
- 1vue-resource拦截器interceptors使用_vueresource 拦截器
- 2大学生如何选择人生第一份工作
- 3自然语言处理3——玩转文本分类 - Python NLP高级应用_python 文本分类
- 4hadoop集群搭建篇(伪分布,完全分布)_hadoop从伪分布式模式怎么切换到完全分布式模式怎么操
- 5docker安装教程(详解)
- 6【MySQL】MySQL表设计的经验(建议收藏)_数据库表设计
- 7SQL语法之LIKE 操作符_sql like 占位符
- 8mysql error 1142_mariadb 1142
- 9【docker】Docker的基本指令和HTML/PYTHON/C++的简单创建示例
- 10机器学习/深度学习/NLP-7-准确率acc、精确率P、召回率R、F1、交叉熵_深度学习 acc函数
自然语言处理(2)_自然语言处理2-thucnew
赞
踩
1. 数据集
数据集:中、英文数据集各一份
THUCNews中文数据集:https://pan.baidu.com/s/1hugrfRu 密码:qfud
IMDB英文数据集: IMDB数据集 Sentiment Analysis
2. 探索模块及指标学习模块
该数据集是通过用户的个人评论数据分析出个人对电影的喜恶(亦即消极和积极,目标是完成二元分类)。数据集共包含5万条评论,其中2.5万条是训练集数据,另外2.5万条是测试集数据。其中还有5万个未做标记的评论,可用来作无监督学习。
数据包包含若干个文件和两个文件夹。文件夹train和test中包含neg、pos、unsup三个子文件夹,分别对应的是消极的,积极的,和未标记的数据。
3. THUCNews数据集下载和探索
THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。我们在原始新浪新闻分类体系的基础上,重新整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。使用THUCTC工具包在此数据集上进行评测,准确率可以达到88.6%。参考链接为:http://thuctc.thunlp.org/#中文文本分类数据集THUCNews 。
数据包包含4个文件夹,分别是cnews.train.txt、cnews.val.txt、cnews.test.txt和cnews.vocab.txt。其中cnews.train.txt是训练集数据,cnews.val.txt是验证集数据、cnews.test.txt是测试集数据,我们需要通过分词然后进行处理。而cnews.vocab.txt是所有数据集中汇集成的词典,每一行表示一个词。
4. 学习召回率、准确率、ROC曲线、AUC、PR曲线


准确率(precision):所有预测中为正分类中预测正确所占的比例:

对正分类的所有预测中,预测正确的比例:
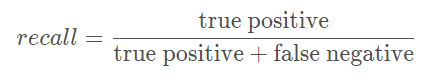
引入F1-Score作为综合指标,是为了平衡准确率和召回率的影响,较为全面的评价一个分类器:
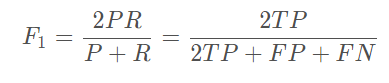
在ROC曲线中,以FPR为x轴,TPR为y轴
AUC(Area Under Curve)即指曲线下面积占总方格的比例。有时不同分类算法的ROC曲线存在交叉,因此很多时候用AUC值作为算法好坏的评判标准。面积越大,表示分类性能越好
参考资料
TensorFlow官方教程:影评文本分类 | TensorFlow (https://tensorflow.google.cn/tutorials/keras/basic_text_classification)
科赛 - Kesci.com
(https://www.kesci.com/home/project/5b6c05409889570010ccce90)
博客中的数据集部分和预处理部分
CNN字符级中文文本分类-基于TensorFlow实现 - 一蓑烟雨 - CSDN博客 (https://blog.csdn.net/u011439796/article/details/77692621)
text-classification-cnn-rnn/cnews_loader.py at mas…
(https://github.com/gaussic/text-classification-cnn-rnn/blob/master/data/cnews_loader.py)
机器学习之类别不平衡问题 (2)
ROC和PR曲线_慕课手记(https://www.imooc.com/article/48072)
参考:https://blog.csdn.net/weixin_43314778/article/details/89157472

