的同时,拉近类内距离。因此,获得了较好的结果[3]。
在google提出的FaceNet中,人脸识别的准确率在LFW上,达到了98.87/%, 如果使用了额外的对齐手段,准确率还能继续提升一个点。
同样,加入三元组损失的问题在于模型训练成本增加。
解决方案包括:先用常规训练得到基本模型,然后再用三元组进行fine tuning,或者是改变simple的方式,把一些较难辨识的类别特殊处理等等。
论文地址:Deep Face

